






基于python3 实现一个简单的词法分析器。
主要使用的库:正则表达式、tkinter
识别关键字,标识符,运算符,分界符,数字(整数和浮点数)
当以数字开头时报错,标识符超过8个字符长度时报错
运行结果如下:
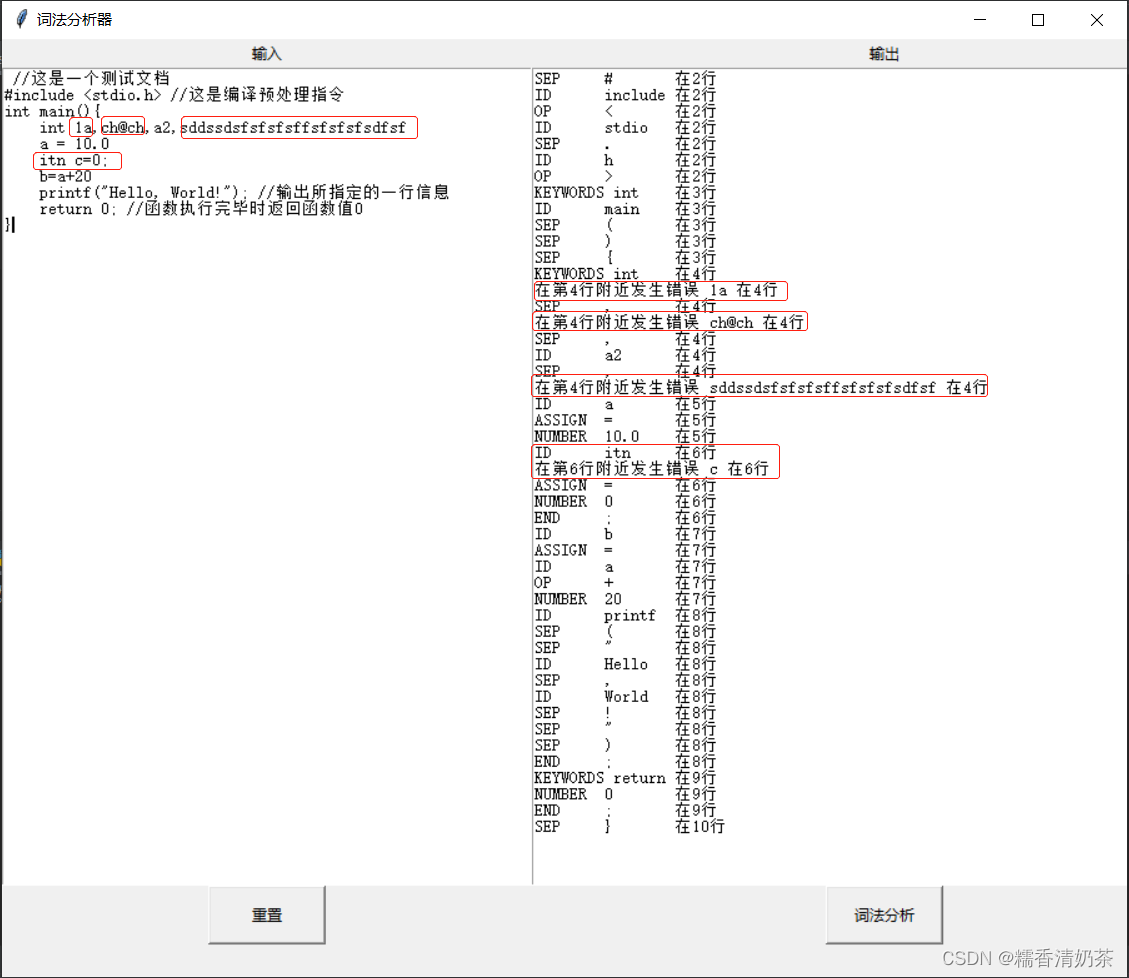
词法分析器结果
有gui界面的源码:
import tkinter as tk
from typing import NamedTuple
import re
class Token(NamedTuple):
type: str
value: str
line: int
column: int
def tokenize(code):
keywords = {'if', 'int', 'char', 'for', 'while', 'do', 'return', 'break', 'continue', 'goto', 'float'}
token_specification = [
('NOTES', r'\/\*[\s\S]*\*\/|\/\/.*'), # 跳过注释
('ERROR', r'[0-9]+[A-Za-z_]+|[A-Za-z_]+[@#$%^&?]+[A-Za-z0-9_]*'), # 标识符不能以数字开头
('NUMBER', r'\d+(\.\d*)?'), # 识别数字
('ASSIGN', r'='), # 赋值运算
('END', r';'),
('ID', r'[A-Za-z0-9_]+'), # 识别标识符
('OP', r'[+\-*/><]+[+-=]*?'), # 算术运算符
('NEWLINE', r'\n'), # 行结束
('SKIP', r'[ \t]+'), # 跳过空格和制表符
('SEP', r'[#{}"\'!(),\.]'), # 符号
('MISMATCH', r'.'), # 其他任何字符
]
tok_regex = '|'.join('(?P<%s>%s)' % pair for pair in token_specification)
line_num = 1
line_start = 0
for mo in re.finditer(tok_regex, code):
kind = mo.lastgroup
value = mo.group()
column = mo.start() - line_start
if kind == 'ERROR':
kind = f'在第{line_num}行附近发生错误'
elif kind == 'NUMBER':
value = float(value) if '.' in value else int(value)
kind='NUMBER'
elif kind == 'ID':
if value in keywords:
kind = "KEYWORDS"
elif len(str(value)) > 8:
kind = f'在第{line_num}行附近发生错误'
else:
if s == 'ID':
kind = f'在第{line_num}行附近发生错误'
else:
kind = 'ID'
elif kind == 'NEWLINE':
line_start = mo.end()
line_num += 1
continue
elif kind == 'SKIP' or kind == 'NOTES':
continue
elif kind == 'MISMATCH':
# raise RuntimeError(f'{value!r} unexpected on line {line_num}')
kind = f"在第{line_num}行附近发生错误"
# print(Token(kind, value, line_num, column))
s = kind
yield Token(kind, value, line_num, column)
# statements = '''
# //这是一个测试文档
# #include <stdio.h> //这是编译预处理指令
# int main(){
# int 1a,ch@ch,a2,sddssdsfsfsfsffsfsfsfsdfsf
# a = 10.0
# if int=0;
# b=a+20
# printf("Hello, World!"); //输出所指定的一行信息
# return 0; //函数执行完毕时返回函数值0
# }
# /*这是*/
# '''
# for token in tokenize(statements):
# print(token)
window=tk.Tk()
window.title('词法分析器')
window.geometry('900x750')
lab1=tk.Label(height=1,text='输入')
lab1.grid(row =1,column=1)
lab2=tk.Label(height=1,text='输出')
lab2.grid(row =1,column=2)
t1=tk.Text(window,width=60,height=50)
t1.grid(row =2,column=1)
t2=tk.Text(window,height=50)
t2.grid(row =2,column=2)
s=''
# 进入词法分析
def insertText():
global s
s=t1.get('1.0', 'end-1c')
t=tokenize(s)
t2.delete("1.0", "end")
# print(token)
for token in tokenize(s):
# print(token)
st=f"{token[0]}\t"+f"{token[1]}\t"+f"在{token[2]}行"
t2.insert(tk.END,st)
t2.insert(tk.END, "\n")
b1=tk.Button(window,text="词法分析",width=12,height=2,command=insertText)
b1.grid(row =3,column=2)
# 重置
def clearText():
t1.delete("1.0", "end")
t2.delete("1.0", "end")
b2=tk.Button(window,text="重置",width=12,height=2,command=clearText)
b2.grid(row =3,column=1)
window.mainloop()














 896
896











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









