







个人学习记录,不定时更新相关内容
特征工程
生成特征变量
个体变量时间序列样本排列之 cumcount
cumcount
通过groupby()函数和cumcount()函数生成分类数据的样本排列值。默认从0开始计数
raw["dcount"] = raw.groupby(['cfips'])['row_id'].cumcount()
字符串映射为数字
pandas.factorize()
将送入的字符映射成数字,原则是相同的字符对应同一个数字。
观察直到,该函数输入一个sequence,返回一个元组,包含一个array对象和index类型对象。
其实就是将分类字符串进行编码,用数字表示
raw['county_i'] = (raw['county'] + raw['state']).factorize()[0]
raw['state_i'] = raw['state'].factorize()[0]
回归预测生成数据
通过与年度序列建立回归,生成以后的年度的数据
# demo
# fit a linear regression
import statsmodels.formula.api as sm
fit = sm.ols(formula="dependent_variable ~ independent_variable", data=df).fit()
print(fit.summary())
predict = fit.predict(df)
df['fitted'] = predict
# fit a linear regression
import statsmodels.formula.api as sm
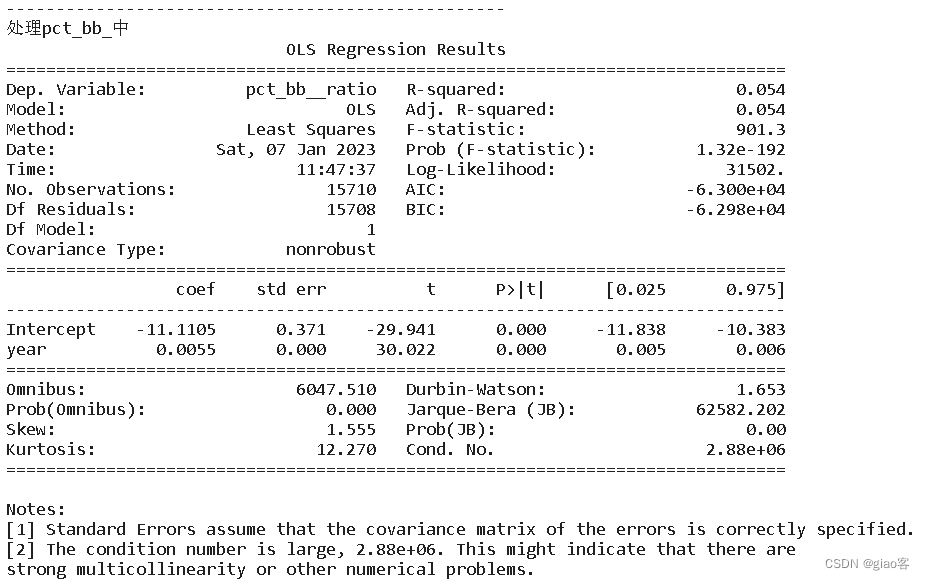
for i in list(census.columns)[2:7]:
print('-'*50)
print('处理{}中'.format(i))
fit = sm.ols(formula=f"{i}_ratio ~ year", data=census).fit()
print(fit.summary())
predict = fit.predict(census)
df['fitted'] = predict
用变量生成滞后变量 lag_n
用变量生成差值变量 diff_n
生成增长率 ratio
增长率(growth rate)也称增长速度,它是时间序列中报告期观察值与基期观察值之比减1 后的结果,用%表示。由于对比的基期不同,增长率可以分为环比增长率和定基增长率。
环比增长速度=(报告期发展水平-基期发展水平)/绝对值基期发展水平
发展速度
环比发展速度=报告期发展水平/基期发展水平=环比增长速度+1
日期数据提取
年份数据
假设变量存在随着年份而变动的情况,可以将年份数据转换为数值型数据(int)
data.year = data['year'].astype('int')
月份数据
如果样本中月份数据是关于12个月份的话。可以将月份数据get_dummies,生成独热特征变量。调用drop_first=True可以避免多重共线性
data = pd.get_dummies(data, columns=['month'], drop_first=True)
生成均值特征变量 mean
对于多个个体,可以根据个体进行分类,生成关于个体的均值特征变量
df = data.groupby('cfips']['density'].agg([('denstiy_mean',np.mean)])
data = data.merge(df,on=['cfips'], how='left')















 2961
2961











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









