






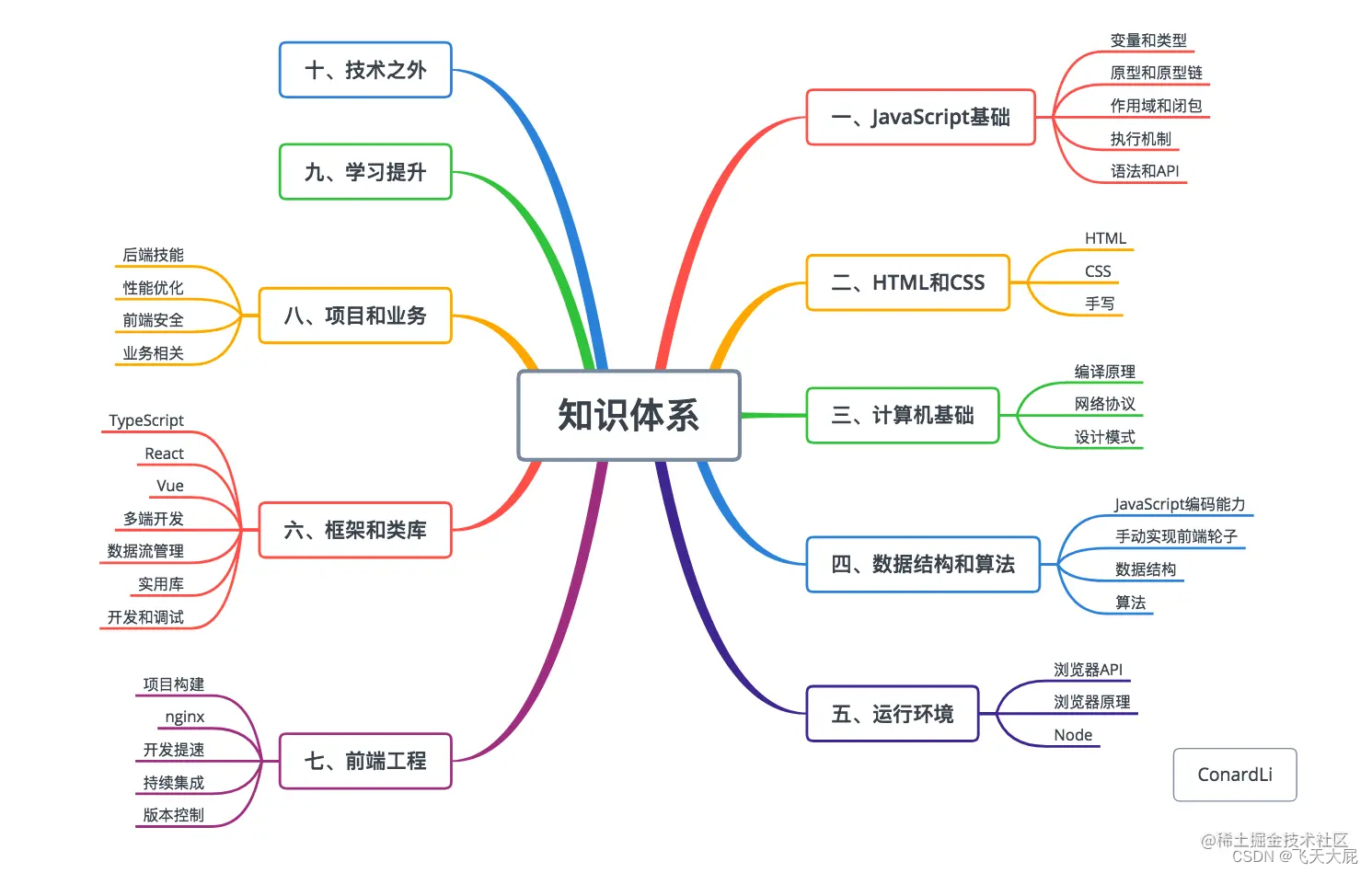
本文取自掘金社区ConardLi大佬的文章《一名【合格】前端工程师的自检清单》,这里对问题的答案进行收集整理!
1.JavaScript规定了几种语言类型?
基本数据类型:number、string、boolean、null、undefined、symbol(es6)
对象引用类型:Array、Function、Object、RegExp、Error、Date
2.JavaScript对象的底层数据结构是什么?
JavaScript 对象的底层数据结构是哈希表(Hash Table)。在 JavaScript 中,对象是一种无序键值对的集合,其中键是字符串类型,值可以是任何类型。为了快速地访问和修改对象的属性,JavaScript 引擎使用了哈希表来实现对象。哈希表是一种基于键值对的数据结构,它通过将键映射为一个索引来实现快速的查找和插入操作。在 JavaScript 中,哈希表被称为对象的属性表。
3.Symbol类型在实际开发中的应用、可手动实现一个简单的Symbol?
Symbol 是 JavaScript 中的一种基本数据类型,用于表示独一无二的值。如果想手动实现一个简单的 Symbol,可以按照以下步骤进行:
(1)创建一个闭包,用于保存已经创建的 Symbol 值。
(2)在闭包中定义一个内部计数器,用于生成唯一的标识符。
(3)定义一个函数,用于创建新的 Symbol 值。
(4)在函数中生成一个唯一的标识符,并将其保存到闭包中。
(5)返回这个标识符。
下面是一个简单的实现示例:
const createSymbol = (() => {
const symbols = {};
let count = 0;
return (description) => {
const symbol = `Symbol(${description || ''})_${count++}`;
symbols[symbol] = true;
return symbol;
};
})();
const symbol1 = createSymbol('foo');
const symbol2 = createSymbol('bar');
console.log(symbol1); // "Symbol(foo)_0"
console.log(symbol2); // "Symbol(bar)_1"
console.log(symbol1 === symbol2); // false
这个实现生成的 Symbol 值类似于 JavaScript 中的内置 Symbol 值,每个值都是唯一的并且不可变。但是需要注意的是,这个实现是不完整的,它没有实现 Symbol 的所有特性,比如说无法使用 typeof 操作符判断一个值是否为 Symbol。
4.JavaScript中的变量在内存中的具体存储形式?
在 JavaScript 中,变量的具体存储形式取决于变量的数据类型。基本数据类型的变量(如数字、字符串等)通常直接存储在栈中,而对象类型的变量(如数组、对象等)则存储在堆中,而变量名则存储在栈中,并指向相应的内存地址。函数作为一种特殊对象类型,也被存储在堆中。当变量被声明时,JavaScript 引擎会自动分配内存,并在变量赋值时将值存储在相应的内存位置。当变量不再被使用时,JavaScript 引擎会自动处理内存回收,以便释放不再使用的内存。
5.基本类型对应的内置对象,以及他们之间的装箱拆箱操作?
在 JavaScript 中,基本类型和对应的内置对象之间可以进行装箱和拆箱操作。装箱操作指的是将基本类型的值转换为对应的内置对象,拆箱操作则是将内置对象转换为基本类型的值。例如,可以使用以下方式进行装箱操作:
// 字符串装箱
const str = 'hello';
const strObj = new String(str);
// 数字装箱
const num = 123;
const numObj = new Number(num);
// 布尔值装箱
const bool = true;
const boolObj = new Boolean(bool);
可以使用以下方式进行拆箱操作:
// 字符串拆箱
const strObj = new String('hello');
const str = strObj.valueOf();
// 数字拆箱
const numObj = new Number(123);
const num = numObj.valueOf();
// 布尔值拆箱
const boolObj = new Boolean(true);
const bool = boolObj.valueOf();
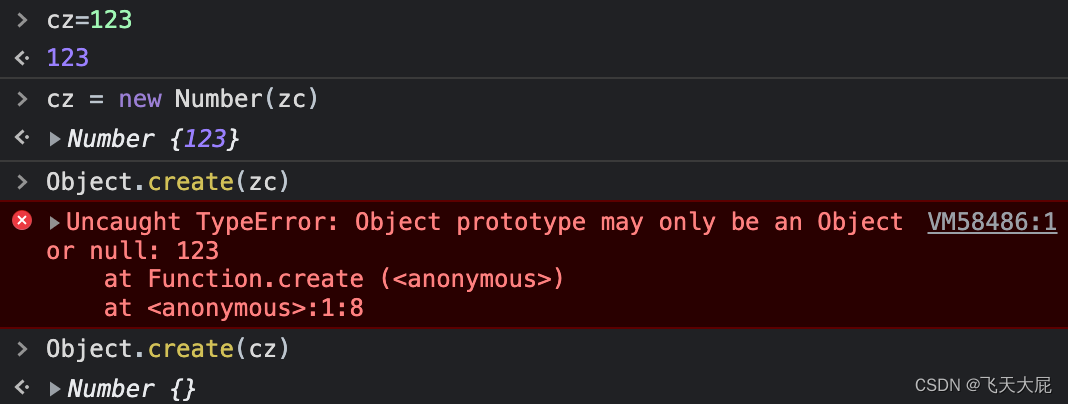
需要注意的是,基本类型和对应的内置对象并不完全等价。例如,对于字符串类型,基本类型的值是不可变的,而字符串对象是可变的。因此,在进行比较时应该使用严格相等运算符"===" 而不是相等运算符。
由于 JavaScript 引擎在处理基本类型和对象类型时的内部实现方式不同,装箱和拆箱操作可能会产生一定的性能开销。因此,在开发中应尽量避免不必要的装箱和拆箱操作,尽量使用基本类型进行数值计算和比较操作。
JavaScript 是一种动态类型语言,它的变量可以存储不同类型的值,包括基本类型和对象类型。为了方便开发者在处理基本类型和对象类型时可以统一使用相同的语法和操作符,JavaScript 引入了装箱和拆箱操作。
装箱操作是将基本类型的值转换为对应的对象类型,这样就可以使用对象的方法和属性对其进行操作。例如,使用字符串对象的 length 属性获取字符串的长度。拆箱操作则是将对象类型转换为基本类型的值,这样就可以直接进行数值计算和比较操作。
如图通过装箱操作的对象可以调用对象的方法,字面量创建会报错
6.理解值类型和引用类型?
值类型的特点是它们的值在内存中占据独立的空间,每个变量在内存中都有自己的副本,因此它们之间的比较是按值比较的。
引用类型的特点是它们的值在内存中不是独立存在的,而是存储在内存中的对象中,变量保存的是对象的地址,因此它们之间的比较是按引用比较的。
当我们对值类型进行赋值时,会在内存中创建一个新的值,变量指向这个新的值。而对引用类型进行赋值时,只是将变量指向内存中的对象,而不是创建一个新的对象。
理解值类型和引用类型对于理解 JavaScript 中的变量赋值、函数参数传递、对象属性访问等操作非常重要。
7.null和undefined的区别?
在JavaScript中,null和undefined是两个不同的值,它们有以下区别:
- undefined表示一个变量没有被定义或者没有被赋值,而null表示变量被显式地赋值为null。
- 如果一个函数没有返回值,它将默认返回undefined,而不是null。
- 当使用==,运算符时,null和undefined被认为是相等的,但当使用===运算符时,它们被认为是不相等的。
- 当访问对象的属性时,如果属性不存在,将返回undefined,而不是null。
总之,null表示一个空值,而undefined表示一个未定义的值。
8.至少可以说出三种判断JavaScript数据类型的方式,以及他们的优缺点,如何准确的判断数组类型?
- typeof 运算符:可以用来判断大多数基本数据类型,返回值为字符串。例如:typeof 123 返回 “number”,typeof “hello” 返回 “string”。
原理:typeof 运算符返回一个字符串,表示未经计算的操作数的类型。它对于大多数基本数据类型都可以正确判断,但对于 null 和一些对象类型如 Date、Array 等则有限制。 - instanceof 运算符:可以用来判断对象的具体类型,返回值为布尔值。例如:[] instanceof Array 返回 true,new Date() instanceof Date 返回 true。
原理:instanceof 运算符通过判断一个对象是否是某个构造函数的实例来判断其类型。例如,[] instanceof Array 表示空数组 [] 是否是 Array 构造函数的实例,如果是则返回 true,否则返回 false。 - Object.prototype.toString 方法:可以用来判断大多数数据类型,返回值为字符串。例如:Object.prototype.toString.call([]) 返回 “[object Array]”,Object.prototype.toString.call({}) 返回 “[object Object]”。
原理:Object.prototype.toString 方法返回一个表示对象的字符串,其中 [object Type] 中的 Type 表示对象的具体类型。通过使用 call 方法可以将该方法应用于不同的对象。 - Array.isArray 方法:可以用来判断是否为数组类型,返回值为布尔值。例如:Array.isArray([]) 返回 true,Array.isArray({}) 返回 false。
原理:Array.isArray 方法用于判断一个对象是否为数组类型。如果是数组则返回 true,否则返回 false。
9.可能发生隐式类型转换的场景以及转换原则,应如何避免或巧妙应用?
Number.toString()
String(null) // 'null'
String(undefined) // 'undefined'
Number('123') // 123
Number(null) // 0
Number(false) // 0
Number('') // 0
Number(true) // 1
parseFloat('111.111.111') // 111.111
Number(undefined) // NaN
Number('a') // NaN
parseFloat('a111.111') // NaN
Bollean(0) // false
Bollean('') // false
Bollean(null) // false
Bollean(NaN) // false
Bollean(undefined) // false
// +
'1' + 1 // '11'
'a' + 1 // 'a1'
// -、*、/、%
1 - '2' // -1
1 - 'a' // NaN
1 * '2' // 2
1 * 'a' // NaN
1 / '2' // 2
1 / 'a' // NaN
1 % '2' // 2
1 % 'a' // NaN
// ==
'' == false // 0 == 0 true
0 == false // 0 == 0 true
10.出现小数精度丢失的原因,JavaScript可以存储的最大数字、最大安全数字,JavaScript处理大数字的方法、避免精度丢失的方法?
11.理解原型设计模式以及JavaScript中的原型规则?
JavaScript原型设计模式是一种面向对象编程的方法,它使用原型链来实现对象之间的继承关系。在这种模式中,每个对象都有一个原型对象,它定义了对象共享的属性和方法。当对象需要访问这些属性和方法时,它会沿着原型链向上查找,直到找到相应的属性或方法为止。
使用原型设计模式可以减少代码量,提高程序的性能和可维护性。它也是JavaScript中实现继承的主要方式之一。在这种模式中,可以使用Object.create()方法来创建新对象,并将其原型设置为另一个对象。这样就可以实现对象之间的继承关系。
在JavaScript中,原型规则是指对象之间通过原型链继承属性和方法的机制。具体来说,原型规则包括以下几条:
1.每个对象都有一个原型对象,它定义了对象共享的属性和方法。
2.如果一个对象的属性或方法在自身找不到,它会沿着原型链向上查找,直到找到相应的属性或方法为止。
3.如果一个对象的原型是null,那么它没有原型链,也就是说它没有继承任何属性或方法。
4.可以使用Object.create()方法来创建新对象,并将其原型设置为另一个对象,从而实现继承。
5.可以使用prototype属性来给对象添加共享的属性和方法。
6.在使用构造函数创建对象时,可以通过将构造函数的prototype属性设置为一个对象来为该构造函数创建一个原型对象,从而实现构造函数的继承。
遵循原型规则可以使代码更加简洁和易于维护,同时也可以提高程序的性能。
12.instanceof的底层实现原理,手动实现一个instanceof?
function myInstanceof(obj, constructor) {
let proto = Object.getPrototypeOf(obj); // 获取 obj 的原型对象
while (proto) {
if (proto === constructor.prototype) { // 判断原型对象是否等于构造函数的原型对象
return true;
}
proto = Object.getPrototypeOf(proto); // 获取下一个原型对象
}
return false;
}
使用示例:
function Person(name) {
this.name = name;
}
let p = new Person('Tom');
console.log(myInstanceof(p, Person)); // true
console.log(myInstanceof(p, Object)); // true
console.log(myInstanceof(p, Array)); // false
注意:这个实现只是一个简单的示例,不考虑一些特殊情况,例如原型对象为 null 的情况。在实际项目中,建议使用 JavaScript 内置的 instanceof 运算符。
18.词法作用域和动态作用域?
JavaScript使用词法作用域,也称为静态作用域,它决定了变量在函数内的可见性。词法作用域是在代码编写阶段就确定的,与函数的调用位置无关。
动态作用域是一种不同的作用域规则,它是在运行时根据函数的调用栈确定变量的可见性。在动态作用域中,变量的可见性取决于函数的调用顺序,而不是函数在代码中的位置。JavaScript不支持动态作用域。
19.理解JavaScript的作用域和作用域链?
JavaScript中的作用域指的是变量和函数在代码中可访问的范围。JavaScript采用的是词法作用域,在函数定义时确定作用域,而不是在函数调用时确定。
作用域链是指在当前作用域中查找变量或函数时所需要经过的所有父级作用域。如果在当前作用域中找不到所需的变量或函数,就会沿着作用域链一层层地向上查找,直到找到为止,或者一直查找到全局作用域仍未找到。
JavaScript变量和函数的作用域链是由它们定义时所处的位置和它们嵌套的作用域决定的。在函数内部可以访问外部作用域中的变量和函数,而在外部作用域中无法访问函数内部的变量和函数。
20.理解JavaScript的执行上下文栈?
JavaScript中的执行上下文栈(Execution Context Stack)是用于管理代码执行上下文的一种数据结构。每次函数调用时,都会创建一个新的执行上下文,并将其推入执行上下文栈的顶部。函数执行完成后,相应的执行上下文会从栈中弹出,控制权会回到上一个执行上下文。
当JavaScript引擎在执行代码时,它会首先创建全局执行上下文,并将其推入执行上下文栈的底部。然后,每当函数被调用时,就会创建一个新的执行上下文,并将其推入栈的顶部。当函数执行完成后,相应的执行上下文会从栈中弹出,控制权会回到上一个执行上下文。
执行上下文栈的主要作用是确保代码的执行顺序和上下文的正确管理。通过使用执行上下文栈,JavaScript引擎可以轻松地跟踪哪些代码正在执行,以及它们在代码中的位置。
21.this的原理以及几种不同使用场景的取值?
- 函数是否在 new 中调用(new 绑定)?如果是的话 this 绑定的是新创建的对象。
var bar = new foo() - 函数是否通过 call、apply(显式绑定)或者硬绑定调用?如果是的话,this 绑定的是
指定的对象。
var bar = foo.call(obj2) - 函数是否在某个上下文对象中调用(隐式绑定)?如果是的话,this 绑定的是那个上
下文对象。
var bar = obj1.foo() - 如果都不是的话,使用默认绑定。如果在严格模式下,就绑定到 undefined,否则绑定到
全局对象。
var bar = foo()
22.闭包的实现原理和作用,可以列举几个开发中闭包的实际应用?
JavaScript 中的闭包指的是一个函数可以访问其定义时所在的词法作用域中的变量和参数,即使在函数被调用和返回之后,依然可以访问这些变量和参数。这是因为闭包会创建一个封闭的环境,保存了函数定义时所在的作用域的状态。
实现原理:当一个函数被定义时,它会创建一个词法环境,并将该环境保存在函数的内部属性 [[Environment]] 中。当函数返回时,该词法环境不会被销毁,而是被闭包持有。因此,闭包可以访问该环境中的变量和参数。
作用:
- 模块化开发:通过使用闭包,可以创建私有的变量和函数,防止全局命名空间的污染,从而实现模块化开发。
- 事件处理:在事件处理中,闭包可以保存事件处理函数中的一些状态信息,这些状态信息可以被事件处理函数之外的代码所访问和修改。
- 防抖和节流:防抖和节流都是在一定时间内防止函数被频繁调用的技术。闭包可以用于保存最后一次执行函数的时间,从而实现防抖和节流效果。
- 记忆化缓存:闭包可以用于实现记忆化缓存,即在函数执行时缓存某些结果,下次调用函数时直接返回缓存结果,避免重复计算。
- 封装私有变量:JavaScript中没有类的概念,但是可以通过闭包来实现类似的封装私有变量的功能。
- 异步编程:一些异步编程的技术,例如Promise和async/await,都是基于闭包实现的。
23.堆栈溢出和内存泄漏的原理,如何防止?
JS堆栈溢出是指当JS引擎执行函数时,如果函数调用栈的深度超过了JS引擎的限制,就会导致堆栈溢出错误。JS内存泄漏是指因为代码错误或逻辑问题导致不再使用的对象仍然被占用,从而导致内存不断增长,最终导致程序崩溃。
堆栈溢出的原理:当一个函数被调用时,JS引擎会将该函数的调用信息(如函数名、参数、返回地址等)保存到一个数据结构中,称为调用栈。每当一个函数调用另一个函数时,JS引擎会将该函数的调用信息也压入调用栈中,直到函数返回。如果函数调用栈的深度超过了JS引擎的限制,就会导致堆栈溢出错误。
内存泄漏的原理:JS中的内存是自动管理的,即由JS引擎自动分配和回收。当一个对象不再被引用时,JS引擎会自动将其标记为垃圾对象,并在适当的时候回收其占用的内存。但是,如果代码中存在循环引用、闭包等问题,就可能导致对象不能被正确地回收,从而发生内存泄漏。
防止堆栈溢出和内存泄漏的方法:
- 减少函数调用深度:尽量避免使用过多的嵌套函数,可以通过重构代码、使用循环等方式来减少函数调用深度。
- 优化递归算法:如果必须使用递归算法,可以考虑使用尾递归优化,减少函数调用深度。
- 使用定时器和异步编程:定时器和异步编程可以避免函数调用栈过深,从而减少堆栈溢出的风险。
- 避免循环引用和闭包:注意避免循环引用和过多的闭包,可以使用垃圾回收器来检测和回收不再使用的对象。
- 及时释放资源:如果代码中使用了大量的全局变量、DOM元素等资源,应该及时释放这些资源,避免内存泄漏。
- 使用工具检测和分析:可以使用Chrome DevTools等工具来检测和分析代码中的性能问题和内存泄漏。
24.如何处理循环的异步操作?
在 JavaScript 中,循环中的异步操作可能会导致意外的行为,因为循环会在异步操作完成之前继续执行,导致结果不如预期。为了解决这个问题,可以使用一些技术来处理循环的异步操作。
- 使用
for await...of循环:for await...of循环是异步迭代器的一种方式,它可以在每次迭代之间暂停执行,等待异步操作完成后再继续执行。
async function asyncForEach(array, callback) {
for await (let item of array) {
await callback(item);
}
}
asyncForEach([1, 2, 3], async (num) => {
console.log(num);
await new Promise(resolve => setTimeout(resolve, 1000));
});
- 使用
Promise.all:Promise.all可以将多个异步操作组合成一个 Promise,等待所有操作完成后再继续执行。
async function asyncForEach(array, callback) {
await Promise.all(array.map(async (item) => {
await callback(item);
}));
}
asyncForEach([1, 2, 3], async (num) => {
console.log(num);
await new Promise(resolve => setTimeout(resolve, 1000));
});
- 使用递归:递归可以避免循环中的异步操作影响下一次迭代。
async function asyncForEach(array, callback, index = 0) {
if (index >= array.length) return;
await callback(array[index]);
await asyncForEach(array, callback, index + 1);
}
asyncForEach([1, 2, 3], async (num) => {
console.log(num);
await new Promise(resolve => setTimeout(resolve, 1000));
});
25.理解模块化解决的实际问题,可列举几个模块化方案并理解其中原理?
26.JavaScript如何实现异步编程,可以详细描述EventLoop机制?
27.宏任务和微任务分别有哪些?
宏任务:
- 整个 JS 脚本程序;
setTimeout()和setInterval()创建的定时器任务;- 用户交互事件处理函数,例如
click、keydown、scroll等; - 网络请求、文件读写等异步操作的回调函数;
requestAnimationFrame()动画渲染任务等。
微任务:Promise的then()和catch()回调函数;async/await中的await表达式;queueMicrotask()API 创建的微任务。
使用Promise实现串行操作可以通过Promise的then方法实现。具体实现方法如下:
28.使用Promise实现串行?
function serialPromise(tasks) {
return tasks.reduce((promiseChain, currentTask) => {
return promiseChain.then(chainResults =>
currentTask().then(currentResult =>
[...chainResults, currentResult]
)
);
}, Promise.resolve([]));
}
这里的tasks是一个包含多个函数的数组,每个函数都返回一个Promise对象。serialPromise函数会依次执行这些函数,并将它们的结果收集到一个数组中。调用serialPromise函数会返回一个Promise对象,该对象在所有函数执行完毕后解析出一个包含所有结果的数组。
29.Node与浏览器EventLoop的差异?
浏览器时间循环机制:
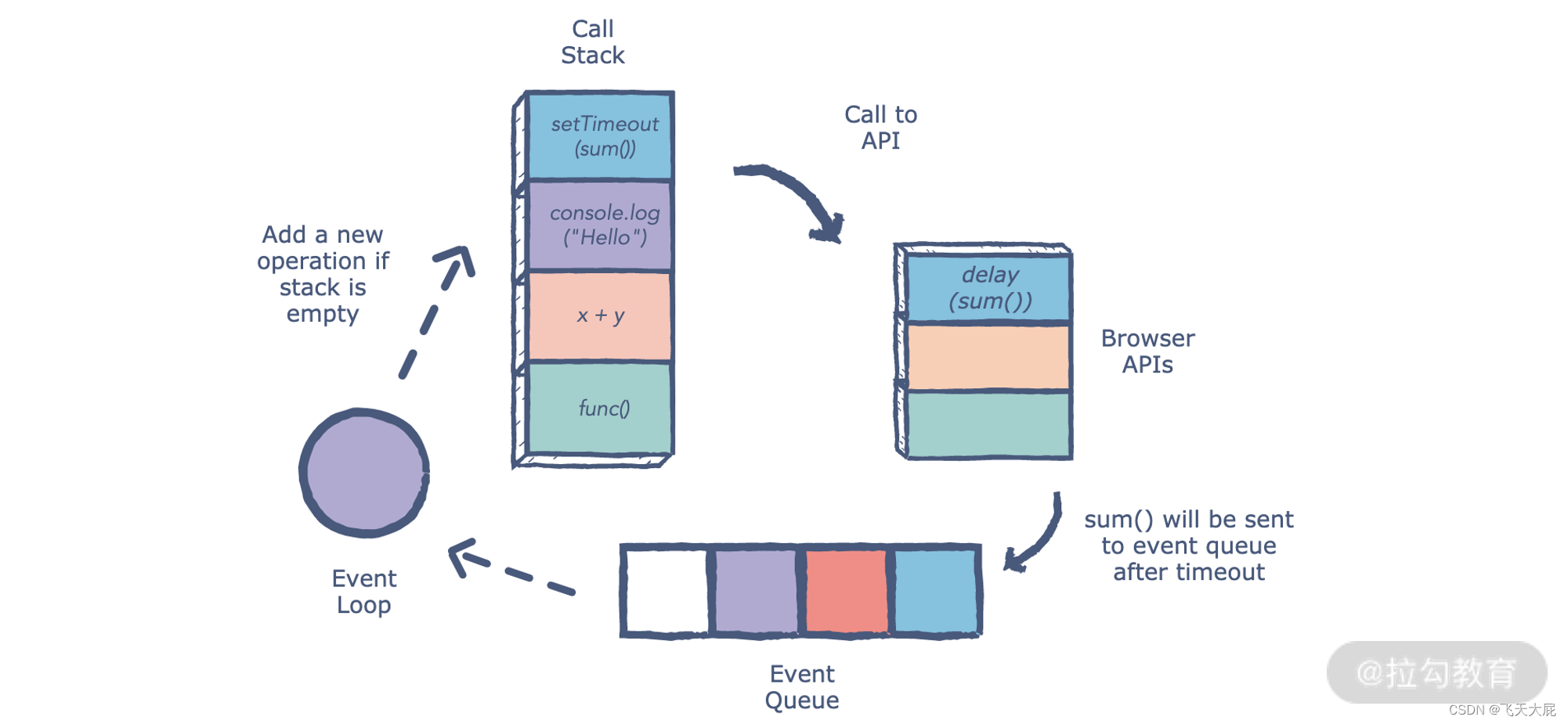
1.JavaScript 引擎首先从宏任务队列(macrotask queue)中取出第一个任务;
2.执行完毕后,再将微任务(microtask queue)中的所有任务取出,按照顺序分别全部执行(这里包括不仅指开始执行时队列里的微任务),如果在这一步过程中产生新的微任务,也需要执行;
3.然后再从宏任务队列中取下一个,执行完毕后,再次将 microtask queue 中的全部取出,循环往复,直到两个 queue 中的任务都取完。
总结起来就是:一次 Eventloop 循环会处理一个宏任务和所有这次循环中产生的微任务。
node事件循环机制:
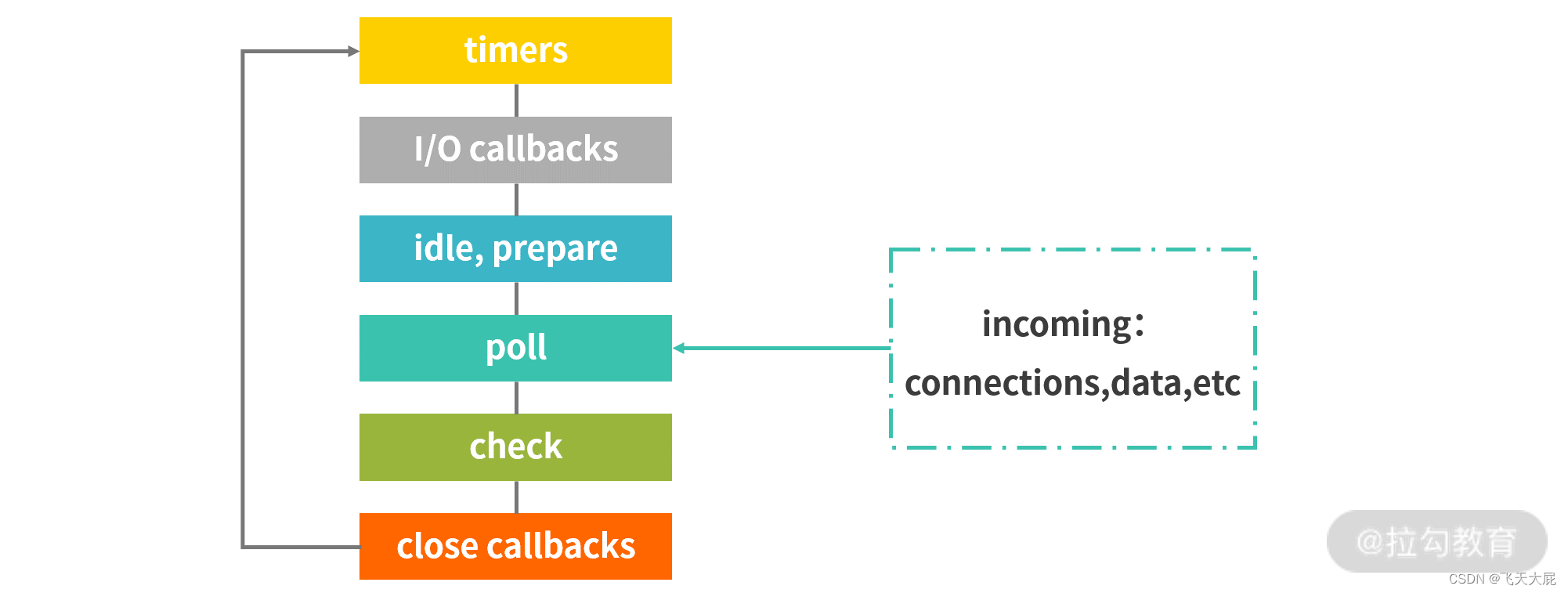
整个流程分为六个阶段,当这六个阶段执行完一次之后,才可以算得上执行了一次 Eventloop 的循环过程。我们来分别看下这六个阶段都做了哪些事情。
Timers 阶段:这个阶段执行 setTimeout 和 setInterval。
I/O callbacks 阶段:这个阶段主要执行系统级别的回调函数,比如 TCP 连接失败的回调。
idle,prepare 阶段:只是 Node.js 内部闲置、准备,可以忽略。
poll 阶段:poll 阶段是一个重要且复杂的阶段,几乎所有 I/O 相关的回调,都在这个阶段执行(除了setTimeout、setInterval、setImmediate 以及一些因为 exception 意外关闭产生的回调),这个阶段的主要流程如下图所示。
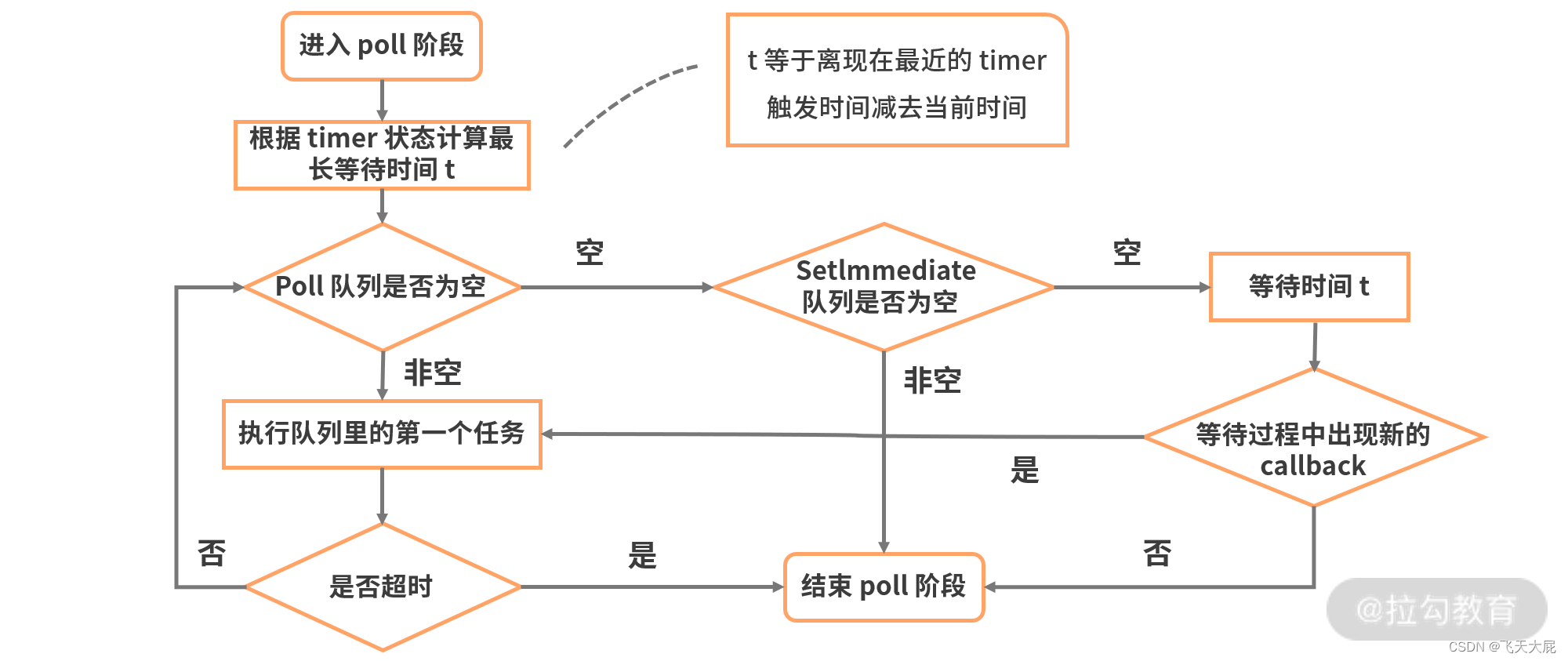
check 阶段:执行 setImmediate() 设定的 callbacks。
close callbacks 阶段:执行关闭请求的回调函数,比如 socket.on(‘close’, …)。
30.如何在保证页面运行流畅的情况下处理海量数据?
处理海量数据时,可以采用以下策略来保证页面运行流畅:
- 分批处理数据:将数据分批处理,每次处理一小部分数据,避免一次性处理过多数据导致页面卡顿或崩溃。
- 使用 Web Worker:将数据处理放到 Web Worker 中,避免阻塞主线程,提高页面的响应速度。
- 虚拟滚动:对于需要展示大量数据的列表或表格等组件,可以采用虚拟滚动的方式,只渲染当前可见部分的数据,避免一次性渲染过多数据导致页面卡顿。
- 数据缓存:对于需要频繁操作的数据,可以采用数据缓存的方式,避免频繁地读写数据。
- 优化算法:对于数据处理的算法进行优化,减小时间复杂度和空间复杂度,提高数据处理效率。
- 使用节流或防抖技术:对于一些频繁触发的事件,如窗口大小变化、滚动等,可以使用节流或防抖技术来减少事件触发的频率,减轻页面的负担。
31.数组常用方法
1. push() - 将一个或多个元素添加到数组的末尾
2. pop() - 从数组的末尾删除一个元素
3. shift() - 从数组的开头删除一个元素
4. unshift() - 在数组的开头添加一个或多个元素
5. splice() - 从数组中添加或删除元素
6. slice() - 返回一个新的数组,该数组包含原始数组的一部分
7. concat() - 合并两个或多个数组
8. join() - 将数组中的元素作为字符串连接起来
9. reverse() - 反转数组中的元素顺序
10. sort() - 对数组中的元素进行排序
11. forEach() - 遍历数组中的每个元素,并为每个元素执行回调函数
12. map() - 遍历数组中的每个元素,并为每个元素执行回调函数,然后将每个回调函数的返回值组成一个新的数组返回
13. filter() - 遍历数组中的每个元素,并将符合条件的元素组成一个新的数组返回
14. reduce() - 遍历数组中的每个元素,并将它们组合成一个值
15. find() - 返回数组中符合条件的第一个元素
16. findIndex() - 返回数组中符合条件的第一个元素的索引
17. indexOf() - 返回数组中第一个匹配项的索引
18. lastIndexOf() - 返回数组中最后一个匹配项的索引
19. includes() - 判断数组是否包含某个元素
20. every() - 判断数组中的每个元素是否都符合条件
21. some() - 判断数组中是否有元素符合条件
还有一些其他的方法,可以在JavaScript文档中找到。
32.对象常用方法
以下是 JavaScript 对象的一些常用方法:
1. Object.assign() - 将一个或多个源对象的属性复制到目标对象中,返回目标对象
2. Object.keys() - 返回一个数组,其中包含对象的所有可枚举属性的名称
3. Object.values() - 返回一个数组,其中包含对象的所有可枚举属性的值
4. Object.entries() - 返回一个数组,其中包含对象的所有可枚举属性的键值对数组
5. Object.freeze() - 冻结一个对象,使其不可更改
6. Object.seal() - 封闭一个对象,使其不可添加或删除属性,但可以修改属性值
7. Object.create() - 创建一个新对象,并将其原型设置为指定对象
8. Object.defineProperty() - 定义一个对象的属性
9. Object.getOwnPropertyDescriptor() - 返回指定对象属性的描述符
10. Object.is() - 比较两个值是否相同
11. Object.toString() - 将对象转换为字符串
12. Object.hasOwnProperty() - 判断对象是否具有指定的属性
13. Object.getOwnPropertyNames() - 返回一个数组,其中包含对象的所有属性的名称,不仅限于可枚举属性
14. Object.getPrototypeOf() - 返回一个对象的原型
这些方法只是 JavaScript 对象方法中的一部分,还有其他方法可以在 JavaScript 文档中找到。
33.字符串常用方法
以下是 JavaScript 字符串的一些常用方法:
1. str.length - 返回字符串的长度
2. str.charAt(index) - 返回指定位置的字符
3. str.charCodeAt(index) - 返回指定位置的字符的 Unicode 值
4. str.concat(str1, str2, ..., strN) - 连接两个或多个字符串,返回新字符串
5. str.includes(searchString, position) - 判断字符串是否包含指定的子字符串
6. str.indexOf(searchValue, fromIndex) - 返回指定值在字符串中第一次出现的位置
7. str.lastIndexOf(searchValue, fromIndex) - 返回指定值在字符串中最后一次出现的位置
8. str.slice(start, end) - 提取字符串的一部分并返回一个新字符串
9. str.substr(start, length) - 提取字符串的一部分并返回一个新字符串
10. str.substring(start, end) - 提取字符串的一部分并返回一个新字符串
11. str.toLowerCase() - 将字符串转换为小写字母
12. str.toUpperCase() - 将字符串转换为大写字母
13. str.trim() - 去除字符串两端的空格
14. str.replace(searchValue, replaceValue) - 替换字符串中的指定值,并返回新字符串
15. str.split(separator, limit) - 将字符串分割成数组
这些方法只是 JavaScript 字符串方法中的一部分,还有其他方法可以在 JavaScript 文档中找到。
34.数字常用方法
以下是 JavaScript 数字类型的一些常用方法:
1. Number() - 将其他数据类型转换为数字
2. parseInt() - 将字符串转换为整数
3. parseFloat() - 将字符串转换为浮点数
4. isNaN() - 判断一个值是否为 NaN
5. isFinite() - 判断一个值是否为有限数值
6. toFixed() - 将数字保留指定位数的小数
7. toPrecision() - 将数字格式化为指定位数的有效数字
8. toString() - 将数字转换为字符串
9. Math.abs() - 返回一个数的绝对值
10. Math.ceil() - 返回大于或等于一个数的最小整数
11. Math.floor() - 返回小于或等于一个数的最大整数
12. Math.round() - 返回四舍五入后的整数
13. Math.max() - 返回一组数中的最大值
14. Math.min() - 返回一组数中的最小值
15. Math.random() - 返回一个随机数
这些方法只是 JavaScript 数字类型方法中的一部分,还有其他方法可以在 JavaScript 文档中找到。
React篇
1.说说你对React的渲染原理的理解?
在React中,先执行useEffect还是先渲染取决于useEffect的依赖项和副作用函数的执行时间。
如果一个组件在首次渲染时,存在useEffect的副作用函数,并且该副作用函数不依赖于任何状态或属性,那么React会先执行该副作用函数,然后再进行组件的渲染。
如果一个组件在首次渲染时,存在useEffect的副作用函数,并且该副作用函数依赖于某些状态或属性,那么React会先进行组件的渲染,然后再执行该副作用函数。
当组件发生更新时,React会先执行组件的渲染,然后再执行useEffect的副作用函数。如果一个组件的多个useEffect钩子函数中存在依赖关系,React会按照它们在代码中出现的顺序依次执行。
2.什么是渲染劫持?
React渲染劫持通常指在React组件渲染期间修改其输出结果的技术。这可以通过许多方式实现,包括使用React生命周期方法、高阶组件、React Hooks和自定义渲染器等。渲染劫持通常用于添加或修改组件的行为,例如添加额外的样式或事件处理程序,或者在组件渲染期间执行某些任务。但是,渲染劫持也可能会引入一些问题,例如影响组件的性能或导致意外的副作用。因此,需要小心地使用它们,并确保在组件上下文中使用它们时保持透明。React渲染劫持通常指在React组件渲染期间修改其输出结果的技术。这可以通过许多方式实现,包括使用React生命周期方法、高阶组件、React Hooks和自定义渲染器等。渲染劫持通常用于添加或修改组件的行为,例如添加额外的样式或事件处理程序,或者在组件渲染期间执行某些任务。但是,渲染劫持也可能会引入一些问题,例如影响组件的性能或导致意外的副作用。因此,需要小心地使用它们,并确保在组件上下文中使用它们时保持透明。
一个常见的渲染劫持的例子是使用高阶组件(Higher-Order Component,HOC)来包装现有的React组件,以添加一些额外的功能。例如,可以编写一个名为withLogging的HOC,该HOC会在组件渲染时记录一些调试信息。下面是一个示例代码:
function withLogging(WrappedComponent) {
return class extends React.Component {
componentDidMount() {
console.log(`Component ${WrappedComponent.name} mounted`);
}
componentWillUnmount() {
console.log(`Component ${WrappedComponent.name} will unmount`);
}
render() {
return <WrappedComponent {...this.props} />;
}
}
}
上述代码中的withLogging函数接受一个现有的React组件作为参数,并返回一个新的组件类,该类是一个高阶组件。新的组件类在componentDidMount和componentWillUnmount生命周期方法中添加了一些额外的日志记录逻辑。然后,它通过render方法调用原始的组件,并将其所有的props传递给它。
使用这个HOC,可以轻松地为任何React组件添加日志记录功能:
const MyComponent = (props) => {
return <div>Hello, {props.name}!</div>;
};
const LoggedComponent = withLogging(MyComponent);
ReactDOM.render(
<LoggedComponent name="World" />,
document.getElementById('root')
);
在这个例子中,MyComponent是一个简单的React函数组件,它接受一个name属性并显示一条问候消息。然后,我们使用withLogging函数将其包装,并将返回的高阶组件赋值给LoggedComponent变量。最后,我们使用LoggedComponent作为渲染树的根节点来渲染整个应用程序。这样,在组件的挂载和卸载过程中,我们将看到一些额外的日志输出,以帮助调试组件。
3.你对context的理解?
1、类组件之contextType 方式:类上面有一个静态contextType属性,这个属性可以指向provider提供的context值。
2、函数组件之 useContext 方式:钩子函数useConext()可以传入一个 provider参数,这个钩子返回的是context的对象
3、订阅者之 Consumer 方式:const ThemeConsumer = ThemeContext.Consumer,ThemeConsumer是一个函数组件,其子组件可以使用订阅的contextValue。
总结:在 Provider 里 value 的改变,会使引用contextType,useContext 消费该 context 的组件重新 render ,同样会使 Consumer 的 children 函数重新执行,与前两种方式不同的是 Consumer 方式,当 context 内容改变的时候,不会让引用 Consumer 的父组件重新更新。
在React中,Context对象有一个可选属性displayName,它是一个字符串,用于在React开发者工具中标识这个Context。
如果创建Context时没有设置displayName属性,React会自动为它生成一个默认的displayName,格式为"Context"加上Context对象的ID号。这个默认的displayName不太友好,可能不太容易识别。
因此,建议在创建Context对象时设置displayName属性,以便在React开发者工具中更好地识别它。例如:
const MyContext = React.createContext();
MyContext.displayName = 'MyContext';
这样,在React开发者工具中,就可以看到这个Context的名称是"MyContext",而不是默认的"Context123"之类的名称。
当一个Consumer无法找到它所需要的Provider时,会抛出一个错误。这个错误的信息通常会提示哪个Context没有被正确地提供。
通常情况下,解决这个问题的方法是要么在合适的地方提供正确的Context,要么在Consumer组件中设置一个默认值,以避免在没有提供Context的情况下出现错误。
一种设置默认值的方法是使用Context对象的defaultValue属性。例如,如果我们有一个名为MyContext的Context,可以这样设置默认值:
const MyContext = React.createContext('default value');
这里将'default value'作为默认值传递给了createContext函数。如果没有提供正确的Provider,Consumer就会使用这个默认值。
当然,这种设置默认值的方法只适用于Context的值是基本类型(例如字符串、数字、布尔值等)的情况。如果Context的值是一个对象或函数,那么需要在Consumer中自行处理默认值的情况。
childContextTypes是React组件定义的一个静态属性,用于指定子组件可以访问的context对象属性及其类型。
当父组件通过getChildContext()方法返回一个context对象时,子组件可以通过在childContextTypes中声明需要的context属性及其类型来访问这些属性。这样,子组件就可以在不通过父组件的props传递的情况下,访问到它所需要的context属性。
childContextTypes:是一种不推荐使用的API,因为它可能会造成不必要的渲染和性能问题。在现代React中,我们更推荐使用useContext或者useContextSelector来访问context属性。
以下是一个简单的例子,演示如何使用childContextTypes和getChildContext():
class Parent extends React.Component {
getChildContext() {
return { color: 'red' };
}
render() {
return <Child />;
}
}
Parent.childContextTypes = {
color: PropTypes.string
};
class Child extends React.Component {
render() {
return <div style={{ color: this.context.color }}>Hello, world!</div>;
}
}
Child.contextTypes = {
color: PropTypes.string
};
在这个例子中,Parent组件通过getChildContext()方法返回了一个包含color属性的context对象,Child组件在它的render()方法中通过this.context.color访问到了这个属性的值。同时,Parent和Child组件分别通过childContextTypes和contextTypes声明了它们需要的context属性及其类型。
4.什么是windowing?
Windowing是一种优化大规模数据渲染的技术,它通过只渲染当前视窗内的数据项来提高渲染性能。
在传统的列表渲染中,如果数据量非常大,那么渲染整个列表就会变得非常耗时。而Windowing的思想是,只渲染当前视窗内的数据项,而不渲染整个列表。当用户滚动列表时,会动态地加载新的数据项,同时卸载离开视窗的数据项,从而保持渲染性能。
常见的Windowing技术有两种:Virtual Scrolling和Virtualization。
Virtual Scrolling是一种通过计算当前视窗内的数据项,动态地计算列表的滚动位置来实现的技术。它可以减少DOM元素的数量,提高渲染性能。实现Virtual Scrolling的常见库有react-window和react-virtualized等。
Virtualization是一种通过渲染当前视窗内的数据项的占位符来实现的技术。它可以在大量数据的情况下提高渲染性能。实现Virtualization的常见库有react-window-infinite-loader和react-lazyload等。
5.什么是严格模式?
React 的严格模式是一种开发模式,可以帮助开发者捕获常见的开发问题,从而提高应用程序的可靠性和稳定性。以下是 React 严格模式的几个主要用处:
- 检测潜在的问题:React 严格模式可以检测出潜在的问题,例如不安全的生命周期使用、重复的 key、弃用的 API 等等。这些问题在非严格模式下可能难以察觉,但在严格模式下会抛出警告或错误。
- 提高性能:React 严格模式可以帮助开发者识别出导致组件重新渲染的问题,从而提高性能。例如,如果一个组件的 render 方法不稳定,那么它可能会在不必要的情况下重新渲染,从而导致性能下降。严格模式可以捕获这种问题,并提示开发者进行优化。
- 未来准备:React 严格模式还可以帮助开发者准备未来的更新。例如,如果一个组件使用了不推荐的 API,那么在未来的版本中可能会被删除。严格模式可以让开发者及早发现这种问题,并进行相应的更新。
综上所述,React 的严格模式可以帮助开发者提高应用程序的可靠性和稳定性,同时也可以提高性能并准备未来的更新。因此,在开发 React 应用程序时,建议开启严格模式。
6.装饰器(Decorator)在React中有什么应用?
在React中,装饰器可以用于增强组件的功能或修改组件的行为。常用的装饰器包括:
- 高阶组件(Higher-Order Component):用于包装一个组件,以增强组件的功能。例如,一个用于验证表单数据的高阶组件可以在表单提交前检查表单数据是否合法。
- 属性代理(Property Proxy):用于传递额外的属性给组件,以修改组件的行为。例如,一个用于记录组件渲染次数的属性代理可以在每次组件更新时增加计数器。
这些装饰器可以通过第三方库(如react-redux和react-router)来实现,也可以通过ES7提供的@语法来使用。例如,使用@connect装饰器可以将Redux store中的状态映射到组件的props中。















 492
492

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









