







Redis补充学习与主从复制和集群配置以及哨兵模式入门学习
一、redis那些数据结构
字符串String、字典Hash、列表List、集合Set、有序集合SortedSet。五种基本数据类型
1、SortedSet数据类型
它里面的元素是唯一的
Sorted Set里面的元素都带有一个浮点值,叫做分数(score),每个元素都映射到了一个分数。
Sorted Set是有序的,规则如下:
如果A.score > B.score,那么A > B。
如果A.score == B.score,那么A和B的大小就通过比较字符串来决定了,而A和B的字符串是不会相等的,因为Sorted Set里面的值都是唯一的。
2、存储SortedSet常用命令
zadd 添加元素 里面包括分数和值
127.0.0.1:6379> zadd sort1 5 a 4 b 6 c
(integer) 3
我们添加集合sort1 元素是a,b,c 评分分别是5,4,6
集合里的排序是根据评分从小到大排序的;
zrange是查找元素 -1代表是最后一个
127.0.0.1:6379> zrange sort1 0 -1
- “b”
- “a”
- “c”
假如我们继续添加元素
这里分两种情况
假如次元素集合里面已经有了,则覆盖
我们继续添加b 此时评分改成7
127.0.0.1:6379> zadd sort1 7 b
(integer) 0
通过zscore 获取b的评分
127.0.0.1:6379> zscore sort1 b
“7”
发现已经修改了;
127.0.0.1:6379> zrange sort1 0 -1
- “a”
- “c”
- “b”
假如添加的元素不在集合里,则添加进去
127.0.0.1:6379> zadd sort1 9 d
(integer) 1
127.0.0.1:6379> zrange sort1 0 -1
- “a”
- “c”
- “b”
- “d”
删除元素zrem
127.0.0.1:6379> zrem sort1 b
(integer) 1
127.0.0.1:6379> zrange sort1 0 -1
- “a”
- “c”
- “d”
zcard 查看集合里的元素个数
127.0.0.1:6379> zcard sort1
(integer) 3
withscores 把评分也显示出来
127.0.0.1:6379> zrange sort1 0 -1 withscores
- “a”
- “5”
- “c”
- “6”
- “d”
- “9”
zrevrange 降序排列
127.0.0.1:6379> zrevrange sort1 0 -1 withscores
- “d”
- “9”
- “c”
- “6”
- “a”
- “5”
我们再加两个元素
127.0.0.1:6379> zadd sort1 10 e 5 f
(integer) 2
zremrangebyrank 根据排名来删除元素 删除3个
127.0.0.1:6379> zremrangebyrank sort1 0 2
(integer) 3
127.0.0.1:6379> zrange sort1 0 -1 withscores
- “d”
- “9”
- “e”
- “10”
再添加元素
127.0.0.1:6379> zadd sort1 11 f 16 g 18 h
(integer) 3
127.0.0.1:6379> zrange sort1 0 -1 withscores
- “d”
- “9”
- “e”
- “10”
- “f”
- “11”
- “g”
- “16”
- “h”
- “18”
zremrangebyscore 根据具体评分范围来删除元素
127.0.0.1:6379> zremrangebyscore sort1 10 16
(integer) 3
127.0.0.1:6379> zrange sort1 0 -1 withscores
- “d”
- “9”
- “h”
- “18”
再添加元素
127.0.0.1:6379> zadd sort1 20 i 23 j 30 k
(integer) 3
127.0.0.1:6379> zrange sort1 0 -1 withscores
- “d”
- “9”
- “h”
- “18”
- “i”
- “20”
- “j”
- “23”
- “k”
- “30”
zrangebyscore 根据评分范围来查找元素
127.0.0.1:6379> zrangebyscore sort1 18 23 withscores
- “h”
- “18”
- “i”
- “20”
- “j”
- “23”
limit 限定查找起始 类似分页
127.0.0.1:6379> zrangebyscore sort1 18 23 withscores limit 0 2
- “h”
- “18”
- “i”
- “20”
zincrby 给指定元素加分
127.0.0.1:6379> zincrby sort1 5 h
“23”
127.0.0.1:6379> zrange sort1 0 -1 withscores
- “d”
- “9”
- “i”
- “20”
- “h”
- “23”
- “j”
- “23”
- “k”
- “30”
zcount 查找指定评分范围的元素个数
127.0.0.1:6379> zcount sort1 20 23
(integer) 3
Sorted-Set使用场景
大型在线游戏积分排行榜
构建索引数据
3、HyperLogLog学习
HyperLogLog是Redis的高级数据结构,是统计基数的利器。前文我们已经介绍过HyperLogLog的基本用法,如果只求会用,只需要掌握HyperLogLog的三个命令即可。
二、Redis学习Pub/Sub
在我们实例中我们创建了订阅频道名为 demo1
redis 127.0.0.1:6379> SUBSCRIBE demo1
则会显示
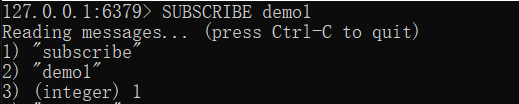
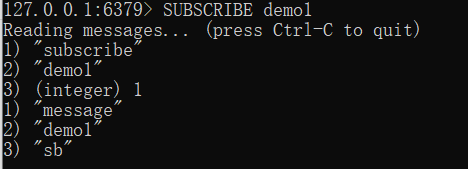
打开第二个客户端订阅并发布消息
redis 127.0.0.1:6379> PUBLISH runoobChat "sb"

而被订阅的则会显示
三、redisTemplate、jedis、lettuce、redission的对比
-
redisTemplate是基于某个具体实现的再封装,比如说springBoot1.x时,具体实现是jedis;而到了springBoot2.x时,具体实现变成了lettuce。封装的好处就是隐藏了具体的实现,使调用更简单,但是有人测试过jedis效率要10-30倍的高于redisTemplate的执行效率,所以单从执行效率上来讲,jedis完爆redisTemplate。redisTemplate的好处就是基于springBoot自动装配的原理,使得整合redis时比较简单。
-
jedis作为老牌的redis客户端,采用同步阻塞式IO,采用线程池时是线程安全的。优点是简单、灵活、api全面,缺点是某些redis高级功能需要自己封装。
-
lettuce作为新式的redis客户端,基于netty采用异步非阻塞式IO,是线程安全的,优点是提供了很多redis高级功能,例如集群、哨兵、管道等,缺点是api抽象,学习成本高。lettuce好是好,但是jedis比他生得早。
-
redission作为redis的分布式客户端,同样基于netty采用异步非阻塞式IO,是线程安全的,优点是提供了很多redis的分布式操作和高级功能,缺点是api抽象,学习成本高。
综上所述:单机并发量低时优先选择jedis,分布式高并发时优先选择redission。
四、Redis哨兵模式
1、介绍
主从切换技术的方法是:当主服务器宕机后,需要手动把一台从服务器切换为主服务器,这就需要人工干预,费事费力,还会造成一段时间内服务不可用。这不是一种推荐的方式,更多时候,我们优先考虑哨兵模式。
然而一个哨兵进程对Redis服务器进行监控,可能会出现问题,为此,我们可以使用多个哨兵进行监控。各个哨兵之间还会进行监控,这样就形成了多哨兵模式。
故障切换(failover)的过程。假设主服务器宕机,哨兵1先检测到这个结果,系统并不会马上进行failover过程,仅仅是哨兵1主观的认为主服务器不可用,这个现象成为主观下线。当后面的哨兵也检测到主服务器不可用,并且数量达到一定值时,那么哨兵之间就会进行一次投票,投票的结果由一个哨兵发起,进行failover操作。切换成功后,就会通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换主机,这个过程称为客观下线。这样对于客户端而言,一切都是透明的。
2、Redis配置哨兵模式



3、Redis配置
用于测试
| 服务类型 | 是否是主服务器 | IP地址 | 端口 |
|---|---|---|---|
| Redis | 是 | 192.168.2.133 | 6379 |
| Redis | 否 | 192.168.2.133 | 6380 |
| Redis | 否 | 192.168.2.133 | 6381 |
| Sentinel | - | 192.168.2.133 | 26379 |
| Sentinel | - | 192.168.2.133 | 26380 |
| Sentinel | - | 192.168.2.133 | 26381 |
下述内容主要是配置Redis服务器,从服务器比主服务器多一个slaveof的配置和密码。
# 使得Redis服务器可以跨网络访问
bind 0.0.0.0
# 设置密码
requirepass "123456"
# 指定主服务器,注意:有关slaveof的配置只是配置从服务器,主服务器不需要配置
slaveof 192.168.2.133 6379
# 主服务器密码,注意:有关slaveof的配置只是配置从服务器,主服务器不需要配置
masterauth 123456
#启动端口
port:6379
# 其他、指定端口运行(程序在src目录下)
./redis-cli -p 6380
./redis-cli -p 6381
4、哨兵配置
配置3个哨兵,每个哨兵的配置都是一样的。在Redis安装目录下有一个sentinel.conf文件,copy一份进行修改,另外两个端口不同而已
# 启动端口
port 26379
# 禁止保护模式
protected-mode no
# 配置监听的主服务器,这里sentinel monitor代表监控,mymaster代表服务器的名称,可以自定义,192.168.2.133代表监控的主服务器,6379代表端口,2代表只有两个或两个以上的哨兵认为主服务器不可用的时候,才会进行failover操作。
sentinel monitor mymaster 192.168.2.133 6379 2
# sentinel author-pass定义服务的密码,mymaster是服务名称,123456是Redis服务器密码
# sentinel auth-pass <master-name> <password>
sentinel auth-pass mymaster 123456
#设置后台启动
daemonize yes
#每个Sentinel节点都要定期PING命令来判断Redis数据节点和其余Sentinel节点是否可达,如果超过30000毫秒30s且没有回复,则判定不可达
sentinel down-after-milliseconds mymaster 30000
#当Sentinel节点集合对主节点故障判定达成一致时,Sentinel领导者节点会做故障转移操作,选出新的主节点,
#原来的从节点会向新的主节点发起复制操作,限制每次向新的主节点发起复制操作的从节点个数为1
sentinel parallel-syncs mymaster 1
#故障转移超时时间为180000毫秒
sentinel failover-timeout mymaster 180000
上述关闭了保护模式,便于测试。
有了上述的修改,我们可以进入Redis的安装目录的src目录,通过下面的命令启动服务器和哨兵
# 启动Redis服务器进程
./redis-server ../redis.conf
# 启动哨兵进程
./redis-sentinel ../sentinel.conf

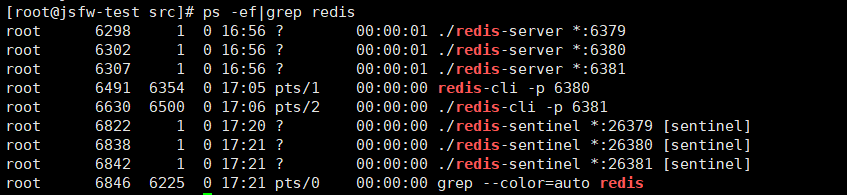
注意启动的顺序。首先是主机(192.168.2.133)的Redis服务进程,然后启动从机的服务进程,最后启动3个哨兵的服务进程。


5、测试
查看主从
info replication
主:

从:

查看哨兵是否成功通信 :
redis-cli -p 26379 info sentinel

测试当主宕机之后,哨兵进行三十秒测试后无果选举
#关闭命令
shutdown


当从机尝试修改信息时,会告知没权限:

六、遇到的坑
当我们学习是在同机测试时查看sentinel myid是否一样,如有一样则哨兵之间会冲突不能相互通信
查看下各个哨兵的配置文件中的sentinel myid xxxx是不是一样的,如果是一样的就把所有配置文件中这行删除,然后重启,会自动生成唯一的。
五、总结
- 问redis为什么快,一定是要有对比,比如和hbase比那就是纯内存操作,和memcached比就是单线程和多路复用,那你要讨论底层数据结构,那就是另外一个话题了,而且redis底层数据结构的设计更多侧重的不是快,而是节省内存,比如hash结构用字典肯定是最快的,但是为什么优先使用压缩列表,就是因为节省内存。
















 340
340











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











