







【场景描述】
在df中对多个变量进行分组统计,并同时计算多个聚合函数比如sum、mean时,会出现多层列名的问题,不方便后续数据处理
【关键代码】
train = df.groupby(['time_id', 'stock_id'], as_index=False)[['ask_price', 'bid_price']].agg(
['sum', 'mean', 'std', 'max', 'min'])
train.columns = [f'{col[0]}_{col[1]}' for col in train.columns] # 合并不同层级的列名
train = train.reset_index()
【场景还原】
假设我们有一个示例数据集,包含了股票的交易信息,数据集如下:
import pandas as pd
# 创建示例数据
data = {
'time_id': [1, 1, 2, 2],
'stock_id': [1, 2, 1, 2],
'ask_price': [10, 20, 15, 25],
'bid_price': [9, 18, 14, 23],
'matched_size': [100, 200, 150, 250],
'seconds_in_bucket': [60, 120, 90, 180]
}
df = pd.DataFrame(data)
print(df)
输出:
time_id stock_id ask_price bid_price matched_size seconds_in_bucket
0 1 1 10 9 100 60
1 1 2 20 18 200 120
2 2 1 15 14 150 90
3 2 2 25 23 250 180
在df中对多个变量进行分组统计,并同时计算多个聚合函数比如sum、mean时,会出现多层列名的问题,不方便后续数据处理
train = df.groupby(['time_id', 'stock_id'], as_index=False)[['ask_price', 'bid_price', 'matched_size', 'seconds_in_bucket']].agg(
['sum', 'mean', 'std', 'max', 'min'])
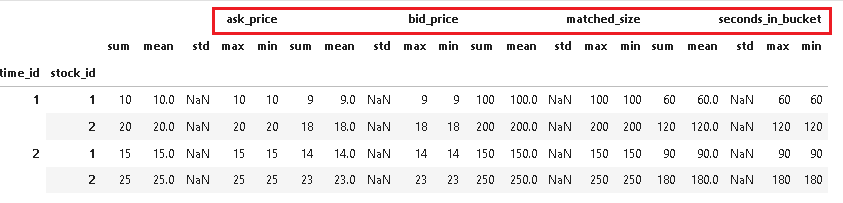
现在,我们希望将多层级的列名合并到单层级的列名中,使用上述提供的代码进行处理:
train.columns = [f'{col[0]}_{col[1]}' for col in train.columns] # 合并不同层级的列名
train = train.reset_index()
print(train)
输出:
time_id stock_id ask_price_sum ask_price_mean ask_price_std ask_price_max ask_price_min bid_price_sum bid_price_mean bid_price_std bid_price_max bid_price_min matched_size_sum matched_size_mean matched_size_std matched_size_max matched_size_min seconds_in_bucket_sum seconds_in_bucket_mean seconds_in_bucket_std seconds_in_bucket_max seconds_in_bucket_min
0 1 1 10 10.0 NaN 10 10 9 9.0 NaN 9 9 100 100.0 NaN 100 100 60 60.0 NaN 60 60
1 1 2 20 20.0 NaN 20 20 18 18.0 NaN 18 18 200 200.0 NaN 200 200 120 120.0 NaN 120 120
2 2 1 15 15.0 NaN 15 15 14 14.0 NaN 14 14 150 150.0 NaN 150 150 90 90.0 NaN 90 90
3 2 2 25 25.0 NaN 25 25 23 23.0 NaN 23 23 250 250.0 NaN 250 250 180 180.0 NaN 180 180
在这个例子中,我们对df数据集进行了分组,并使用agg()函数计算了每组数据的总和、均值、标准差、最大值和最小值。然后,我们使用列表推导式将多层级的列名合并到单层级的列名中。
最后,我们使用reset_index()将time_id和stock_id重新设置为普通列,得到了合并了不同层级的列名的DataFrame对象train。















 9154
9154











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









