






数字图像识别
import torchvision.datasets
import torchvision.transforms
import torch.utils.data
train_dataset=torchvision.datasets.MNIST(root='./data/mnist',train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_dataset=torchvision.datasets.MNIST(root='./data/mnist',train=False,transform=torchvision.transforms.ToTensor(),download=True)
batch_size=100
train_loader=torch.utils.data.DataLoader(dataset=train_dataset,batch_size=batch_size)
print('len(train_loader)={}'.format(len(train_loader)))#训练总数据6万,每批次100个,所以结果为600
test_loader=torch.utils.data.DataLoader(dataset=test_dataset,batch_size=batch_size)
print('len(test_loader)={}'.format(len(test_loader)))#测试总数据1万,每批次100个,所以结果为100
for images,labels in train_loader:
print('image_size={}'.format(images.size()))#【100,1,28,28】[批次大小,1,28*28大小]
print('labels_size={}'.format(labels.size()))#100
break
至此,将MNIST数据集加载到内存,并将各条数据以tensor形式存在程序中。
显示训练数据的特征和标签:
import matplotlib.pyplot as plt
plt.imshow(images[0,0],cmap='gray')
plt.title('label={}'.format(labels[0]))
plt.show()
利用多项逻辑回归识别MNIST数据
import torch.nn
import torch.optim
fc=torch.nn.Linear(28*28,10)
criterion=torch.nn.CrossEntropyLoss()
optimizer=torch.optim.Adam(fc.parameters())
epochs=5
for epoch in range(5):
for idx,(images,labels) in enumerate(train_loader):
#enumerate() 是一个 Python 内置函数,用于将一个可迭代的对象组合成一个索引序列,同时列出数据和数据的索引。
#在这里,使用 enumerate 能够在每次迭代中同时获取到当前批次的索引 idx(从0开始)和数据 images, labels。
#这个索引 idx 对于记录当前是训练过程中的第几个批次非常有用,特别是在你想打印信息或者进行特定批次处理时。
#这是从 train_loader 中一次迭代(即一批数据)获取的元组,其中包含了两部分数据:images 和 labels。
#images 包含了当前批次的图像数据,这是模型的输入。
#labels 包含了与这些图像相对应的标签,即真实值,这通常是用于训练过程中的比较,以计算损失并进行梯度下降。
x=images.reshape(-1,28*28)
#images: 这通常是一个包含多个图像的批次,其中每个图像是一个多维数组(或在 PyTorch 中称为张量)。在大多数图像处理任务中,特别是涉及到深度学习的任务,images 的形状通常是 [batch_size, channels, height, width]。对于 MNIST 数据集的图像,由于是灰度图,channels 为 1,且每张图像的高和宽为 28 像素。
#reshape(-1, 28*28):
#第一个参数 -1 在 PyTorch 中表示自动计算这一维的大小,以保证总的元素数与原张量相同。这里,它代表批次大小(batch_size),但是不需要显式指定。
#第二个参数 28*28 是将每个图像的所有像素值展平为一个一维数组。因为每张图像的大小是 28x28 像素,所以展平后的向量长度是 784。
optimizer.zero_grad()
preds=fc(x)
loss=criterion(preds,labels)
loss.backward()
optimizer.step()
if idx%100==0:
print('epoch={},批次={},loss={:g}'.format(epoch,idx,loss))
训练结束后,得到的权重值保存在torch.nn.Linear实例中,可以通过parameters()查看权重值。
接下来,我们在测试集上测试准确率。在测试过程中,对每批次测试数据,通过fc类实例获得线性加权后的结果,然后对每条数据求出让这个结果最大的索引作为预测值,通过比较预测值和真实的标签,计算一共正确预测了多少条测试数据,从而计算出准确度。
import torch
correct=0
total=0
for images,labels in test_loader:
x=images.reshape(-1,28*28)#每个批次为100,所以这里x为[100,28*28]
preds=fc(x)#经过训练好的fc,使得测试数据进行叠加的线性权值计算
predicted=torch.argmax(preds,1)#因为fc的输出有10个结果,我们要选择结果最大的那一个预测值,这里返回的是10个类别中值最大的数字所在的索引。1表示在第一维度上这样做。0是列,1是行(对于二维数据来说)
total+=labels.size(0)#总共有多少测试数据
correct+=(predicted==labels).sum().item()#有多少预测正确的?
accuracy=correct/total
print('acc={:.1%}'.format(accuracy))
股票成交量预测
通过读取股票每日价格和成交量,利用线性判别器预测未来成交量是否会增加。
数据获取:
import quandl
# 设置 API key:https://data.nasdaq.com/account/profile
quandl.ApiConfig.api_key = 'nybe52aDxdcuiHEHNTim'
# 获取数据
df = quandl.get('WIKI/FB', start_date='2012-01-01', end_date='2018-02-01')
# 打印前几行数据
print(df.head())

特征和标签的计算:
train_start,train_end=sum(df.index>='2017'),sum(df.index>='2013')
test_start,test_end=sum(df.index>='2018'),sum(df.index>='2017')
n_total_train=train_end-train_start
n_total_test=test_end-test_start
s_mean=df[train_start:train_end].mean()
s_std=df[train_start:train_end].std()
n_features=5
df_feature=((df-s_mean)/s_std).iloc[:,:n_features]
s_label=(df['Volume']<df['Volume'].shift(1)).astype(int)
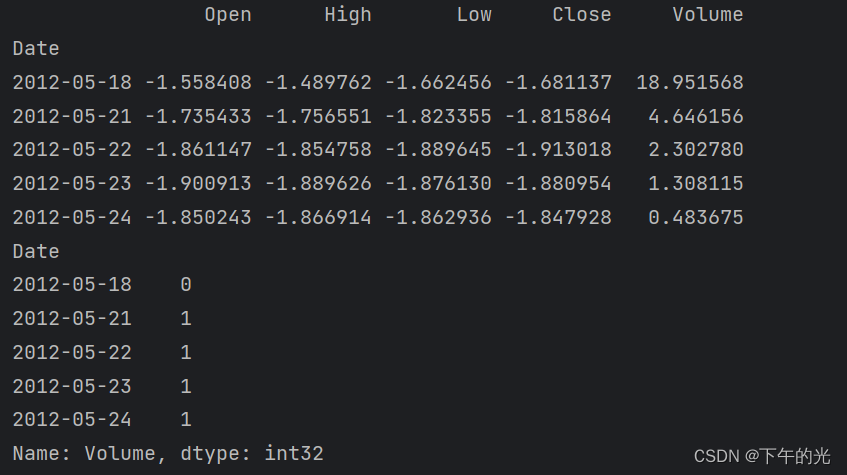
print(df_feature.head())
print(s_label.head())
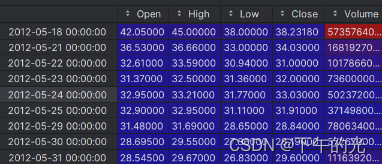
原来df,即df[‘Volume’]:
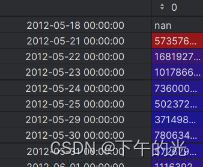
df[‘Volume’].shift(1):
处理后的结果:
训练和测试:
import torch
import torch.nn
import torch.optim
fc=torch.nn.Linear(n_features,1)
weights,bias=fc.parameters()
criterion=torch.nn.BCEWithLogitsLoss()
optimizer=torch.optim.Adam(fc.parameters())
x=torch.tensor(df_feature.values,dtype=torch.float32)
y=torch.tensor(s_label.values.reshape(-1,1),dtype=torch.float32)
n_step=20001
for step in range(n_step):
if step:
optimizer.zero_grad()
loss.backward()
optimizer.step()
pred=fc(x)
loss=criterion(pred[train_start:train_end],y[train_start:train_end])
if step%500==0:
print('#{},loss={:g}'.format(step,loss))
output=(pred>0)
correct=(output==y.byte())
n_correct_train=correct[train_start:train_end].sum().item()
n_correct_test=correct[test_start:test_end].sum().item()
accuracy_train=n_correct_train/n_total_train
accuracy_test=n_correct_test/n_total_test
print('训练集准确率={},测试集准确率={}'.format(accuracy_train,accuracy_test))


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









