






 本文介绍了马尔可夫链的基本概念,这是一种基于当前状态预测未来事件概率的随机模型。文章通过Python展示了如何创建和应用马尔可夫链进行文本预测,特别提到了马尔可夫链在文本生成中的作用,如自动完成和建议回复。同时,提供了莎士比亚文本数据集的案例实现。
本文介绍了马尔可夫链的基本概念,这是一种基于当前状态预测未来事件概率的随机模型。文章通过Python展示了如何创建和应用马尔可夫链进行文本预测,特别提到了马尔可夫链在文本生成中的作用,如自动完成和建议回复。同时,提供了莎士比亚文本数据集的案例实现。
本篇为测试内容,因此不必看本篇内容。标题可见没有加入机器学习系列中。
马尔可夫链是一种随机模型,它概述了基于先前事件发生的一系列事件的概率。本文中,我将解释并提供马尔可夫链的 Python 实现。不会深入探讨马尔可夫链背后的数学,而是关注它的工作原理以及如何用Python实现它。
什么是马尔可夫链?
马尔可夫链是一种随机模型,它使用数学来根据最近的事件预测一系列事件发生的概率。马尔可夫链的一个常见示例是 Google 根据您在 Gmail 中的先前条目预测句子中下一个单词的方式。
马尔可夫链是由 Andrey Markov 创建的随机模型,它概述了与基于前一个事件的状态发生的一系列事件相关的概率。这是一个非常常见且易于理解的模型,经常用于处理金融等顺序数据的行业。即使是百度的页面排名算法,它决定了在其搜索引擎中首先显示哪些链接,也是一种马尔可夫链。通过数学,该模型使用我们的观察来预测未来事件的近似值。
马尔可夫过程的主要目标是确定从一种状态转换到另一种状态的概率。对马尔可夫的主要吸引力之一是随机变量的未来状态仅取决于其当前状态。随机变量的非正式定义被描述为一个变量,其值取决于随机事件的结果。
一、马尔可夫链的特点
如上所述,马尔可夫过程是具有无记忆特性的随机过程。数学中的术语“无记忆”是概率分布的一个属性。它通常是指与某个事件发生相关的时间不取决于已经过去了多少时间的场景。换句话说,当模型具有无记忆特性时,这意味着模型已经“忘记”了系统所处的状态。因此,过程的先前状态不会影响概率。
马尔可夫过程的主要特征是这种无记忆性。与马尔可夫过程相关的预测取决于其当前状态,并且独立于过去和未来状态。
这种无记忆属性对应用中的马尔可夫模型既是福也是祸。想象一个场景,您希望根据之前输入的文本来预测单词或句子——类似于 Google 对Gmail所做的事情。使用马尔可夫过程的好处是新生成的预测将不依赖于您在段落前编写的内容。但是,缺点是您将无法预测基于模型先前状态的上下文的文本。这是自然语言处理(NLP) 中的常见问题,也是许多模型面临的问题。
二、创建马尔可夫链模型
马尔可夫链模型依赖于两个关键信息——转移矩阵和初始状态向量。
2.1 转移矩阵
这个 NxN 矩阵表示状态转换的概率分布,表示为“P”。矩阵每一行的概率之和将为 1,这意味着这是一个随机矩阵。
请注意,有向连通图可以转换为转移矩阵。矩阵中的每个元素将表示与连接两个节点的边相关联的概率权重。
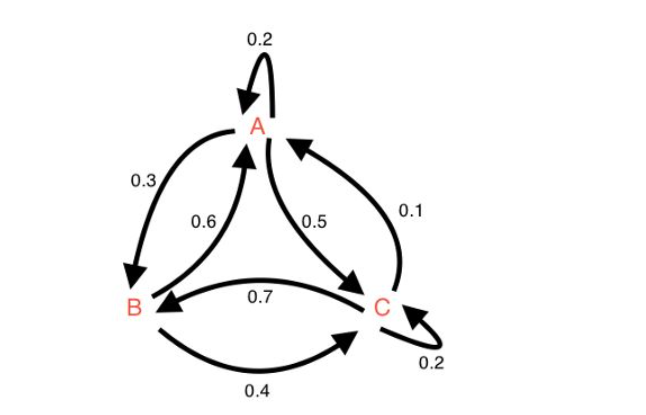
该图概述了与从一种状态移动到另一种状态相关的概率。例如,有 60% 的机会从状态 B 移动到状态 A。
2.2 初始状态向量
这个 Nx1 向量表示从 N 个可能状态中的每一个开始的概率分布,表示为“S”。向量中的每个元素都表示从该状态开始的概率。
给定这两个依赖项,可以取 的乘积P x I来确定马尔可夫链的初始状态。为了预测未来状态发生的概率,您可以将转移矩阵 P 提高到“M”次方。
三、场景
马尔可夫链在数据科学中的一个常见应用是文本预测。这是 NLP 的一个领域,谷歌、LinkedIn 和 Instagram 等公司在科技行业中普遍使用。在您撰写电子邮件时,Google 会预测并建议字词或短语来自动完成您的电子邮件。当你在 Instagram 或 LinkedIn 上收到消息时,这些应用程序会建议潜在的回复。这些是我们将探讨的马尔可夫链的应用。也就是说,这些大型公司在生产中用于这些功能的模型类型更加复杂。
假设您有大量与某个主题相关的文本。您可以将每个句子想象成该文本语料库中的一系列单词。然后,每个单词将成为其自己的状态,并且您将根据您连接到的可用单词关联从一种状态移动到另一种状态的概率。这将允许您根据与转换矩阵相关的概率从一种状态转换到另一种状态。这可以在下面可视化。
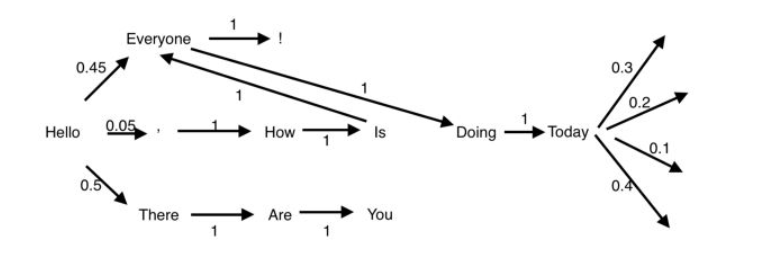
这个序列可以被设想为一个连接的、有向的网络。出于可视化目的,上面的网络在其语料库中包含少量单词。当处理像哈利波特系列这样的大量文本时,这个网络会变得非常庞大和复杂。如果你看一下开头的单词“ Hello ”,后面还有其他三个潜在的单词和符号:Everyone , There以及它们相关的概率。计算这些概率的最简单方法是通过语料库中单词的频率。
Hello --> ['Everyone', ',', 'Everyone', 'Everyone', 'There', 'There', 'There', There', There', ...]
如果上面的列表中有 20 个单词,其中每个单词都在单词“ Hello” 之后陈述,那么每个单词出现的概率将遵循以下公式:
P(word) = Frequency of Word / Total Number of Words in List
P(Everyone) = 9 / 20
P(,) = 1 / 20
P(There) = 10 / 20
初始状态向量将与您可以用来开始句子的所有单词的概率相关联。在上面的示例中,由于“ Hello”是唯一开始的词,初始状态向量将是一个 Nx1 向量,具有与“Hello”一词相关联的 100% 的概率。您现在可以通过此马尔可夫模型预测未来状态。接下来我将向您展示如何在 Python 中实现这一点。
四、案例实现
这里以莎士比亚的数据集为例子,同理换个数据集即可:
from collections import defaultdict
import string
import random
class Markov():
def __init__(self, file_path):
self.file_path = file_path
self.text = self.remove_punctuations(self.get_text())
self.model = self.model()
def get_text(self):
'''
该函数将读取输入文件并以列表形式逐行返回与该文件相关的文本
'''
text = []
for line in open(self.file_path):
text.append(line)
return ' '.join(text)
def remove_punctuations(self, text):
'''
给定一个文本字符串,该函数将返回相同的输入文本,不含任何标点符号。
'''
return text.translate(str.maketrans('','', string.punctuation))
def model(self):
'''
这个函数将接受一个文本块作为输入,并将文本中的每个词映射到一个键上,而与该键相关的值就是该键后面的词。
与该键相关的值是该键前面的词。
args:
text (String) : 你想训练你的马尔科夫模型的文本字符串
example:
text = 'hello my name is V hello my name is G hello my current name is F world today is a good day'
markov_model(text)
>> {'F': ['world'],
'G': ['hello'],
'V': ['hello'],
'a': ['good'],
'current': ['name'],
'good': ['day'],
'hello': ['my', 'my', 'my'],
'is': ['V', 'G', 'F', 'a'],
'my': ['name', 'name', 'current'],
'name': ['is', 'is', 'is'],
'today': ['is'],
'world': ['today']}
'''
# 将输入的文本分割成以空格隔开的单个单词
words = self.text.split(' ')
markov_dict = defaultdict(list)
# 创建所有单词对的列表
for current_word, next_word in zip(words[0:-1], words[1:]):
markov_dict[current_word].append(next_word)
markov_dict = dict(markov_dict)
print('Successfully Trained')
return markov_dict
def predict_words(chain, first_word, number_of_words=5):
'''
给出markov_model函数的输入结果和单词的数量,这个函数将允许你预测序列中的下一个单词 序列中的下一个词
args:
chain (Dictionary) : markov_model函数的结果
first_word (String) : 你想从哪个词开始预测,注意这个词必须在链中可用。
number_of_words (整数) : 你要预测的词的数量
example:
chain = markov_model(text)
generate_sentence(chain, first_word = 'do', number_of_words = 3)
>> Do not fail.
'''
if first_word in list(chain.keys()):
word1 = str(first_word)
predictions = word1.capitalize()
# 从值列表中生成第二个词。将新词设为第一个词。重复进行。
for i in range(number_of_words-1):
word2 = random.choice(chain[word1])
word1 = word2
predictions += ' ' + word2
# 用句号结束
predictions += '.'
return predictions
else:
return "Word not in corpus"
if __name__ == '__main__':
m = Markov(file_path='sha.txt')
chain = m.model
print(predict_words(chain, first_word = 'do', number_of_words = 10))
如下:
Successfully Trained
Do not for I rather hear of night and lost.
总而言之,马尔可夫链是一个随机模型,它概述了与基于前一个事件中的状态发生的一系列事件相关的概率。创建马尔可夫链的两个关键组成部分是转移矩阵和初始状态向量。它可以用于许多任务,例如文本生成,我已经根据上面的 Python 代码展示了如何完成这些任务。


















 1197
1197

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











