







138. 复制带随机指针的链表
题意:
给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点。
构造这个链表的 深拷贝。 深拷贝应该正好由 n 个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的 next 指针和 random 指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点 。
例如,如果原链表中有 X 和 Y 两个节点,其中 X.random --> Y 。那么在复制链表中对应的两个节点 x 和 y ,同样有 x.random --> y 。
返回复制链表的头节点。
用一个由 n 个节点组成的链表来表示输入/输出中的链表。每个节点用一个 [val, random_index] 表示:
val:一个表示 Node.val 的整数。
random_index:随机指针指向的节点索引(范围从 0 到 n-1);如果不指向任何节点,则为 null 。
你的代码 只 接受原链表的头节点 head 作为传入参数。
示例 1:
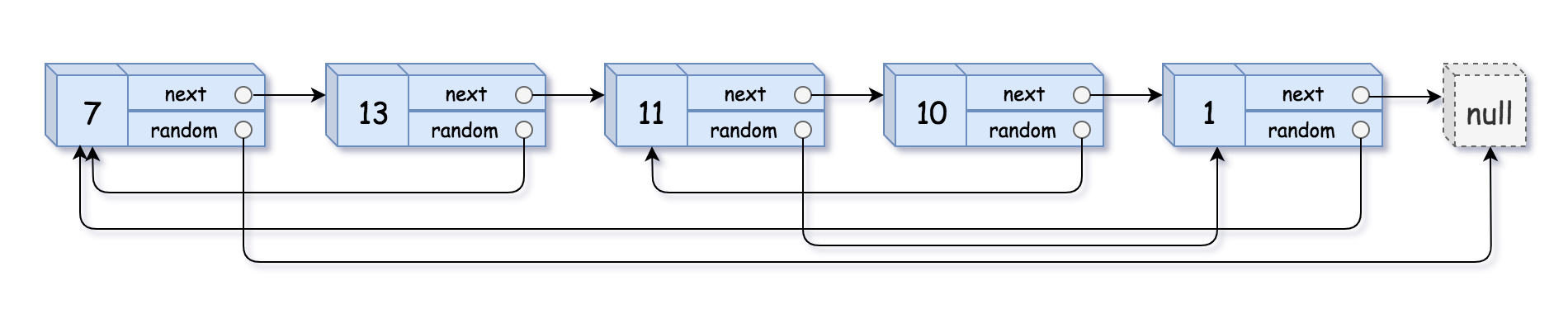
输入:head = [[7,null],[13,0],[11,4],[10,2],[1,0]]
输出:[[7,null],[13,0],[11,4],[10,2],[1,0]]
示例 2:

输入:head = [[1,1],[2,1]]
输出:[[1,1],[2,1]]
示例 3:

输入:head = [[3,null],[3,0],[3,null]]
输出:[[3,null],[3,0],[3,null]]
示例 4:
输入:head = []
输出:[]
解释:给定的链表为空(空指针),因此返回 null。
解题思路:
用简单的解法,我做了两种
第一种:
创建一个哈希表,用来记录新创建的链表的节点和老节点的对应关系.
遍历链表,先不管random指针.把所有节点全部备份一份,然后用哈希表一一对应.
重新遍历链表,这时候的节点已经全部创建完毕,只需要把random指针的连接完成即可.
第二种:
- 创建一个哈希表,用来记录新创建的链表的节点和老节点的对应关系.
- 遍历链表,然后先创建next的节点,让next连接.然后如果有random节点,需要再创建一个random节点连接.所有创建过的节点都要压入哈希表.避免重复创建.
代码:
第一种
class Solution {
public:
Node* copyRandomList(Node* head) {
if(!head)
return nullptr;
unordered_map<Node *, Node *> hash;
Node *p = head;
Node *s_head = new Node(p->val);
hash[p] = s_head;
Node *s = s_head;
p = p->next;
while (p != nullptr)
{
Node *newNode = new Node(p->val);
newNode->next = nullptr;
hash[p] = newNode;
s->next = newNode;
s = s->next;
p = p->next;
}
p = head;
s = s_head;
while (p != nullptr)
{
s->random = hash[p->random];
s = s->next;
p = p->next;
}
return s_head;
}
};
运行结果:

第二种:
class Solution {
public:
Node* copyRandomList(Node* head) {
if (!head)
return nullptr;
unordered_map<Node *, Node *> hash;
Node *p = head;
Node *s_head = new Node(p->val);
Node *s = s_head;
hash[p] = s_head;
p = p->next;
while (p != nullptr)
{
//插入下一个节点
if (hash.find(p) != hash.end()) //如果节点已经创建
{
s->next = hash[p];
}
else
{
Node *newNode = new Node(p->val);
hash[p] = newNode;
s->next = newNode;
}
//插入随机节点
if (hash.find(p->random) != hash.end())
{
s->next->random = hash[p->random];
}
else
{
if (p->random != nullptr)
{
Node *newranNode = new Node(p->random->val);
hash[p->random] = newranNode;
s->next->random = newranNode;
}
else
{
s->next->random = nullptr;
}
}
s = s->next;
p = p->next;
}
s = s_head;
s_head->random = hash[head->random];
return s_head;
}
};
~~~#### 总结:
t;
}
s = s_head;
s_head->random = hash[head->random];
return s_head;
}
};
运行结果:

总结:
两种的时间复杂度应该是差不多的,只是分开和不分开的关系.分开逻辑上清晰点.
















 628
628











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











