







一、搭建Python自带的静态Web服务器
1、静态Web服务器
可以为发出请求的浏览器提供静态文档(html/css/js/图片/音频/视频)的程序。
平时我们浏览百度新闻数据的时候,每天的新闻数据都会发生变化,那访问的这个页面就是动态的,而我们开发的是静态的,每天访问我们自己的静态web服务器,页面的数据不会发生变化。
2、搭建Python自带的静态Web服务器
Linux创建方式:
Windows创建方式:
① 创建一个文件夹,然后把所有的资源文件都放入这个文件夹中
② 在DOS窗口使用cd命令切换到此目录
③ 使用python -m命令创建静态Web服务器
python -m http.server 9000
-m表示==运行包里面的模块==,执行这个命令的时候,需要==进入你自己指定静态文件的目录==,然后通过浏览器就能访问对应的html文件了,这样一个静态的web服务器就搭建好了。
④ 访问Web静态服务器:
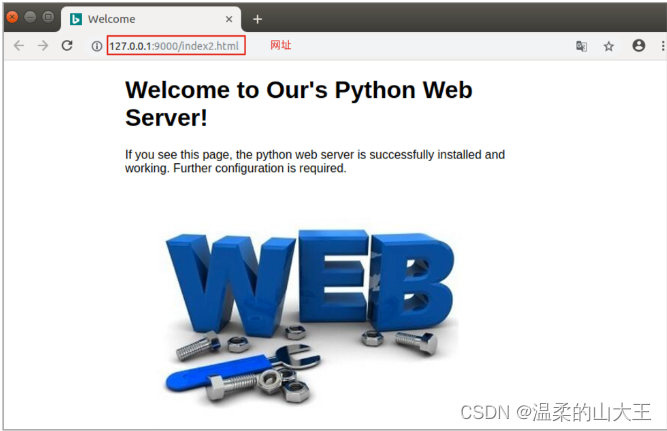
查看HTTP通信过程:
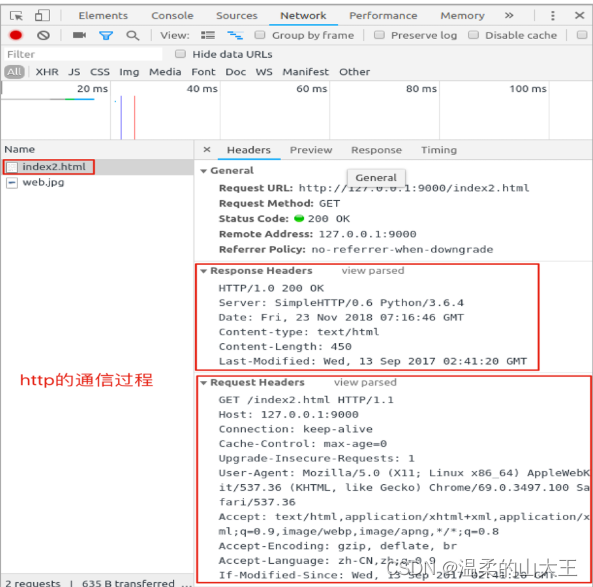
3、小结
静态Web服务器是为发出请求的浏览器提供静态文档的程序,搭建Python自带的Web服务器使用
python –m http.server 端口号这个命令即可,端口号不指定默认是8000
强调!:应答体中携带的数据发送到浏览器,浏览器经过渲染产生具体页面
二、使用Python开发自己的Web服务器
Web服务器 = TCP服务器(七步走) + HTTP协议(请求、响应)
1、开发步骤
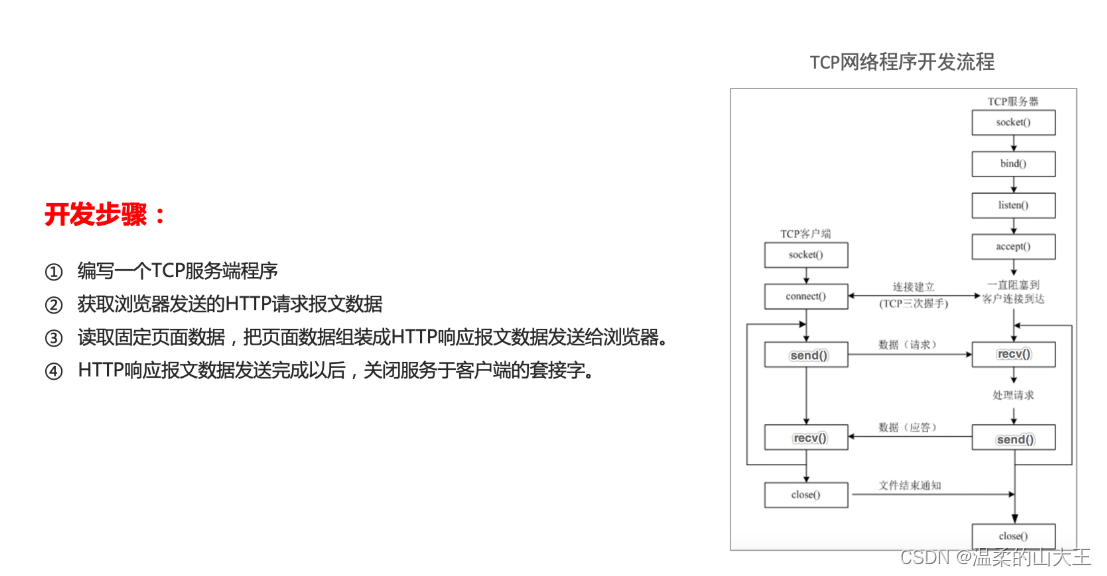
2、返回固定页面的数据
import socket
if __name__ == '__main__':
# 1、创建socket
tcp_server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
tcp_server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, True)
# 2、绑定IP和端口
tcp_server_socket.bind(("", 8080))
# 3、设置监听
tcp_server_socket.listen(128)
while True:
# 4、建立连接
client_socket, client_addr = tcp_server_socket.accept()
client_request_data = client_socket.recv(1024).decode()
print(client_request_data)
with open("./index.html", "rb") as f:
file_data = f.read()
# 响应行
response_line = "HTTP/1.1 200 OK\r\n"
# 响应头
response_header = "Server:pwb\r\n"
# 响应体
response_body = file_data
# 响应数据
response_data = (response_line + response_header + "\r\n").encode() + response_body
# 5、发送数据
client_socket.send(response_data)
# 6、关闭客户端socket连接
client_socket.close()
3、返回指定页面的数据
分析步骤:
① 获取用户请求资源的路径
② 根据请求资源的路径,读取指定文件的数据
③ 组装指定文件数据的响应报文,发送给浏览器
④ 判断请求的文件在服务端不存在,组装404状态的响应报文,发送给浏览器
获取用户请求资源的路径:
request_list = client_request_data.split(" ", maxsplit=2)
request_path = request_list[1] # /gdp.html
if request_path == "/":
# 如果用户没有指定资源路径那么默认访问的数据是首页的数据
request_path = "/index.html"
获取指定页面的数据:
# 读取指定文件数据
# 使用rb的原因是浏览器也有可能请求的是图片
with open("s" + request_path, "rb") as file:
# 读取文件数据
file_data = file.read()
组装指定页面数据的响应报文:
# 响应行
response_line = "HTTP/1.1 200 OK\r\n"
# 响应头
response_header = "Server: PWS1.0\r\nContent-Type: text/html;charset=utf-8\r\n"
# 响应体
response_body = file_data
# 拼接响应报文数据
response_data = (response_line + response_header + "\r\n").encode("utf-8") + response_body
# 发送响应报文数据
client_socket.send(response_data)
client_socket.close()
组装404页面数据的响应报文:
try:
# 打开指定文件,代码省略...
except Exception as e:
response_line = 'HTTP/1.1 404 Not Found\r\n'
response_header = 'Server: PWS1.0\r\nContent-Type: text/html;charset=utf-8\r\n'
response_body = '<h1>非常抱歉,您当前访问的网页已经不存在了</h1>'.encode('utf-8')
response_data = (response_line + response_header + '\r\n').encode('utf-8') + response_body
# 发送404响应报文数据
client_socket.send(response_data)
else:
# 发送指定页面的响应报文数据,代码省略...
finally:
client_socket.close()
三、FastAPI框架
学习目标
-
能够知道什么是FastAPI
-
能够知道怎么安装FastAPI
-
能够掌握FastAPI的基本使用
-
能够掌握FastAPI实现访问多个指定网页
1. 什么是FastAPI
FastAPI是一个现代的,快速(高性能)python web框架. 基于标准的python类型提示,使用python3.6+构建API的Web框架.
简单讲FastAPI就是把做web开发所需的相关代码全部简化, 我们不需要自己实现各种复杂的代码, 例如多任务,路由装饰器等等. 只需要调用FastAPI提供给我们的函数, 一调用就可以实现之前需要很多复杂代码才能实现的功能.
-
FastAPI的特点
-
性能快:高性能,可以和NodeJS和Go相提并论
-
快速开发:开发功能速度提高约200%至300%
-
更少的Bug:
-
Fewer bugs: 减少40%开发人员容易引发的错误
-
直观:完美的编辑支持
-
简单: 易于使用和学习,减少阅读文档的时间
-
代码简洁:很大程度上减少代码重复。每个参数可以声明多个功能,减少bug的发生
-
标准化:基于并完全兼容API的开发标准:OpenAPI(以前称为Swagger)和JSON Schema
-
-
搭建环境
-
python环境:Python 3.6+
-
-
fastapi安装
☆ 安装方式:
-
安装fastapi
-
pip install fastapi
-
-
如果用于生产,那么你还需要一个ASGI服务器,如Uvicorn或Hypercorn
-
pip install uvicorn
-
2. FastAPI的基本使用
功能需求:
-
搭建服务器
-
返回html页面
基本步骤:
-
导入模块
-
创建FastAPI框架对象
-
通过@app路由装饰器收发数据
-
运行服务器
代码实现:
# 导入FastAPI模块
from fastapi import FastAPI
# 导入响应报文Response模块
from fastapi import Response
# 导入服务器uvicorn模块
import uvicorn
# 创建FastAPI框架对象
app = FastAPI()
# 通过@app路由装饰器收发数据
# @app.get(参数) : 按照get方式接受请求数据
# 请求资源的 url 路径
@app.get("/index.html")
def main():
with open("source/html/index.html") as f:
data = f.read()
# return 返回响应数据
# Response(content=data, media_type="text/html"
# 参数1: 响应数据
# 参数2: 数据格式
return Response(content=data, media_type="text/html")
# 运行服务器
# 参数1: 框架对象
# 参数2: IP地址
# 参数3: 端口号
uvicorn.run(app, host="127.0.0.1", port=8000)
3. 通过FastAPI访问多个指定网页
-
路由装饰器的作用:
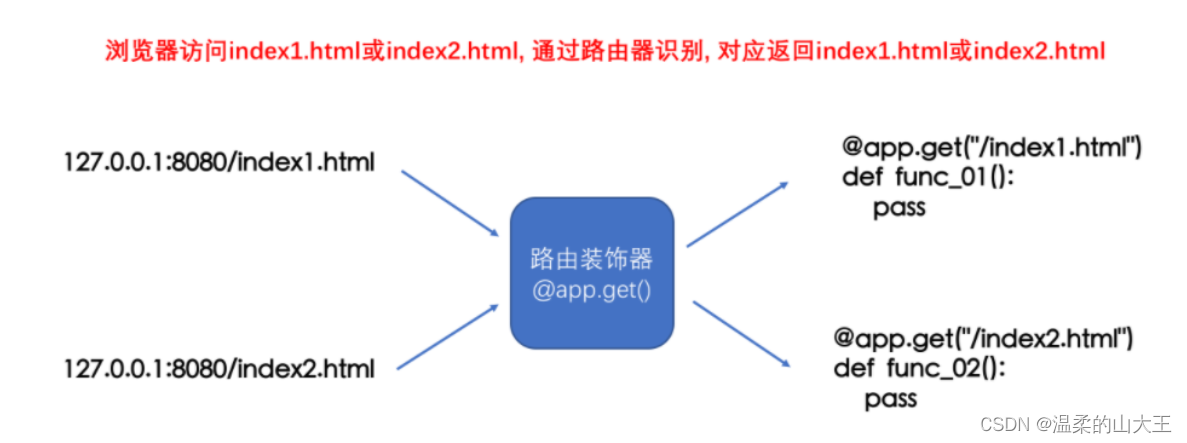
-
实际上通过
路由装饰器我们就可以让一个网页对应一个函数, 也就可以实现访问指定网页了.
# 导入FastAPI模块
from fastapi import FastAPI
# 导入响应报文Response模块
from fastapi import Response
# 导入服务器uvicorn模块
import uvicorn
# 创建FastAPI框架对象
app = FastAPI()
# 通过@app路由装饰器收发数据
# @app.get(参数) : 按照get方式接受请求数据
# 请求资源的 url 路径
@app.get("/index1.html")
def main():
with open("source/html/index1.html") as f:
data = f.read()
# return 返回响应数据
# Response(content=data, media_type="text/html"
# 参数1: 响应数据
# 参数2: 数据格式
return Response(content=data, media_type="text/html")
@app.get("/index2.html")
def main():
with open("source/html/index2.html") as f:
data = f.read()
# return 返回响应数据
# Response(content=data, media_type="text/html"
# 参数1: 响应数据
# 参数2: 数据格式
return Response(content=data, media_type="text/html")
# 运行服务器
# 参数1: 框架对象
# 参数2: IP地址
# 参数3: 端口号
uvicorn.run(app, host="127.0.0.1", port=8000)
4. 小结
-
基本步骤:
-
导入模块
-
创建FastAPI框架对象
-
通过@app路由装饰器收发数据
-
运行服务器
-
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









