








今天推荐给大家的是一个非常好用的PDF提取工具PDF-Extract-Kit,只要是关于PDF的提取处理这里基本上全都包含了,可以告别网上各种pdf处理的网站了。
PDF-Extract-Kit
https://github.com/opendatalab/PDF-Extract-Kit
https://pdf-extract-kit.readthedocs.io/zh-cn/latest/index.html
使用起来也是模块化的管理,非常简单,也可以直接嵌入到自己的流程中使用
01
主要功能
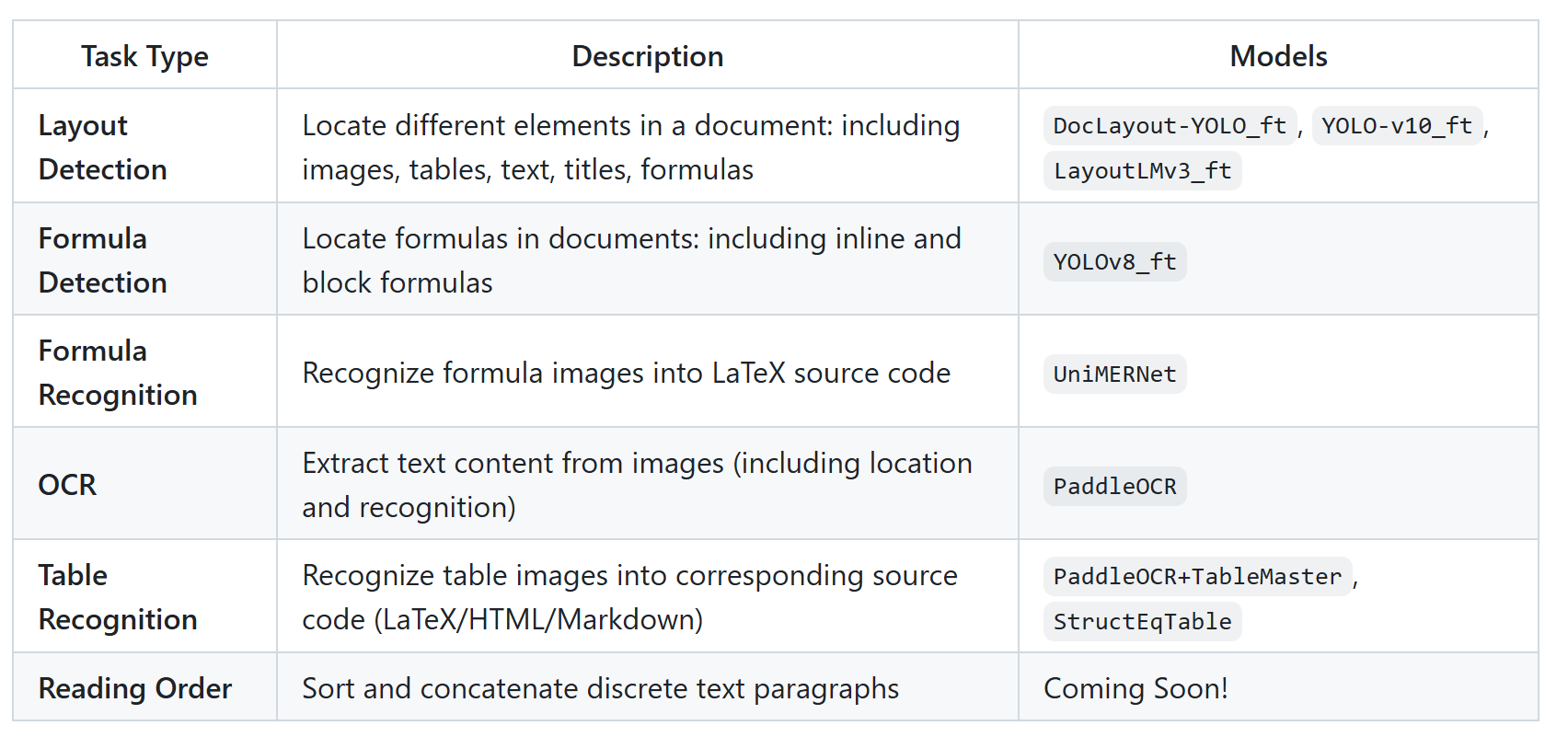
功能包含
-
布局检测:定位文档中不同元素位置:包含图像、表格、文本、标题、公式等
-
公式检测:定位文档中公式位置:包含行内公式和行间公式
-
公式识别:识别公式图像为latex源码
-
OCR:提取图像中的文本内容(包括定位和识别)
-
表格识别:识别表格图像为对应源码(Latex/HTML/Markdown)
所提到的模型也都开源在:
02
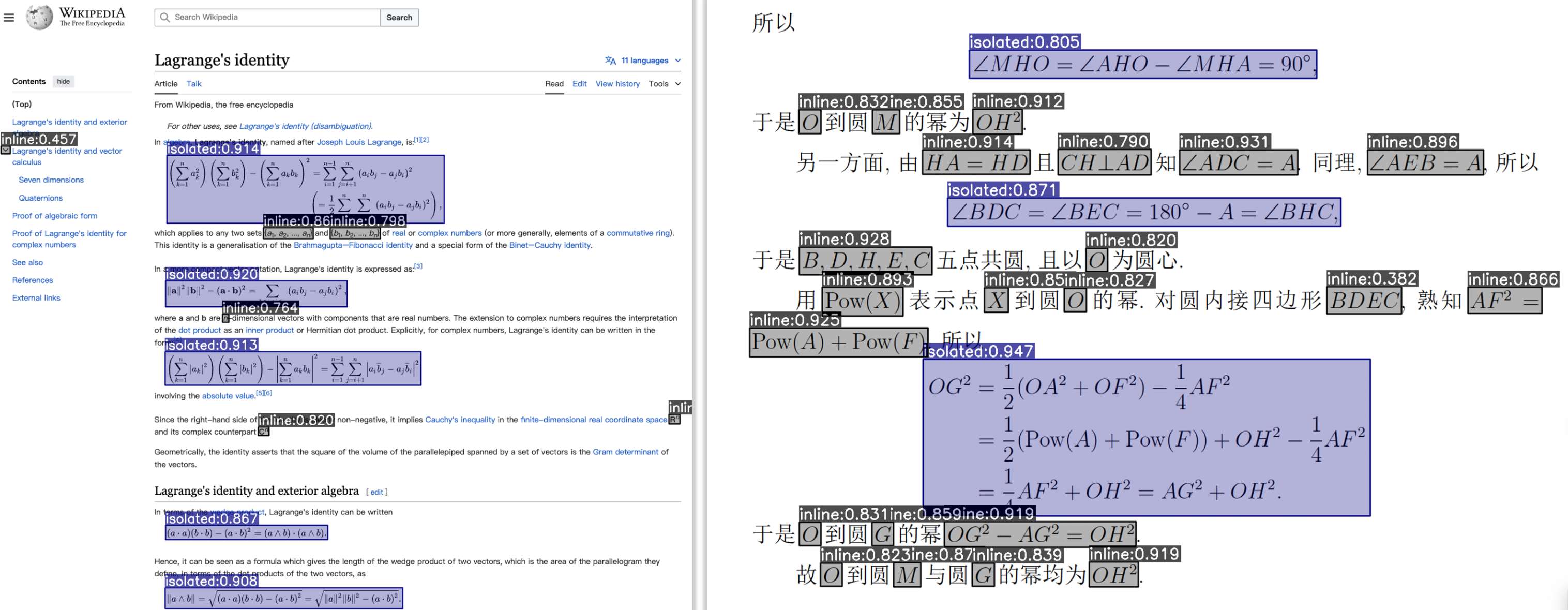
效果演示
布局检测

公式检测
03
使用方法
建立环境
conda create -n pdf-extract-kit-1.0 python=3.10
conda activate pdf-extract-kit-1.0
pip install -r requirements.txt 如果没有gpu就安装cpu版本: requirements-cpu.txt
模型下载
pip install huggingface_hub
安装完下载工具包,开始下载模型
from huggingface_hub import snapshot_download
snapshot_download(repo_id='opendatalab/pdf-extract-kit-1.0', local_dir='./', max_workers=20)
也可以只下载需要用到的模型
from huggingface_hub import snapshot_download
snapshot_download(repo_id='opendatalab/pdf-extract-kit-1.0', local_dir='./', allow_patterns='models/MFD/YOLO/*')
运行
可以直接运行给出的demo,注意模型要在目录下,demo脚本请参考scripts文件夹下
python scripts/layout_detection.py --config=configs/layout_detection.yaml
点击下方卡片关注我:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









