







指导
第一步先要添加依赖
groupId = org.apache.spark
artifactId = spark-streaming-kafka-0-8_2.12
version = 2.4.5
1.Receiver-based方法
编写Spark Streaming项目代码
def main(args: Array[String]): Unit = {
//新建一个SparkConf 将Master和AppName设置进去
val conf: SparkConf = new SparkConf()
.setAppName("FlumePush")
.setMaster("local[2]")
//新建一个StreamingContext,第一个参数是上面定义的SparkConf
//第二个参数是个Seconds类型,表示多久进行一次批处理
val ssc = new StreamingContext(conf, Seconds(4))
//这边定义了zookeeper端口地址,组名,topic名和线程数量
val zkAddr = "192.168.0.133:2181"
val group = "test"
val topics = "project"
val numThread = 1
//这边创建了一个map,将所有topic丢进去,key是topic名,value是线程数量
val map: Map[String, Int] = topics.split(",").map((_, numThread)).toMap
//通过KafkaUtils.createStream创建数据流
//这里4个参数分别是StreamingContext,zookeeper端口地址,组名,上面创建的map
val messages: ReceiverInputDStream[(String, String)] = KafkaUtils.createStream(ssc, zkAddr, group, map)
//我们需要先通过一个map拿到第二个有用信息再进行wc操作
val value: DStream[(String, Int)] = messages.map(_._2).flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
//打印
value.print()
ssc.start()
ssc.awaitTermination()
}
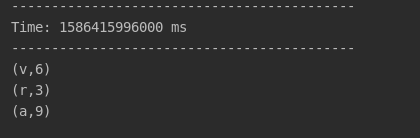
我们先开启kafka,在开启Spark Streaming项目进行测试
往producer端生产数据

然后查看控制台:
2.Direct方法
编写Spark Streaming项目代码
def main(args: Array[String]): Unit = {
//新建一个SparkConf 将Master和AppName设置进去
val conf: SparkConf = new SparkConf()
.setAppName("FlumePush")
.setMaster("local[2]")
//新建一个StreamingContext,第一个参数是上面定义的SparkConf
//第二个参数是个Seconds类型,表示多久进行一次批处理
val ssc = new StreamingContext(conf, Seconds(4))
//这边定义了brokers端口地址和topics名
val brokers = "localhost:9092"
val topics = "project"
//创建一个map存放信息,这边只要将brokers端口地址放进去就行了
val map = Map[String,String]("metadata.broker.list"->brokers)
//创建一个set存放topic名
val set: Set[String] = topics.split(",").toSet
//通过KafkaUtils.createDirectStream创建数据流
//要定义4个泛型分别是key类型,value类型,keyDecoder类型,valueDecoder类型
//有3个参数分别是StreamingContext,上面定义用于存放信息的map,用于存放topic的set
val messages: InputDStream[(String, String)] = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, map, set)
//我们需要先通过一个map拿到第二个有用信息再进行wc操作
messages.map(_._2).flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
//打印
.print()
ssc.start()
ssc.awaitTermination()
}
我们先开启kafka,在开启Spark Streaming项目进行测试
往producer端生产数据
然后查看控制台:
3.Kafka0.10版本Direct方法
def main(args: Array[String]): Unit = {
//新建一个SparkConf 将Master和AppName设置进去
val conf: SparkConf = new SparkConf()
.setAppName("StreamingApp")
.setMaster("local[2]")
//新建一个StreamingContext,第一个参数是上面定义的SparkConf
//第二个参数是个Seconds类型,表示多久进行一次批处理
val ssc = new StreamingContext(conf, Seconds(4))
//设置一个map存放kafka参数
val kafkaParams = Map[String, Object](
//broker端口地址
"bootstrap.servers" -> "localhost:9092",
//key和value的反序列化
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
//设置组id
"group.id" -> "1",
//自动偏移量设置
"auto.offset.reset" -> "latest",
//是否自动提交
"enable.auto.commit" -> (false: java.lang.Boolean)
)
//使用KafkaUtils.createDirectStream创建数据流,第一个参数StreamingContext
val stream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(ssc,
//第二个参数Location策略
LocationStrategies.PreferConsistent,
//第三个参数消费者策略,泛型是key和value的类型
//这里还有2个参数分别是装有topic名的array,上面定义的map类型的kafka参数
ConsumerStrategies.Subscribe[String, String]("test".split(","), kafkaParams))
//打印value
stream.map(x=>x.value()).print()
ssc.start()
ssc.awaitTermination()
}
运行,命令行启动生产者生存数据
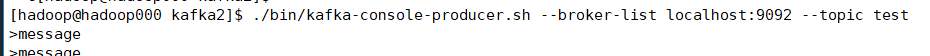
查看控制台:
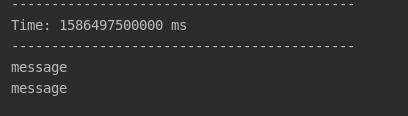














 192
192











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









