







一、简介
小白一枚,如有不足,请不吝赐教。第一篇文章,写的可能很乱很杂,望海涵。
本文总体架构和站内大佬的的差不太多,登录过程总共分为三个阶段:预登录,登录和最后的跳转登录。不过我查看站内大佬的资源以及github上的资源时发现,时间都是比较久远的了,对于现在的微博反爬技术稍稍有一点不足,比如现在登录需要特殊验证渠道去实现:扫码验证、微博内点击验证以及短信验证。鄙人都实现了,其实原理都差不多,因此我就发了这个相对于而言验证操作比较简单的来作为例子讲解。
二、过程分析
2.1 预登录
当我们打开微博登录界面的时候,在这个账号输入框内输入账号的时候,当失去焦点,抓包抓取到了一个prelogin的包。

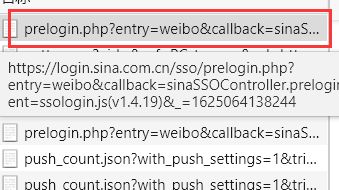
下面是他的查询字符串参数列表:

分析这个包的查询字符串参数的时候,经过多次尝试,我发现只有这个 _ 和su是改变的,而它其实很明显的是一个时间戳,在python里面用time.time()就可以很简单的实现,对于su,如果有一定js逆向经验,不难看出这是一个base64编码得到的字符串(以 = 结尾,其实看到这种没有什么头绪的,就可以猜,计算机常用的编码技术无非哪几种,而在js中用的最多的应该就是md5和base64了吧),通过反编码之后可以知道,其实这个su就是账号的编码(网上就有base64反编码的网址)。所以上述包的请求参数列表我们可以通过下述代码实现。
params = {
"entry": "cnmail",
"callback": "sinaSSOController.preloginCallBack",
"su": str(base64.b64encode(bytes(account, encoding="utf-8")), encoding="utf-8"), # base64编码之后的用户账号
"rsakt": "mod",
"client": "ssologin.js(v1.4.19)",
"_": str(int(time.time() * 1000)) # 时间戳
}这个时候我们可以用requests发起请求了,我们会得到下面的一串信息:

这些信息在后面的登录里面都会用得上。
2.2 登 录
登录最重要的就是拿到第一个通行证,大概长这样子:
<html>
<head>
<title>新浪通行证</title>
<meta http-equiv="refresh" content="0; url='https://weibo.com/ajaxlogin.php?framelogin=1&callback=parent.sinaSSOController.feedBackUrlCallBack&sudaref=mail.sina.com.cn&display=0&retcode=2071&reason=%C7%EB%CA%B9%D3%C3%C9%A8%C2%EB%B5%C7%C2%BC&protection_url=https%3A%2F%2Fpassport.weibo.com%2Fprotection%2Findex%3Ftoken%3D2YWVg3H73AASyHdnT5GHfXjI-TXP83ZQmCnByb3RlY3Rpb24.'"/>
<meta http-equiv="Content-Type" content="text/html; charset=GBK" />
</head>
<body bgcolor="#ffffff" text="#000000" link="#0000cc" vlink="#551a8b" alink="#ff0000">
<script type="text/javascript" language="javascript">
location.replace("https://weibo.com/ajaxlogin.php?framelogin=1&callback=parent.sinaSSOController.feedBackUrlCallBack&sudaref=mail.sina.com.cn&display=0&retcode=2071&reason=%C7%EB%CA%B9%D3%C3%C9%A8%C2%EB%B5%C7%C2%BC&protection_url=https%3A%2F%2Fpassport.weibo.com%2Fprotection%2Findex%3Ftoken%3D2YWVg3H73AASyHdnT5GHfXjI-TXP83ZQmCnByb3RlY3Rpb24.");
</script>
</body>
</html>关于登录的包,其实也很好找(我觉得这个login提示很明显了,就不大细讲了)。
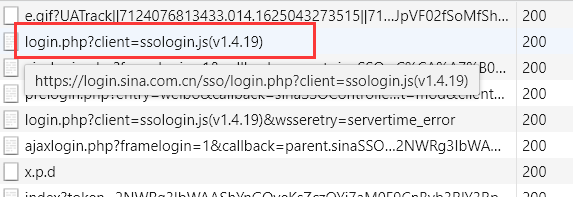
当我们点开这个包的时候呢,我们发现下面有一大串极其恶心的表单数据:

看起来却比较复杂,但是多次尝试后呢,我发现其实很多都是后台写死的,比如service、encoding、returntype啥的。这个时候我们把思维跳到第一步预登录所拿到的resp中,可以看到,其实这个里面很多的参数就是上面copy下来的,比如servertime,nonce,su,rsakv。在这个里面唯一的大头就是这个很长的sp。查看预登录的信息,我发现只剩下一个看似很重要的pubkey和pd_id没有使用了,多方查找资料以及取精华去糟粕后找到了这个sp的解决方法。
于是我们可以创建下面的一个参数表单:
def encrypt_passwd(self,passwd, pubkey, servertime, nonce):
key = rsa.PublicKey(int(pubkey, 16), int('10001', 16))
message = str(servertime) + '\t' + str(nonce) + '\n' + str(passwd)
passwd = rsa.encrypt(message.encode('utf-8'), key)
return binascii.b2a_hex(passwd)
params = {
'entry': 'weibo',
'gateway': '1',
'from': '',
'savestate': '7',
'qrcode_flag': 'false',
'useticket': '1',
'pagerefer': 'https',
'vsnf': '1',
'su': 'MTU2NzU0OTEyODQ=',
'service': 'miniblog',
'servertime': self.preDic['servertime'],
'nonce': self.preDic['nonce'], # 预登录拿到的东西
'pwencode': 'rsa2',
'rsakv': self.preDic['rsakv'],
'sp': self.encrypt_passwd(passwd, self.preDic['pubkey'], self.preDic['servertime'], self.preDic['nonce']),
'sr': '1536*864', # sp就是加密的密码
'encoding': 'UTF-8',
# 'prelt': '35',
'url': 'https://weibo.com/ajaxlogin.php?framelogin=1&callback=parent.sinaSSOController.feedBackUrlCallBack',
'returntype': 'META'
}登录成功之后就可以得到一个通行证了,这个时候我们也是来到了下面的左边界面,这个时候点击私信验证就会来到右边界面,在这个点击过程中只有一个关于微博头像包的传输,想要验证是否真的来到这个登录成功界面,可以试着去抓取这个头像包:


2.3 验证码的发送
点击图中的发送私信验证后,我们的手机上的微博就会受到一个是否确认登陆的消息。于是我们需要抓取点击发送的这个包。这个send包也很好找,我就不发图了。
老规矩,我们先看表单数据:

只有一个token标记,是不是和之前对比的十几个参数舒服多了,可是问题来了,这个token哪来的?随机字符串不成(手动滑稽)?
是的,我们做的每一步都是有意义的,我们看到上一步的那个通行证,这个里面正好有一个返回的token,为什么不拿来试一试呢? 当然,就是这个东西啦。

做好这个参数准备后,我们就可以下面的方法去发送啦。
def verify(self,token,veUrl):
# 请求验证
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, br',
"Connection": "keep-alive",
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Host': 'passport.weibo.com',
'Origin': 'https://passport.weibo.com',
'Referer': 'https://passport.weibo.com/protection/index?token={}&callback_url=https%3A%2F%2Fweibo.com'.format(token),
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36 Edg/91.0.864.59',
'X-Requested-With': 'XMLHttpRequest',
}
params = {
"token":"{}".format(token)
}
url = "https://passport.weibo.com/protection/privatemsg/send"
res = self.session.post(url = url,headers=headers,data=params)
print(res.json())
if res.json()['msg'] == "succ":
print("请验证")
self.verifyTickets(token)
print("="*30)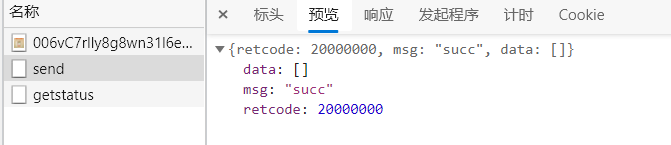
这里我们可以用返回的这个json里面的msg去检查是否发送成功,然后我们到手机里面点击确认登录,我们就可以正常登录的微博啦。
但是!问题来了,如何用代码去实现呢?
2.4 验证登录
当我们登录成功的时候,我们会抓取到这个样子的一些包
这些包才是重点。

我们一个个分析。
=========================================================================
看请求参数其实会很恶心的,因为很多参数都出现的很奇怪。因此,我们执果索因,先看最后那个包(红色),我们会看到下面的样子:

这不正式登录成功的账号反馈信息吗,然后,我们看看这个包的请求参数。

总共六个,多次测试后,后面四个都是写死的,只有1、2是需要动的,但是并不知道这是什么。
问题不大,我们继续往上看(绿色包)。

好的,通信证!说明而且有正在登录的信息,我们姑且可以判断这就是最后的登录了,然后我们仔细看这个里面的参数:
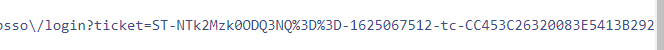

相信看到了吧,这个里面藏着红色包的参数。不仔细还真难找!
然后我们看这个绿色包的请求参数:

ok 除了action entry 写死,其他的都是变得,当然仔细一点可以发现,其实login_time就藏在这个r里面。(仔细看,总能发现)
没有什么思路,我们继续向上找那个黄色的包。

并没有返回值,只有一大串的查询字符串参数,多次实验后,其实也就这个alt在动。然后我们不难发现,其实绿色包的r就是这个黄色包的url(仔细看就知道)。
基本上算是破案了,整个登录就差这个alt。
有个基本的思想:凡是数据包,绝大多数都能被抓包工具抓住,因此我们继续往上看,在send和这个黄色包之间有一串的getstatus,获取状态!
什么状态?登录状态呗,于是我们抽取了最后一个包和前面的一个包进行分析。

很显然,这个就是等待用户在手机上点击确认登录那个按钮发送的查询包,ok我们看最后一个:

空的!!!!!!!!!!!!!!
我当时就懵了,由于对于爬虫只是amateur,所以有点难搞!
想了很久之后,我决定换抓包,使用fillder抓包而不是浏览器自带的。
发送验证后,fillder抓取如下包,这次只看最后一个。


好的,成功破案!果然是浏览器漏了一个!在这里有alt信息了,爬虫的逻辑分析基本到此结束了!
我们只需要对于这个getstatus包进行死循环发送,直到抓取到状态为“验证成功”停止,继续下面步骤即可。
代码比较长,我就不贴了,先发一个运行结果。
预登录拿到第一个通行证

验证拿到第二个通行

第三个通行证

成功登录
















 5717
5717











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









