







Elasticsearch
一、安装
安装docker
docker命令安装与启动elasticsearch和kibana集成
docker pull nshou/elasticsearch-kibana
docker run -d -p 9200:9200 -p 9300:9300 -p 5601:5601 --name eskibana nshou/elasticsearch-kibana
可能出现的问题
#报错
Error response from daemon: Get https://registry-1.docker.io/v2/: dial tcp: lookup registry-1.docker.io on [::1]:53: read udp [::1]:46783->[::1]:53: read: connection refused
#修改配置文件
vi /etc/resolv.conf
#添加
nameserver 8.8.8.8
#docker报错
WARNING: IPv4 forwarding is disabled. Networking will not work.
#追加
net.ipv4.ip_forward=1
#重启网络
systemctl restart network
进入容器修改kibana为中文
docker exec -it e4287ef6a10f /bin/bash
#容器中代码
cd /home/elasticsearch/kibana-7.12.1-linux-x86_64/config/
vim kibana.yml
#最后一行加上这个 i18n.locale: "zh-CN"
验证ES:
打开浏览器,输入IP:端口,比如我的:http://127.0.0.1:9200/

验证Kibana:
打开浏览器,输入Kibana的IP:端口,比如我的:http://127.0.0.1:5601/

ElasticSearch Head,它相当于是ES的图形化界面,这个更简单,它是一个浏览器的扩展程序,直接在chrome浏览器扩展程序里下载安装即可

二、操作索引
1、介绍
| ES | MySql |
|---|---|
| 字段 | 列 |
| 文档 | 一行数据 |
| 类型(已废弃) | 表 |
| 索引 | 数据库 |
分片
- 通过分片技术,咱们可以水平拆分数据量,同时它还支持跨碎片(可能在多个节点上)分布和并行操作,从而提高性能/吞吐量;
- ES可以完全自动管理分片的分配和文档的聚合来完成搜索请求,并且对用户完全透明;
- 主分片数在索引创建时指定,后续只能通过Reindex修改,但是较麻烦,一般不进行修改。
- 在创建索引时,只需要咱们定义所需的碎片数量就可以了,其实每个分片都可以看作是一个完全功能性和独立的索引,可以托管在集群中的任何节点上。
副本分片
- 当分片或者节点发生故障时提供高可用性。因此,需要注意的是,副本分片永远不会分配到复制它的原始或主分片所在的节点上;
- 可以提高扩展搜索量和吞吐量,因为ES允许在所有副本上并行执行搜索;
- 默认情况下,ES中的每个索引都分配5个主分片,并为每个主分片分配1个副本分片。主分片在创建索引时指定,不能修改,副本分片可以修改。
2、创建一个空索引(库)
如下代码,咱们创建了一个0副本2分片的ropledata索引,然后咱们可以在Elasticsearch Head里刷新一下,并查看索引的信息:
PUT /ropledata
{
"settings": {
"number_of_shards": "2",
"number_of_replicas": "0"
}
}


3、修改副本(库)
咱们如果对刚才创建的索引副本数量不满意,可以进行修改,注意:分片不允许修改。
PUT ropledata/_settings
{
"number_of_replicas" : "2"
}

4、删除索引(库)
当这个索引不想用了,可以进行删除,执行如下命令即可,执行成功后,刷新ElasticSearch Head可以看到刚才创建的ropledata索引消失了:
DELETE /ropledata

三、基础使用
1、数据插入数据
插入数据的时候可以指定id,如果不指定的话,ES会自动帮我们生成。我们以指定id为例,如下代码是我们创建了一个mydb1的文档,创建成功后,可以在Elasticsearch Head的数据浏览模块里看到这些数据,代码及演示如下:
格式
PUT /{index}/{type}/{id}
{
"field": "value",
...
}
举例
//指定id为mydb1
POST /ropledata/_doc/mydb1
{
"id":1,
"name":"渊哥",
"page":"www.baidu.com",
"say":"测试罢了"
}

2、局部更新
POST /ropledata/_update/mydb1
{
"doc":
{
"say":"奥力给"
}
}
这时候我们可以多次去执行上面的局部更新代码,会发现除了第一次执行,后续不管又执行了多少次,_version都不再变化!

3、删除数据
比如我们想把ropledata索引下的id为mydb1的文档删除,可以使用如下命令:
DELETE /ropledata/_doc/mydb1

查询或者删除时候用到的ID是创建文档时候指定或者ES自动生成的那个id,而不是文档里面的那个叫id 字段!文档里面的文档字段是可以没有id 的。
4、查询数据
普通查询
GET /ropledata/_doc/mydb1

5、两种查询模式
Query-string:通过url参数来搜索,被称为查询字符串搜索。
GET /megacorp/employee/_search?q=say:测试

Query-DSL:使用查询表达式搜索,被称为DSL查询,它支持构建更加复杂和健壮的查询,一般来说我们重点学习这种方法。
GET /megacorp/employee/_search
{
"query" : {
"match" : {
"say" : "测试"
}
}
}

6、复杂搜索
注意这里搜索say是测试,同时年龄大于15。注意下语法bool里面有must,filter类型,当然以后还会学到更多类型,这里先有个意识。
GET /megacorp/employee/_search
{
"query" : {
"bool": {
"must": {
"match" : {
"say" : "测试"
}
},
"filter": {
"range" : {
"age" : { "gt" : 15 }
}
}
}
}
}

7、全文搜索
比如我搜索员工说的话,注意这里稍有不同,about字段中包含两个单词,搜索的结果并不是完全匹配,是根据单词去做了相关性匹配。
Elasticsearch 默认按照相关性得分排序,即每个文档跟查询的匹配程度。
Elasticsearch中的 相关性 概念非常重要,也是完全区别于传统关系型数据库的一个概念,数据库中的一条记录要么匹配要么不匹配。
GET /megacorp/employee/_search
{
"query" : {
"match" : {
"say" : "love eat"
}
}
}

8、短语搜索
上面如果一个短语包含多个单词,那岂不是不能精确查询了,当然不是,可以使用短语搜索。
GET /megacorp/employee/_search
{
"query" : {
"match_phrase" : {
"say" : "love eat"
}
}
}

9、高亮搜索
GET /megacorp/employee/_search
{
"query" : {
"match_phrase" : {
"say" : "love eat"
}
},
"highlight": {
"fields" : {
"say" : {}
}
}
}

10、聚合搜索一
聚合类似于SQL中的GROUP_BY,但功能更强大
开启功能
PUT /megacorp/_mapping
{
"properties": {
"interests": {
"type": "text",
"fielddata": true
}
}
}
GET /megacorp/employee/_search
{
"aggs": {
"all_interests": {
"terms": {
"field": "interests"
}
}
}
}

11、聚合搜索二
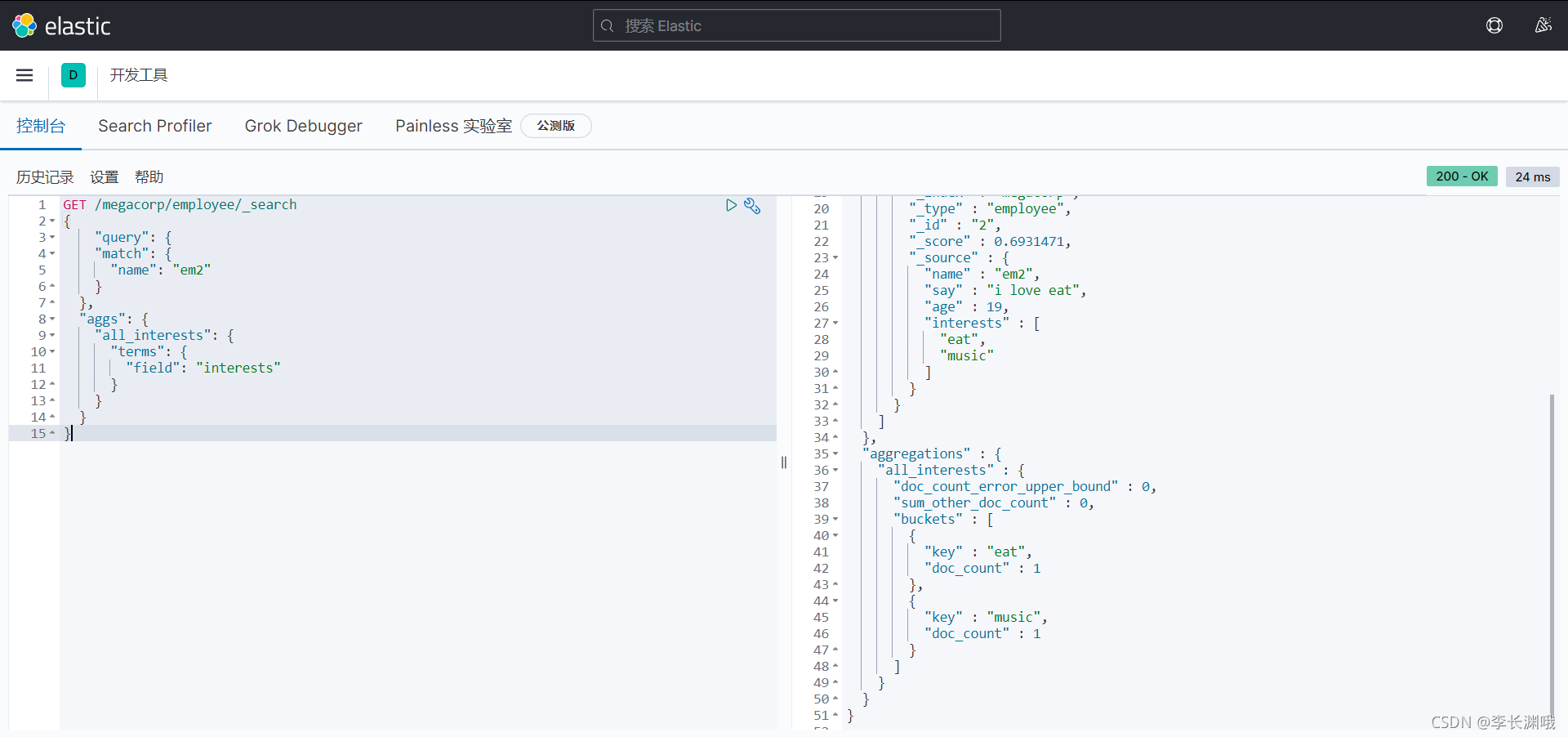
以上是对所有的雇员进行统计,我们也可以其中的一部分雇员进行组合查询统计,比如我们想知道叫em2的雇员最受欢迎的兴趣爱好。
GET /megacorp/employee/_search
{
"query": {
"match": {
"name": "em2"
}
},
"aggs": {
"all_interests": {
"terms": {
"field": "interests"
}
}
}
}
四、实践
1、依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<!-- 开启web-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--lombok-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
2、代码
config
@Configuration
public class ElasticsearchConfig {
@Bean
RestHighLevelClient elasticsearchClient() {
ClientConfiguration configuration = ClientConfiguration.builder()
.connectedTo("192.168.2.133:9200")
//.withConnectTimeout(Duration.ofSeconds(5))//指的是建立连接所用的时间,适用于网络状况正常的情况下,两端连接所用的时间。
//.withSocketTimeout(Duration.ofSeconds(3))//指客户端和服务进行数据交互的时间
//.useSsl()
//.withDefaultHeaders(defaultHeaders)
//.withBasicAuth(username, password)
// ... other options
.build();
RestHighLevelClient client = RestClients.create(configuration).rest();
return client;
}
}
存储类
public interface EmployeeRepository extends ElasticsearchRepository<Employee,Integer> {//范型的第二个参数为id的数据类型
}
实体类
@Document(indexName = "employee")
@Setter
@Getter
public class Employee {
// 必须指定一个id,
@Id
private Integer id;
private Integer age;
private String name;
private String say;
private ArrayList<String> interests;
}
在 6.X 版本中,一个 index 下只能存在一个 type;
在 7.X 版本中,直接去除了 type 的概念,就是说 index 不再会有 type。
3、核心数据类型
(1)字符串类型: text, keyword
(2)数字类型:long, integer, short, byte, double, float, half_float, scaled_float
(3)日期:date
(4)日期 纳秒:date_nanos
(5)布尔型:boolean
(6)Binary:binary
(7)Range: integer_range, float_range, long_range, double_range, date_range
#创建索引
PUT employee
PUT employee
{
"mappings": {
"properties": {
"id": {
"type": "integer"
},
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"age": {
"type": "integer"
},
"say": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"interests": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
4、测试
@SpringBootTest
class MyElasticsearch2ApplicationTests {
@Autowired
EmployeeRepository employeeRepository;
@Test
void contextLoads() {
Employee employee=new Employee();
employee.setAge(19);
employee.setName("渊哥");
employee.setSay("i love eat");
ArrayList<String> strings = new ArrayList<>();
strings.add("aa");
strings.add("bb");
strings.add("cc");
employee.setInterests(strings);
employeeRepository.save(employee);
}
}
因此在索引的时候,我输入的:http://192.168.2.133:9200/employee/_doc/_search
















 763
763











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











