










目录
4.4 位置计算
本节介绍几个经常到用的位置计算操作。diff()和shift()经常用来计算数据的增量变化,rank()用来生成数据的整体排名。
4.4.1 位置差值diff()
df.diff()可以做位移差操作,经常用来计算一个序列数据中上一个数据和下一个数据之间的差值,如增量研究。默认被减的数列下移一位,原数据在同位置上对移动后的数据相减,得到一个新的序列,第一位由于被减数下移,没有数据,所以结果为NaN。可以传入一个数值来规定移动多少位,负数代表移动方向相反。Series类型如果是非数字,会报错,DataFrame会对所有数字列移动计算,同时不允许有非数字类型列。
pd.Series([9, 4, 6, 7, 9])
'''
0 9
1 4
2 6
3 7
4 9
dtype: int64
'''
# 后面与前面的差值
pd.Series([9, 4, 6, 7, 9]).diff()
'''
0 NaN
1 -5.0
2 2.0
3 1.0
4 2.0
dtype: float64
'''
# 后方向,移动两位求差值
pd.Series([9, 4, 6, 7, 9]).diff(-2)
'''
0 3.0
1 -3.0
2 -3.0
3 NaN
4 NaN
dtype: float64
'''对于DataFrame,还可以传入axis=1进行左右移动:
# 只筛选4个季度的5条数据
df.loc[:5,'Q1':'Q4'].diff(1, axis=1)
'''
Q1 Q2 Q3 Q4
0 NaN -68.0 3.0 40.0
1 NaN 1.0 0.0 20.0
2 NaN 3.0 -42.0 66.0
3 NaN 3.0 -25.0 7.0
4 NaN -16.0 12.0 25.0
5 NaN -11.0 74.0 -44.0
'''以上计算出了每个学生每个季度较前一个季度成绩的变化值。
4.4.2 位置移动shift()
shift()可以对数据进行移位,不做任何计算,也支持上下左右移动,移动后目标位置的类型无法接收的为NaN。
# 整体下移一行,最顶的一行为NaN
df.shift()
df.shift(3) # 移三行
# 整体上移一行,最底的一行为NaN
df.Q1.head().shift(-1)
# 向右移动一位
df.shift(axis=1)
df.shift(3, axis=1) # 移三位
# 向左移动一位
df.shift(-1, axis=1)
# 实现了df.Q1.diff()
df.Q1 - df.Q1.shift()4.4.3 位置序号rank()
rank()可以生成数据的排序值替换掉原来的数据值,它支持对所有类型数据进行排序,如英文会按字母顺序。使用rank()的典型例子有学生的成绩表,给出排名:
# 排名,将值变了序号
df.head().rank()
'''
name team Q1 Q2 Q3 Q4
0 4.0 5.0 4.0 1.0 2.0 2.0
1 2.0 2.5 1.0 2.0 3.0 1.0
2 1.0 1.0 2.0 4.0 1.0 4.0
3 3.0 2.5 5.0 5.0 5.0 3.0
4 5.0 4.0 3.0 3.0 4.0 5.0
'''
# 横向排名
df.head().rank(axis=1)
'''
Q1 Q2 Q3 Q4
0 4.0 1.0 2.0 3.0
1 1.0 2.5 2.5 4.0
2 2.0 3.0 1.0 4.0
3 3.0 4.0 1.0 2.0
4 3.0 1.0 2.0 4.0
'''参数pct=True可以将序数转换成0到1的数,让我们知道数据所处的位置:
df.head().rank(pct=True)
'''
name team Q1 Q2 Q3 Q4
0 0.8 1.0 0.8 0.2 0.4 0.4
1 0.4 0.5 0.2 0.4 0.6 0.2
2 0.2 0.2 0.4 0.8 0.2 0.8
3 0.6 0.5 1.0 1.0 1.0 0.6
4 1.0 0.8 0.6 0.6 0.8 1.0
'''method参数指定的排序过程中遇到相同值的序数计算方法,可取的值有下面几个。
average:序号的平均值,如并列第1名,则按二次元计算(1+2)/2,都显示1.5,下个数据的值为3。
min:最小的序数,如并列第1名,则都显示1,下个数据为3。
max:最大的序数,如并列第1名,则都显示1,下个数据为2。
first:如并列第1名,则都显示1,下个数据为2。
dense:按照索引的先后显示。
如果遇到空值,可以传入na_option='bottom',把空值放在最后,值为top放在前面。
shift()移动位置,diff()计算移动后的差值,rank()将位置上的数据在本序列的序号计算出来。
4.5 数据选择
除了上文介绍的查看DataFrame样本数据外,还需要按照一定的条件对数据进行筛选。通过Pandas提供的方法可以模拟Excel对数据的筛选操作,也可以实现远比Excel复杂的查询操作。
本节将介绍如何选择一列、选择一行、按组合条件筛选数据等操作,让你对数据的操作得心应手,灵活地应对各种数据查询需求。表4-1给出了最为常用的数据查询方法,下面将进行详细介绍。
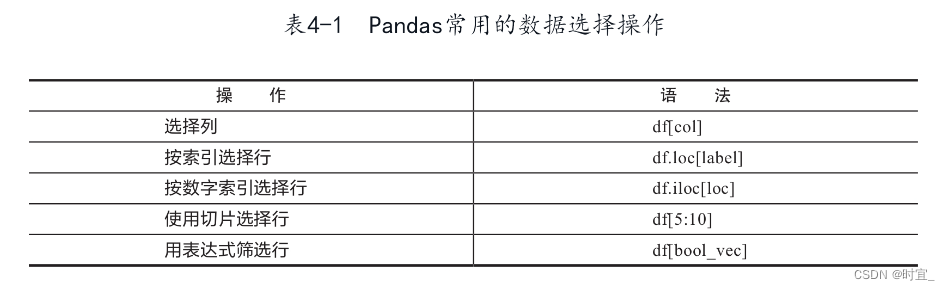
4.5.1 选择列
以下两种方法都可以取一列数据,得到的数据类型为Series:
df['name'] # 会返回本列的Series, 下同
df.name
df.Q1
'''
0 89
1 36
2 57
3 93
4 65
..
95 48
96 21
97 98
98 11
99 21
Name: Q1, Length: 100, dtype: int64
'''
type(df.Q1)
# pandas.core.series.Series这俩种操作方法效果是一样的,切片([])操作比较通用,当列名为一个合法的Python变量时,可以直接使用点操作(.name)为属性去使用。如列名为1Q、my name等,则无法使用点操作,因为变量不允许以数字开头或存在空格,如果想使用可以将列名处理,如将空格替换为下划线、增加字母开头前缀,如s_1Q、my_name。
4.5.2 切片[]
我们可以像列表那样利用切片功能选择部分行的数据,但是不支持仅索引一条数据:
df[:2] # 前两行数据
df[4:10]
df[:] # 所有数据,一般不这么用
df[:10:2] # 按步长取
s[::-1] # 反转顺序
df[2] # 报错!需要注意的是,切片的逻辑和Python列表的逻辑一样,不包括右边的索引值。如果切片里是一个列名组成的列表,则可筛选出这些列:
df[['name','Q4']]
'''
name Q4
0 Liver 64
1 Arry 57
2 Ack 84
3 Eorge 78
4 Oah 86
.. ... ..
95 Gabriel 74
96 Austin7 43
97 Lincoln4 20
98 Eli 91
99 Ben 74
[100 rows x 2 columns]
'''需要区别的是,如果只有一列,则会是一个DataFrame:
df[['name']] # 选择一列,返回DataFrame,注意与下例进行区分
df['name'] # 只有一列,返回Series切片中支持条件表达式,可以按条件查询数据,5.1节会详细介绍。
4.5.3 按轴标签.loc
df.loc的格式是df.loc[<行表达式>, <列表达式>],如列表达式部分不传,将返回所有列,Series仅支持行表达式进行索引的部分。loc操作通过索引和列的条件筛选出数据。如果仅返回一条数据,则类型为Series(见图4-2)。
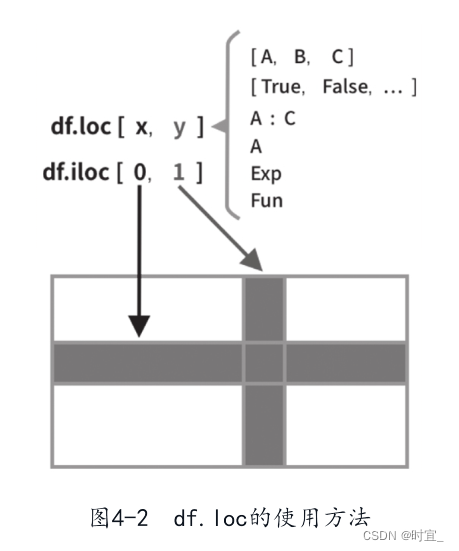
以下示例为单个索引:
# 代表索引,如果是字符,需要加引号
df.loc[0] # 选择索引为0的行
df.loc[8]
# 索引为name
df.set_index('name').loc['Ben']
'''
team E
Q1 21
Q2 43
Q3 41
Q4 74
Name: Ben, dtype: object
'''以下示例为列表组成的索引:
df.loc[[0,5,10]] # 指定索引为0,5,10的行
'''
name team Q1 Q2 Q3 Q4
0 Liver E 89 21 24 64
5 Harlie C 24 13 87 43
10 Leo B 17 4 33 79
'''
df.set_index('name').loc[['Eli', 'Ben']] # 两位学生,索引是name
df.loc[[False, True]*50] # 为真的列显示,隔一个显示一个以下示例为带标签的切片(包括起始和停止):
df.loc[0:5] # 索引切片,代表0~5行,包括5
df.loc['2010':'2014'] # 如果索引是时间,可以用字符查询,第14章会介绍
df.loc[:] # 所有
# 本方法支持Series附带列筛选,必须有行筛选。列部分的表达式可以是一个由希望筛选的表名组成的列表,也可以是一个用冒号隔开的切片形式,来表示从左到右全部包含,左侧和右侧可以分别省略,表示本侧所有列。
df.loc[0:5, ['name', 'Q2']]
'''
name Q2
0 Liver 21
1 Arry 37
2 Ack 60
3 Eorge 96
4 Oah 49
5 Harlie 13
'''
df.loc[0:9, ['Q1', 'Q2']] # 前10行,Q1和Q2两列
df.loc[:, ['Q1', 'Q2']] # 所有行,Q1和Q2两列
df.loc[:10, 'Q1':] # 0~10行,Q1后边的所有列
df.loc[:, :] # 所有内容以上方法可以混用在行和列表达式,.loc中的表达式部分支持条件表达式,可以按条件查询数据,后续章节会详细介绍。
4.5.4 按数字索引.iloc
与loc[]可以使用索引和列的名称不同,利用df.iloc[<行表达式>, <列表达式>]格式可以使用数字索引(行和列的0~n索引)进行数据筛选,意味着iloc[]的两个表达式只支持数字切片形式,其他方面是相同的。
df.iloc[:3] # 前三行
s.iloc[:3] # 序列中的前三个
df.iloc[:] # 所有数据
df.iloc[2:20:3] # 步长为3
df.iloc[:3, [0,1]] # 前两列
df.iloc[:3, :] # 所有列
df.iloc[:3, :-2] # 从右往左第三列以左的所有列以上方法可以混用在行和列表达式,.iloc中的表达式部分支持条件表达式,可以按条件查询数据,后续章节会详细介绍。
4.5.5 取具体值 .at/.iat
如果需要取数据中一个具体的值,就像取平面直角坐标系中的一个点一样,可以使用.at[]来实现。.at类似于loc,仅取一个具体的值,结构为df.at[<索引>,<列名>]。如果是一个Series,可以直接值入索引取到该索引的值。
# 注:索引是字符,需要加引号
df.at[4, 'Q1'] # 65
df.set_index('name').at['Ben', 'Q1'] # 21 索引是name
df.at[0, 'name'] # 'Liver'
df.loc[0].at['name'] # 'Liver'
# 指定列的值对应其他列的值
df.set_index('name').at['Eorge', 'team'] # 'C'
df.set_index('name').team.at['Eorge'] # 'C'
# 指定列的对应索引的值
df.team.at[3] # 'C'iat和iloc一样,仅支持数字索引:
df.iat[4, 2] # 65
df.loc[0].iat[1] # 'E'4.5.6 获取数据.get
.get可以做类似字典的操作,如果无值,则返回默认值(下例中是0)。格式为df.get(key, default=None),如果是DataFrame,key需要传入列名,返回的是此列的Series;如果是Series,需要传入索引,返回的是一个定值:
df.get('name', 0) # 是name列
df.get('nameXXX', 0) # 0,返回默认值
s.get(3, 0) # 93,Series传索引返回具体值
df.name.get(99, 0) # 'Ben'4.5.7 数据截取.truncate
df.truncate()可以对DataFrame和Series进行截取,可以将索引传入before和after参数,将这个区间以外的数据剔除。
df.truncate(before=2, after=4)
'''
name team Q1 Q2 Q3 Q4
2 Ack A 57 60 18 84
3 Eorge C 93 96 71 78
4 Oah D 65 49 61 86
'''
s.truncate(before=2, after=4)
'''
0 89
1 36
2 57
3 93
4 65
Name: Q1, dtype: int64
'''4.5.8 索引选择器
pd.IndexSlice是一个专门的索引选择器,它的使用方法类似df.loc[]切片中的方法,常用在多层索引中,以及需要指定应用范围(subset参数)的函数中,特别是在链式方法中。
df.loc[pd.IndexSlice[:, ['Q1', 'Q2']]]
# 变量化使用
idx = pd.IndexSlice
df.loc[idx[:, ['Q1', 'Q2']]]
df.loc[idx[:, 'Q1':'Q4'], :] # 多索引还可以按条件查询创建复杂的选择器,以下是几个案例:
# 创建复杂条件选择器
selected = df.loc[(df.team=='A') & (df.Q1>90)]
idxs = pd.IndexSlice[selected.index, 'name']
# 应用选择器
df.loc[idxs]
# 选择这部分区域加样式
df.style.applymap(style_fun, subset=idxs)本节介绍了数据查询的几个常用方法,可以根据需求把所需要的行和列筛选出来。切片([])就像列表的索引操作一样,可以按行把数据筛选出来,如果传入一个列表,则可以按列把指定的列筛选出来。.loc[]和.iloc[]中提供了行和列两个位置,可以按行和列组合筛选出数据,不同的是.iloc[]仅支持轴上的数字索引。
.at[]及.iat[]与.loc[]系列一样,不过它们的两个位置都只接受一个索引,得出的是一个具体值。.get()是一个类似于字典的操作,可以将数据当作字典来操作,Series的键是索引,DataFrame的键是列名。
————————————————————————————————















 2706
2706











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









