









声明: 1. 本文为我的个人复习总结, 并非那种从零基础开始普及知识 内容详细全面, 言辞官方的文章
2. 由于是个人总结, 所以用最精简的话语来写文章
3. 若有错误不当之处, 请指出
整理了大数据领域常用的15个软件的安装, 除了最后4个 其他都有对应的安装包, 这4个以后会进行补充;
不同版本的安装包可能有不同的安装配置方式, 为了不必要的报错, 请使用和我一样版本的安装包 以及 Linux系统
目录:
- Linux
- JDK
- MySQL
- Hadoop
- ZooKeeper
- Hive
- Flume
- Kafka
- HBase-Phoenix
- Scala
- Spark
- Redis
- ClickHouse
- Flink
- ElasticSearch
01. Linux基础配置
Linux(CentOS-7.6-x64位)基础配置, 虚拟机平台VmWare15
CentOS-7.6-x64镜像下载–> 百度云链接: https://pan.baidu.com/s/1iWfsCydjEU6soT7HO2OYRA 提取码:1111
VmVare15安装包下载–> 百度云链接: https://pan.baidu.com/s/1SfaWn3xpwDBNEGYqipRtaw 提取码:1111
-
虚拟机网络配置好,使用静态ip, 确保网关(ip地址如 192.168.80.86 的前3段 192.168.80 为网关 )使用正确, 和虚拟网卡一致
-
VmWare的虚拟网络编辑器里
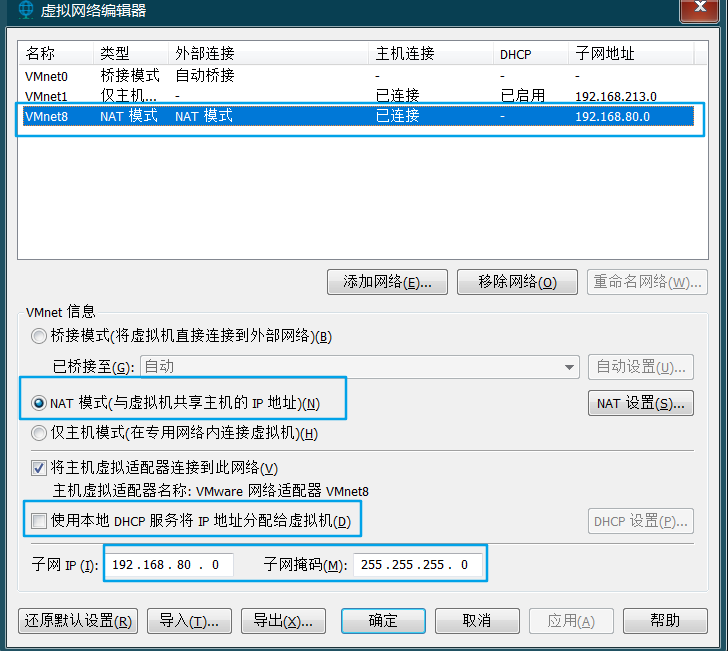
-
点开上图的NAT设置
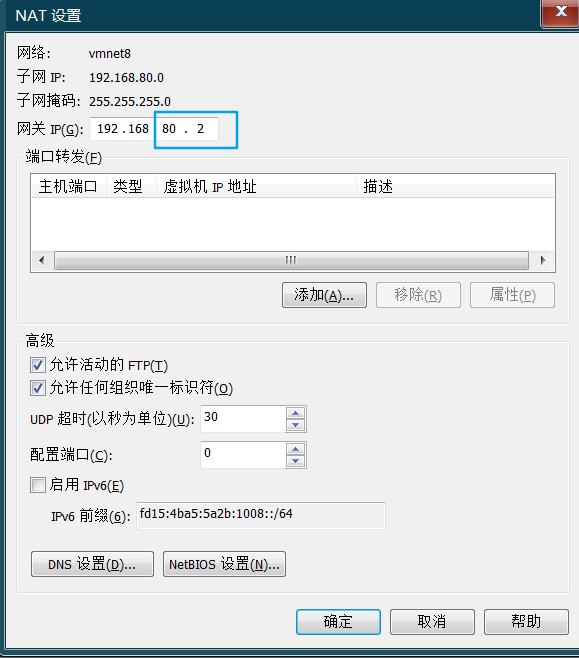
> > > 与前一张图同网段, 网关为.2, 因为.1给Windows的虚拟网卡了 > >-
确认要启动的虚拟机的网络适配器类型是NAT模式
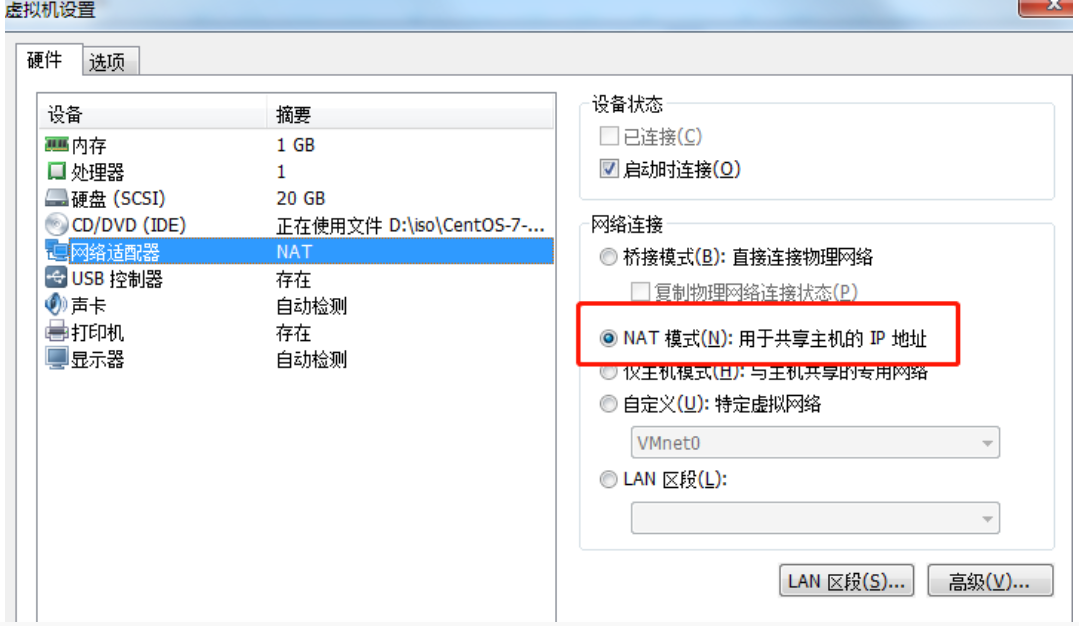
-
修改虚拟机配置文件
vi /etc/sysconfig/network-scripts/ifcfg-ens33DEVICE=“eth0”
BOOTPROTO=“static”
HWADDR=“00:0C:29:83:7F:54”
IPV6INIT=“yes”
NM_CONTROLLED=“yes”
ONBOOT=“yes”TYPE=“Ethernet”
UUID=“aae85c0a-42db-4772-b940-0fc9c875afd2”IPADDR=192.168.80.86 (同网段,别选.0, .1, .2)
GATEWAY=192.168.80.2
NETMASK=255.255.255.0
DNS1=192.168.80.2 (和网关一样即可)
DNS2=114.114.114.114
-
重启网络服务
systemctl restart network
-
-
yum下载 相关必备的软件包
yum install -y rsync gcc gcc-c++ vim wget perl ntp ntpdate net-tools lrzsz libaio -
配置hosts文件
vim /etc/hosts192.168.80.11 hadoop102 192.168.80.12 hadoop103 192.168.80.13 hadoop104windows的hosts文件也配置一下,配完别忘了保存文件, 它在 C:\WINDOWS\System32\drivers\etc 目录下
-
配置SSH免密登录
-
执行ssh-keygen -t rsa (一直回车)生成公钥私钥
-
cd ~/.ssh
-
在 ~/.ssh目录下 ssh-copy-id hadoop102 ssh-copy-id hadoop103
ssh-copy-id hadoop104 (hadoop104访问不通hadoop102时,在hadoop104上执行这些命令)
-
-
脚本编写:
-
自己编写xsync.sh脚本(放在家目录下,家目录配置到环境变量/etc/profile的Path里),对rsync做封装,在集群间发送拷贝文件
修改的配置文件必须source一下才能生效
export PATH=$PATH:~/binxsync.sh的编写
#!/bin/bash #1. 判断参数个数 if [ $# -lt 1 ] then echo Not Enough Arguement! exit; fi #2. 遍历集群所有机器 for host in hadoop102 hadoop103 hadoop104 do echo ==================== $host ==================== #3. 遍历所有目录,挨个发送 for file in $@ do #4 判断文件是否存在 if [ -e $file ] then #5. 获取父目录 pdir=$(cd -P $(dirname $file); pwd) #6. 获取当前文件的名称 fname=$(basename $file) ssh $host "mkdir -p $pdir" rsync -av $pdir/$fname $host:$pdir else echo $file does not exists! fi done donecd 软连接, pwd一下显示是软连接指向的实际文件所在目录; 而 cd -P 软连接, pwd一下显示的是软连接所在目录
chmod +x xsync.sh
-
转发命令脚本all
#!/bin/bash for i in hadoop102 hadoop103 hadoop104 do echo --------- $i ---------- ssh $i "$*" donechmod +x all
-
-
关闭并禁用防火墙自启
systemctl stop firewalld && systemctl disable firewalld -
调整时间为网络时间, 时间同步
ntpdate ntp.aliyun.comhwclock --systohc
最好现在创建下快照,保留最基础配置,以后可以多次测试练习
02. JDK安装配置
Linux下 OpenJDK1.8 的安装与环境变量配置
安装包下载–> 百度云链接: https://pan.baidu.com/s/1aN9VVMYc9_Fw_xq0Q-lOxA 提取码:1111
-
解压到指定目录并修改名字为 /opt/module/jdk-1.8
-
配置环境变量
vim /etc/profile.d/jdk.sh -
检查是否安装成功
java -version -
配置环境变量
vim /etc/profile.d/jdk.sh# JAVA export JAVA_HOME=/opt/module/jdk-1.8 export PATH=$PATH:$JAVA_HOME/binsource /etc/profile.d/jdk.sh chmod 755 /tmp/hsperfdata_* -
xsyn.sh同步分发
集群同步分发文件
集群同步分发配置文件/etc/profile.d/jdk.sh的话,还要source一下
03. MySQL安装配置
MySQL 5.7.16 安装配置, 默认连接端口3306
安装包下载–> 百度云链接: https://pan.baidu.com/s/19PlQdOiInNxXzFpGDqjhHA 提取码:1111
-
检查是否曾经安装过mysql
rpm -qa|grep mariadb # 若有,则卸载 rpm -e --nodeps mariadb-libs -
检查mysql的以依赖环境 libaio和 net-tools 和 perl
rpm -qa|grep libaio rpm -qa|grep net-tools rpm -qa|grep perl # 若没有,可以到自带的media光盘里找安装包进行安装 -
授予文件夹读写可执行权限
# 由于mysql安装过程中,会通过mysql用户在/tmp目录下新建tmp_db文件,所以请给/tmp较大的权限 chmod -R 777 /tmp -
安装, 用rpm安装, 或者用简易的tar.gz安装
# 在mysql的安装文件目录下执行:(必须按照顺序执行) rpm -ivh mysql-community-common-5.7.16-1.el7.x86_64.rpm rpm -ivh mysql-community-libs-5.7.16-1.el7.x86_64.rpm rpm -ivh mysql-community-client-5.7.16-1.el7.x86_64.rpm rpm -ivh mysql-community-server-5.7.16-1.el7.x86_64.rpm -
检查是否安装成功
mysqladmin --version -
mysql服务的初始化
mysqld --initialize --user=mysql # 查看密码: cat /var/log/mysqld.log | grep root@localhost # root@localhost: 后面就是初始化的密码, :+空格+密码 -
服务开停
启动: systemctl start mysqld 关闭: systemctl stop mysqld 自启动: systemctl enable mysqld (mysqld.service) -
首次登录
# 登陆后修改密码,不然用初始密码做不了事 ALTER USER 'root'@'localhost' IDENTIFIED BY 'root12345'; # 然后退出,用新密码重新登录 -
mysql的安装目录
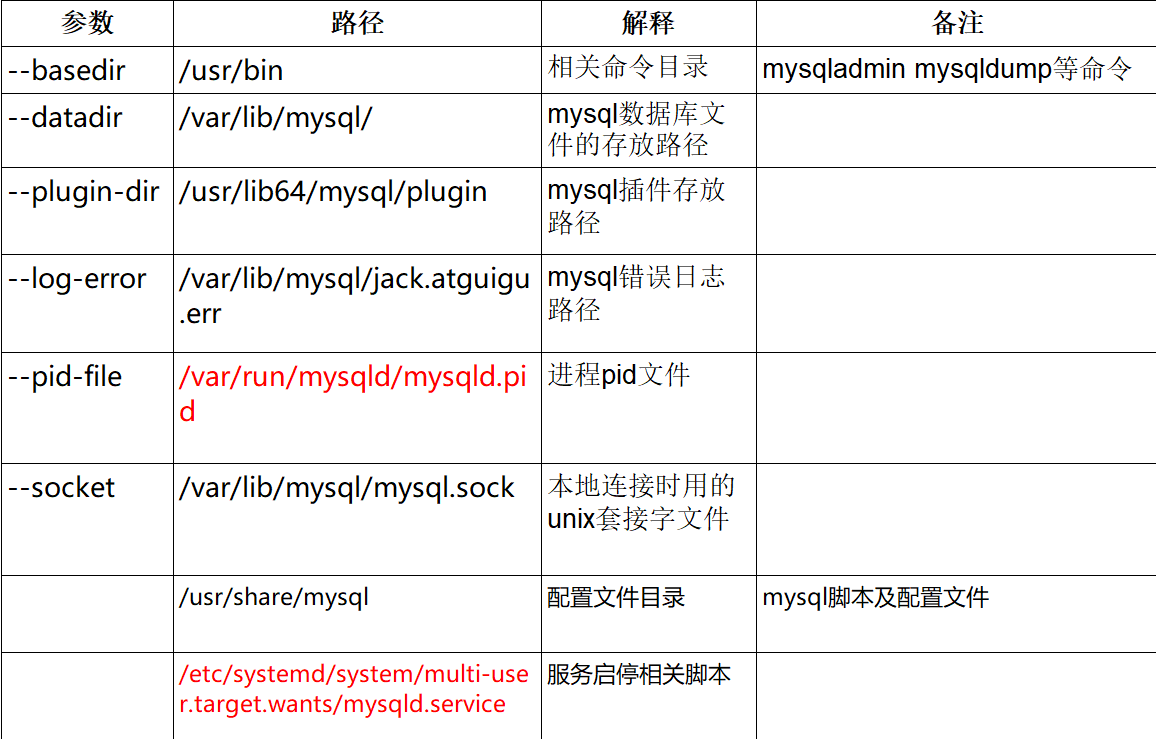
-
开启允许远程访问
grant all privileges on *.* to root@'%' identified by 'root12345';flush privileges; -
sqlmode
show variables like ‘sql_mode’;
set sql_mode=‘ONLY_FULL_GROUP_BY’;sql_mode常用值如下:
-
ONLY_FULL_GROUP_BY:
对于GROUP BY聚合操作,如果在SELECT中的列,没有在GROUP BY中出现,那么这个SQL是不合法的,因为列不在GROUP BY从句中 -
NO_AUTO_VALUE_ON_ZERO:
该值影响自增长列的插入。默认设置下,插入0或NULL代表生成下一个自增长值。如果用户 希望插入的值为0,而该列又是自增长的,那么这个选项就有用了。 -
STRICT_TRANS_TABLES:
在该模式下,如果一个值不能插入到一个事务表中,则中断当前的操作,对非事务表不做限制
NO_ZERO_IN_DATE:
在严格模式下,不允许日期和月份为零 -
NO_ZERO_DATE:
设置该值,mysql数据库不允许插入零日期,插入零日期会抛出错误而不是警告。 -
ERROR_FOR_DIVISION_BY_ZERO:
在INSERT或UPDATE过程中,如果数据被零除,则产生错误而非警告。如 果未给出该模式,那么数据被零除时MySQL返回NULL -
NO_AUTO_CREATE_USER:
禁止GRANT创建密码为空的用户 -
NO_ENGINE_SUBSTITUTION:
如果需要的存储引擎被禁用或未编译,那么抛出错误。不设置此值时,用默认的存储引擎替代,并抛出一个异常 -
PIPES_AS_CONCAT:
将"||"视为字符串的连接操作符而非或运算符,这和Oracle数据库是一样的,也和字符串的拼接函数Concat相类似 -
ANSI_QUOTES:
启用ANSI_QUOTES后,不能用双引号来引用字符串,因为它被解释为识别符 -
ORACLE: 设置等同PIPES_AS_CONCAT,ANSI_QUOTES,IGNORE_SPACE,
NO_KEY_OPTIONS, NO_TABLE_OPTIONS, NO_FIELD_OPTIONS, NO_AUTO_CREATE_USER
-
-
修改字符集
vim /etc/my.cnf
在最后加上中文字符集配置 character_set_server=utf8mb4, 重启mysql
对已经存在的库修改: alter database mydb character set ‘utf8mb4’;
对已经存在的表修改: alter table mytbl convert to character set ‘utf8mb4’;
对已经存在的数据,若要修改只能删除这条数据重新输入了
然后重启mysqld服务 systemctl restart mysqld.service
-
mysql报错
-
Can’t connect to local MySQL server through socket ‘/var/run/mysqld/mysqld.sock’
解决办法: 配置文件的mysqld下指明socket实际路径,比如加上socket = /var/lib/mysql/mysql.sock
-
[ERROR] Plugin ‘InnoDB’ init function returned error.
[ERROR] Plugin ‘InnoDB’ registration as a STORAGE ENGINE failed.
解决办法: 吧/var/lib/mysql下ib_logfile开头的文件删除掉
- mysql启动失败时,可以把var/run/mysqld目录删了重建
-
-
maxwell时配置
server-id=1
log-bin=master
binlog_format=row
启动mysqld的命令: /usr/sbin/mysqld --user=root
04. Hadoop集群搭建
Hadoop[3.1.3] 完全分布式模式搭建配置
安装包下载 --> 百度云链接: https://pan.baidu.com/s/1HDEF-JoWfD-Nj_9rEkyyBg 提取码:1111
-
解压到指定目录并修改名字为 /opt/module/hadoop-3.1.3
-
配置环境变量 vim /etc/profile.d/hdp.sh
#HADOOP export HADOOP_HOME=/opt/module/hadoop-3.1.3 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin
Hadoop重要目录
(1)bin目录:存放对Hadoop相关服务(HDFS,YARN)进行操作的脚本
(2)etc目录:Hadoop的配置文件目录
(3)lib目录: 存放Hadoop的本地库(对数据进行压缩解压缩功能)
(4)sbin目录:存放启动或停止Hadoop相关服务的脚本
(5)share目录:存放Hadoop的依赖jar包、文档、和官方案例
Hadoop的运行模式:
- 本地模式: 非分布式, 无需任何配置, 直接简单的Java进程运行, 无需启动 HDFS&Yarn
- 伪分布式模式: HDFS&Yarn都在同一台机器的同一个Hadoop上
- 完全分布式模式: HDFS&Yarn在不同机器的不同Hadoop上
集群规划部署:
-
NameNode和SecondaryNameNode不要安装在同一台服务器
-
ResourceManager也很消耗内存,不要和NameNode、SecondaryNameNode配置在同一台机器上
-
hadoop103至少给cpu (1*2)个,8g内存, 因为Yarn太耗资源
hadoop102 hadoop103 hadoop104 HDFS NameNode DataNode DataNode SecondaryNameNode DataNode YARN NodeManager ResourceManager NodeManager NodeManager
配置文件:
在$HADOOP_HOME/etc/hadoop/hadoop-env.sh里添加
export JAVA_HOME=/opt/module/jdk-1.8
在$HADOOP_HOME/etc/hadoop/workers里写上: (别有多余空格空行)
hadoop102
hadoop103
hadoop104
四类配置文件: core, hdfs, mapred, yarn, 对于site文件间,大部分都配置在哪个-site.xml都一样,但核心重要配置还是放到core-site.xml下
core-site.xml:
<configuration>
<!--存储目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!--允许的主机,用户,和组-->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 运行hadoop fs -ls 命令显示本地目录问题解决-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
</property>
</configuration>
hdfs-site.xml:
<configuration>
<!--负数,0代表不开启安全模式,大于等于1代表开启安全模式 -->
<property>
<name>dfs.safemode.threshold.pct</name>
<value>0</value>
</property>
<!--secondnode的地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
<!-- nn web 端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<!-- 指定HDFS副本的数量,默认为3 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
mapred.xml:
<configuration>
<!-- 指明MR在哪里运行 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
</property>
<!-- 怕找不到classpath -->
<property>
<name>mapreduce.application.classpath</name>
<value>
${HADOOP_HOME}/etc/hadoop,
${HADOOP_HOME}/share/hadoop/common/*,
${HADOOP_HOME}/share/hadoop/common/lib/*,
${HADOOP_HOME}/share/hadoop/hdfs/*,
${HADOOP_HOME}/share/hadoop/hdfs/lib/*,
${HADOOP_HOME}/share/hadoop/mapreduce/*,
${HADOOP_HOME}/share/hadoop/mapreduce/lib/*,
${HADOOP_HOME}/share/hadoop/yarn/*,
${HADOOP_HOME}/share/hadoop/yarn/lib/*
</value>
</property>
</configuration>
yarn-site.xml:
<configuration>
<!--单个Task容器的最小最大内存-->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<!--NodeManager总内存-->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<!--虚拟内存检测关掉, jdk8检测内存会和centos7检测内存冲突-->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 日志服务器 -->
<property>
<name>yarn.timeline-service.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.timeline-service.hostname</name>
<value>${yarn.resourcemanager.hostname}</value>
</property>
<property>
<name>yarn.timeline-service.http-cross-origin.enabled</name>
<value>true</value>
</property>
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址(把每个机器的日志放到一块) -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为 7 天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<!-- yarn的ip:port -->
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop103:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop103:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop103:8031</value>
</property>
<!-- 怕找不到类路径 -->
<property>
<name>yarn.application.classpath</name>
<value>/opt/module/hadoop-3.1.3/etc/hadoop:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/common/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn:/opt/module/hadoop-3.1.3/share/hadoop/yarn/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn/*</value>
</property>
<!-- 指定 ResourceManager 的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<!-- 指定 MR 走 shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME
</value>
</property>
</configuration>
安全用户:
1、对于start-dfs.sh和stop-dfs.sh文件,添加下列参数:
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
2、对于start-yarn.sh和stop-yarn.sh文件,添加下列参数:
YARN_RESOURCEMANAGER_USER=rootHADOOP_SECURE_DN_USER=yarnYARN_NODEMANAGER_USER=root
启动集群
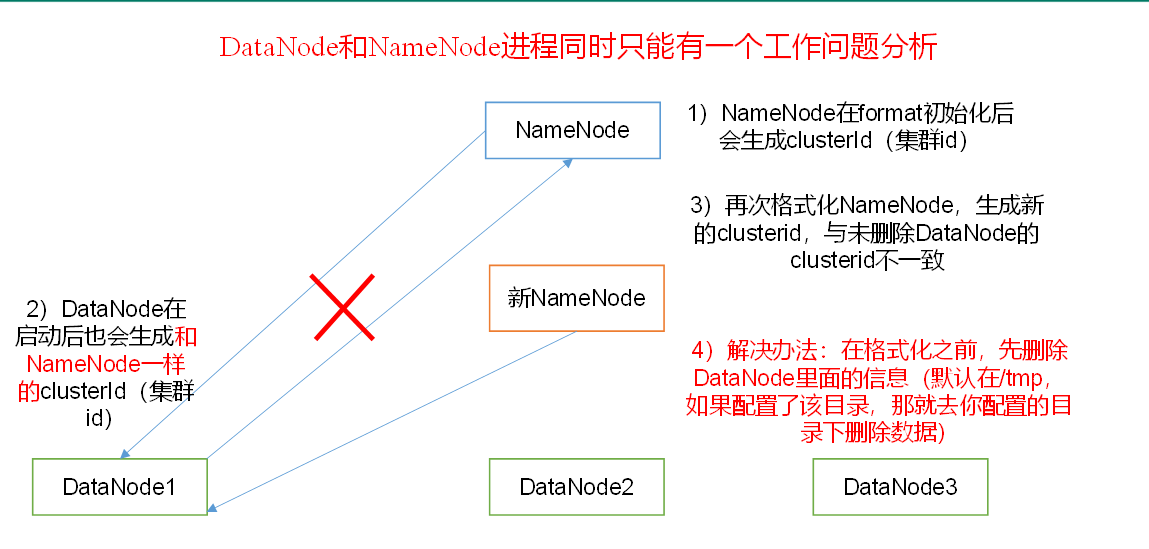
1. 格式化:
第一次启动时在hadoop102格式化NameNode, 如果格式化失败,需要杀死所有的hadoop进程,然后删除指定的本地data目录 (防止重新格式化生成的clusterId和data目录下老的clusterId不一致)
hdfs namenode -format
2. xsync.sh集群分发
集群同步分发文件
集群同步分发配置文件/etc/profile.d/hdp.sh的话,还要source一下
3. 启动停止命令:
sbin/start-all.sh
sbin/start-dfs.sh
sbin/start-yarn.sh
sbin/mr-jobhistory-daemon.sh start historyserver
hdfs --daemon start namenode/datanode/secondarynamenode
yarn --daemon start resourcemanager/nodemanager
4.测试官方案例wordcount
编写wc.txt 上传到HDFS上, 计算结果放到HDFS的/out下, 若能计算成功, 则说明安装配置OK了
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /wc.txt /out
5. Web端访问:
- 查看NN http://hadoop102:9870/
- 查看2NN http://hadoop104:9868/status.html
- 查看MR的日志 http://hadoop102:19888/jobhistory
- 查看Yarn的监控日志(更全,不只有MR) http://hadoop103:8088/
05. ZooKeeper集群搭建
ZooKeeper [3.5.7] 部署有单机部署版和集群部署版, 默认连接端口号2181
安装包下载–> 百度云链接: https://pan.baidu.com/s/1PsiwnwILw8pk_gDh726tIw 提取码:1111
-
单机版
-
解压到指定目录并修改名字为 /opt/module/zookeeper-3.5.7
-
配置环境变量
vim /etc/profile.d/zk.sh# ZOOKEEPER export ZOOKEEPER_HOME=/opt/module/zookeeper-3.5.7 export PATH=$PATH:$ZOOKEEPER_HOME/binsource /etc/profile.d/zk.sh -
创建ZooKeeper所需要的工作目录
mkdir /opt/module/zookeeper-3.5.7/zkData -
复制模板生成配置文件
cp /opt/module/zookeeper-3.5.7/conf/zoo_sample.cfg /opt/module/zookeeper-3.5.7/conf/zoo.cfg -
编辑配置文件
vim /opt/module/zookeeper-3.5.7/conf/zoo.cfg#修改如下内容: dataDir=/opt/module/zookeeper-3.5.7/zkData -
ZooKeeper的启动和停止
服务端启动: /opt/module/zookeeper-3.5.7/bin/zkServer.sh start
服务端状态查看: /opt/module/zookeeper-3.5.7/bin/zkServer.sh status
服务端关闭: /opt/module/zookeeper-3.5.7/bin/zkServer.sh stop
jps一下出现:
4020 Jps 4001 QuorumPeerMain #即为ZooKeeper进程
客户端启动: /opt/module/zookeeper-3.5.7/bin/zkCli.sh
客户端退出: quit
-
-
集群版
在配置完单机版的基础上, 在每个机器的 /opt/module/zookeeper-3.5.7/zkData下新建一个myid的文件,里面写上自己的id(整数, 不重复就行)
然后在配置文件/opt/module/zookeeper-3.5.7/conf/zoo.cfg下添加
#######################cluster##########################server.2=hadoop102:2888:3888server.3=hadoop103:2888:3888server.4=hadoop104:2888:3888#以server.2=hadoop102:2888:3888为例, 2指的是myid的id号,#2888端口是这个服务器Follower与集群中的Leader服务器交换信息的端口,#3888端口是选举时通讯要用的端口集群同步分发文件后别忘了修改myid文件,使每个机器的id都不一样,
集群同步分发配置文件/etc/profile.d/zk.sh的话,还要source一下
客户端基本命令:
命令基本语法 功能描述 help 显示所有操作命令 ls path 使用 ls 命令来查看当前znode的子节点 -w 监听子节点变化 -s 附加次级信息 create 普通创建 -s 含有序列 -e 临时(重启或者超时消失) get path 获得节点的值 -w 监听节点内容变化 -s 附加次级信息 set 设置节点的具体值 stat 查看节点状态 delete 删除节点 deleteall 递归删除节点
配置文件解读:
1)tickTime =2000:通信心跳数,ZooKeeper服务器与客户端心跳时间,单位毫秒
ZooKeeper使用的基本时间,服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个tickTime时间就会发送一个心跳,时间单位为毫秒。
它用于心跳机制,并且设置最小的session超时时间为两倍心跳时间。(session的最小超时时间是2*tickTime)
2)initLimit =10:LF初始通信时限
Follwer和Leader超过 initLimit * tickTime还没初始连接时连接上进行通信,即踢出Follwer
3)syncLimit =5:LF同步通信时限
Follwer和Leader超过 syncLimit * tickTime还没成功进行同步,即踢出Follwer
4)dataDir:数据文件目录**+**数据持久化路径
主要用于保存ZooKeeper中的数据。
5)clientPort =2181:服务端端口
06. Hive安装配置
Hive [3.1.2] 部署有客户端进行 直接本地连接, 以metastore服务方式本地连接,
和hiveserver2-JDBC远程连接(端口号10000)3种
Hive安装包下载–> 百度云链接: https://pan.baidu.com/s/1NrCB-Qi-hO0n8EfHnu3HLw 提取码:1111
MySQL的JDBC连接驱动包下载–> 百度云链接: https://pan.baidu.com/s/1u_vThTJI0z-oP2pPOODJ9g 提取码:1111
依赖于Hadoop的HDFS和MapReduce, 所以请先启动Hadoop的HDFS和Yarn
-
直接本地连接
-
解压到指定目录并修改名字为 /opt/module/hive-3.1.2
-
配置环境变量
vim /etc/profile.d/hive.sh# HIVE export HIVE_HOME=/opt/module/hive-3.1.2 export PATH=$PATH:$HIVE_HOME/binsource /etc/profile.d/h.sh -
解决日志jar包冲突, 在Hive的lib下
mv log4j-slf4j-impl-2.10.0.jar log4j-slf4j-impl-2.10.0.jar.bak -
不以默认的derby作为元数据库,以mysql作为元数据库,首先在lib下添加mysql的jdbc驱动包(如果你用的是我给你的安装包,就不用执行这一步了,因为我给你的是我修改后重新打包的,已经做好这一步了)
-
mysql下新建一个库,我这里命名为metastore,你也可以用其他名字
-
在conf 目录下新建 hive-site.xml 文件,注意修改里面的jdbc(用户名,密码,url,驱动)配置
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- jdbc 连接的 URL, 这里用的库,是上面创建的 放元数据的库metastore--> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false</value> </property> <!-- jdbc 连接的 Driver--> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <!-- jdbc 连接的 username--> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <!-- jdbc 连接的 password --> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>root12345</value> </property> <!-- Hive 元数据存储版本的验证 --> <property> <name>hive.metastore.schema.verification</name> <value>false</value> </property> <!--元数据存储授权--> <property> <name>hive.metastore.event.db.notification.api.auth</name> <value>false</value> </property> <!--显示 当前库--> <property> <name>hive.cli.print.current.db</name> <value>true</value> </property> <!--显示 当前表头--> <property> <name>hive.cli.print.header</name> <value>true</value> </property> <!-- Hive 默认在 HDFS 的工作目录 --> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> </property> <!-- <property> <name>hive.exec.mode.local.auto</name> <value>true</value> </property> --> </configuration> -
初始化 Hive 元数据库
schematool -initSchema -dbType mysql - verbose -
启动Hive
bin/hive #即可进入到类似于mysql的命令行, 可以写sql 测试: show databases; use default; create table test (id int); insert into test values(1); select * from test;
-
-
以metastore服务方式本地连接
在做完上面本地连接的基础上
-
在 hive-site.xml 文件中添加如下配置信息
<!-- 指定存储元数据服务所在的地址 --> <property> <name>hive.metastore.uris</name> <value>thrift://hadoop102:9083</value> </property> -
启动metastore
hive --service metastore
-
-
以hiveserver2的JDBC服务方式远程连接
在做完上面本地连接的基础上,因为hiveserver2依赖于metastore
-
在 hive-site.xml 文件中添加如下配置信息
<!-- 指定 hiveserver2 连接的 host --><property><name>hive.server2.thrift.bind.host</name><value>hadoop102</value></property><!-- 指定 hiveserver2 连接的端口号 --><property><name>hive.server2.thrift.port</name><value>10000</value></property> -
修改hiveserver2堆内存配置,
在bin/hive-config.sh下面:
export HADOOP_HEAPSIZE=${HADOOP_HEAPSIZE:-256}
改为export HADOOP_HEAPSIZE=${HADOOP_HEAPSIZE:-1500}
-
先启动metastore服务, hive --service metastore
再启动hiveserver2服务 hive --service hiveserver2 (等待较为漫长)
服务端启动完毕后,即可开始进行客户端远程访问
客户端执行 bin/beeline -u jdbc:hive2://hadoop102:10000 -n root 名字为HDFS里设置的用户名字
-
07. Flume安装配置
Flume [1.9.0] 安装配置
安装包下载–> 百度云链接: https://pan.baidu.com/s/1BtYeNNRwa0yxv2dEfMWhww 提取码:1111
-
解压到指定目录并修改名字为 /opt/module/flume-1.9.0
-
将lib文件夹下的guava-11.0.2.jar删除以兼容Hadoop 3.1.3
rm -f /opt/module/flume-1.9.0/lib/guava-11.0.2.jar -
测试
-
安装nc
yum install -y nc -
在flume目录下创建job并进入
-
新建编辑 flume-netcat-logger.conf配置文件
# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 # Describe the sink a1.sinks.k1.type = logger # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 -
在flume目录下启动flume
bin/flume-ng agent -c conf/ -n a1 -f job/flume-netcat-logger.conf -Dflume.root.logger=INFO,console -
新建一个终端 向44444端口发送数据, 观察flume控制台采集数据打印情况
nc -lk 44444
-
08. Kafka集群搭建
Kafka [2.11-0.11.0.0] 集群搭建
安装包下载–> 百度云链接: https://pan.baidu.com/s/1sLSqZEisEfcNiACTEF-0Mw 提取码:1111
依赖于ZooKeeper,先启动ZooKeeper
集群搭建
解压到指定目录并修改名字为 /opt/module/kafka_2.11-0.11.0.0
配置环境变量
vim /etc/profile.d/kfk.sh# KAFKA export KAFKA_HOME=/opt/module/kafka_2.11-0.11.0.0 export PATH=$PATH:$KAFKA_HOME/binsource /etc/profile.d/kfk.sh在/opt/module/kafka_2.11-0.11.0.0 目录下创建logs文件夹
修改配置文件 config/server.properties
#修改: #broker的全局唯一编号,不能重复 broker.id=2 log.dirs=/opt/module/kafka_2.11-0.11.0.0/logs #配置连接Zookeeper集群地址 zookeeper.connect=hadoop102:2181/kafka #zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka #添加: #删除topic功能使用 delete.topic.enable=true #配置允许远程访问 listeners=PLAINTEXT://:9092 advertised.listeners=PLAINTEXT://hadoop101:9092 #其他说明 #num.partitions=1 topic在当前broker上的分区个数 #log.retention.hours=168 segment文件保留的最长时间, 超时将被删除分发配置文件/etc/profile.d/kfk.sh并source, 分发kafka, 再修改broker.id使每个机器的broker.id都不一样
先启动ZooKeeper,
再启动Kafka kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
停止Kafka kafka-server-stop.sh
测试
创建一个topic
kafka-topics.sh --zookeeper hadoop102:2181/kafka --create --replication-factor 3 --partitions 1 --topic demo 生产者发送消息
kafka-console-producer.sh --broker-list hadoop102:9092 --topic demo 消费者消费消息
kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --from-beginning --topic demo
09. HBase-Phoenix集群搭建
HBase [2.2.7] 集群搭建, Phoenix版本5.0.0
安装包下载–> 百度云链接: https://pan.baidu.com/s/1W8Szu4MAWTSZW3ursz8RGQ 提取码:1111
依赖于ZooKeeper,HDFS, 先启动ZooKeeper和HDFS
HBase集群搭建
解压到指定目录并修改名字为 /opt/module/hbase-2.2.7-bin-phoenix5.0.0
配置环境变量
vim /etc/profile.d/hbase.sh# HBASE export HBASE_HOME=/opt/module/hbase-2.2.7 export PATH=$PATH:$HBASE_HOME/binsource /etc/profile.d/hbase.sh编辑conf下的 hbase-env.sh, 添加
export HBASE_MANAGES_ZK=false export JAVA_HOME=/opt/module/jdk-1.8编辑conf下的hbase-site.xml
<configuration> <property> <name>hbase.rootdir</name> <value>hdfs://hadoop102:8020/hbase</value> </property> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>hadoop102,hadoop103,hadoop104</value> </property> <property> <name>hbase.tmp.dir</name> <value>./tmp</value> </property> <property> <name>hbase.unsafe.stream.capability.enforce</name> <value>false</value> </property> <property> <name>hbase.wal.provider</name> <value>filesystem</value> </property> </configuration>编辑conf下的reginservers
hadoop102 hadoop103 hadoop104软连接Hadoop配置文件到HBase:
ln -s /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml /opt/module/hbase-2.2.7/conf/core-site.xml ln -s /opt/module/hadoop-3.1.3/etc/hadoop/hdfs-site.xml /opt/module/hbase-2.2.7/conf/hdfs-site.xml分发配置文件/etc/profile.d/hbase.sh并source, 分发HBase
3台机器上都执行时间同步
ntpdate ntp.aliyun.com hwclock --systohc先启动ZooKeeper,
再启动HBase start-hbase.sh
停止HBase stop-hbase.sh
查看访问HBase的Web页面: http://hadoop102:16010
测试
HBase的Shell操作
hbase shelllistcreate 'student','info'put 'student','1001','info:sex','male'scan 'student'
Phoenix的使用
Phoenix是HBase的开源SQL皮肤。可以使用sql代替HBase客户端API来创建表,插入数据和查询HBase数据
我给的安装包是我已经集成了Phoenix之后重新打包的, 使用我的安装包 就不用从官网下载Phoenix了; 若使用官网的,则用附录里面的步骤安装配置
配置环境变量
vim /etc/profile.d/hbase.sh#PHOENIXexport PHOENIX_HOME=/opt/module/hbase-2.2.7/phoenixexport PHOENIX_CLASSPATH=$PHOENIX_HOMEexport PATH=$PATH:$PHOENIX_HOME/binsource /etc/profile.d/hbase.sh启动Phoenix
/opt/module/hbase-2.2.7/phoenix/bin/sqlline.py hadoop102,hadoop103,hadoop104:2181测试:
在sql命令行里,
!tablesCREATE TABLE "teacher"("username" VARCHAR(30) PRIMARY KEY);upsert into "teacher" values('zhangsan');select * from "teacher";
附录(官网下载Phoenix, 安装配置目录自己根据实际情况,不一样的地方修改一下):
安装bsdtar3
sudo yum install -y epel-releasesudo yum install -y bsdtar3上传并解压tar包(这里可能会报不识别的文件头,忽略即可,或者可以改用bsdtar)
tar -zxvf /opt/software/apache-phoenix-5.0.0-HBase-2.0-bin.tar.gz -C /opt/module
mv apache-phoenix-5.0.0-HBase-2.0-bin phoenix
复制server包并拷贝到各个节点的hbase-2.2.7/lib
复制client包并拷贝到各个节点的hbase-2.2.7/lib
配置环境变量
vim /etc/profile.d/hbase.sh#PHOENIXexport PHOENIX_HOME=/opt/module/phoenixexport PHOENIX_CLASSPATH=$PHOENIX_HOMEexport PATH=$PATH:$PHOENIX_HOME/binsource /etc/profile.d/hbase.sh启动Phoenix
/opt/module/phoenix/bin/sqlline.py hadoop102,hadoop103,hadoop104:2181
10. Scala安装配置
Linux下 Scala-2.12.11 的安装与环境变量配置
安装包下载–> 百度云链接: https://pan.baidu.com/s/1_KYhe95mcUqQBiqtQAkVBA 提取码:1111
-
解压到指定目录并修改名字为 /opt/module/scala-2.12.11
-
配置环境变量
vim /etc/profile.d/scala.sh# SCALA export SCALA_HOME=/opt/module/scala-2 export PATH=$PATH:$SCALA_HOME/binsource /etc/profile.d/scala.sh -
xsyn.sh同步分发
集群同步分发文件
集群同步分发配置文件/etc/profile.d/scala.sh的话,还要source一下
-
检查是否安装成功
scala -version
11. Spark集群搭建
Spark [3.0.0] 集群搭建, 有Local, Standalone,和Yarn三种模式
Spark安装包下载–> 百度云链接: https://pan.baidu.com/s/1LIMwN_MCevenyzDZsyVkhQ 提取码:1111
-
Local 模式:
-
解压到指定目录并修改名字为 /opt/module/spark-3.0.0-bin-hadoop3.2
-
配置环境变量
vim /etc/profile.d/spark.sh# SPARK export SPARK_HOME=/opt/module/spark-3.0.0-bin-hadoop3.2 export PATH=$PATH:$SPARK_HOME/binsource /etc/profile.d/spark.sh -
输入spark-shell即可进入交互界面
-
测试官方案例,计算圆周率的值
spark-submit --class org.apache.spark.examples.SparkPi --master local[2] /opt/module/spark-3.0.0-bin-hadoop3.2/examples/jars/spark-examples_2.12-3.0.0.jar 10
-
-
Standalone模式
在Local模式的配置的基础上
-
在conf下
mv slaves.template slaves mv spark-env.sh.template spark-env.shvim slaves
hadoop102 hadoop103 hadoop104vim spark-env.sh
export JAVA_HOME=/opt/module/jdk-1.8 SPARK_MASTER_HOST=hadoop102 SPARK_MASTER_PORT=7077 -
xsyn.sh同步分发
集群同步分发文件
集群同步分发配置文件/etc/profile.d/spark.sh的话,还要source一下
-
启动 sbin/start-all.sh
关闭 sbin/stop-all.sh
查看 Master 资源监控 Web UI 界面: http://hadoop102:8080
-
测试官方案例,计算圆周率的值
spark-submit --class org.apache.spark.examples.SparkPi --master spark://hadoop102:7077 /opt/module/spark-3.0.0-bin-hadoop3.2/examples/jars/spark-examples_2.12-3.0.0.jar 10
-
-
Yarn模式
在完成Standalone的基础上
-
vim spark-env.sh 添加
YARN_CONF_DIR=/opt/module/hadoop-3.1.3/etc/hadoop -
xsyn.sh同步分发
集群同步分发文件
集群同步分发配置文件/etc/profile.d/spark.sh的话,还要source一下
-
启动HDFS和Yarn, 然后执行sbin/start-all.sh 启动spark
-
测试官方案例,计算圆周率的值
spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster /opt/module/spark-3.0.0-bin-hadoop3.2/examples/jars/spark-examples_2.12-3.0.0.jar 10
-
12. Redis搭建
Redis6 有单机, 集群两种模式
一: 单机模式
解压
安装依赖
yum install -y centos-release-scl scl-utils-build gcc gcc-c++ yum install -y devtoolset-8-toolchain设置环境
scl enable devtoolset-8 bash进入redis根目录 make, 如果make失败, make distclean 是清除上一次的make
make #make distcleanmv src bin mkdir /opt/module/redis-6.0.6/logs/ touch /opt/module/redis-6.0.6/logs/redis.log修改redis.conf文件
vim redis.conf bind 127.0.0.1 注释掉它 protected-mode yes 改为 no daemonize no 改为 yes logfile "" 改为 logfile /opt/module/redis-6.0.6/logs/redis.log启动
bin/redis-server /xxx/redis.conf
- 进入客户端:
bin/redis-cli bin/redis-cli -h hadoop101 -p 6379 bin/redis-cli -h hadoop101 -p 6379 -a root12345
- 关闭
bin/redis-cli shutdown
13. ClickHouse安装配置
ClickHouse 安装配置, 默认连接端口8123
一: 单机模式
修改Linux本身的一些限制
vim /etc/security/limits.conf #添加 * soft nofile 65536 * hard nofile 65536 * soft nproc 131072 * hard nproc 131072 vim /etc/security/limits.d/20-nproc.conf #添加 * soft nofile 65536 * hard nofile 65536 * soft nproc 131072 * hard nproc 131072 vim /etc/selinux/config #修改 SELINUX=disabled安装依赖
sudo yum install -y libtool yum install -y *unixODBC*
方法一: rpm安装, 遇到输入user,直接回车跳过就好
rpm -ivh clickhouse-common-static-21.7.3.14-2.x86_64.rpm rpm -ivh clickhouse-common-static-dbg-21.7.3.14-2.x86_64.rpm rpm -ivh clickhouse-client-21.7.3.14-2.noarch.rpm rpm -ivh clickhouse-server-21.7.3.14-2.noarch.rpm
方法二: 执行命令进行yum在线安装:
sudo yum install yum-utils sudo rpm --import https://repo.clickhouse.tech/CLICKHOUSE-KEY.GPG sudo yum-config-manager --add-repo https://repo.clickhouse.tech/rpm/clickhouse.repo sudo yum install clickhouse-server clickhouse-client修改配置:
vim /etc/clickhouse-server/config.xml #添加 <listen_host>0.0.0.0</listen_host>启动
/etc/init.d/clickhouse-server start进入客户端
clickhouse-client #换行代表一条语句的结束 clickhouse-client -m #分号代表一条语句的结束, 但粘贴的语句里只能有一个分号若发生错误: Connecting to localhost:9000 as user default. Code: 210. DB::NetException: Connection refused (localhost:9000)
解决办法:
使用systemctl来启动停止, 而不是直接用原生/etc/init.d下的文件
sudo systemctl stop clickhouse-server
sudo systemctl start clickhouse-server
关闭
/etc/init.d/clickhouse-server stop重要文件:
- 数据文件: /var/lib/clickhouse/
- 日志文件: /var/log/clickhouse-server/clickhouse-server.log
14. Flink集群搭建
Flink [1.1.13] 集群搭建, 有Standalone,Yarn 和 Kubernetes三种模式
一: Standalone模式
解压
修改配置文件
vim conf/flink-conf.yaml # 修改 jobmanager.rpc.address: localhost 修改为对应的ip taskmanager.numberOfTaskSlots: 1 修改成4 vim conf/slaves #添加 hadoop101启动
bin/start-cluster.sh访问Web-UI http://localhost:8081
提交任务
bin/flink run examples/batch/WordCount.jar bin/flink run -c com.atguigu.wc.StreamWordCount myJar/flink-1-1.0-SNAPSHOT-jar-with-dependencies.jar关闭
bin/stop-cluster.sh
二: Yarn模式
在上述Standalone完成的基础上, 注意这时插槽等资源是Yarn动态分配的
先启动HDFS和YARN
再配置HADOOP_CLASSPATH环境变量, 并source
export HADOOP_CLASSPATH=`${HADOOP_HOME}/bin/hadoop classpath`参数:
-n(–container): TaskManager 的数量
-s(–slots): 每个TaskManager的slot数量, 默认每个TaskManager有1个slot, 一个slot一个core
-jm: JobManager 的内存(单位 MB)
-tm: 每个 taskmanager 的内存(单位 MB)。
-nm: 起个appName
-d: 后台执行
一: Session-Cluster 模式
启动一个永久的Flink集群, 每来一个job都放在这个集群运行 (不推荐)
启动, 它会创建一个 /tmp/.yarn-properties-root的临时文件
bin/yarn-session.sh -jm 1024 -tm 1024 -d访问http://localhost:8088/cluster 的Yarn界面中 任务列表的Tracking UI这一列即可进入到监控界面
提交任务
bin/flink run examples/batch/WordCount.jar bin/flink run -c com.atguigu.wc.StreamWordCount myJar/flink-1-1.0-SNAPSHOT-jar-with-dependencies.jar关闭
yarn application -kill application_1631431602106_0001二: yarn-per-job 模式
启动一个临时的Flink集群, 每来一个job都新开一个集群运行 (推荐, 任务间相互独立, 便于管理)
在提交任务时才新起集群
提交任务:
bin/flink run -t yarn-per-job -yjm 1024m -ytm 1024m examples/batch/WordCount.jar参数加上 -t yarn-per-job
jm变成yjm
tm变成ytm
15. ElasticSearch集群搭建
ElasticSearch 有单机, 集群两种模式
一: 单机模式
解压
创建Linux普通用户, 因为Elasticsearch不允许root用户直接运行
useradd es #新增es用户 passwd es #为es用户设置密码 chown -R es:es /opt/module/elasticsearch-7.8.0 #赋予用户访问目录权限修改配置
vim config/elasticsearch.yml # 加入如下配置 cluster.name: elasticsearch node.name: node-1 network.host: 0.0.0.0 http.port: 9200 cluster.initial_master_nodes: ["node-1"]vim /etc/security/limits.conf #增加 #每个进程可以打开的文件数的限制 es soft nofile 65536 es hard nofile 65536 vim /etc/security/limits.d/20-nproc.conf #增加 #每个进程可以打开的文件数的限制 es soft nofile 65536 es hard nofile 65536 #操作系统级别对每个用户创建的进程数的限制, *带表Linux所有用户名称 * hard nproc 4096 vim /etc/sysctl.conf #增加 #一个进程可以拥有的VMA(虚拟内存区域)的数量,默认值为65536 vm.max_map_count=655360刷新加载配置
sysctl -p切换es用户, 启动
su es bin/elasticsearch # -d代表后台启动 bin/elasticsearch -dWebUI访问: http://hadoop102:9200
二: 集群模式
其它跟单机模式一样
每台机器都要改Linux系统配置
修改elasticsearch配置文件:
vim config/elasticsearch.yml #增加 #集群名称 cluster.name: cluster-es #节点名称,每个节点的名称不能重复 node.name: node-1 #ip地址,每个节点的地址不能重复 network.host: hadoop102 #es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举 master cluster.initial_master_nodes: ["node-1"] # TODO #是不是有资格主节点 node.master: true node.data: true http.port: 9200 # head 插件需要这打开这两个配置 http.cors.allow-origin: "*" http.cors.enabled: true http.max_content_length: 200mb #es7.x 之后新增的配置,节点发现 discovery.seed_hosts: ["hadoop102:9300","hadoop103:9300","hadoop104:9300"] # TODO gateway.recover_after_nodes: 2 network.tcp.keep_alive: true network.tcp.no_delay: true transport.tcp.compress: true #集群内同时启动的数据任务个数,默认是 2 个 cluster.routing.allocation.cluster_concurrent_rebalance: 16 #添加或删除节点及负载均衡时并发恢复的线程个数,默认 4 个 cluster.routing.allocation.node_concurrent_recoveries: 16 #初始化数据恢复时,并发恢复线程的个数,默认 4 个 cluster.routing.allocation.node_initial_primaries_recoveries: 16















 516
516











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









