






RingBuffer
ringbuffer适用于单生产者,单消费者的场景,虽然是两个线程,但是却不用加锁,可以用数组或者链表实现,以下介绍一种典型的数组实现方法,注意整个Buffer的大小是预先要定好的。
如图,N = 5,但是要区分满和空,所以实际存储的大小要比N小1,也就是只能存储4个元素。write和read是两个指针,也可以看成是序号,都是指向下一个要写或者要读的位置!注意这一点很关键,是下一次要读/写的位置!
write和read实际中只会++,但是数组的序号只能[0, 4]范围,所以寻址时:read % N , write % N。
判断Buffer是否是空: if (write - read) % N == 0, 判断Buffer是否是满: if (write - read + 1) % N == 0
注意:这里非常巧妙的用少一个元素的状态判断是否满,如果不这样,也就是如果认为Buffer可以写入N个元素,则当read == write时,无法判断当前是空还是满,必须要借助各种其他辅助变量判断,较为复杂。
写入一个元素: if(Buffer满)return; buffer[write % N] = val; write++;这个顺序至关重要,先赋值,再增加index
读取一个元素: if (Buffer空)return; val = buff[read % N]; read++; 先取,再增加index
注意:这里写入和读取可以一次不止一个元素,如果判断buffer没有满,则写入从write到read-1都是安全的,因为即使此时有人要去read,那也是read完之后,再增加read index, 而且read最多也只到write-1,所以从write到read-1都是安全的,如果buffer不是空,则读取从read 到write-1都是安全的
用write和read两个序号保证线程安全,所以这两个序号得是原子的std::atomic。
所以这种RingBuffer,用简单的两个原子变量作为“屏障”,保证了单读单写下的线程安全,可谓精妙至极。
双Buffer
RingBuffer适合于单生产者单消费者,那如果是多读一写,能不能也做成无锁呢?可以!用双Buffer。
双buffer也能实现无锁,关键是借助于shared_ptr的use_count(),shared_ptr的use_count的增加减少和获取,都是原子的,所以,虽然对shared_ptr做swap, reset等操作不是线程安全的,但是count却是线程安全的。
考虑用两个buffer,一个buffer供多线程读,另一个buffer是给写用的,写完之后,交换两个buffer的index,下次再来读的任务时,就去读新的buffer了。
关键就在于,如图3,写更新buffer时,如何知道该buffer还有没有人在读,因为有可能有的读任务比较慢,下次开始读的时候,还在操作老buffer。不解决这个问题,这个方案就没有任何意义了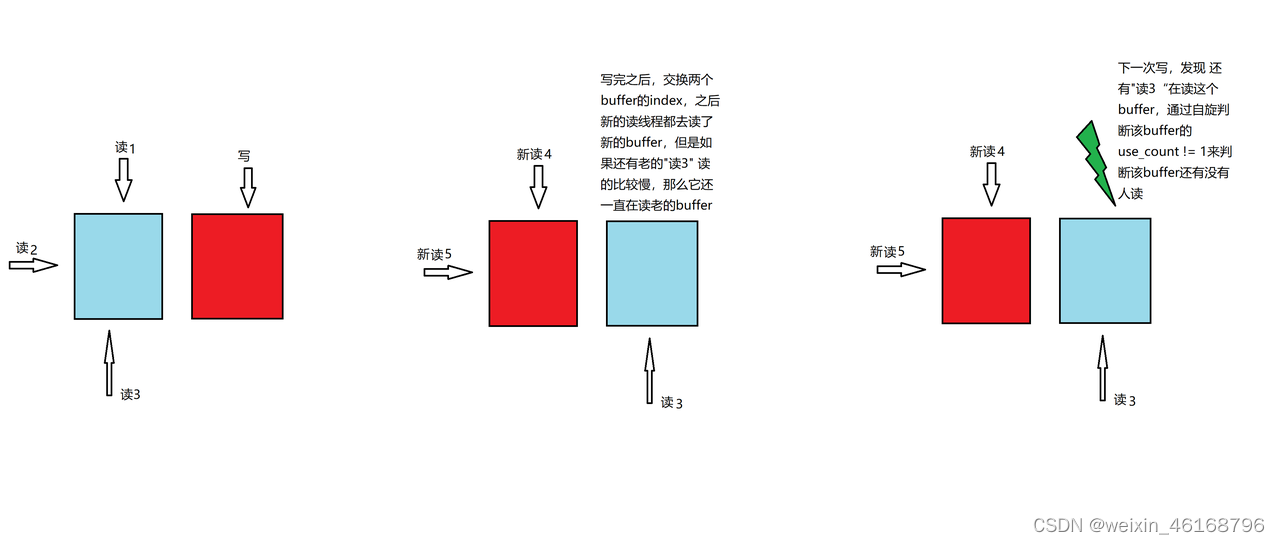
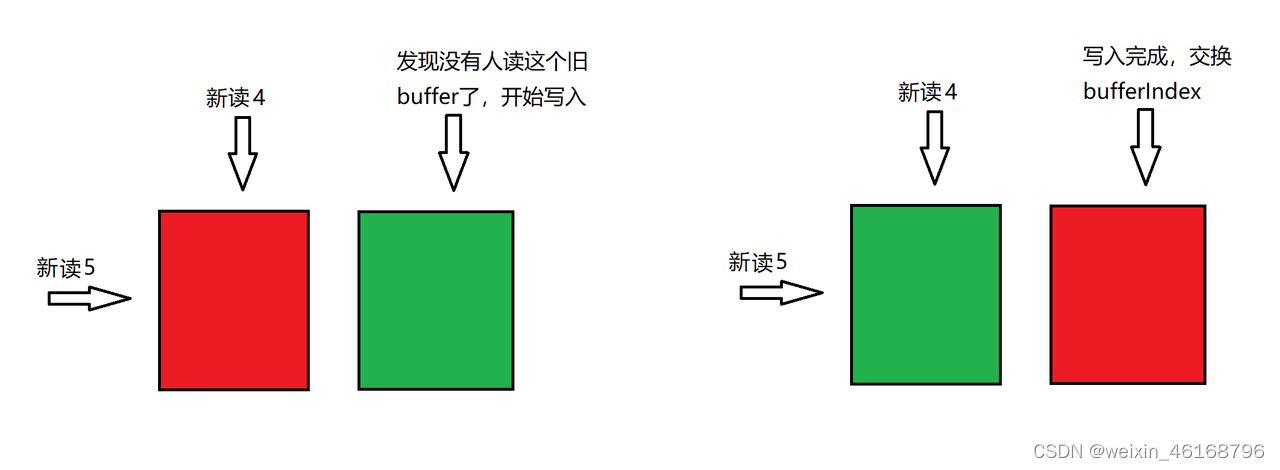 所以这种双buffer的实现,一定是借助于share_ptr实现,并且为了更小的交换开销,用index作为标志,所以定义一个两个元素的数组,数组中是两个buffer的shared_ptr:
所以这种双buffer的实现,一定是借助于share_ptr实现,并且为了更小的交换开销,用index作为标志,所以定义一个两个元素的数组,数组中是两个buffer的shared_ptr:
std::shared_ptr<T> arr[2];
有一个index表示读buffer的index, 默认设为0:std::atomic_int readIndex{0}。
注意,这里一定要是原子的,每次的写bufferindex是 1 - readIndex, 而交换的过程为:readIndex = 1 -readIndex,这样可以最大限度的减少开销。
读的代码如下:
{
auto sp = arr[readIndex];
read from sp...; //从sp读取数据并处理
}
写的代码如下:
{
int writeIndex = 1 - readIndex;
// 自旋锁,判断写buffer能否被写入(有没有其他读线程占用)
while(arr[writeIndex].use_count() != 1)
Sleep(1);
write to arr[writeIndex]... // 写入写buffer
readIndex = 1 -readIndex; // 交换两个buffer
Sleep(1); // 高能,后面介绍
}
重点看一下写的代码,首先通过自旋判断写buffer能否被写入,这一步相当于也是"锁"了,只不过这种比mutex直接加锁效率高。
最后有个Sleep(1),这个是什么作用呢?
原来,因为shared_ptr的赋值并不是原子的,也就是读代码的第一行: auto sp = arr[readIndex];,这一行代码先赋值裸指针,再增加arr的引用计数,那么有极低的概率写线程while(arr[writeIndex].use_count() != 1)可能拿到的是1, 就往下走了,紧接着该内存use_count才被读线程增加1,出现读写冲突。
Sleep(1)的作用就是,如果两次写入无间隔,那么会有概率出现这种情况,sleep(1)后,这种情况出现的可能性为0了,因为这个赋值不操作外设,也没有锁,1ms内绝对可以执行完。
通过测试,如果用普通的lock_guard<std::mutex> 需要耗时13s, 如果用std::shard_mutex读写锁,耗时2.7s,如果用这种无锁双buffer,耗时1.7s,是多读一写场景下的最佳方案。
RCU
Read-Copy Update是指读取的时候不加锁,可以多读,写的时候先拷贝一个副本,改好之后,再更新过去,个人感觉如果是多读一写,还是双buffer效率更高。
不过RCU提供了一种编程思路,比如有一个公共的STL: std::vector<T> vec;
这个vec本身数据量不大,拷贝的开销小,但是有多个线程读取或者写入,一种用读写锁的写法是:
void read(){
std::shared_lock;//加读锁
// 读vec;
}
void write(){
std::unique_lock;//加写锁
// 写vec;
}
还有一种就是借鉴RCU的思路,只对set和get加锁:
std::vector<T> Get(){
std::shared_lock;//加读锁
return vec;
}
void Set(const std::vector<T>& newval){
std::shared_lock;//加写锁
Vec = newval;
}
然后用的时候:void read(){
auto v = Get();
// 读v
}
void write(){
auto v = Get();
// 写v
Set(v); // 写完v后,再更新回去
}
这样多了几次拷贝,但是减少了锁的作用域,而且这样做的前提是,拷贝的开销要远远小于操作的开销,如果拷贝的成本本身很大,那这样做也没有意义了。















 3424
3424











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









