






描述
题目描述:
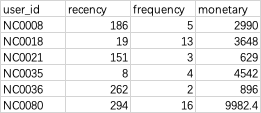
现有某店铺会员消费情况sales.csv。包含以下字段:
- user_id:会员编号;
- recency:最近一次消费距离当天的天数;
- frequency:一段时间内消费的次数;
- monetary:一段时间内消费的总金额。
请你统计最有价值的用户中消费金额最多的前5名用户。
输入描述:
数据集可以从当前目录下sales.csv读取。
输出描述:
请你先对每个用户销售情况的每个特征进行评分,分值为1-4分。再将所有评分拼接到一起形成新的列RFMClass。
评分规则如下: 对于recency特征,值越小越好。对于frequency和monetary值越大越好。如对于recency:
- 数值小于等于下四分位数则评为4分;
- 大于下四分位数并且小于等于中位数则评为3分;
- 大于中位数且小于等于上四分位数则评为2分;
- 大于上四分位数则评为1分。
对于frequency和monetary则方法刚好相反。
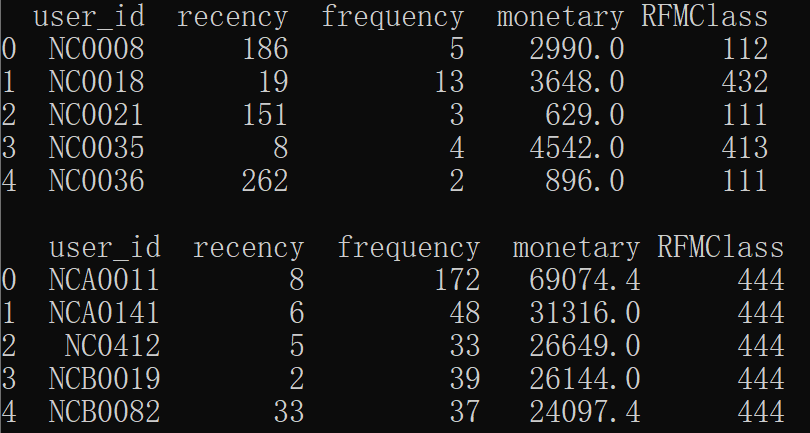
请你输出评分后的数据的前5行并输出最有价值的用户(评分为“444”)中销售总金额最高的前5位(索引从0开始),以上数据集的输出如下图所示(两次输出之间有一个空行)。
解答
import pandas as pd
sales = pd.read_csv('sales.csv')
def get_score(x,df,loc,big_better = True):
q1 = df[loc].quantile(0.25)
q2 = df[loc].quantile(0.50)
q3 = df[loc].quantile(0.75)
if big_better == True:
if x >= q3:
return 4
elif x >= q2:
return 3
elif x >=q1:
return 2
else:
return 1
else:
if x >= q3:
return 1
elif x >= q2:
return 2
elif x >=q1:
return 3
else:
return 4
sales['R_Quartile'] = sales['recency' ].apply(lambda x:get_score(x,sales,'recency',False)).astype(str)
sales['F_Quartile'] = sales['frequency'].apply(lambda x:get_score(x,sales,'frequency',True)).astype(str)
sales['M_Quartile'] = sales['monetary' ].apply(lambda x:get_score(x,sales,'monetary',True)).astype(str)
sales['RFMClass'] = sales['R_Quartile']+sales['F_Quartile']+sales['M_Quartile']
print(sales[['user_id','recency','frequency','monetary','RFMClass']].head(5))
result = sales[sales['RFMClass']=='444'].sort_values('monetary',ascending= False)
print(result[['user_id','recency','frequency','monetary','RFMClass']].reset_index(drop=True).head(5))
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









