






Yi, Xunpeng, et al. "Text-IF: Leveraging Semantic Text Guidance for Degradation-Aware and Interactive Image Fusion." arXiv preprint arXiv:2403.16387 (2024).
Introduction
图像融合是数字图像处理领域的一个重要领域。 单模态图像只能捕获场景的部分表示。多模态图像允许有效获取更全面的表示。 作为一个重要的代表,可见光图像提供了基于反射率的视觉信息,类似于人类的视觉。红外图像提供基于热辐射的信息,对检测热目标和观察夜间活动更有价值。
Problems
受环境条件的限制,最初获取的红外和可见光图像可能会受到退化的影响,并显示出较低的融合图像质量。可见图像容易受到退化问题的影响,例如低光、过度曝光等。红外图像不可避免地受到噪声(包括热、电子和环境噪声)、对比度降低和其他相关效应的影响。 目前的融合方法缺乏自适应解决退化的能力,导致融合图像质量较低。此外,依靠人工预处理来增强图像存在灵活性和效率的问题。因此,研究损害退化感知处理和交互融合的模型具有重要的现实意义。
Contributions
- image fusion and degradation-aware processing;
- semantic interaction guidance module;
- generate more flexible, high-quality and user-required results
Methods

Methods: Image Fusion
Image Encoder --- restormer block

cross fusion layer

Semantic Interaction Fusion Decoder

Methods: Text Interaction Guidance
Text Semantic Encoder
![]()
Semantic Interaction Guidance Module(SIGM)
![]()
Methods: Loss Function
- Intensity Loss
- Structural Similarity Loss
- Maximum Gradient Loss
- Color Consistency Loss
Experiments


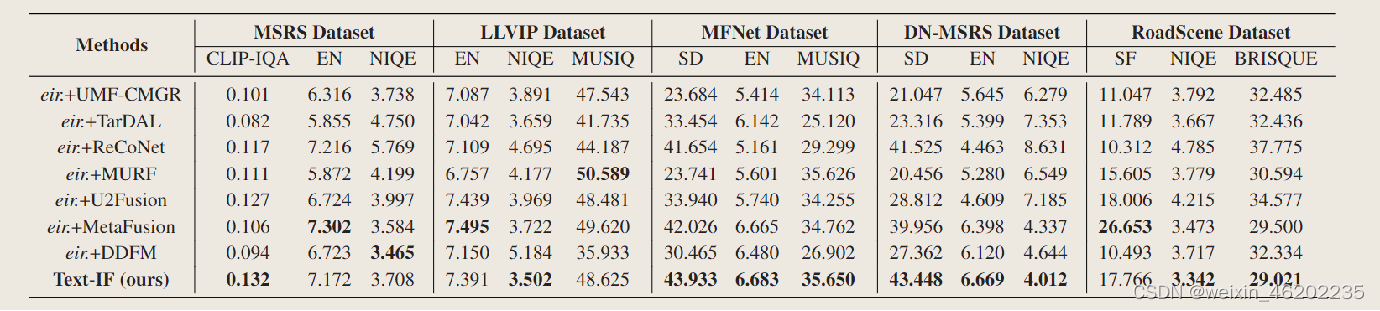
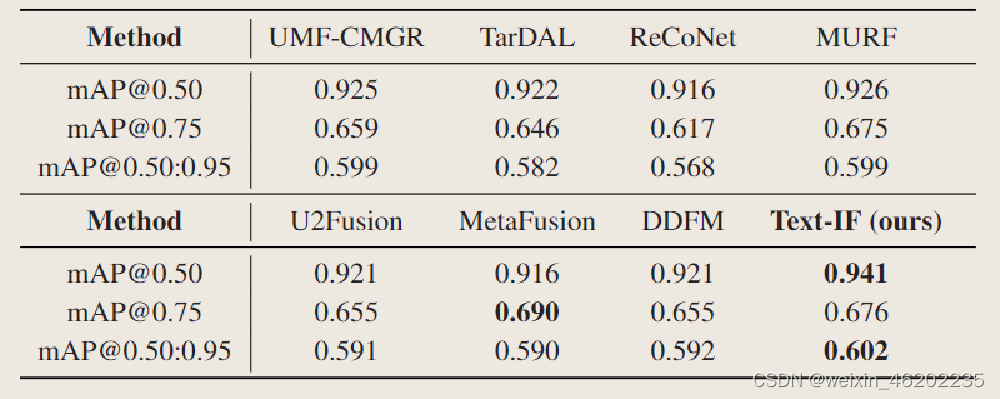
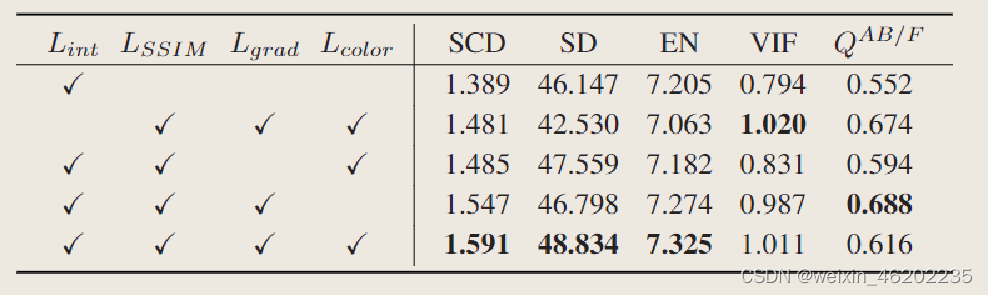
Conclusions
本文扩展了图像融合任务,提出一种新的文本引导图像融合框架来解决现有方法难以解决退化的复杂场景融合的问题,并获得具有交互性的用户所需的融合图像。在图像融合工作流程中,实现了文本语义特征提取和语义交互引导模块,实现了文本语义引导的图像融合目标。大量的实验结果表明,该方法在融合性能和退化处理方面都具有明显的优势。它可以自由根据交互式用户文本输入生成相应的融合图像,这在实践中和后续的理论研究中发挥着重要作用。
参考文献
Wu, Wenhui, et al. "Uretinex-net: Retinex-based deep unfolding network for low-light image enhancement." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022. Li, Boyun, et al. "All-in-one image restoration for unknown corruption." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022. Chen, Haoyu, et al. "Masked image training for generalizable deep image denoising." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023. Afifi, Mahmoud, et al. "Learning multi-scale photo exposure correction." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.

















 186
186

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









