







4. 内存寻址方式
文章目录
- 参考视频:烟台大学贺利坚老师的网课《汇编语言程序设计系列专题》,或者是B站《汇编语言程序设计 贺利坚主讲》,大家一起看比较热闹。
- 中文教材:《汇编语言-第3版-王爽》(课程使用)、《汇编语言-第4版-王爽》(最新版)。
- 老师的博客:《迂者-贺利坚的专栏-汇编语言》
- 检测点答案参考:《汇编语言》- 读书笔记 - 各章检测点归档
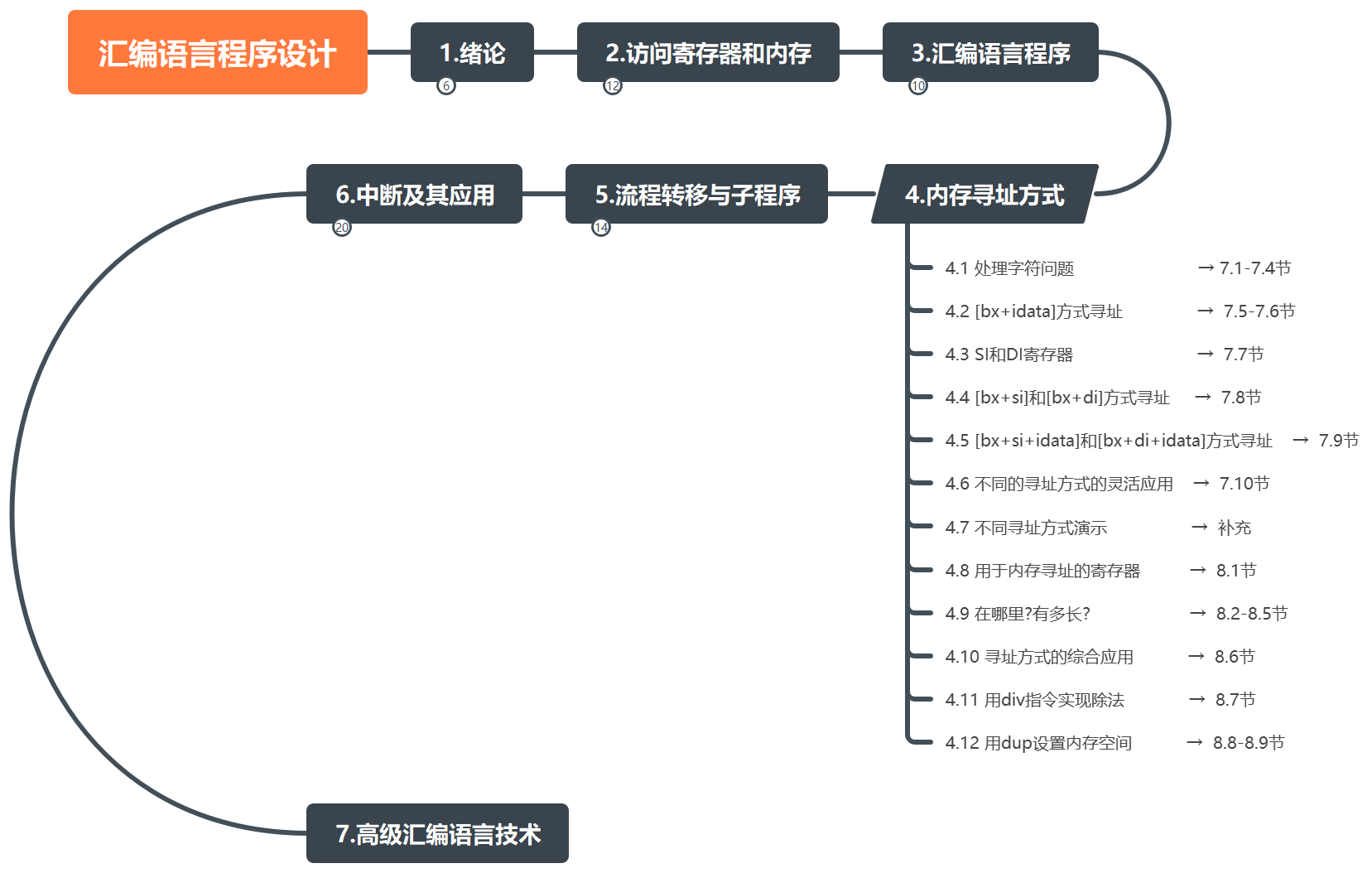
本篇笔记对应课程第四章(下图倾斜),章节划分和教材对应关系如下。
4.0 导学
参考教材第七章:介绍各种寻址方式。
【4.1 处理字符问题】是计算机常见应用,并引出内存寻址方式。
【4.2】【4.3】【4.4】【4.5】介绍不同的寻址方式。
【4.6 不同的寻址方式的灵活应用】
【4.7 不同寻址方式演示】参考教材第八章:对寻址方式进行更深层次的解答。
【4.8 用于内存寻址的寄存器】bp寄存器。
【4.9 数据在哪里?有多长?】
【4.10 寻址方式的综合应用】
【4.11 用div指令实现除法】除法指令。
【4.12 用dup设置内存空间】dup伪指令,重复定义内存空间的值。
4.1 处理字符问题
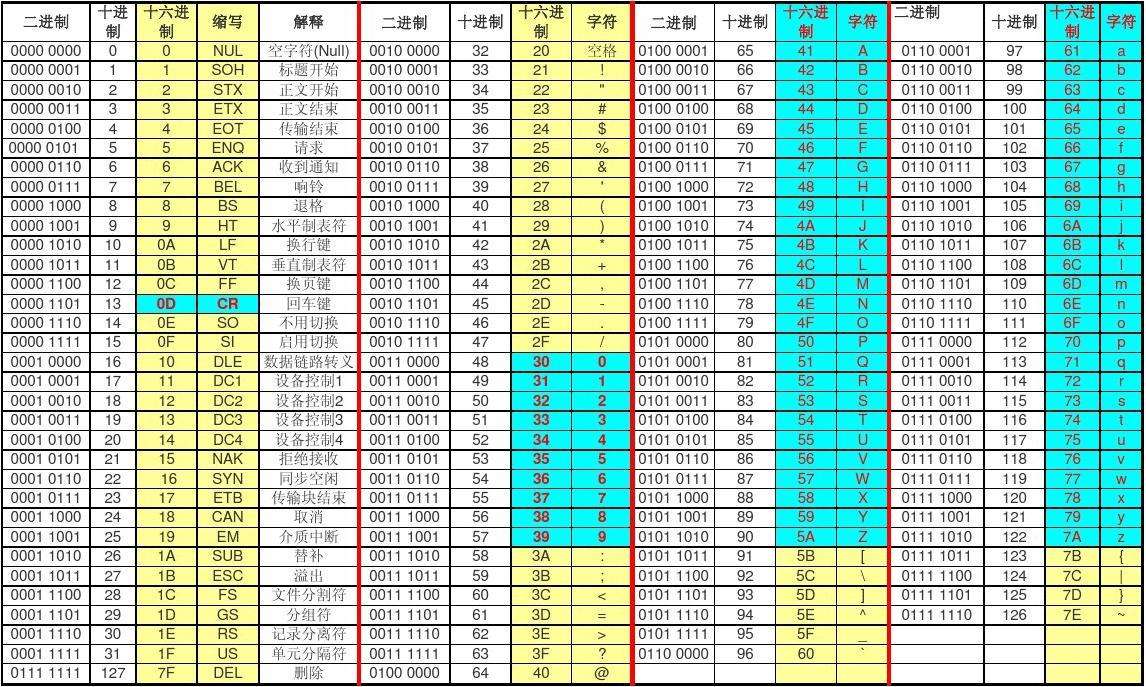
汇编程序中,用 单引号'...'的方式指明数据是以字符的形式给出的,编译器将把它们转化为相对应的ASCII码。可以发现,小写字母比大写字母的ASCII码大32,也就是第6位正好取反。于是利用汇编指令中的 逻辑或and、逻辑与or,通过将第6位强制置为0/1,就可以很方便地实现大小写转换:
【代码示例】将字符 ‘BaSiC’ 全部转为大写,将第二个字符 ‘iNfOrMaTiOn’ 全部转为小写。
关键:ASCII码中,小写字母第6位必为1,大写字母第6位必为0,其余位全部相同。assume ds:data,cs:code data segment db 'BaSiC' db 'iNfOrMaTiOn' data ends code segment start: ; 数据段寄存器 mov ax,data mov ds,ax ; 第一个字符串转大写 mov bx,0 mov cx,5 s0: mov al,ds:[bx] and al,11011111b ; 第6位强制置为0,是大写 mov ds:[bx],al inc bx loop s0 ; 第二个字符串转小写 mov cx,11 s1: mov al,ds:[bx] or al,00100000b ; 第6位强制置为1,小写 mov ds:[bx],al inc bx loop s1 mov ax,4c00h int 21h code ends end start
4.2 [bx+idata]方式寻址
上述我们一直使用 ds:[bx]的方式访问内存单元,但每次访问都需要重新设置 bx太麻烦了。于是我们可以使用 [bx+idata]表示一个内存单元,它的偏移地址为 (bx)+idata(bx中的数值加上idata),称为“相对寻址”。这类似于C语言的数组索引。下面以 mov ax,[bx+200]为例,给出几种等价的表示形式:
mov ax,[bx+200]mov ax,[200+bx]mov ax,200[bx]mov ax,[bx].200
下面来看一个代码示例:
【代码示例】将字符 ‘BaSiC’ 全部转为大写,将第二个字符 ‘MinIx’ 全部转为小写。
关键点:注意两字符长度相同,使用[bx+idata]配合1个循环就可以完成任务,增加了代码的简洁性、可读性。assume ds:data,cs:code data segment db 'BaSiC' db 'MinIx' data ends code segment start: ; 数据段寄存器 mov ax,data mov ds,ax ; 转换字符 mov bx,0 mov cx,5 s0: mov al,ds:[bx] and al,11011111b ; 第6位强制置为0,转大写 mov ds:[bx],al mov al,ds:[bx+5] ; ix+idata的形式,这个5表示第一个字符的长度 or al,00100000b ; 第6位强制置为1,转小写 mov ds:[bx+5],al inc bx loop s0 mov ax,4c00h int 21h code ends end start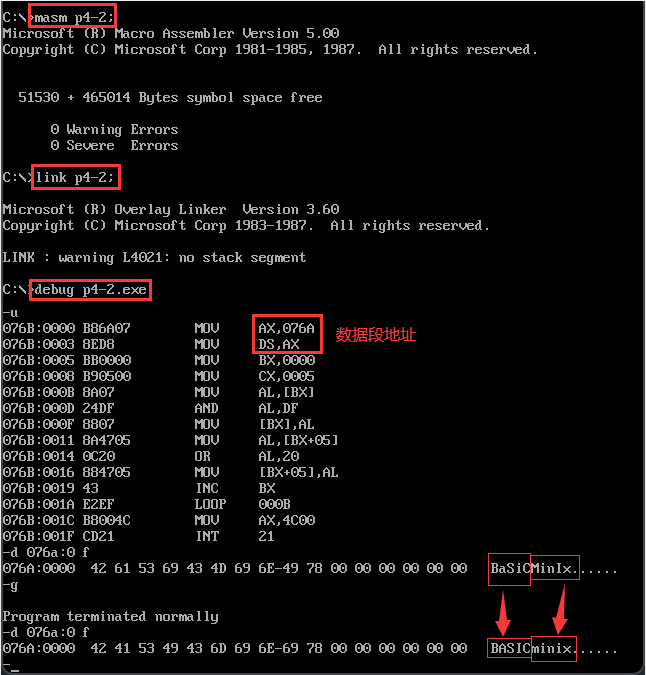
4.3 SI和DI寄存器
8086CPU中的16个寄存器:
- 通用寄存器:AX、BX、CX、DX
- 变址寄存器:SI(Source Index)、DI(Destination Index)
- 指针寄存器:SP、BP
- 指令指针寄存器: IP
- 段寄存器:CS、SS、DS、ES
- 标志寄存器:PSW
本小节我们来介绍上述的 源变址寄存器SI、目标变址寄存器DI。BX、SI、DI经常执行与地址有关的操作,但涉及到数组相关的数据索引时,优先使用 SI、DI。它们的区别如下:
- BX:常用于基址寄存器,且可以被拆成 BH、BL 使用。
- SI:
ds:[si]常用于指向源字符串,不可拆分。- DI:
ds:[di]常用于指向目标字符串,不可拆分。
下面来看一个例子:
【代码示例】用寄存器SI和DI实现将字符串‘welcome to masm!’复制到它后面的数据区中。
提示:严格来说,数据流可以为 [si] -> ax -> [di],但根据上一小节,我们可以使用 [si+idata] 的形式。assume ds:data,cs:code data segment db 'welcome to masm!' ; 16个字节 db '................' data ends code segment start: ; 数据段寄存器 mov ax,data mov ds,ax ; 转换字符 mov si,0 mov cx,8 ; 按字为单位,循环8次即可 s0: mov ax,ds:[si] mov ds:[si+16],ax add si,2 loop s0 mov ax,4c00h int 21h code ends end start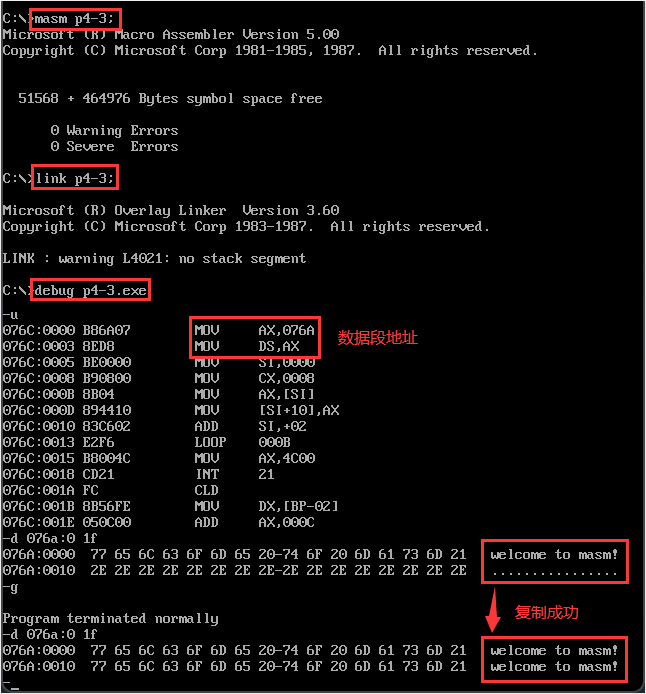
4.4 [bx+si]和[bx+di]方式寻址
我们也可以使用 [bx+si]和 [bx+di]方式指定内存单元,称为“基址变址寻址”。下面是等价形式:
mov ax,[bx+si]mov ax,[bx][si]
4.5 [bx+si+idata]和[bx+di+idata]方式寻址
进一步我们还可以使用 [bx+si+idata]表示一个内存单元,称为“相对 基址变址 寻址”,下面是等价形式:
mov ax,[bx+si+200]mov ax,[bx+200+si]mov ax,[200+bx+si]mov ax,200[bx][si]mov ax,[bx].200[si]mov ax,[bx][si].200
4.6 不同的寻址方式的灵活应用
| 形式 | 名称 | 特点 | 示例 |
|---|---|---|---|
| [idata] | 直接寻址 | 用一个常量/立即数来表示地址, 用于直接定位一个内存单元。 | mov ax,[200] |
| [bx] | 寄存器间接寻址 | 用一个变量来表示内存地址, 用于间接定位一个内存单元。 | mov bx,0 mov ax,[bx] |
| [bx+idata] | 寄存器相对寻址 | 用一个变量和常量表示地址, 可在一个起始地址的基础上用变量间接定位一个内存单元。 | mov bx,4 mov ax,[bx+200] |
| [bx+si] | 基址变址寻址 | 用两个变量表示地址 | mov ax,[bx+si] |
| [bx+si+idata] | 相对基址变址寻址 | 用两个变量和一个常量表示地址 | mov ax,[bx+si+200] |
上表总结了不同的寻址方式,下面来看几个灵活使用多种寻址方式进行编程的案例:
【代码示例1】编程将datasg段中每个单词的头一个字母改为大写字母,datasg的数据存储结构如下图。
思路:每一行长度固定为16且索引3位置就是首字母,直接 [bx+idata] 寻址即可。
assume ds:datasg,cs:codesg datasg segment db '1. file ' db '2. edit ' db '3. serach ' db '4. view ' db '5. options ' db '6. help ' datasg ends codesg segment start: ; 数据段寄存器 mov ax,datasg mov ds,ax ; 遍历每一行 mov bx,0 mov cx,6 s0: mov al,[bx+3] and al,11011111b ; 变成大写 mov [bx+3],al add bx,16 loop s0 mov ax,4c00h int 21h codesg ends end start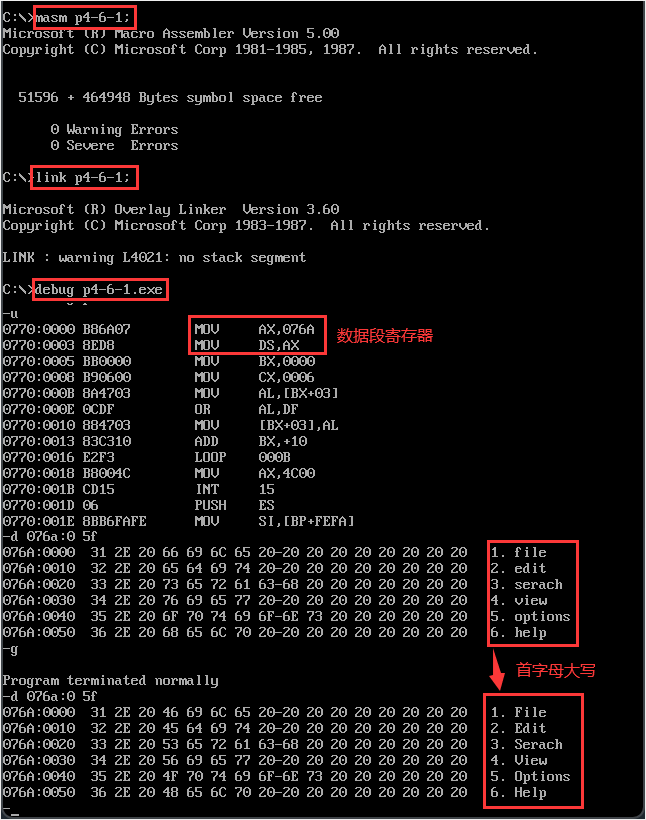
【代码示例2】编程将datasg段中每个单词的所有字母都改为大写字母,datasg的数据存储结构如下图。
难点:需要二重循环,使用 [bx+si] 遍历每一个字母,但只有一个CX。下面给出三种处理方法。
【方法一】外层循环的 CX 保存在 DX 中,内层循环用 CX。【不推荐】
assume ds:datasg,cs:codesg datasg segment db 'ibm ' db 'dec ' db 'dos ' db 'vax ' datasg ends codesg segment start: ; 数据段寄存器 mov ax,datasg mov ds,ax ; 遍历每一行 mov bx,0 mov cx,4 s0: mov dx,cx ; 外循环的cx保存在dx ; 遍历一行中的三个字母 mov si,0 mov cx,3 s1: mov al,[bx+si] and al,11011111b ; 变成大写 mov [bx+si],al inc si loop s1 mov cx,dx add bx,16 loop s0 mov ax,4c00h int 21h codesg ends end start【方法二】外层循环的 CX 保存在 固定内存空间ds:40H 中,内层循环用 CX。
assume ds:datasg,cs:codesg datasg segment db 'ibm ' db 'dec ' db 'dos ' db 'vax ' datasg ends codesg segment start: ; 数据段寄存器 mov ax,datasg mov ds,ax ; 遍历每一行 mov bx,0 mov cx,4 s0: mov ds:[40h],cx ; 外循环的cx保存在ds:40h ; 遍历一行中的三个字母 mov si,0 mov cx,3 s1: mov al,[bx+si] and al,11011111b ; 变成大写 mov [bx+si],al inc si loop s1 mov cx,ds:[40h] ; 取回外层循环CX add bx,16 loop s0 mov ax,4c00h int 21h codesg ends end start【方法三】外层循环的 CX 压栈,内层循环用 CX。【推荐】
assume ds:datasg,ss:stacksg,cs:codesg datasg segment db 'ibm ' db 'dec ' db 'dos ' db 'vax ' datasg ends stacksg segment dw 0,0,0,0,0,0,0,0 stacksg ends codesg segment start: ; 数据段寄存器 mov ax,datasg mov ds,ax ; 栈段寄存器 mov ax,stacksg mov ss,ax mov sp,16 ; 遍历每一行 mov bx,0 mov cx,4 s0: push cx ; 外循环的cx压栈 ; 遍历一行中的三个字母 mov si,0 mov cx,3 s1: mov al,[bx+si] and al,11011111b ; 变成大写 mov [bx+si],al inc si loop s1 pop cx ; 取回外层循环CX add bx,16 loop s0 mov ax,4c00h int 21h codesg ends end start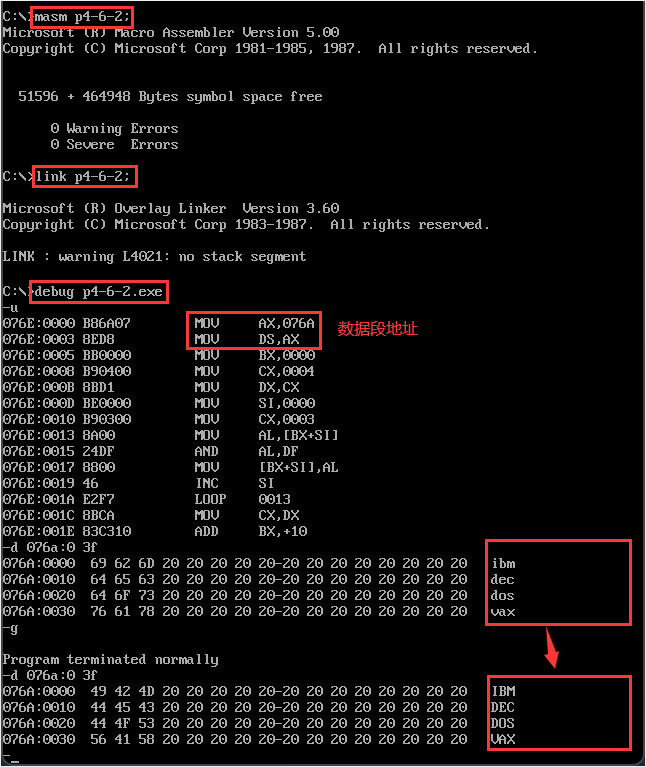
4.7 不同寻址方式演示
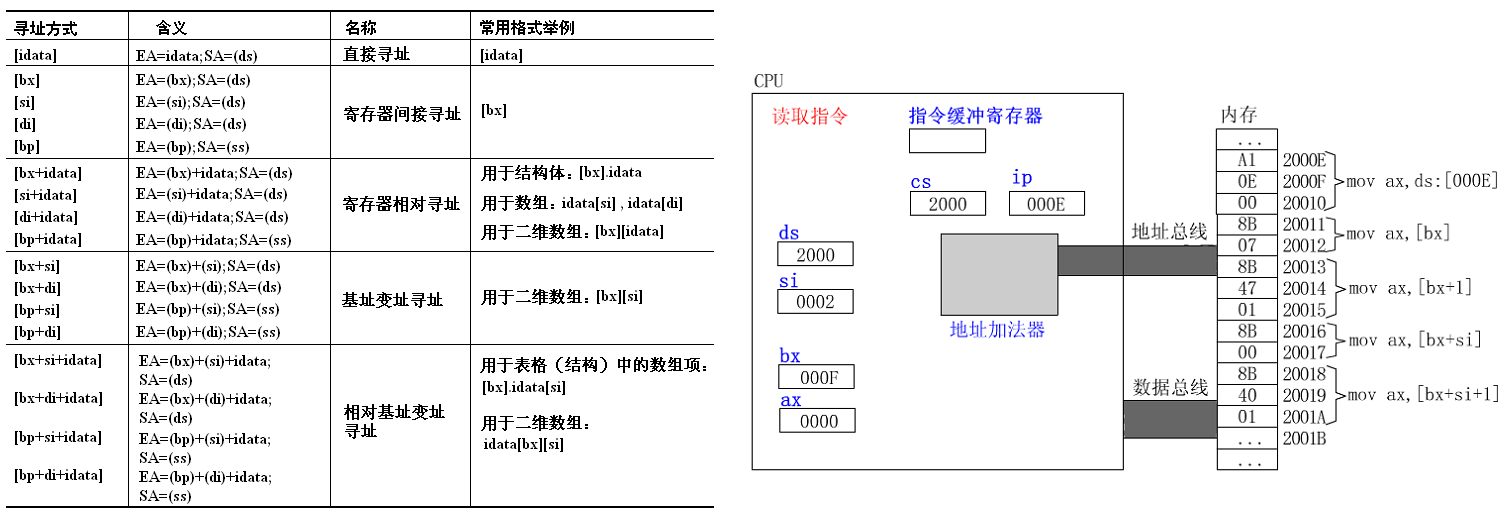
上左图基于表4-1进行更为完善的总结,右图则是演示了不同的寻址方式的动态过程,整体步骤如下:
- 取指令:根据 CS:IP 从内存取出当前指令。
- 合成地址:根据指令合成地址,段地址来自于DS,偏移地址来自于“指令缓冲寄存器”、SI、DI等寄存器。
- 取数据:根据合成的地址从内存中取出数据。
注:偏移地址中的立即数 idata 从“指令缓冲寄存器”中得到。
注:上右图 CS 和 DS 的值相同,说明了汇编语言中,二进制码是数据还是指令完全取决于程序员,也给了黑客可乘之机。
注:上右图的动态演示见视频“不同寻址方式演示”。
4.8 用于内存寻址的寄存器
8086CPU中的16个寄存器:
- 通用寄存器:AX、BX、CX、DX
- 变址寄存器:SI、DI
- 指针寄存器:SP、BP(B Pointer,起名类似于 BX)
- 指令指针寄存器: IP
- 段寄存器:CS、SS、DS、ES
- 标志寄存器:PSW
本小节介绍 BP 寄存器。8086的16个寄存器中,只有BX、BP、SI、DI可以用于内存寻址,其他的通用寄存器、段寄存器不能用于 [...]寻址,比如 [cx]、[ds]是错误的。并且在使用上来说,如上图,bx、bp属于同一等级,si、di属于同一等级,同一等级不能重复使用,比如 [bx+bp]、[si+di]就是错误的指令。
4.9 数据在哪里?有多长?
内存寻址时,数据在哪里,由 [...]中的内容给出:
立即数(idata):对于直接包含在机器指令中的数据,称为立即数(idata),数据包含在指令中。
寄存器:指令要处理的数据在寄存器中,在汇编指令中给出相应的寄存器名。
内存:指令要处理的数据在内存中,由段地址和偏移地址 SA:EA 确定内存单元。注意下面 BX 和 BP 的使用。



内存寻址时,数据有多长,则是由指令默认解析或者程序员指明:
指令默认解析:内存单元访问指令中,有寄存器参与,则根据寄存器的宽度决定。
用
word ptr或byte ptr指明:内存单元访问指令中,没有寄存器参与,必须由程序员显性指明数据长度!

4.10 寻址方式的综合应用
本小节通过以下的示例,演示内存寻址时使用结构化思想处理数据:
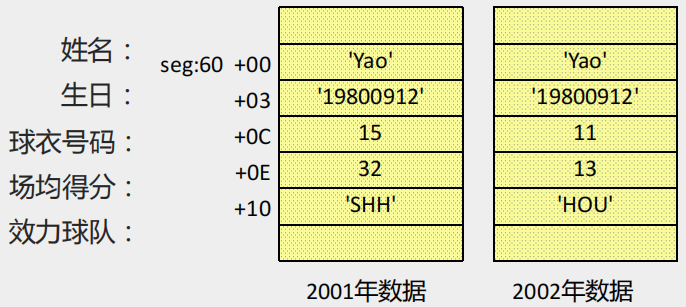
【代码示例】如下图给出了姚明的信息变化,编程修改内存中的过时数据。
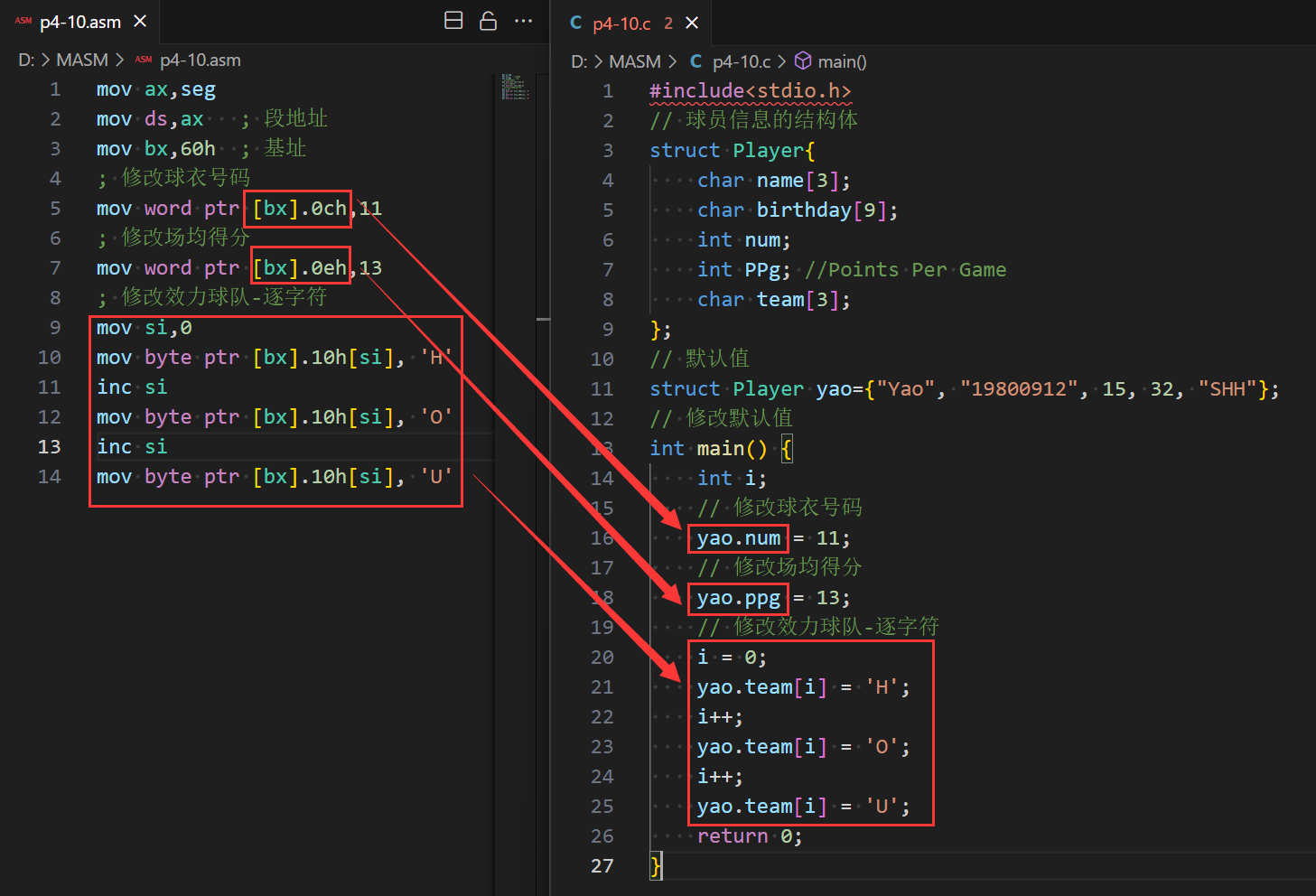
- C语言中的
yao.team[i]:yao 是一个变量名,指明了结构体变量的地址;team 是一个名称,指明了数据项 team 的地址;i 用来定位 team 中的字符。- 汇编程序中的
[bx].idata[si]:用 bx 定位整个结构体;用 idata 定位结构体中的某一个数据项;用 si 定位数据项中的元素。
4.11 用div指令实现除法
本小节介绍除法指令 div,其后面只有一个操作数——“除数”所在的寄存器或内存单元,涉及到AX、DX寄存器。8086CPU中可以进行8位除法、16位除法,由操作数决定,若为寄存器则可以直接参考寄存器长度,否则需要程序员使用 byte ptr、word ptr指定位数。使用除法指令时,切记提前在默认寄存器中设置好“被除数”,且默认寄存器不作别的用处,四个操作数的说明:
- 除数:由操作数给出所在位置,若为内存单元必须指出数据长度。
- 被除数:固定存储在DX、AX中。8位除法存储在AX中;16位除法则是高16位在DX、低16位在AX。
- 商:8位除法为AL、16位除法为AX。
- 余数:8位除法为AH、16位除法为DX。
| 示例指令 | 被除数 | 除数 | 商 | 余数 | |
|---|---|---|---|---|---|
| 8位除法 | div bl | (ax) | (bl) | (al) | (ah) |
| div byte ptr ds:[0] | (ax) | ((ds)*16+0) | (al) | (ah) | |
| div byte ptr [bx+si+8] | (ax) | ((ds)*16+(bx)+(si)+8) | (al) | (ah) | |
| 16位除法 | div bx | (dx)*10000H+(ax) | (bx) | (ax) | (dx) |
| div word ptr es:[0] | (dx)*10000H+(ax) | ((ds)*16+0) | (ax) | (dx) | |
| div word ptr [bx+si+8] | (dx)*10000H+(ax) | ((ds)*16+(bx)+(si)+8) | (ax) | (dx) | |
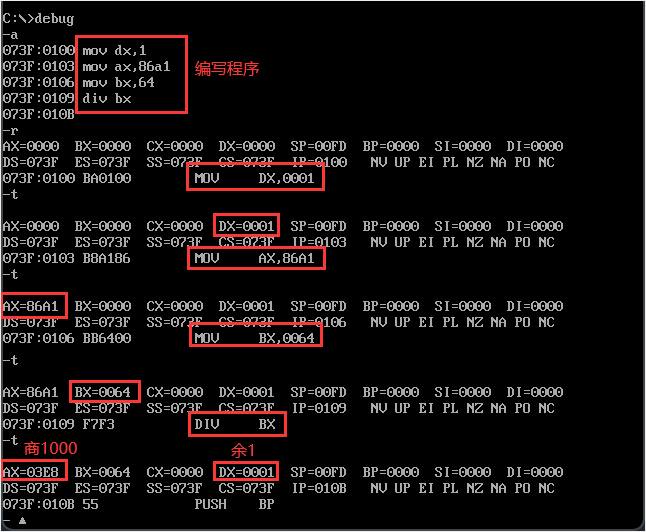
【代码示例1-寄存器除法】利用除法指令计算100001/100。
关键点:232>100001D=186A1H>216,需要进行16位除法。被除数的高16位 0001H 放DX、低16位 86A1H 放AX。
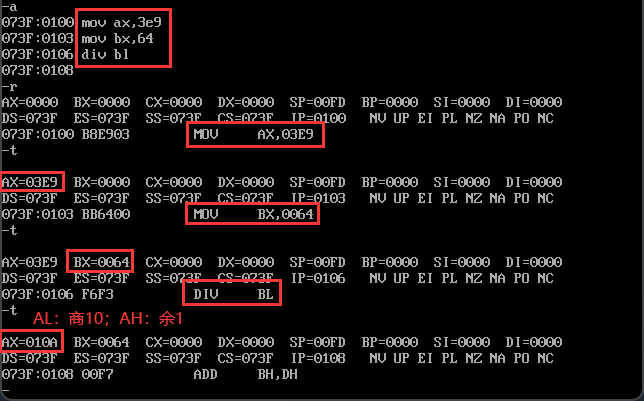
【代码示例2-寄存器除法】利用除法指令计算1001/100。
关键点:1001D=3E9H<216,且除数100D=64H<28,可以进行8位除法。被除数 3E9H 放AX。
【代码示例3-内存单元除法】定义数据段三个数据
dd 100001、dw 100、dw 0,计算第一个数据除以第二个数据后的结果,并将商存放在第3个数据的存储单元中。
关键点:和示例1相同,需要进行16位除法。注意dd是双字(4字节)。assume ds:data,cs:code data segment dd 100001 dw 100 dw 0 data ends code segment start: ; 数据段寄存器 mov ax,data mov ds,ax ; 被除数 mov dx,ds:[2] ; 注意这里的高位 mov ax,ds:[0] ; 除法 div word ptr ds:[4] ; 保存结果 mov ds:[6],ax mov ax,4c00h int 21h code ends end start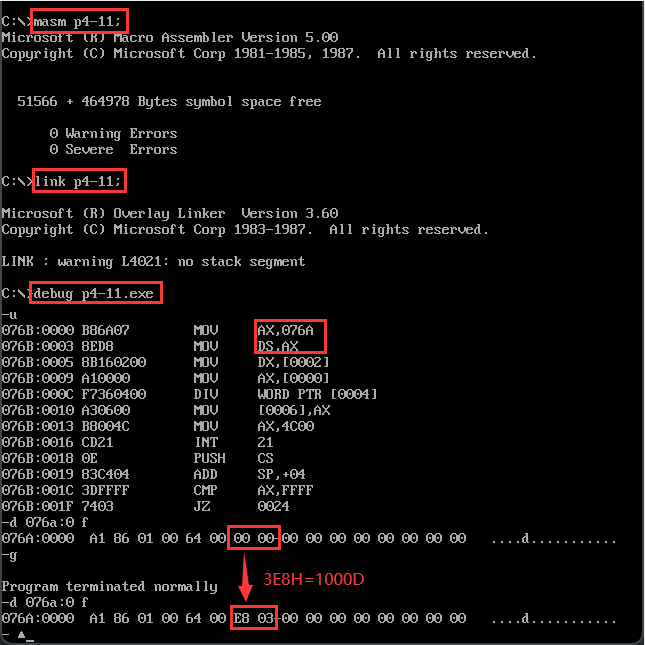
4.12 用dup设置内存空间
dup(duplicate)和 db、dw、dd等数据定义伪指令配合使用,用来进行数据的重复。使用格式如下:
db 重复的次数 dup (字节型数据)dw 重复的次数 dup (字型数据)dd 重复的次数 dup (双字数据)
指令 功能 相当于 db 3 dup (0) 定义了3个字节,它们的值都是0 db 0,0,0 db 3 dup (0,1,2) 定义了9个字节,由0、1、2重复3次构成 db 0,1,2,0,1,2,0,1,2 db 3 dup (‘abc’,‘ABC’) 定义了18个字节,构成’abcABCabcABCabcABC’ db ‘abcABCabcABCabcABC’
【代码示例】定义一个容量为 200 个字节的栈段。
关键点:体会 dup 带来的简洁之处。

















 6923
6923

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











