






Mitigating Catastrophic Forgetting in Large Language Models with Self-Synthesized Rehearsal
利用自合成回放缓解大语言模型中的灾难性遗忘

📖导读:本篇博客有精读版和速读版两部分;精读版是全文的翻译,篇幅较长;如果你想快速了解论文方法,可以直接阅读速读版部分,它是对文章的通俗解读。
🦥精读版
👀目录
Abstrct
大语言模型(LLMs)在持续学习过程中会遭受灾难性遗忘。传统的基于回放的方法依赖于先前的训练数据来保持模型的能力,但这在实际应用中可能并不可行。当基于公开的大语言模型检查点进行持续学习时,原始训练数据可能无法获取。为了应对这一挑战,我们提出了一个名为自合成回放(SSR)的框架,该框架利用大语言模型生成合成实例用于回放。具体来说,我们首先使用基础大语言模型进行上下文学习以生成合成实例。随后,我们利用最新的大语言模型根据合成输入来优化实例输出,从而保留其已获得的能力。最后,我们选择多样化的高质量合成实例用于未来阶段的回放。实验结果表明,与传统的基于回放的方法相比,SSR 实现了更优或相当的性能,同时数据效率更高。此外,SSR 有效地保留了大语言模型在一般领域的泛化能力。
1. Introduction
大语言模型(LLMs)在各种自然语言处理(NLP)任务中都展现出了卓越的性能(Touvron 等人,2023b;OpenAI,2023)。在实际应用中,大语言模型通常以持续学习(CL)的方式进行更新(de Masson d’Autume 等人,2019),即随着时间的推移逐步引入新的指令调优数据。然而,一个严重限制大语言模型有效性的问题是灾难性遗忘,即大语言模型在学习新实例时倾向于忘记先前获得的知识(Kirkpatrick 等人,2017;Li 等人,2022;Luo 等人,2023)。
为了缓解灾难性遗忘,一系列工作专注于回放先前的训练实例(de Masson d’Autume 等人,2019;Rolnick 等人,2019;Scialom 等人,2022)。这些基于回放的方法通过在先前训练阶段的真实数据上进行训练来维持模型的能力。然而,在实际应用中,真实数据并不总是理想的。例如,当基于公开的大语言模型检查点(例如 Llama-2chat)进行持续学习时,原始训练数据可能无法获取。这就引出了一个有趣的研究问题:在持续学习过程中,我们能否在不使用先前训练阶段的真实数据的情况下维持大语言模型的能力?
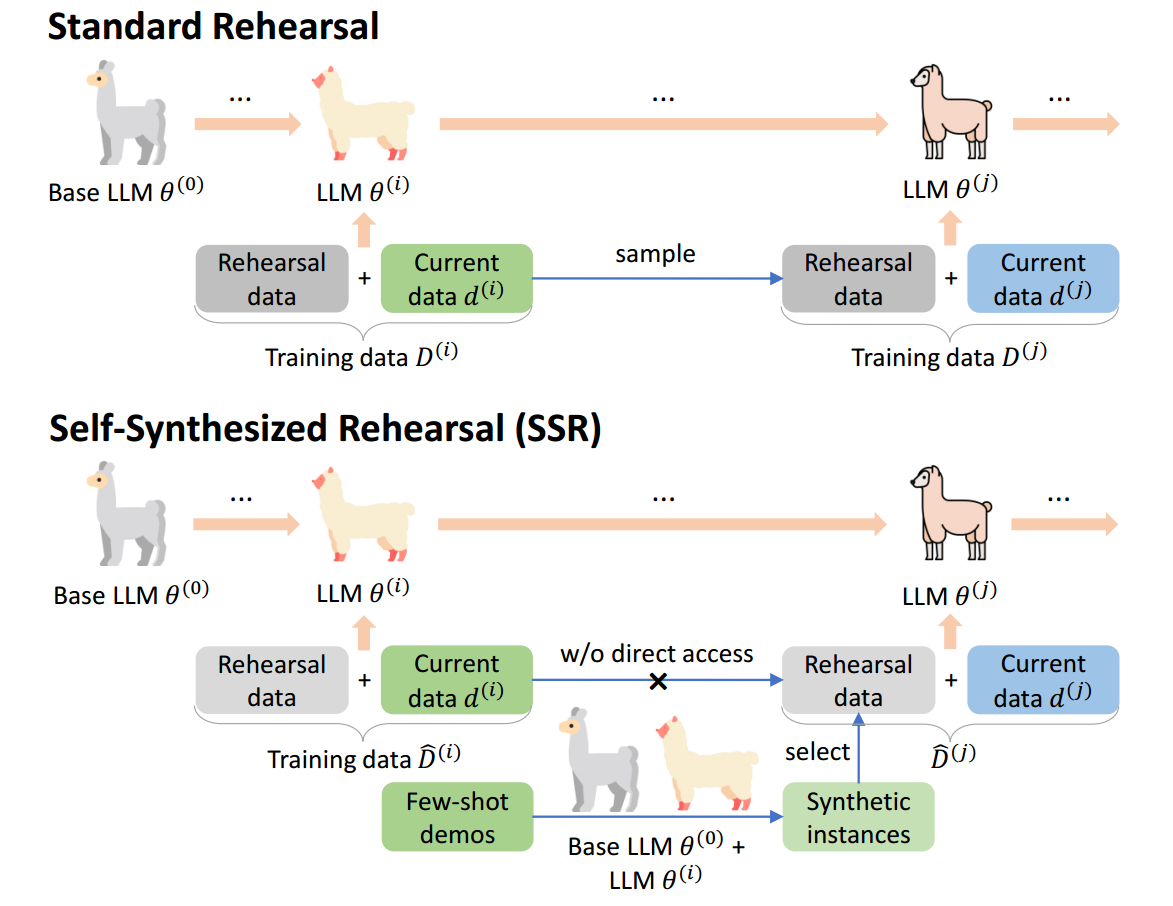
我们提出了自合成回放(SSR)框架以缓解持续学习中的灾难性遗忘。如图 1 所示,与标准的基于回放的持续学习从先前阶段采样训练实例作为回放数据不同,SSR 框架使用大语言模型生成合成实例用于回放。具体来说,我们首先使用基础大语言模型生成合成实例,通过少样本演示进行上下文学习(ICL)。这些演示可以从先前的数据中收集,或者由人类构建,包含与先前数据相似的知识。然后,使用最新的大语言模型来优化合成实例的输出,以保留最新大语言模型的能力。最后,我们选择多样化的高质量合成实例用于未来阶段的回放。
在来自 SuperNI 数据集(Wang 等人,2022)的任务序列上进行的大量实验表明,SSR 与传统的基于回放的方法相比具有更优或相当的性能,且具有更高的数据利用效率。此外,在 AlpacaEval 和 MMLU(Hendrycks 等人,2021)上的实验表明,SSR 还可以有效地保留大语言模型在一般领域的泛化能力。我们在 https://github.com/DeepLearnXMU/SSR 上发布我们的代码和数据。
2. 相关工作
在持续学习一系列数据集的同时保留过去的知识和技能是实现人类水平智能的一个关键方面。现有的持续学习方法大致可以分为三大类:(i)基于正则化的方法,(ii)基于架构的方法和(iii)基于回放的方法。正则化技术(Kirkpatrick 等人,2017;Cha 等人,2021;Huang 等人,2021;Zhang 等人,2022)控制学习过程中参数更新的程度,防止对先前学习的任务产生干扰。尽管如此,这些方法通常依赖于需要仔细调整以获得最佳性能的超参数。基于架构的方法(Xu 和 Zhu,2018;Huang 等人,2019;Razdaibiedina 等人,2023)通常采取不同的方法,为单个任务学习单独的参数集。这使得模型能够专门化并为每个任务调整其参数,避免任务之间的干扰并保留特定任务的知识。然而,这些方法会引入额外的训练参数,对于各种大语言模型来说可能不是非常灵活和可行。
因此,我们专注于基于回放的方法(de Masson d’Autume 等人,2019;Rolnick 等人,2019),也被称为基于重放的方法。这些方法通常涉及存储来自先前任务的一部分数据。这些存储的数据通过经验重放(Rolnick 等人,2019)和表示整合(Bhat 等人,2022)等技术用于未来的回放。先前基于回放的语言模型方法主要集中在使用少量的先前数据(Scialom 等人,2022;Mok 等人,2023;Zhang 等人,2023b)。然而,这些方法往往忽略了对现实世界应用的讨论,在现实世界中,先前的数据可能有限或不可用。尽管无数据知识蒸馏方法(Yin 等人,2020;Smith 等人,2021)引入了辅助生成模型进行数据构建,但它们主要是为分类任务设计的,在涉及广泛自然语言处理任务的大语言模型中可能并不有效。此外,与引入教师模型(Miao 等人,2023;Cheng 等人,2023;Huang 等人,2024)类似,训练额外的生成模型可能具有挑战性且耗时。自蒸馏方法(Zhang 等人,2023a)可能有用,但最新大语言模型的灾难性遗忘以及不同阶段的大语言模型之间的知识差异仍然是不可避免的挑战。
在这项工作中,我们提出了一个基于回放的持续学习框架,在该框架中,大语言模型可以在自合成数据上进行训练,以保留先前阶段的知识,并且在数据构建过程中使用了一些演示。与其他方法不同,我们的框架不依赖于额外的生成模型进行数据构建,也不需要先前的真实数据进行回放。这在数据效率和应用灵活性方面具有优势。
3. 基于回放的持续学习
在持续学习中,大语言模型按顺序在 T T T 个阶段进行更新,每个阶段 t t t 都有其相应的指令数据 d ( t ) d^{(t)} d(t)。为了缓解灾难性遗忘,在每个阶段 t t t 中,基于回放的方法(Scialom 等人,2022;Mok 等人,2023)对先前阶段的一些训练实例进行采样,以扩展当前阶段的训练数据。形式上,扩充后的训练数据 D ( t ) D^{(t)} D(t) 可以如下公式化表示:

其中 r r r 表示回放比例,决定了采样的训练实例的百分比。最后,我们使用 D ( t ) D^{(t)} D(t)来微调大语言模型 θ ( t − 1 ) θ^{(t−1)} θ(t−1),得到更新后的大语言模型 θ ( t ) θ^{(t)} θ(t)。特别地,在第一阶段,我们在 D ( 1 ) = d ( 1 ) D^{(1)}=d^{(1)} D(1)=d(1)上微调基础大语言模型 θ ( 0 ) θ^{(0)} θ(0)。通过这样做,可以有效地缓解大语言模型的灾难性遗忘问题,这在先前的研究中已经得到了验证(Scialom 等人,2022;Mok 等人,2023;Zhang 等人,2023b)。

图2:我们的 SSR 框架。为了在有限或没有回放数据的情况下缓解灾难性遗忘,我们首先采用具有上下文学习能力的基础大语言模型
θ
(
0
)
θ^{(0)}
θ(0)来生成合成实例
{
(
x
^
,
y
^
)
}
\{(\hat{x}, \hat{y})\}
{(x^,y^)}。然后,我们利用最新的大语言模型
θ
(
t
−
1
)
θ^{(t−1)}
θ(t−1)基于
x
^
\hat{x}
x^生成优化后的输出
y
‾
\overline{y}
y。最后,选择多样化的高质量合成实例用于未来阶段的回放。
4. 我们的框架
在本节中,我们详细介绍所提出的自合成回放(SSR)框架,它包括三个主要步骤:1)基于上下文学习的实例合成,2)合成输出优化,3)使用选定的合成实例进行回放,如图 2 所示。
基于上下文学习的实例合成 基于回放的方法利用训练实例来缓存大语言模型从先前阶段获取的知识。然而,在使用公开的大语言模型检查点的实际场景中,原始训练数据的可用性可能有限。为了解决这个限制,我们尝试合成地生成回放训练实例。为了让大语言模型遵循抽象指令,我们利用大语言模型的上下文学习(ICL)能力进行实例合成。
形式上,在每个训练阶段 t t t,我们首先获取 K K K 个演示 { ( x k , y k ) } k = 1 K \{(x_k, y_k)\}_{k = 1}^K {(xk,yk)}k=1K。为了保留先前获得的知识,这些演示可以从先前的指令数据 d ( t − 1 ) d^{(t−1)} d(t−1)中收集,或者手动构建包含与 d ( t − 1 ) d^{(t−1)} d(t−1)相似知识的内容。我们将所有演示连接起来,并利用基础大语言模型生成合成实例 ( x ^ , y ^ ) = LLM ( concat k = 1 K ( x k , y k ) ; θ ( 0 ) ) (\hat{x}, \hat{y})=\text{LLM}(\text{concat}_{k=1}^K(x_k, y_k);θ^{(0)}) (x^,y^)=LLM(concatk=1K(xk,yk);θ(0))。通过重新排列演示并多次采样,我们可以轻松获得不同的合成实例。需要注意的是,我们使用基础大语言模型 θ ( 0 ) θ^{(0)} θ(0)而不是最新的大语言模型 θ ( t − 1 ) θ^{(t−1)} θ(t−1)来进行上下文学习。这是因为正如(Wang 等人,2023)所分析的那样,在特定任务上进行有监督微调(SFT)后,大语言模型的上下文学习能力往往会出现显著下降。
合成输出优化 通过上述过程,我们获得了一系列合成实例,然而,其中一些可能质量较低,输出不可靠。为了解决这个问题,我们使用最新的大语言模型 θ ( t − 1 ) θ^{(t−1)} θ(t−1)来优化每个合成实例的输出: y ‾ = LLM ( x ^ ; θ ( t − 1 ) ) \overline{y} = \text{LLM}(\hat{x};θ^{(t−1)}) y=LLM(x^;θ(t−1))。通过这样做,我们可以确保每个优化后的合成实例 ( x ^ , y ‾ ) (\hat{x}, \overline{y}) (x^,y)保留最新大语言模型所获得的知识。
使用选定的合成实例进行回放 最后,我们选择优化后的合成实例进行回放。在这个过程中,为了确保选定的合成实例的多样性和质量,我们首先采用一种聚类算法(例如 K-means)将 ( x ^ , y ‾ ) (\hat{x}, \overline{y}) (x^,y)分为 C C C 个簇。然后,我们计算每个合成实例与其相应的聚类中心之间的距离,最后选择靠近聚类中心的一定数量的合成实例作为回放数据。
形式上,我们用 d ^ ( t − 1 ) \hat{d}^{(t−1)} d^(t−1)表示选定的合成实例的集合。因此,阶段 t t t 的扩充训练数据可以公式化为:

其中 d ^ ( i ) \hat{d}^{(i)} d^(i)表示与先前的训练数据 d ( i ) d^{(i)} d(i)相似的选定合成数据。注意, d ^ ( 1 ) \hat{d}^{(1)} d^(1), d ^ ( 2 ) \hat{d}^{(2)} d^(2),…, d ^ ( t − 2 ) \hat{d}^{(t-2)} d^(t−2)是在先前阶段生成的,因此在阶段 t t t中我们不会重新生成它们。最后,我们使用 D ^ ( t ) \hat{D}^{(t)} D^(t)来微调 θ ( t − 1 ) θ^{(t−1)} θ(t−1),将大语言模型更新为 θ ( t ) θ^{(t)} θ(t)。这样,即使没有来自先前阶段的真实数据,大语言模型也可以保留先前学到的知识。
5. 实验
5.1 设置
数据集 我们在 SuperNI 数据集(Wang 等人,2022)上进行了几组实验,这是一个庞大而全面的指令调优基准数据集。首先,为了模拟典型的持续学习过程,我们从 SuperNI 中选择了 10 个任务的子集,涵盖了各种类别和领域。每个任务在单独的阶段进行训练以进行实证研究。对于每个任务,我们随机抽取 2000 个实例用于训练,500 个用于评估。有关这些任务的详细信息,请参阅附录 A。为了简化实证研究,我们在{5,10}个 SuperNI 任务上采用默认的持续学习顺序:QA→QG→SA→Sum.→Trans.(→DSG→Expl.→Para.→PE→POS)。
基础LLMs 我们的主要实验涉及三个基础大型语言模型:Llama-2-7b(Touvron 等人,2023b)、Llama-2-7b-chat(Touvron 等人,2023b)、Alpaca7b(Taori 等人,2023)。
Baselines 我们将 SSR 与以下基准方法进行比较:
- 多任务学习(MTL)。这是最常用的基准方法,其中所有任务同时进行训练。
- 无回放。这是一个简单的基准方法,在每个阶段 t t t 中,大型语言模型仅使用指令数据 d ( t ) d^{(t)} d(t) 进行微调。
- RandSel ( r r r)(Scialom 等人,2022)。我们为每个先前的任务随机采样 r = { 1 , 10 } % r = \{1,10\}\% r={1,10}%的原始指令数据。请注意,正如(Scialom 等人,2022)中所提到的,当 r = 1 % r = 1\% r=1% 时,可以有效地保留语言模型的能力。
- KMeansSel ( r r r)。与上述方法不同,我们首先使用 K- means聚类将真实实例分为 20 个簇,然后选择 r = { 1 , 10 } % r = \{1,10\}\% r={1,10}%与簇中心具有最高相似度的实例。在这里,我们在聚类之前采用 SimCSE(Gao 等人,2021)来获得实例表示。
评估指标 由于 SuperNI 任务的多样性和开放式序列生成特性,我们采用 ROUGE-L 指标(Lin,2004)来评估大型语言模型在每个任务上的性能。正如 Wang 等人(2022)所展示的,这个指标与人类评估具有良好的一致性。此外,我们遵循 Lopez-Paz 和 Ranzato(2017),基于 ROUGE-L 考虑以下指标。这里 a j ( i ) a_j^{(i)} aj(i) 表示在训练阶段 i i i 中任务 j j j 的 ROUGE-L 性能。
- 平均 ROUGE-L(AR)。它用于量化在阶段 T T T 中大型语言模型在所有 T T T 个任务上的最终平均性能,定义如下:

- 前向传递(FWT)。它评估大型语言模型在未见过的任务上的泛化能力,测量在每个阶段 i − 1 i - 1 i−1 中对下一个任务 i i i 的平均零样本性能 a i ( i − 1 ) a_i^{(i−1)} ai(i−1):

- 后向传递(BWT)。它是一个用于评估学习后续任务对先前任务影响的指标。对于除最后一个任务之外的每个任务 i i i,它将最终性能 a i ( T ) a_i^{(T)} ai(T)与阶段 i i i中的在线性能 a i ( i ) a_i^{(i)} ai(i)进行比较:

负的 BWT 表明大型语言模型忘记了一些先前获得的知识。
实现细节 在训练过程中,我们在自注意力模块中使用带有查询和值投影矩阵的低秩适应(LoRA,Hu 等人,2021)来训练大型语言模型,将 LoRA 的秩设置为 8,丢弃率设置为 0.1。我们使用 Adam 优化器,初始学习率为 2e-4。在我们所有的实验中,全局批次大小为 32。此外,我们将输入的最大长度设置为 1024,输出的对应长度设置为 512。按照 Luo 等人(2023)的方法,我们对每个大型语言模型训练 3 个周期,并使用最终的检查点进行评估。
为了进行上下文学习(ICL),我们使用来自 SuperNI 任务的训练数据的
1
%
1\%
1% 作为演示,考虑
K
=
2
K = 2
K=2 个演示,并多次采样以获得多样化的合成实例。在对实例进行聚类时,我们对 SuperNI 任务的合成实例使用 K-means聚类,
C
=
20
C = 20
C=20 个簇,这与 KMeansSel (
r
r
r) 类似。
5.2 在 5 个 SuperNI 任务上的实验
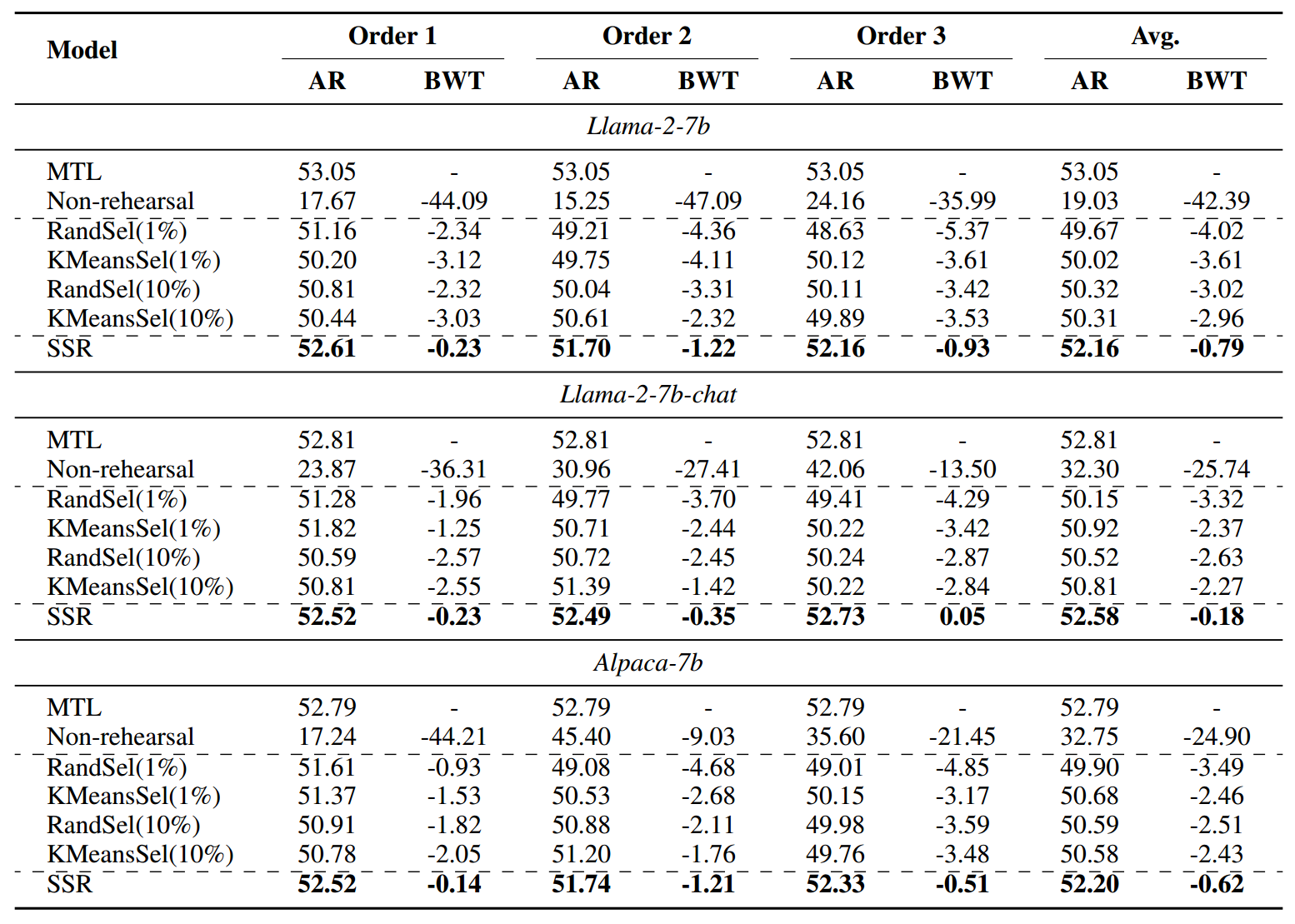
表 1 展示了在 5 个 SuperNI 任务上的实验结果。总体而言,无论持续学习顺序和基础大型语言模型如何,SSR 始终优于所有基于回放的基准方法,在平均 ROUGE-L(AR)和后向传递(BWT)指标上均显示出大约 2 个分数的提升。这一结果表明了 SSR 在缓解灾难性遗忘方面的优越性。特别地,SSR 非常接近多任务学习(MTL),后者设定了 AR 性能的上限。此外,与基于回放的基准方法 RandSel ( r r r) 和 KMeansSel ( r r r) 相比,SSR 数据效率更高,仅使用 1 % 1\% 1% 的真实数据用于上下文学习(ICL),并且仅使用先前阶段的合成数据进行回放。
经过进一步分析,我们得出以下结论:
无回放 vs. 有回放 无回放基准方法表现最差,表明存在严重的灾难性遗忘。此外,它显示出最高的指标方差,表明其在不同的持续学习顺序中缺乏稳健性。相比之下,SSR 和基于回放的基准方法无论持续学习顺序如何都能保持更好且更一致的性能。
r r r 的影响 合适的回放比例 r r r因持续学习顺序而异。在某些情况下,较高的 r r r 是有益的,如在持续学习顺序 2 和 3 中观察到的那样。然而,情况并非总是如此。在持续学习顺序 1 中,无论采用何种实例采样策略, r = 1 % r = 1\% r=1% 的基于回放的基准方法始终分别优于 r = 10 % r = 10\% r=10% 的对应方法。
RandSel( r r r) vs. KMeansSel( r r r) 当比较 RandSel( r r r)和 KMeansSel( r r r)时,我们可以观察到,在仅使用 r = 1 % r = 1\% r=1% 时,基于 K-means聚类选择先前数据进行回放可能会略微提高模型性能,这表明了数据代表性的重要性。然而,当 r r r 设置为 10 10% 10时,对于像 Llama-2-7b 和 Alpaca-7b 这样的大型语言模型,可能不会观察到模型性能的显著差异。
5.3 在 10 个 SuperNI 任务上的实验
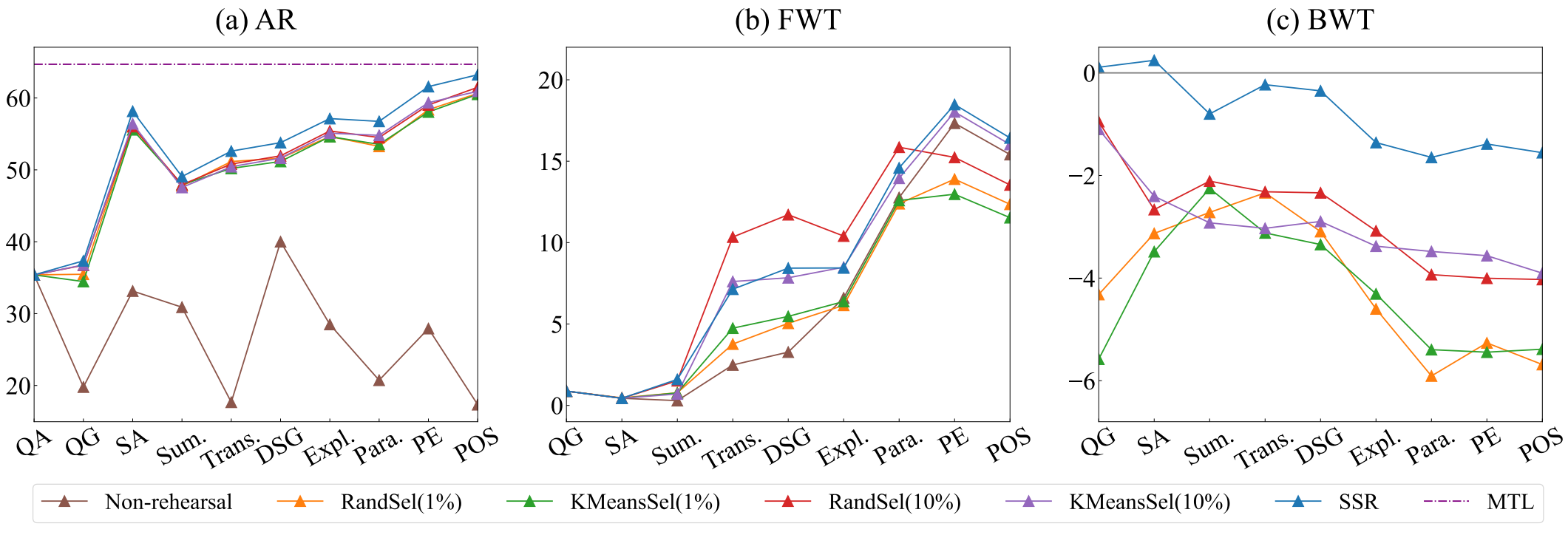
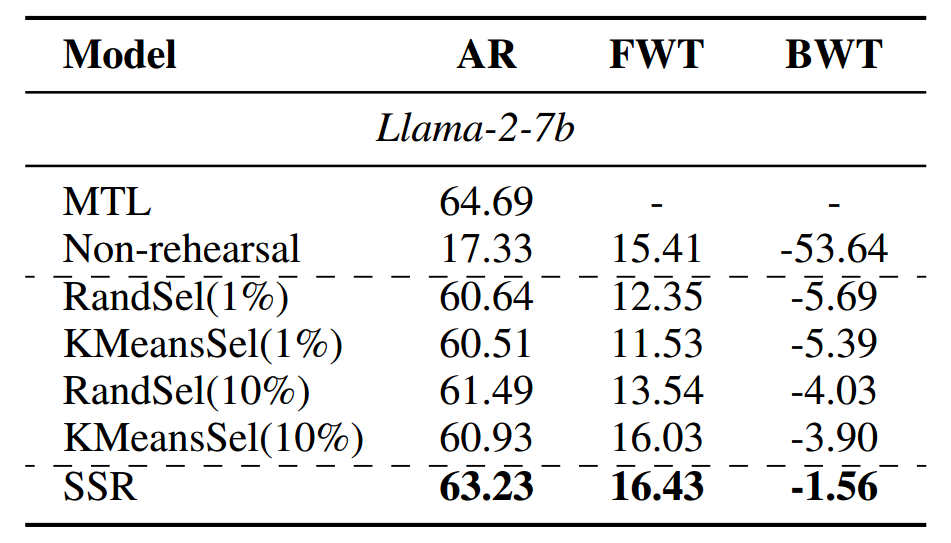
为了进一步研究 SSR 在更长的持续学习序列中的有效性,我们在 10 个 SuperNI 任务上评估了 SSR 和所有的基准方法。表 2 显示,SSR 在所有指标上都超过了所有基于回放的基准方法。此外,如图 3 所示,在整个持续学习过程中,SSR 在平均 ROUGE-L(AR)和后向传递(BWT)方面始终比基于回放的基准方法取得更好的性能。虽然以 Llama-2-7b 作为基础大型语言模型的 SSR 在早期的前向传递(FWT)方面落后于 RandSel( 10 % 10\% 10%),但随着训练阶段数量的增加,它的性能逐渐增强,最终超过了 RandSel( 10 % 10\% 10%)。更多详细信息请参阅附录 C。
5.4 对 Alpaca-7b 泛化能力保留的实验
为了进一步分析在 SuperNI 任务之外更广泛领域中大型语言模型泛化能力的保留情况,我们使用 Alpaca-7b 在 5 个 SuperNI 任务上进行持续学习,然后研究 SSR 是否能够保留 Alpaca-7b 从 Alpaca-52k 数据集获得的能力。在这里,Llama-7b(Touvron 等人,2023a)作为基础大型语言模型 θ ( 0 ) θ^{(0)} θ(0),而 Alpaca-7b 在 Alpaca-52k 上进行微调后被视为更新后的大型语言模型 θ ( 1 ) θ^{(1)} θ(1)。因此,我们也为 SSR 生成类似于 Alpaca-52k 的合成实例,并将 Alpaca-52k 用于基于回放的基准方法。
我们从三个角度评估大型语言模型:1)通用指令遵循能力。我们使用 AlpacaEval 2.0 作为自动评估器。具体来说,我们通过比较大型语言模型的生成结果与 gpt-4-turbo 生成的结果,以胜率来衡量大型语言模型的性能。为了最小化财务成本,我们使用 ChatGPT 作为评估标注器。2)通用语言理解能力。我们利用 MMLU(Hendrycks 等人,2021)基准,其中准确率(Acc.)被用作评估指标。3)特定任务能力。我们评估大型语言模型在 5 个 SuperNI 任务上的平均 ROUGE-L(AR)性能。更多详细信息请参阅附录 D。
从表 3 中,我们观察到 SSR 不仅在 5 个新学习的任务上取得了最佳成绩,而且在 AlpacaEval 和 MMLU 上也保持了相当甚至更优的性能。这些发现表明,SSR 在持续学习过程中有效地保留了 Alpaca-7b 的泛化能力,即使在没有 Alpaca-52k 作为回放数据的情况下也是如此。这凸显了 SSR 在一般领域中的巨大潜力。
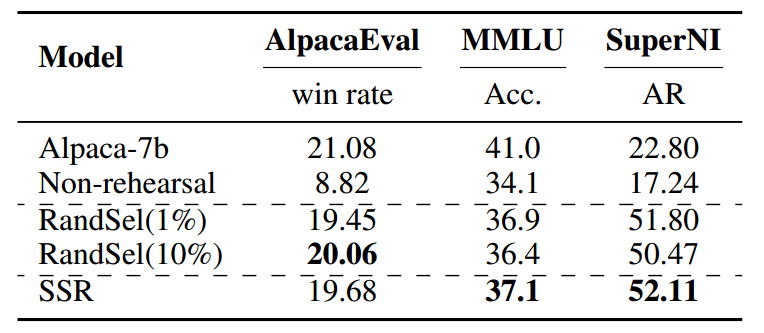
表 3:在 Alpaca-52k + 5 个 SuperNI 任务上的最终结果。
| 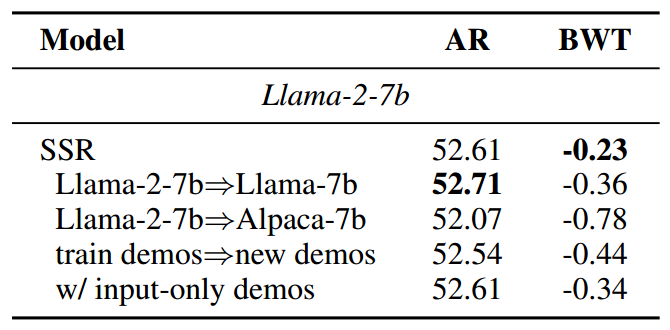
表 4:上下文学习对 Llama-2-7b 在 5 个 SuperNI 任务上的影响。
|
5.5 分析
上下文学习的效果 为了研究上下文学习对 SSR 的影响,我们在 5 个 SuperNI 任务上对 Llama-2-7b 进行实验,引入以下变体:(a)Llama-2-7b⇒Llama-7b。这个变体验证了我们获得一个公开的微调后的大型语言模型检查点,但原始基础大型语言模型不可用的情况。因此,我们使用不同的大型语言模型 Llama-7b 进行上下文学习。(b)Llama-2-7b⇒Alpaca-7b。与上述情况类似,但使用 Alpaca-7b。(c)train demos⇒new demos。在这个变体中,我们使用不包含在先前训练数据中但属于相同 SuperNI 任务的演示,模拟手动构建的演示进行上下文学习。(d)w/ input-only demos。这个变体仅使用先前阶段的实例输入作为演示,模拟真实实例缺乏输出标注的情况。
表 4 表明,即使没有原始基础大型语言模型或来自先前训练数据的演示来进行上下文学习,SSR 也能表现良好。这为在实际应用场景中替换一些上下文学习组件提供了便利。比较 SSR 及其变体(a)到(b),我们注意到使用 Alpaca-7b 进行上下文学习时性能略有下降。这突出了这个微调后的大型语言模型在上下文学习能力方面的局限性。此外,仅使用输入的演示进行上下文学习也能产生相当的性能,这表明输出标注对于上下文学习也不是必不可少的,进一步验证了 SSR 的稳健性。
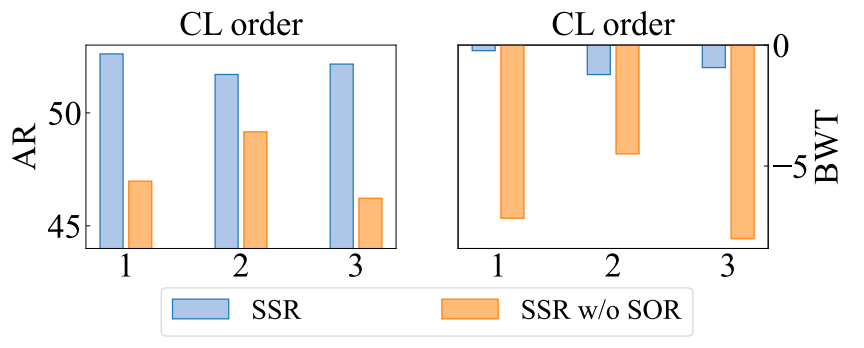
图 4:在不同持续学习顺序下,合成输出优化(SOR)对 Llama-2-7b 在 5 个 SuperNI 任务上的影响。
| 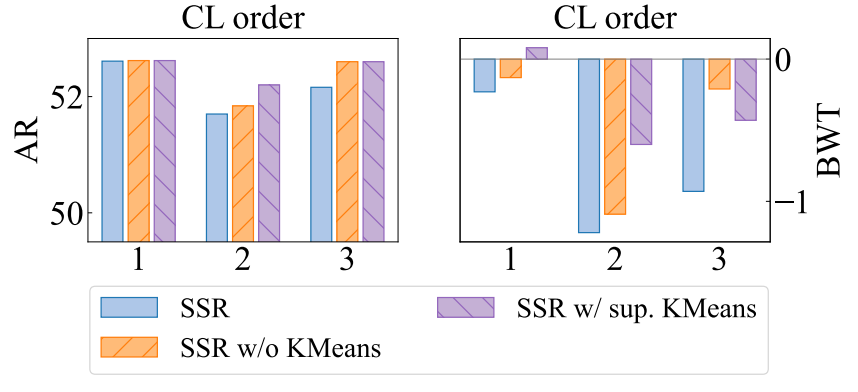
图 5:在不同持续学习顺序下,K-means聚类对 Llama-2-7b 在 5 个 SuperNI 任务上的影响。
|
合成输出优化的效果 在第 4 节中,我们声称合成输出优化从最新的大型语言模型中提供了更可靠的合成输出。为了验证其有效性,我们进行了一个实验,在该实验中实施 SSR 时不进行合成输出优化。
如图 4 所示,这导致了较低的平均 ROUGE-L(AR)值和显著的后向传递(BWT)劣势,突出了来自基础大型语言模型的数据噪声的负面影响。相比之下,通过将合成输入与优化后的输出结合,SSR 可以在回放期间保持最新大型语言模型的预测分布,从而保留所获得的知识。
K-means聚类在合成实例选择中的效果 在应用灵活性方面,我们使用无监督的 K-means聚类算法,仅使用合成实例进行拟合和预测。为了探索 K-means聚类的效果,我们将 SSR 与以下变体进行比较:(a)SSR w/o KMeans:随机选择合成实例。(b)SSR w/ sup. KMeans:基于 K-means聚类的合成实例选择,在真实实例的监督下拟合 K-means聚类,然后在合成实例上进行预测。
图 5 显示,有监督的 K-means聚类方法在平均 ROUGE-L(AR)方面略有改进,并通过更大的后向传递(BWT)减少遗忘。因此,在聚类过程中纳入真实实例可能会实现更具代表性的选择。尽管如此,在没有监督的情况下,聚类并非必不可少,因为对合成实例进行随机选择的 SSR 可以优于 SSR,有时甚至超过有监督的 K-means聚类的 SSR。这表明 SSR 具有一定程度的稳健性。
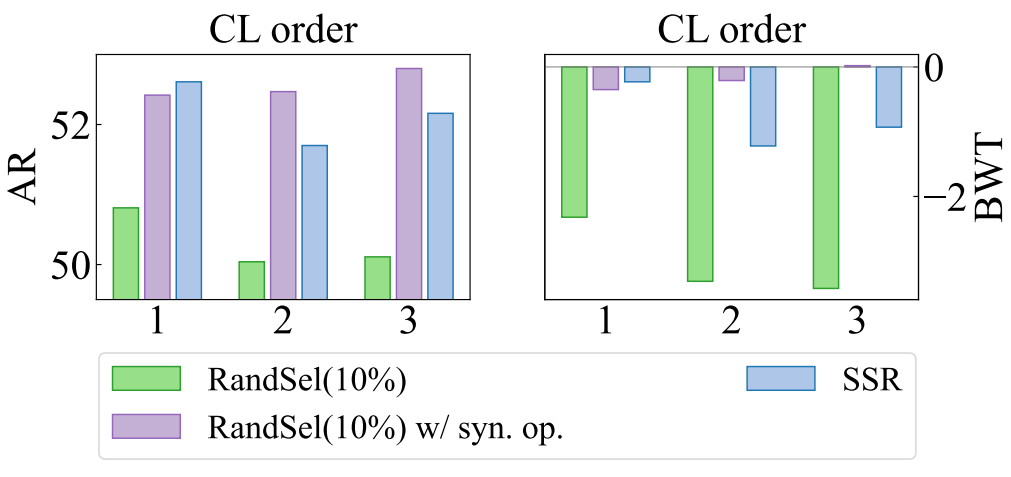
图 6:在不同持续学习顺序下,合成输入和输出对 Llama-2-7b 在 5 个 SuperNI 任务上的影响。注意,在持续学习顺序 3 中,带有合成输出(syn.op.)的随机选择(10%)具有最佳的向后迁移(BWT)值,为 0.02。
| 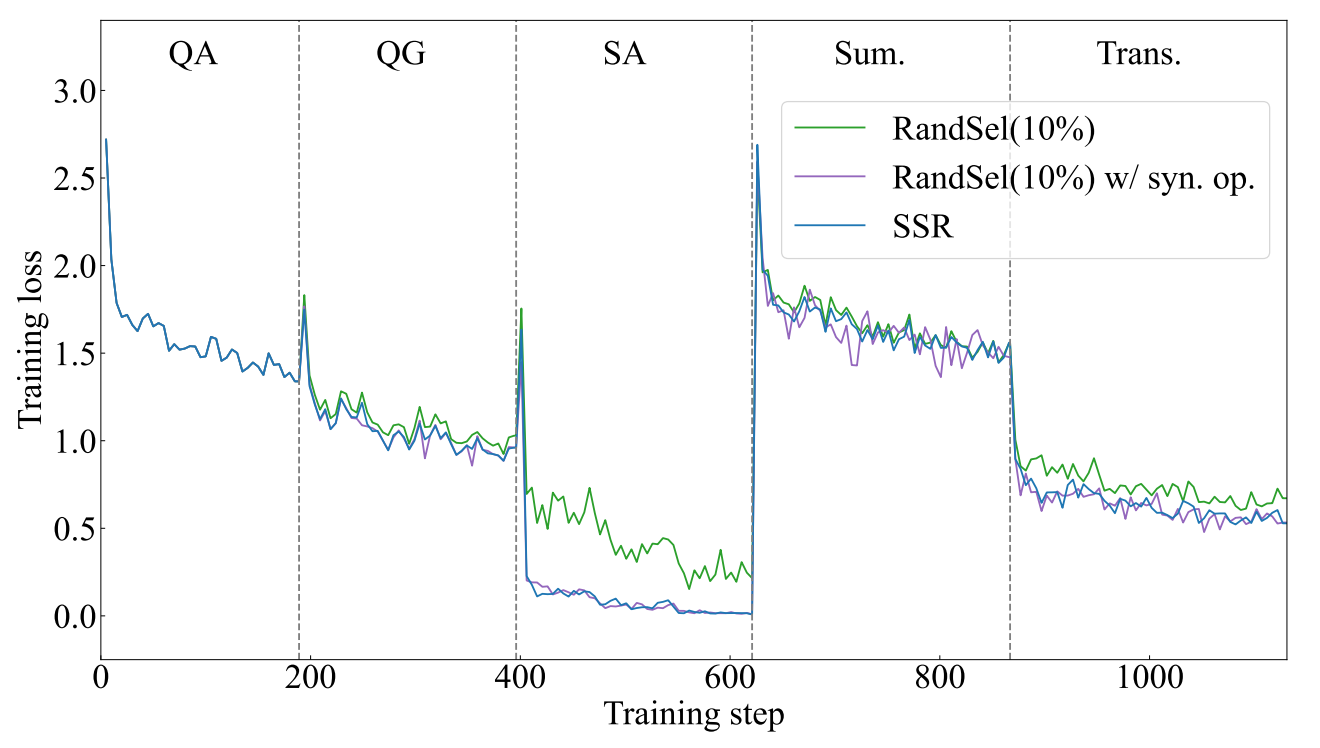
图 7:在 5 个 SuperNI 任务上,合成输入和输出对 Llama-2-7b 损失曲线的影响。
|
真实实例 vs. 合成实例 我们的主要实验展示了令人惊讶的结果,即使用合成实例进行回放可能会超过使用真实实例进行回放的效果。为了比较真实实例和合成实例,我们考虑以下变体:(a)RandSel( 10 % 10\% 10%):用于回放的真实输入和输出。(b)RandSel( 10 % 10\% 10%) w/ syn. op.:用于回放的真实输入和合成输出。具体来说,我们通过最新的大型语言模型重新生成随机采样的先前实例的输出,其操作与 SSR 类似。图 6 表明,使用真实输入和合成输出进行回放的 RandSel( 10 % 10\% 10%)优于仅使用真实实例的RandSel( 10 % 10\% 10%)。同时,利用合成输入和输出进行回放的 SSR 取得了中等性能,有时甚至超过其他两种方法。这表明真实实例并不总是对大型语言模型的持续学习必不可少且合适。如图 7 所示,真实实例通常会导致损失下降更慢。因此,由于不同数据集之间的分布差距,它们可能不利于优化。相反,合成实例具有较低的模型困惑度,体现了大型语言模型实时获得的知识,这有助于平滑数据分布并为大型语言模型找到更好的局部最优解。

图 8:SSR 比率
r
^
\hat{r}
r^ 对 Llama-2-7b 在 5 个 SuperNI 任务上的影响。
合成实例数量的影响 在这里,我们定义 r ^ = ∣ d ^ ( i ) ∣ / ∣ d ( i ) ) \hat{r} = \vert \hat{d}^{(i)}\vert / \vert d^{(i)}) r^=∣d^(i)∣/∣d(i))为 SSR 比率,它表示与原始训练数据大小相比,选定的合成数据的比例。默认情况下,我们以 r ^ = 10 % \hat{r} = 10\% r^=10% 的 SSR 比率保留合成实例。然而,如图 8 所示,增加 r ^ \hat{r} r^ 可以进一步提高最终的平均 ROUGE-L(AR),突出了 SSR 的潜力。此外,需要注意的是,在确定合适的 r ^ \hat{r} r^ 时,还应考虑训练成本和内存限制。

SSR vs. 基于正则化和基于架构的方法 在本文中,我们专注于为指令调优生成合成回放数据。先前的工作(Zhang 等人,2023b)已经证明,对于语言模型的指令调优,基于回放的方法通常优于基于正则化和基于架构的方法。表 5 展示了在 CL 顺序 1 下使用两个经典的基于正则化的基准方法(L2 和 EWC)对 Llama-2-7b 的实验结果,SSR 仍然显示出其优越性。此外,这些轻量级策略可以很容易地与 SSR 结合,有可能进一步提高模型性能。而且,基于架构的方法严重依赖于额外的特定任务参数,在大型语言模型的推理时间是关键考虑因素的实际应用中,这可能不太实用。
6. 总结
在这项工作中,我们提出了自合成回放(SSR),这是一个用于缓解大型语言模型中灾难性遗忘的持续学习框架,能够在回放过程中不依赖真实数据而有效地保留知识。通过大量的实验,SSR 展示了其数据效率以及相对于传统基于回放的方法的优越性能。此外,它在特定领域和一般领域都能保留大型语言模型的泛化能力,在实际场景中具有灵活性和稳健性。总体而言,SSR 为大型语言模型在实际环境中的持续学习提供了一个有前景的解决方案,对维持大型语言模型已获得的能力具有重要意义。
局限性
尽管自合成回放(SSR)在平均准确率(AR)和后向传递(BWT)方面表现出优异性能,但如图3(b)所示,它可能并非总能取得最佳的前向传递(FWT)分数。不过,正如在5.4小节所讨论的,SSR有效地保留了大型语言模型在一般领域的泛化能力,凸显了其实际应用价值。关于在5个SuperNI任务上的最终正向传递结果,请参阅附录B中的表7。此外,由于大型语言模型在训练期间的数据偏差,其生成的合成实例可能潜在地包含不安全内容。
🐇速读版
1. 论文要解决什么问题?
背景介绍: 人类在学习一项技能(如算术)之后,仍然能继续学习另外的技能(如翻译),更为关键的是,在学会翻译技能之后,人类不会忘记学过的算术技能,这就是人类具备的持续学习能力。如何让机器具备这种能力,就是机器学习领域的持续学习研究。这篇论文研究的就是如何让大语言模型具备更好的持续学习能力。

难点: 与人类不同,大语言模型是通过参数存储知识的,这就导致大语言模型在持续学习中面临众所周知的灾难性遗忘问题,简单来说就是学了新技能后,参数就变了,参数变了后,之前学的就忘了,如图2所示。因此大语言模型在持续学习过程中如何缓解灾难性遗忘成为研究重点。
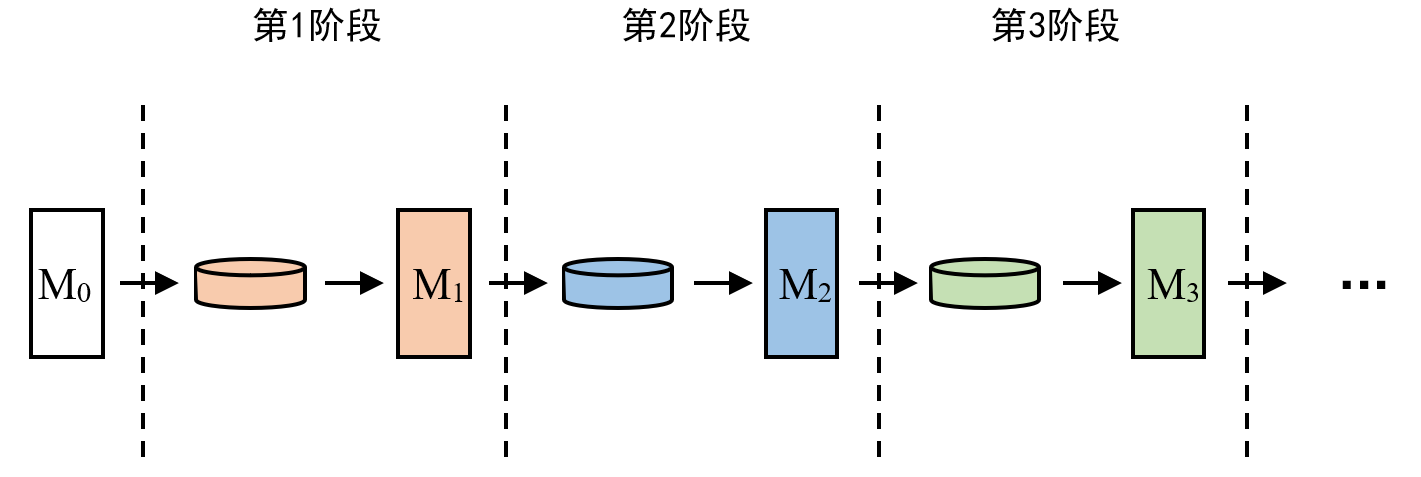
现有方法: 缓解灾难性遗忘的方法大体分为3种:①基于正则化的方法;②基于架构的方法;③基于回放的方法。这篇论文选用的是基于回放的方法(关于①②方法的介绍和弊端,详见精读版第2节相关方法)。基于回放的方法原理很直观,就是模型在学习新技能(如翻译任务)的时候,添加一些旧技能(如问答任务)相关的数据作为回放数据,一起训练模型,这样模型既能学习新技能,也能不忘记旧技能,如图3所示。
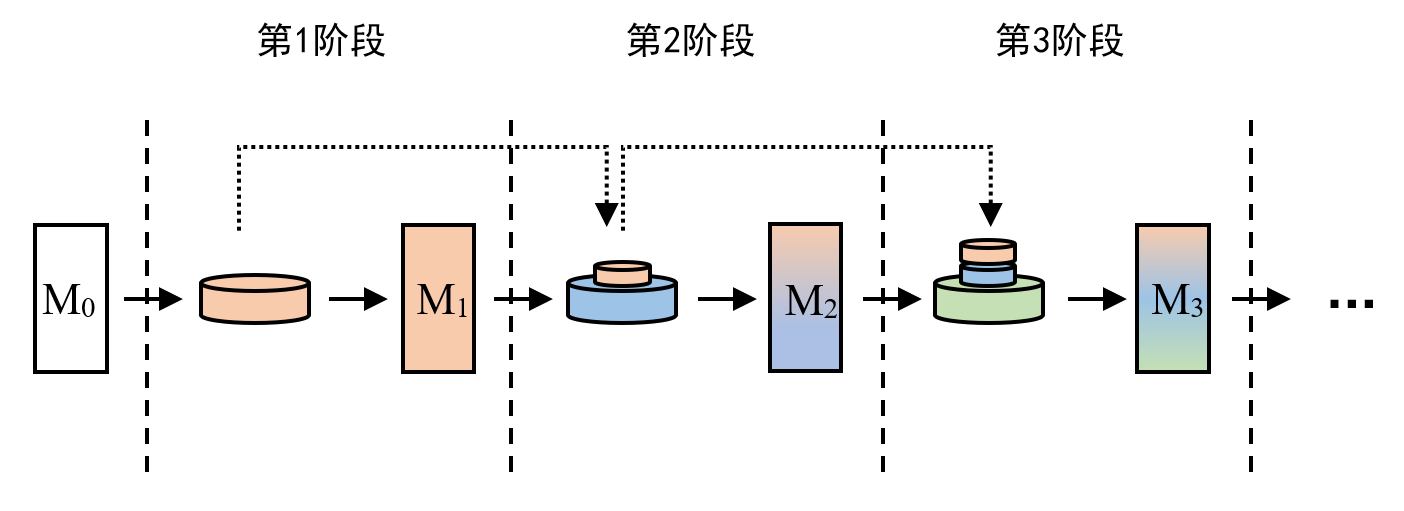
现有方法不足之处: 基于回放的方法核心是要有回放数据,但在实际应用中,旧技能相关的真实数据并不好获取甚至无法获取,如图4所示。例如,公开的大语言模型(例如 Llama-2chat),其原始训练数据可能无法获取,因而无法通过回放数据进行持续学习。因此,本文要解决的问题就是:如何在不使用先前训练阶段的真实数据情况下,仍然能够让大语言模型具备持续学习能力。
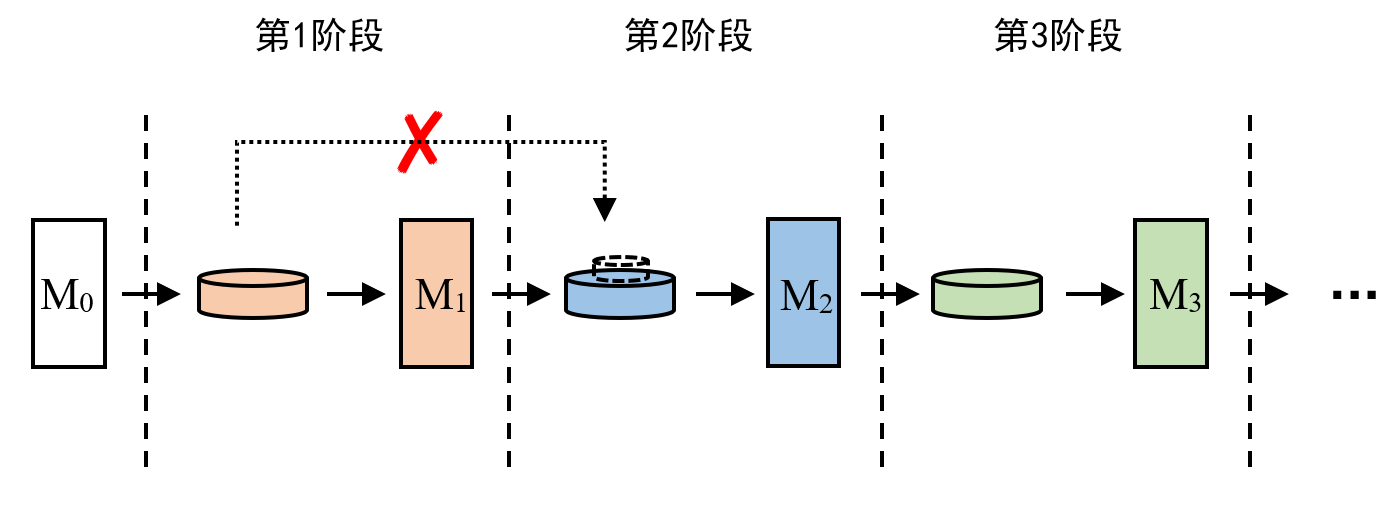
2. 如何解决的?
思路: 既然真实的数据难以获取,那就想办法生成合成数据用于回放。那如何得到高质量的合成数据,则是这篇论文的精华所在。
论文方法:(三步骤生成高质量合成数据用于回放)
- 1.让大语言模型通过上下文学习来生成合成数据
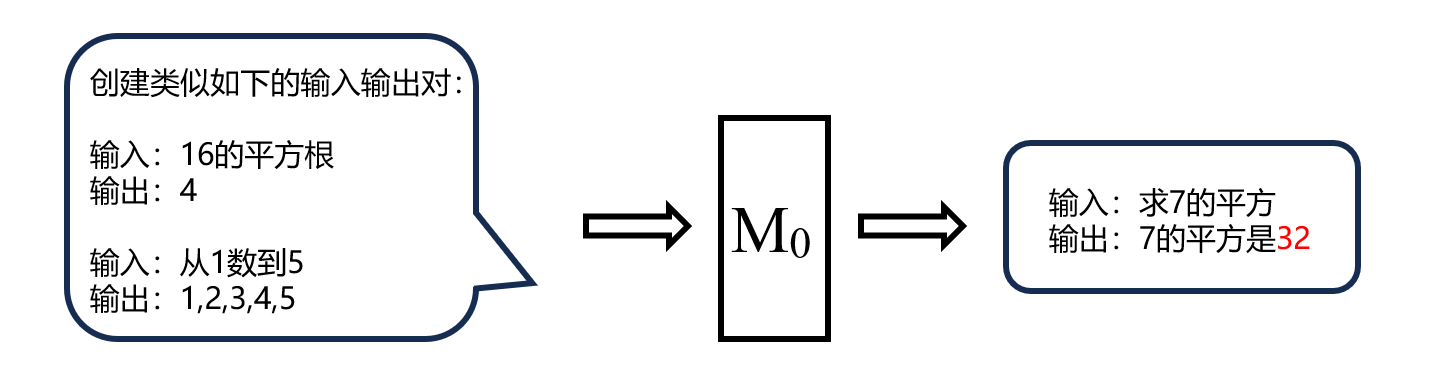
在图2中,假设在第2阶段,我们无法获得上一阶段(第1阶段)的数据用于回放,那么可以先手动构建和第1阶段数据相似内容的数据,然后利用这些数据,通过上下文学习,让基础模型 M 0 M_0 M0来生成合成数据。这里需要强调的是,为什么选择 M 0 M_0 M0而不是上一个任务的模型 M 1 M_1 M1,这是因为之前的研究表面,在特定任务上进行有监督微调(SFT)后,大语言模型的上下文学习能力往往会出现显著下降,因此这里使用上下文能力较强的基础模型 M 0 M_0 M0。但是这一步生成的合成数据质量可能较差,如图5所示。
- 2.合成输出优化
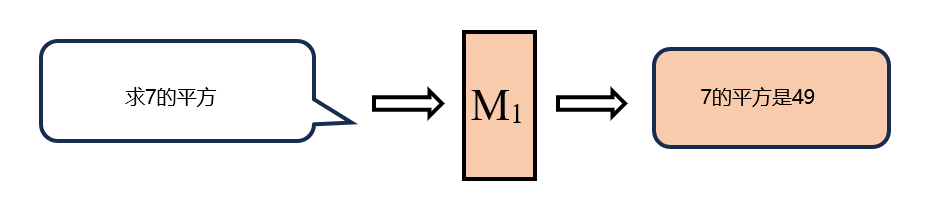
将第一步中得到的合成数据的输入部分通过模型 M 1 M_1 M1,使其产生高质量的输出,从而得到优化的合成数据,如图6所示。
- 3.使用选定的合成实例进行回放
为了进一步确保得到的合成实例的多样性和质量,论文采用 K-means将合成数据聚类,选择靠近聚类中心的一定数量的合成数据作为最终的回放数据以缓解灾难性遗忘问题。至此,实现了在不使用先前训练阶段的真实数据情况下,仍然能够让大语言模型具备持续学习的能力。
3. 方法优点
- 不需要获取先前的真实数据;
- 不需要额外的生成模型构建数据;
- 持续学习过程中还有一个不可忽视的点是,在持续学习各种特定领域技能的过程中,大模型本身的通用领域能力也不应被弱化,本论文通过实验证明所提出方法同样可以有效地保留大语言模型在通用领域的泛化能力。
参考文献
Jianheng Huang, Leyang Cui, Ante Wang, Chengyi Yang, Xinting Liao, Linfeng Song, Junfeng Yao, and Jinsong Su. 2024. Mitigating Catastrophic Forgetting in Large Language Models with Self-Synthesized Rehearsal. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1416–1428, Bangkok, Thailand. Association for Computational Linguistics.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









