







老师给出的作业要求是根据数据集绘图,这一题的难点依然在于对数据的处理。

老师给我们的原数据集如下图
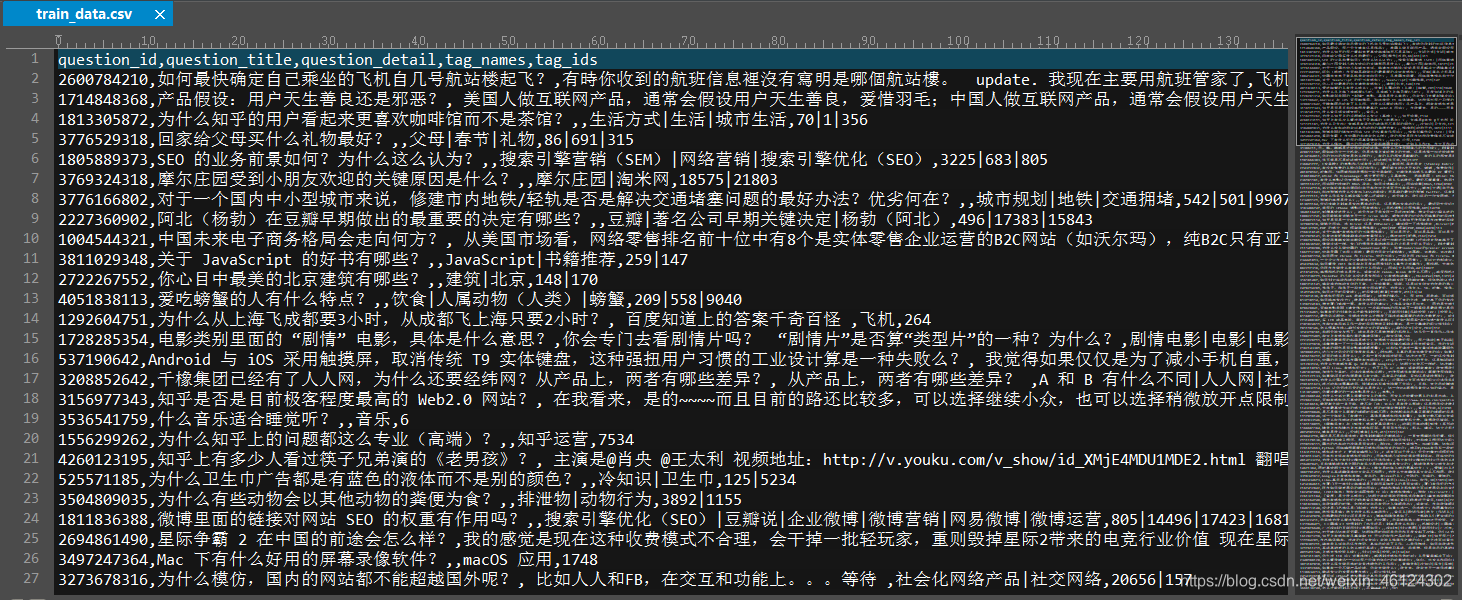
接下来我们需要运用R语言对数据进行处理
首先解决第一个问题
一、最频繁的100个标签及频率
1.设置工作路径与读入数据
一般比较常用的数据读取语句是
data = read.csv("train_data.csv",header = TRUE)
但是read.csv不适合对大数据进行处理,速度太慢。所以我们选择read_csv()函数,需要用到readr包
综合以上理解,第一步代码设计如下↓
library(ggplot2)
library(readr)
# 工作路径
setwd("D://1Study//R//CH05")
# 读入数据
#data = read.csv("train_data.csv",header = TRUE) # read.csv不适合对大数据进行处理,速度太慢
data_tags = read_csv("train_data.csv") #read_csv读取大数据的时候效率更高
data_tags
2.提取标签并制表
现在的标签一栏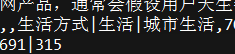 是被|所分开的
是被|所分开的
所以需要先处理"|"这个分割符号
tags_name = data_tags$tag_names#提取标签名这一栏
tags_name = strsplit(x=tags_name,split = "|",fixed = TRUE) # 按照|进行拆分
- 注意:像.?等字符是通配符,也就是说代表着一些字母或符号,比如"."就是代表全部字母,直接替换会把他们代表的东西全替换了,所以要在fixed属性中设为TRUE,这一点在我的前一篇博文【R语言】如何进行英文分词统计(以《爱丽丝漫游奇境》词频统计为例)(20年3月22日复习笔记)中也有提及。如果没有修复的话,会出现如下乱码

接下来转换一下格式,把数据从列表中打开(刚才是在data里,现在就变成了value值了)
tags_name = unlist(tags_name) # 把拆分以后的数据重组成数据框
为什么要做这一步呢?
因为我们可以发现,做这一步之前,数据在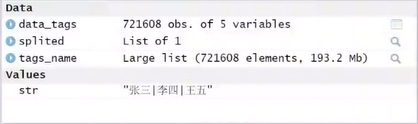
data中,是data类型,把它输出出来长这样

不是我们想要的像表格一样的格式。
所以用unlist()函数重新打开,unlist()会将列表元素(数据框作为特殊列表)则取出列表元素的组成作为项
关于这一函数,在黄大明数据分析前辈的博文中翻译了unlist()在R语言帮助文档里的内容,感兴趣的同学可以点击学习。
根据取出项生成频数表
tagsFreq = as.data.frame(table(tags_name)) #生成频数表
3.制图
排序一下
# 排序一下
tagsFreq = tagsFreq[order(-tagsFreq$Freq),] # 按照tagsFre$Freq降序排列
取前100多的词
data = tagsFreq[1:100,]
然后将图形的柱状图再按从高到低排列
# 对柱子的顺序进行重新排列
data$tags_name = factor(data$tags_name,levels = data$tags_name)
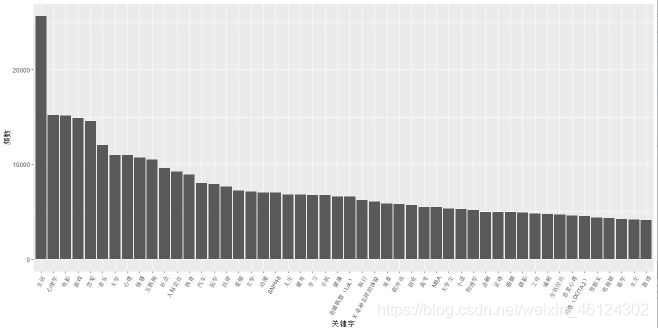
绘制频数图
ggplot(data,aes(x=tags_name,y = Freq))+
geom_bar(stat = "identity")+
theme(axis.text.x = element_text(angle = 60,hjust = 1))+
xlab("关键字")+
ylab("频数")
接下来解决第二个问题
二、中文词频提取
1.另存数据
第一步养成习惯另存数据,保证不破坏原数据,方便修正错误步骤
question_titles = data.frame(data_tags[,2])#另存为数据,使不破坏原数据
2.引用中文分词处理所需要的的包
library(jiebaR)
library(jiebaRD)
3.对所有中文标题进行分词
seg_engine = worker()#固定分词句式,定义环境
seg_question = segment(question_titles$question_title,seg_engine) # 对所有的标题进行中文分词。
如果有停用词文档的话也可以直接在环境中输入文档
engine = worker(stop_word = "stopwordsC.txt")
4.生成频数表并对内容进行排序
questionFreq = as.data.frame(table(seg_question))# 生成频数表
questionFreq = questionFreq[order(-questionFreq$Freq),]#排序
5.去除停用词
除了前面介绍的在环境中直接去除停用词的方法外,也可以用语句的方式去除停用词
#去除停用词
stopwords = read.table("stopwordsC1.txt",header = FALSE)
cleaned_questionFreq = questionFreq
for(word in questionFreq$seg_question){
if(word %in% stopwords$V1){#如果word出现在stopwords里(标题中的分词出现在停用词列表中)
cleaned_questionFreq = cleaned_questionFreq[-which(cleaned_questionFreq[,1]==word),]
}
}
6.补充处理
# 过滤关键词的最短长度,只有一个的词不留
cleaned_questionFreq = cleaned_questionFreq[-which(nchar(as.character(cleaned_questionFreq[,1]))<2),]
data = cleaned_questionFreq[1:100,]
7.制图
# 对柱子的顺序进行重新排列
data$seg_question = factor(data$seg_question,levels = data$seg_question)
ggplot(data,aes(x=seg_question,y=Freq))+
geom_bar(stat="identity")+
theme(axis.text.x = element_text(angle = 60,hjust = 1))+
xlab("关键字")+
ylab("频数")+
labs(title = '频率图--前100个问题标题的频繁词')
结果如图
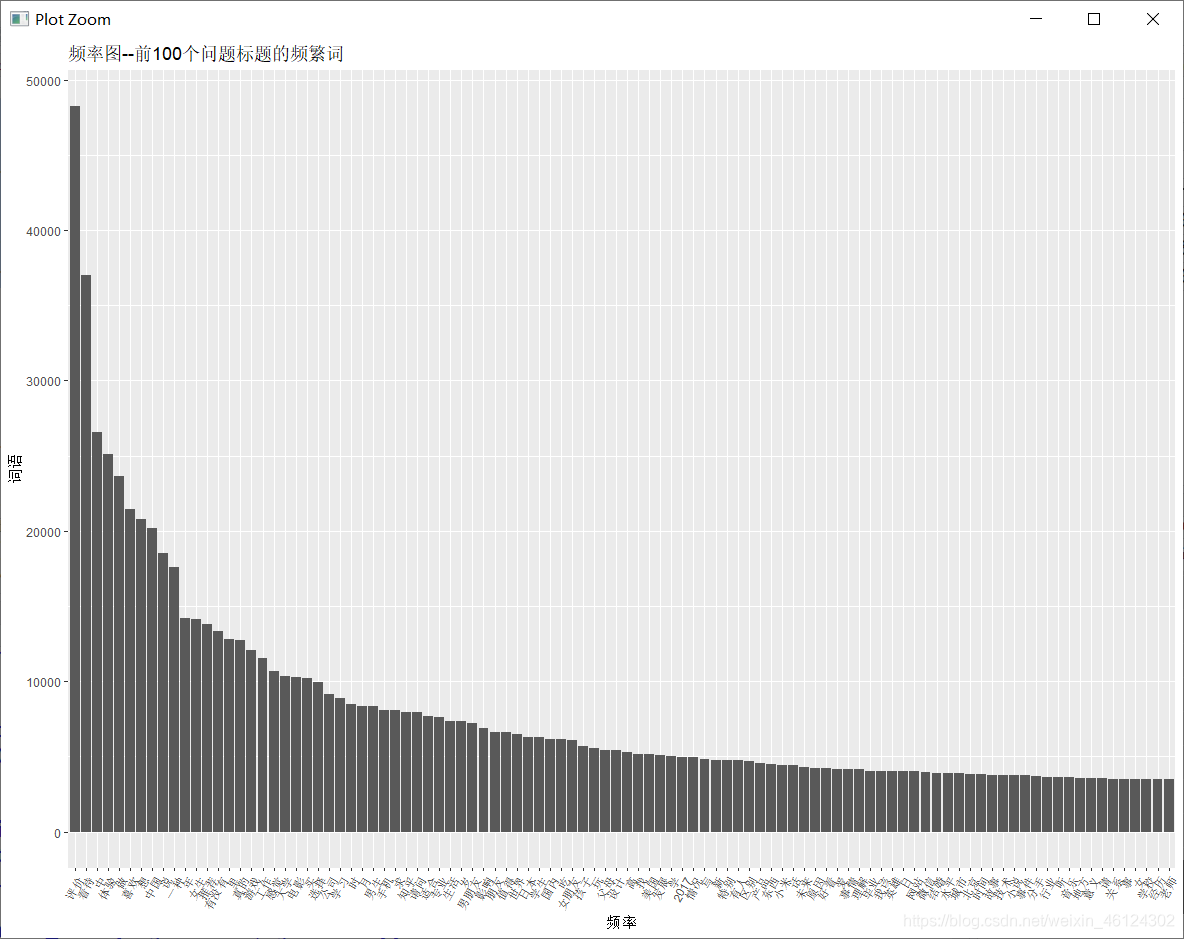
两次制图我们都用到了对柱子的顺序进行重新排列的方法
data$seg_question = factor(data$seg_question,levels = data$seg_question)
这里,x=data $ seg_question,levels = data$seg_question
对于x和levels,帮助中这样描述
x
a vector of data, usually taking a small number of distinct values.
一个向量数据,通常是一组数量不多的清晰数据
levels
an optional vector of the unique values (as character strings) that x
might have taken. The default is the unique set of values taken by
as.character(x), sorted into increasing order of x. Note that this set
can be specified as smaller than sort(unique(x)).
x的唯一值(作为字符串)的可选向量可能已经被拿走了。默认值是as.character(x),按x的递增顺序排序。注意这个集合
可以指定为小于sort(unique(x))
所以能起到排序效果。
最后附上本次学习中产生的全部代码↓
library(ggplot2)
library(readr)
# 工作路径
setwd("D://1Study//R//CH05")
# 读入数据
#data = read.csv("train_data.csv",header = TRUE) # read.csv不适合对大数据进行处理,速度太慢
data_tags = read_csv("train_data.csv") #read_csv读取大数据的时候效率更高
data_tags
# 以|为分隔符拆分Tag
tags_name = data_tags$tag_names#提取标签名这一栏
#####
# 使用R语言的字符串拆分函数 strsplit
# str ="张三;李四;王五"
# splited = strsplit(str,";")
# splited
#
# str ="张三|李四|王五"
# splited = strsplit(str,"|",fixed = TRUE)
# splited
#####
# 使用R语言的字符串拆分函数 strsplit
tags_name = strsplit(x=tags_name,split = "|",fixed = TRUE) # 按照|进行拆分
tags_name = unlist(tags_name) # 把拆分以后的数据重组成数据框
tagsFreq = as.data.frame(table(tags_name)) #生成频数表
# 排序一下
tagsFreq = tagsFreq[order(-tagsFreq$Freq),] # 按照tagsFre$Freq降序排列
data = tagsFreq[1:100,]
ggplot(data,aes(x=tags_name,y = Freq))+
geom_bar(stat = "identity")
ggplot(data,aes(x=tags_name,y = Freq))+
geom_bar(stat = "identity")+
theme(axis.text.x = element_text(angle = 60,hjust = 1))
# 对柱子的顺序进行重新排列
data$tags_name = factor(data$tags_name,levels = data$tags_name)
ggplot(data,aes(x=tags_name,y = Freq))+
geom_bar(stat = "identity")+
theme(axis.text.x = element_text(angle = 60,hjust = 1))+
xlab("关键字")+
ylab("频数")
######
#绘制问题标题的频繁词前100以及频率(先进行中文分词)
question_titles = data.frame(data_tags[,2])#另存为数据,使不破坏原数据
library(jiebaR)
library(jiebaRD)
seg_engine = worker()#固定分词句式,定义环境
#engine = worker(stop_word = "stopwordsC.txt")也可以
#print(segment("南京市长江大桥",seg_engine))
seg_question = segment(question_titles$question_title,seg_engine) # 对所有的标题进行中文分词。
#苹果电脑上可以设置一个参数
#win上结巴分词不能并行化,但是mac以及linux系统上可以并行分词,极大提高效率
#16G的语料,linux使用32核
questionFreq = as.data.frame(table(seg_question))# 生成频数表
questionFreq = questionFreq[order(-questionFreq$Freq),]#排序
#去除停用词
stopwords = read.table("stopwordsC1.txt",header = FALSE)
cleaned_questionFreq = questionFreq
for(word in questionFreq$seg_question){
if(word %in% stopwords$V1){#如果word出现在stopwords里(标题中的分词出现在停用词列表中)
cleaned_questionFreq = cleaned_questionFreq[-which(cleaned_questionFreq[,1]==word),]
}
}
# 过滤关键词的最短长度
cleaned_questionFreq = cleaned_questionFreq[-which(nchar(as.character(cleaned_questionFreq[,1]))<2),]
data = cleaned_questionFreq[1:100,]
# 对柱子的顺序进行重新排列
data$seg_question = factor(data$seg_question,levels = data$seg_question)
ggplot(data,aes(x=seg_question,y=Freq))+
geom_bar(stat="identity")+
theme(axis.text.x = element_text(angle = 60,hjust = 1))+
xlab("关键字")+
ylab("频数")+
labs(title = '频率图--前100个问题标题的频繁词')
以上是我对标签处理的全部理解,如果有误,欢迎批评指正。















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









