







5.2 有监督特征抽取
请参考《数据准备和特征工程》中的相关章节,调试如下代码。

基础知识
from sklearn.datasets import make_classification
# make_classification:用于生成随机的n类分类问题。
# 利用make_classification()函数创建一个可用于分类的数据集
# n_features=4: 总的特征数量为4
# n_redundant=0:冗余特征的数量
# n_classes=3: 类别或标签的数量为3
# n_clusters_per_class=1: 每个类别中cluster的数量为1
# class_sep=0.5: 这个因素决定了hypercube的size。较大的值会分散聚/类别,并且使得分类任务更加容易
X,y = make_classification(n_samples=1000,
n_features=4,
n_redundant=0,
n_classes=3,
n_clusters_per_class=1,
class_sep=0.5,
random_state=10)
# x为产生的样本(特征矩阵),y为每个样本的类的标签(矩阵每行的标签(整型))
X.shape, y.shape
((1000, 4), (1000,))
%matplotlib inline
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
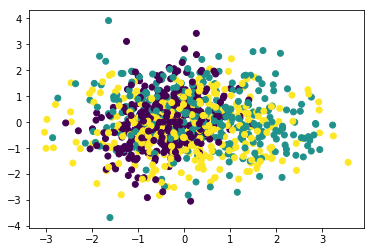
# PCA模型用于特征抽取,效果不好
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)
plt.scatter(X_pca[:, 0], X_pca[:, 1], c=y)
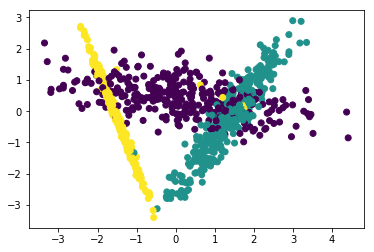
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
# LDA:线性判别分析,需要输入X和y,因此也被称为有监督的特征抽取。
# LDA模型用于特征抽取,效果非常好
lda = LinearDiscriminantAnalysis(n_components=2)
X_lda = lda.fit_transform(X, y)
plt.scatter(X_lda[:, 0], X_lda[:, 1], c=y)
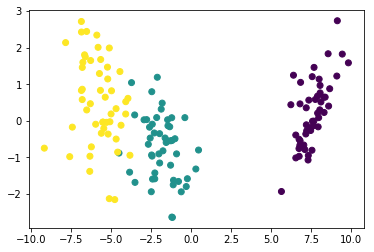
项目案例
from sklearn import datasets
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
# LDA用于特征抽取
iris = datasets.load_iris()
X_iris, y_iris= iris.data, iris.target
lda = LinearDiscriminantAnalysis(n_components=2)
X_iris_lda = lda.fit_transform(X_iris, y_iris)
plt.scatter(X_iris_lda[:, 0], X_iris_lda[:, 1], c=y_iris)
import numpy as np
# 计算每个特征不同类别数据的均值X_mean和方差X_var
X_mean = []
X_var = []
for i in range(4):
m = []
v = []
for j in range(3):
m.append(np.mean(X[:, i][j==y]))
v.append(np.var(X[:, i][j==y]))
X_mean.append(v)
X_var.append(m)
print("X_mean: ", X_mean)
print("X_var: ", X_var)
X_mean: [[0.2183712580305977, 1.1052626159191397, 0.4057388127038256], [1.061062843407683, 1.050045165331185, 1.0287851089775246], [0.9874712352883422, 0.9682431042431385, 1.0036869489851274], [0.7034263353290686, 0.5892565808874551, 1.0390892157973233]]
X_var: [[-0.5278067685825016, -0.5169064671104584, 0.4672757741731266], [0.061662385983550616, -0.17231056591994068, 0.08946387250298174], [-0.014067167509643446, -0.07051190168141928, 0.0039673167895780004], [0.45836039396857386, -0.46246572782720174, 0.5115950547496408]]
X_mean[0]
[0.2183712580305977, 1.1052626159191397, 0.4057388127038256]
X_var[0]
[-0.5278067685825016, -0.5169064671104584, 0.4672757741731266]
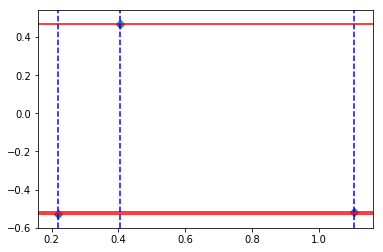
fig, axs = plt.subplots()
# axhline:绘制平行于x轴的水平参考线
for i in range(3):
axs.axhline(X_var[0][i], color='red')
axs.axvline(X_mean[0][i], color='blue', linestyle="--")
# 横轴数据表示的是均值,纵轴数据表示的是方差
# 由图可知,均值之间的差异化比方差要好,这就是LDA分类效果要优于PCA的原因
axs.scatter(X_mean[0], X_var[0], marker="D")
动手练习
import pandas as pd
from sklearn.model_selection import train_test_split
# 划分训练集和测试集
df_wine = pd.read_csv("data/data20527/wine_data.csv")
X, y = df_wine.iloc[:, 1:].values, df_wine.iloc[:, 0].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
from sklearn.preprocessing import StandardScaler
# 特征标准化
std = StandardScaler()
X_train_std = std.fit_transform(X_train)
X_test_std = std.transform(X_test)
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA
from sklearn.linear_model import LogisticRegression
# LDA模型进行特征抽取(降维)
lda = LDA(n_components=2)
X_train_lda = lda.fit_transform(X_train_std, y_train)
X_test_lda = lda.transform(X_test_std)
# LogisticRegression:用对数几率回归模型lr对降维后的训练数据X_train_lda进行分类
lr = LogisticRegression()
lr = lr.fit(X_train_lda, y_train)
# !mkdir /home/aistudio/external-libraries
# !pip install -i https://pypi.tuna.tsinghua.edu.cn/simple mlxtend -t /home/aistudio/external-libraries
import sys
sys.path.append('/home/aistudio/external-libraries')
import mlxtend
from mlxtend.plotting import plot_decision_regions
# 训练集上的分类效果
plot_decision_regions(X_train_lda, y_train, clf=lr)
plt.xlabel('LD 1')
plt.ylabel('LD 2')
plt.legend(loc='lower left')
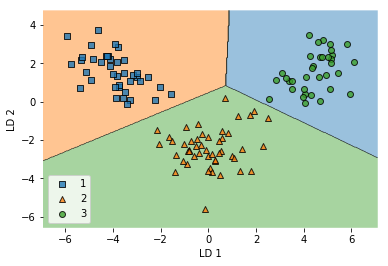
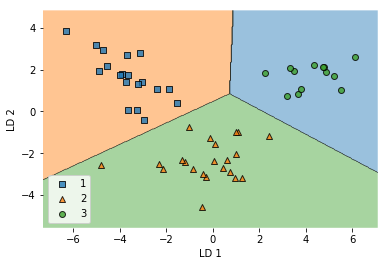
# 在测试集上的表现
plot_decision_regions(X_test_lda, y_test, clf=lr)
plt.xlabel('LD 1')
plt.ylabel('LD 2')
plt.legend(loc='lower left')















 229
229











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











