







一、shell脚本简介(输入与输出、调试、结果处理)
输入与输出
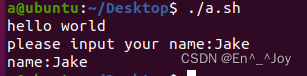
shell脚本类似于Windows下的批处理文件,是将连续执行的命令写成一个文件的形式,shell脚本提供数组、循环、条件判断功能。shell脚本的后缀名为.sh,该脚本需要修改权限为可执行文件chmod 777 a.sh,第一行的内容为#!/bin/bash时表示使用bash,除此之外还有cshell等(#!/bin/csh)其他类型。shell脚本的输出语句是echo,如指令echo "hello"会输出hello,输入语句是read,如执行指令read name时需要你输入,输入的内容给name变量赋值,如果需要在输入的时候需要添加一些提示语句,可以使用-p参数,如read -p "请输入你的姓名:" name,实例代码如下:
#!/bin/bash
echo "hello world"
read -p "please input your name:" name
echo "name:"$name
输出结果如图所示:
输出的格式也可以自行组装,比如一个echo输出多个变量的值
#!/bin/bash
a=1
b=2
echo "a = ${a} b = ${b}" # a = 1 b = 2
当一次性需要输出多行的时候,可以使用如下语句,该语句一般结合read和case使用
#!/bin/bash
cat <<EOF
f.磁盘管理工具
d.系统挂载工具
m.内存管理工具
q.退出
EOF
read -p "请输入要操作类型:" action
# 下面接着case语句,对输入的action分别进行操作
脚本运行方式
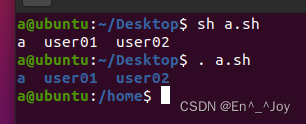
执行shell脚本的方式有如下几种:bash a.sh,sh a.sh,. a.sh,source a.sh。区别在于前两个属于子shell,后两个属于本shell,子shell和本shell的区别是在调用的脚本中如果包含cd /home时,属于子shell的当前终端不会进入该目录,而本shell的会进入,如果有输出内容,则都会有对应的输出。bash和sh是同一个东西,sh是bash的软连接得到
#!/bin/bash
cd /home
ls
子shell和本shell执行效果如下:
一行多条指令
当一行包含多条指令时,可以使用;分隔,也可以使用&&和||,比如cmd1 && cmd2表示当cmd1执行完且正确,接着执行cmd2,否则不执行;cmd1 || cmd2表示当cmd1执行完且正确,则不执行cmd2,否则执行,用三条语句可以组成判断输出格式,如cmd1 && echo "1" || echo "2",如果cmd1执行正确,则输出前者,否则输出后者
比如下面这个例子,使用if判断格式如下
#!/bin/bash
if [ -d /home/test ] # 中括号与数字直接一定要使用空格隔开
then
echo "/home/test exist"
else
echo "/home/test not exist"
fi
使用test格式如下
#!/bin/bash
test -d /home/test && echo "/home/test exist" || echo "/home/test not exist"
脚本调试
脚本写完后,可以使用指令调试脚本:如sh -n a.sh 仅调试脚本中的语法错误,sh -vx a.sh 以调试的方式执行,查询整个执行过程
结果处理
不需要结果或导将运行结果导出为文件格式
#!/bin/bash
> a.txt # 清空文件内容
ls > a.txt # 清空文件内容(原文件存在则替换,不存在则创建),不需要输出在终端 (结果包含a.txt)
ls &> a.txt # 输出到文件中(原文件存在则替换,不存在则创建),不需要输出在终端 (结果包含a.txt)
ls >> a.txt # 输出在文件中(原文件存在则叠加,不存在则创建),不需要输出在终端 (结果包含a.txt)
ls | tee -a a.txt # 输出到文件中(原文件存在则替换,不存在则创建),并且在终端输出 (结果不包含a.txt)
ls &> /dev/null # 不需要输出结果,结果直接丢到垃圾桶
二、引号的区别(" ’ ` $())
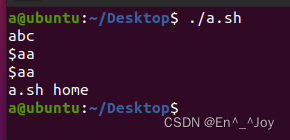
""为弱引用,在引用变量的时候可以使用该引用。''为强引用,在该引号里面的所有特殊符号都失去其本身意义,比如该脚本当中的一些特殊符号$等。左上角(Tab键上方)的`和$()为优先执行,一些指令的结果可以作为一些指令的参数的时候可以使用
#!/bin/bash
aa="abc"
echo "$aa"
echo '$aa'
b='$aa'
echo $b
echo `ls`
运行结果如下:
三、变量
3.1 自定义变量与环境变量
自定义变量
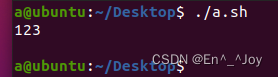
变量名和值由用户自己定义,定义变量时,值不能用空格,空格作为分隔符,当使用空格时,需要使用引号,使用unset指令可以删除变量,如unset a。set指令可以查看所有变量内容,结合grep可以将获得的内容进行过滤,如set | grep aa 在所有变量中过滤出aa
#!/bin/bash
a=123
echo $a
unset a
echo $a
执行输出结果如下:
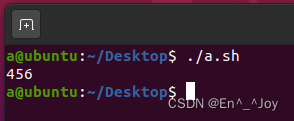
重复定义变量
多次对一个变量进行定义的时候,最后一次定义的变量会覆盖之前定义的变量,比如如下代码:
#!/bin/bash
a=123
a=456
echo $a
输出结果如图所示:
环境变量
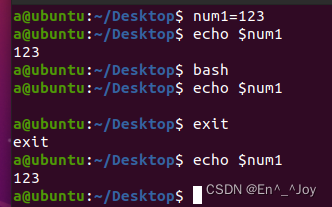
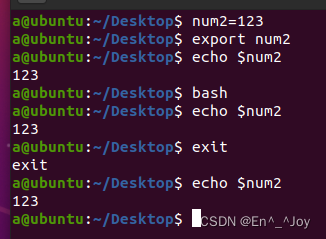
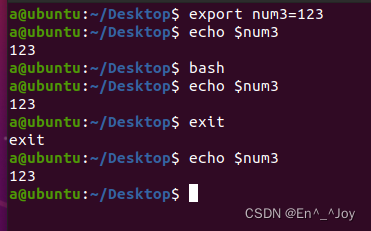
不用任何声明,直接定义的变量为自定义变量,该变量只能在当前shell中生效,在子shell和兄弟shell中都不生效,如下面的变量num1,使用export声明的变量为环境变量,使用时候会被继承下去,该变量在当前和子shell中都生效,但是在兄弟shell中不生效,如下面的变量num3,一个变量初始化时没声明的时候,后面使用export声明(不需要等号赋值),则该变量也变成了环境变量,如下面的变量2;如果想要使变量在当前用户登入后一直生效(当前用户的子shell和兄弟shell都生效,其他用户不生效),可以写在root/.bash_profile中(登入自启动),vim /root/.bash_profile,环境变量写在这里,开机即声明,这里面是每次开机都会执行的命令;想要变量在所有用户登入后一直生效,可以将变量放在/etc/profile中(开机自启动)。
如下指令在终端输入
实例一:
实例二:
实例三:
注:bash进入子shell,exit退回到原来的shell
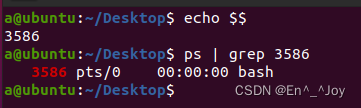
pstree展示进程之间的父子关系,echo $$可以输出当前shell的id,ps | grep 19712可以查到的PID
3.2 位置变量与预定义变量
位置变量
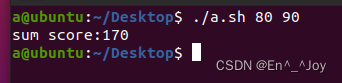
命令格式为:命令 参数1 参数2 参数3...,也就是$0 $1 $2 $3 ...。比如之前运算总分的脚本,修改成求平均值然后使用位置变量之后,可以将两行read省略,使用$1和$2表示,a.sh代码如下:
#!/bin/bash
#read -p "输入第一门成绩:" number1
#read -p "输入第二门成绩:" number2
echo -n "sum score:"
expr $1 + $2
运行结果如图:
预定义变量
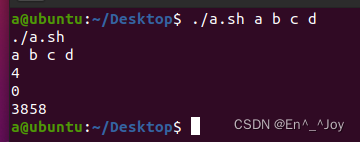
就是被系统预定义好的变量,如下面这个例子,a.sh代码如下:
#!/bin/bash
echo $0 #输出程序名
echo $* #输出所有参数
echo $# #输出参数个数
echo $? #输出为bool值,为0是表示上一条指令执行成功,非0则表示失败
echo $$ #输出进程的PID
运行结果如下:
3.3 变量运算(数学运算与字符串相加、字符串索引)
整数运算
shell编程中可以进行数学中的加减乘除运算,进行整数运算的方法有如下几种:expr,$(()),$[],let,运算符中的加减乘除符号分别如下:加+,减-,乘\* (*是任意字符,需要使用\转义),除\,取余%,let还可以对变量进行i++操作
#!/bin/bash
expr 1 + 2 # 3
num1=2
num2=3
expr $num1 + $num2 # 5
echo $(($num1+$num2)) # 5
echo $((5-2*3)) # -1
echo $((2**3)) # 8
echo $[5-2] # 3
let sum=2+3
echo $sum # 5
let sum++
echo $sum # 6
小数运算
处理进行上面的整数运行,还可以进行小数运算,小数运行需要使用到工具bc,如果没有,需要使用指令安装:yun install -y bc。终端使用bc,会进入一个新的系统,在这输入运算,会有对应结果输出
#!/bin/bash
echo "2*4" | bc # 8
echo "2^4" | bc #16
echo "scale=2;10/3" | bc #scale表示保存的小数位数 # 3.33
字符串相加
如果需要实现不被替代,实现叠加效果,可以使用"$"或者${}的形式实现,代码如下:
#!/bin/bash
a=12
echo $a # 12
a="$a"34
echo $a # 1234
a=${a}56
echo $a # 123456
也可以自行组装输出字符串格式,其中可包含多个变量值,比如一个echo输出多个变量的值
#!/bin/bash
a=1
b=2
echo "a = ${a} b = ${b}" # a = 1 b = 2
字符串索引
#!/bin/bash
name=helloworld
echo ${name:3:3} # 第一个3表示从哪里开始,第二个3表示多长
echo ${name:3} # 第一个3表示从哪里开始,直到末尾
echo ${#name} # 输出字符长度
四、判断
4.1 条件测试(数值比较、文件测试、字符串比较、多条件测试)
注意事项:测试中的符号[和]前后需要使用空格隔开,if和then要么写在同一行使用;隔开,要么写在两行,字符串比较当中,=和!=符号前后都要用空格分开
数值比较
| 操作符 | 含义 |
|---|---|
| -gt | 大于 |
| -lt | 小于 |
| -eq | 等于 |
| -ne | 不等于 |
| -ge | 大于等于 |
| -le | 小于等于 |
举例
#!/bin/bash
num1=10
num2=15
if [ $num1 -gt $num2 ] # 中括号与数字直接一定要使用空格隔开
then
echo "num1>num2"
else
echo "num1<num2"
fi
功能同上
#!/bin/bash
num1=10
num2=15
test $num1 -gt $num2 && echo "num1>num2" || echo "num1<num2"
文件测试
| 操作符 | 含义 |
|---|---|
| -f | 是否存在 |
| -b | 是否为块文件 |
| -d | 是否文文件夹 |
| -h | 链接文件 |
| -c | 字符文件 |
| -e | 文件或文件夹 |
| -g | 文件或文件夹设置了SGID位(chmod g+s filename)(r - - r - S r - - ) |
| -k | 文件或文件夹设置了“粘滞”位(chmod o+t filename)(r - - r - - r - T ) |
| -p | 存在且为命名管道 |
| -r | 存在且可读 |
| -s | 存在且大小大于0 |
| -S | 存在且为socket |
| -t | 与终端设备相关联的文件描述符 |
| -w | 存在且可写 |
| -x | 存在且可执行 |
| -O | 存在且属于当前进程的用户 |
| -G | 存在且属于当前进程的用户所处的用户组 |
举例
#!/bin/bash
if [ -d /home/test ] # 中括号与数字直接一定要使用空格隔开
then
echo "/home/test exist"
else
echo "/home/test not exist"
fi
功能同上
#!/bin/bash
test -d /home/test && echo "/home/test exist" || echo "/home/test not exist"
字符串比较
| 操作符 | 含义 |
|---|---|
| = | 相等(或==) |
| != | 不等于 |
| -z | 判断字符长度为0(也可用来检测变量是否定义) |
| -n | 判断字符长度不为0(也可用来检测变量是否定义) |
| ${#str} | 判断str字符长度 |
#!/bin/bash
read -p "是否创建文件夹[yes/no]" select
if [ "$select" = "yes" ] # 中括号与数字直接一定要使用空格隔开,等号之间要使用空格隔开
then
mkdir /home/test
fi
功能同上
#!/bin/bash
read -p "是否创建文件夹[yes/no]" select
test "$select" = "yes" && mkdir /home/test
多条件测试
| 操作符 | 含义 |
|---|---|
| -gt | 大于 |
| -lt | 小于 |
| -eq | 等于 |
| -ne | 不等于 |
| -ge | 大于等于 |
| -le | 小于等于 |
#!/bin/bash
[ xxx -a xxx ] # 并运算,相当于&&
[ xxx -o xxx ] # 或运算,相当于||
[[ xxx && xxx ]]
[[ xxx || xxx ]]
[ xxx ] && [ xxx ]
# xxx相当于一个条件,如 [ 90 -gt 80 ] 、再如[ -d file_path ] 都可以用于if的条件判断
[ $score -gt 60 -a $score -lt 90 ]
[[ $score -gt 60 && $score -lt 90 ]]
[ $score -gt 60 ] && [ $score -lt 90 ]
4.2 if判断
单分支结构
#!/bin/bash
num1=10
num2=15
if [ $num1 -gt $num2 ] # 中括号与数字直接一定要使用空格隔开
then
echo "num1>num2"
fi
双分支结构
#!/bin/bash
num1=10
num2=15
if [ $num1 -gt $num2 ] # 中括号与数字直接一定要使用空格隔开
then
echo "num1>num2"
else
echo "num1<num2"
fi
多分支结构
#!/bin/bash
read -p "是否创建文件夹[yes/no]" select
if [ "$select" = "yes" ] # 中括号与数字直接一定要使用空格隔开,等号之间要使用空格隔开
then
mkdir /home/test
elif [ "$select" = "no" ]
then
echo "not create"
else
echo "error"
fi
嵌套结构
单分支结构
#!/bin/bash
num1=70
if [ $num1 -gt 60 ] # 中括号与数字直接一定要使用空格隔开
then
if [ $num1 -gt 90 ]
then
echo "num1>90"
else
echo "60<num1<=90"
fi
else
echo "num1<=60"
fi
4.3 case匹配
当action输入的为yes/YES/Y/y都会进入第一个,输出yes
当action输入的为no/NO/N/n都会进入第二个,输出no
当action输入其他,会进入最后一个输出error
#!/bin/bash
read action
case $action in
yes|YES|Y|y)
echo "yes"
;;
no|NO|N|n)
echo "no"
;;
*)
echo "error"
;;
esac
五、循环
5.1 for循环(支持线程、读文件、变量、位置变量)
输出1到10,使用sleep延时总共需要10秒
#!/bin/bash
for i in {1..10} # 或 $(seq 1 10) 或 `seq 10`
do
echo $i
sleep 1
done
#!/bin/bash
for((i=1; i<=3;i=i+1))
do
echo "$i"
sleep 1
done
使用线程形式,总共只需要一秒即可
#!/bin/bash
for i in {1..10} # 或 $(seq 1 10) 或 `seq 10`
do
{
echo $i
sleep 1
}&
done
wait # 等待上面所有结束
echo "end"
以读文件的形式
#!/bin/bash
for i in `cat a.txt` # 空格和换行分隔
do
echo $i
sleep 1s
done
以位置变量的格式
#!/bin/bash
for i in `cat $1` # 位置变量传入文件名 空格和换行分隔
do
echo $i
sleep 1s
done
#!/bin/bash
for i in $1 $2 $3
do
echo $i
sleep 1s
done
以变量的格式
#!/bin/bash
a="aa bb cc"
for i in $a
do
echo "$i"
sleep 1
done
效果同上
#!/bin/bash
for i in aa bb cc
do
echo "$i"
sleep 1
done
5.2 while循环以及与for循环读取文件区别
while循环
#!/bin/bash
i=0
while : # :前要有空格
do
if [ $i -eq 10 ]
then
exit 1
fi
let i++
sleep 1
echo $i
done
#!/bin/bash
i=1
while [ $i -ne 10 ]
do
echo "$i"
let i++
sleep 1
done
while读取文件
while循环读取文件是以分行符做分隔
#!/bin/bash
while read line # read后可以加-p提示语句
do
echo $line
done < a.txt # 读取a.txt文件
for循环读取文件与while循环的区别是这里空格也是分隔符
#!/bin/bash
for i in `cat a.txt`
do
echo $i
done
此处的while循环是按行分隔,for循环是按空格和行分隔,for循环也可以设置为按行读取,在for循环之前加入IFS=$'\n',分隔符改成了换行,为了不影响这后面的内容,在此处的for循环用完之后,在将IFS回复原样,这里使用一个变量保存IFS原来的值,代码如下
#!/bin/bash
# 读取hosts文件内容,写入变量
OLD_IFS=$IFS
IFS=$'\n'
for i in `cat a.txt`
do
echo $i
done
IFS=$OLD_IFD
# 下面如果还有for循环,将不受影响,恢复原来的以空格分隔
5.3 until循环及expect(免交互)
until循环
#!/bin/bash
until [[ $i -eq 10 ]]
do
let i++
sleep 1
echo $i
done
yum install -y expect.x86_64 tcl tcl-devel
a.sh
#!/bin/bash
read -p "yes/no" action
read filename
if [ $action = "yes" ]
then
read filename
touch a.txt
fi
b.sh
#!/bin/bash
/usr/bin/expect <<-EOF
set timeout 10 # 设置超时时间,答复之后那边没回复超过事件则结束
spawn a.sh
expect {
"yes/no" { send "yes\r" } # \r回车
"file name:" { send "a.txt\r";exp_continue } # exp_continue表示如果没出现可忽略这句话
}
expect eof # expect eof表示不保留会话, interact 表示保留会话,停留在此处
EOF
六、数组与函数
6.1 数组(直接定义、读文件、其他指令定义、变量定义、索引定义)
变量是用一个固定的字符串,代替一个不固定字符串,数组是用一个固定的字符串,代替多个不固定字符串。数组分为普通数组和关联数组,普通数组只能使用整数作为数组索引,关联数组可以使用字符串作为数组索引
变量索引
#!/bin/bash
name=helloworld
echo ${name:3:3} # 第一个3表示从哪里开始,第二个3表示多长
echo ${name:3} # 第一个3表示从哪里开始,直到末尾
echo ${#name} # 输出字符长度
数组定义
可以直接给定所需要定义的元素,也可以以其他指令的格式给定元素,比如使用cat读取某个文件,使用ls指令,也可以使用变量的格式定义,在元素前面使用[index]=可以指定该元素的索引,指定位置,除此之外还可以单独一个一个的定义
#!/bin/bash
username=(tom jack alice)
username=(tom jack alice "bash shell") # 引号是把空格忽略,充当一个(输出所有有空格可能看不出来,需要单独输出方便查看)
username=(`cat a.txt`) # 读取文件定义数组,按空格分隔
username=(`ls /home`) # 输出定义数组
username=($tom $jack $alice) # 变量定义数组
username=(tom jack alice "bash shell" [10]=hello) # 前面的为按顺序定义,[10]表示hello为第十个位子,后面还有则是第十一个(单独输出方便查看)
# 单独一个一个定义
username[0]=tom
username[1]=jack
username[2]=alice
访问数组
#!/bin/bash
echo ${username} # 输出数组第一个
echo ${username[*]} # 输出数组所有内容
echo ${username[0]} # 访问第一个元素
echo ${username[@]} # 访问数组中所有内容,等同于[*]
echo ${#username[*]} # 统计数组元素个数
echo ${!username[@]} # 获取数组元素索引
echo ${username[*]:1} # 从数组下标1开始
echo ${username[*]:1:2} # 从数组下标1开始,访问两个元素
declare -a # 查看系统中所有的数组
declare -a | grep username # 使用管道过滤除想要的变量
关联数组定义
#!/bin/bash
declare -A username # 使用前一定要先声明
username[use1]=tom
username[use2]=jack
username=([use1]=tom [use2]=jack [use3]="bash shell")
关联数组的访问方式和上面的差不多,结果中不具有顺序特性
#!/bin/bash
echo ${username[*]} # 查看所有
echo ${username[*]:0} # 按统计个数顺序显示,而不是按索引顺序
实例
通过while循环读取文件进行数组定义,通过while循环的格式读取过来的格式是以分行符做分隔
#!/bin/bash
while read line # read后可以加-p提示语句
do
username[++i]=$line
done < a.txt # 读取a.txt文件
echo ${username[*]}
for i in ${!username[*]}
do
echo "$i : ${username[$i]}"
done
通过for循环读取文件进行数组定义,和while循环的区别是这里空格也是分隔符
#!/bin/bash
for i in `cat a.txt`
do
username[++o]=$i
done
for i in ${!username[*]}
do
echo "$i : ${username[$i]}"
done
此处的while循环是按行分隔,for循环是按空格和行分隔,for循环也可以设置为按行读取,在for循环之前加入IFS=$'\n',分隔符改成了换行,为了不影响这后面的内容,在此处的for循环用完之后,在将IFS回复原样,这里使用一个变量保存IFS原来的值,代码如下
#!/bin/bash
# 读取hosts文件内容,写入变量
OLD_IFS=$IFS
IFS=$'\n'
for i in `cat a.txt`
do
username[++o]=$i
done
for i in ${!username[*]}
do
echo "$i : ${username[$i]}
done
IFS=$OLD_IFD
# 下面如果还有for循环,将不受影响
6.2 函数
#!/bin/bash
func1 () { # 或 function func1 { 或function func1 () {
echo "hello world"
}
func1
传参格式
#!/bin/bash
func2 () { # 或 function func1 { 或function func1 () {
echo "hello $1"
}
func2 world # 传参,world为参数
七、流编辑器(文本内容处理)
7.1 正则表达式
正则表达式是一种字符模式,用于在查找过程中匹配特定的字符。正则表达式一般置于两个正斜杠之间(如/l[oO]ve/),他将匹配被查找的行中任何位置出现的相同模式。正则表达式一般用于vim、sed、awk、grep中,也可以使用在输入当中,比如下面这个例子,如果输入的是数字,则输出success并退出,否则不退出,这里if判断当中使用正则时需要使用=~
#!/bin/bash
while :
do
read -p "请输入数字才能退出:" num
if [[ $num =~ ^[0-9]+$ ]] # 匹配只能是数字,涉及到正则需要使用 =~
then
echo "success"
exit 0
else
echo "fail"
fi
done
元字符表达的是不同于字面本身含义的字符,一般都是多个搭配使用
| 模式 | 描述 |
|---|---|
| ^ | 开头定位符(行首) |
| $ | 结尾定位符 (行尾) |
| <abc | 以abc开头的词(词首) |
| >abc | 以abc结尾的词(词尾) |
| . | 匹配单个任意字符,除了换行符 |
| * | 匹配0个或多个表达式(等价于+和?总的) |
| + | 匹配1个或多个表达式 |
| ? | 匹配0个或1个前面的正则表达式定义的字段,非贪婪方式 |
| […] | 用来表示一组字符,单独列出,比如[amk]匹配a, m或k的单个字符 |
| [a-z0-9] | 匹配a到z或0~9 |
| [^…] | 不在[]内的字符,比如[^abc] 匹配除了a,b,c之外的单个字符 |
| \ | 转义符(''或""同样意义,前者所有) |
| {n} | 精确匹配n个前面的表达式 |
| {n,m} | 匹配n到m次由前面正则表达式定义的片段,贪婪方式 |
| a|b | 匹配a或b |
| () | 稍后可能使用的字符 |
| \w | 匹配字母、数字、下划线 |
| \W | 匹配不是字母、数字、下划线的字符 |
| \s | 匹配任意空白字符、等价于[\t\n\r\f] |
| \S | 匹配任意非空字符 |
| \d | 匹配任意数字,等价于[0–9] |
| \D | 匹配任意非数字的字符 |
| \A | 匹配字符串开头 |
| \Z | 匹配字符串结尾,如果存在换行,只匹配到换行前的结束字符串 |
| \z | 匹配字符串结尾,如果存在换行,同时还会匹配换行符 |
| \G | 匹配最后匹配完成的位置 |
| \n | 匹配一个换行符 |
| \t | 匹配一个制表符 |
#!/bin/bash
grep ^root a.txt # root开头的行
grep love$ a.txt # love结尾的行
grep "\<abc" a.txt # abc开头的词
grep "abc\>" a.txt # abc结尾的词
grep "a.c" a.txt # axc 其中x为任意字符
grep "a\.c" a.txt # a.c 需要用\转义
grep "abc*" a.txt # abx 其中x表示0到多个c
grep "abc.*" a.txt # abc开头,后面为任意个任意字符,也可没有
grep "a[bB]c" a.txt # axc 其中x为[]里的b或B
grep "a[^bB]c" a.txt # axc 其中X为除了b或B之外的任意值,上面的取反
grep "a[0-9a-z]c" a.txt # axc 其中x为0-9或a-z之间任意数
egrep "o\{3\}" a.txt # 重复3次的o
egrep "o\{3,\}" a.txt # 重复3次及以上的o
egrep "o\{3,4\}" a.txt # 重复3次4次的o
egrep lo+ve a.txt # lxve 其中x为一个或多个o,不能为0个
egrep lo?ve a.txt # lxve 其中x为一个o或没有 (+和?相当于把*拆开了)
egrep "lo(ve|VE)" a.txt # 匹配love或loVE
sed -r 's/root/&abc/' a.txt # root替换为rootabc,&表示前面匹配到的
sed -r 's/(root)/\1abc/' a.txt # root替换为rootabc,&表示前面匹配到的
# vim 编辑器中可以使用如下替换
:% s/\(abc\)/dd\1/ # 替换功能,后面的\1表示使用前面的abc,()前后需要使用\去掉括号含义
7.2 grep(按行查找)
grep主要用于过滤文件中的内容,grep分为grep、egrep、fgrep,其中grep最为常用支持常规正则,一些扩展的正则需要使用egrep(grep不支持的正则),fgrep不支持正则。grep返回值为0表示找到了,1表示没找到,2表示找的位置不对,grep的一些参数如下
| 参数 | 含义 |
|---|---|
| grep -q | 不输出结果 |
| grep -v | 取反,比如查看出某些之外的内容 |
| grep -R | 可以查目录下所有内容 |
| grep -o | 只查找这个关键字 |
| grep -B2 | 查找查找内容的前两行 |
| grep -A2 | 查找查找内容的后两行 |
| grep -C2 | 查找查找内容的上下两行 |
| egrep -l | 只要文件名(L的小写) |
| egrep -n | 带行号 |
#!/bin/bash
grep abc /home # 报错,不能对目录查找,要对文件查找,对文件需要加-R,如下
grep -R abc /home
grep -o love a.txt # 只显示love
grep -B2 love a.txt # 查看love的前两行
grep -n love a.txt # 查看love,并带上行号
7.3 sed(行操作、替换、插入、删除等)
sed是一种在线的、非交互的编辑器,它一次处理一行内容。处理是把行存储在临时缓冲区中,接着用sed命令处理缓冲区中的内容,处理完接着处理下一行,直到文件末尾。文件内容并没有改变,除非使用重定向存储输出到原文件。sed主要用来自动编辑一个或多个文件,简单对文件的反复操作。grep中可以使用正则匹配文本
格式:sed 选项 命令 文件、sed 选项 -f 脚本 文件
| 参数 | 含义 |
|---|---|
| d | 删除 |
| s | 替换 |
| r | 读 |
| w | 写 |
| a | 追加(之后) |
| i | 插入(之前) |
| c | 替换整行 |
| n | 获取下一行 |
| ! | 反向选择 |
| e | 多重编辑 |
| g | 一行全局 |
sed -i 为修改之后会写回原文件中,sed -r则不会,可以指定生成一个新文件,如果一次有多条执行,可以使用多个-e参数或者使用;分隔
#!/bin/bash
# 是否修改原文件
sed -r '/root/d' a.txt >> b.txt # 将a.txt中包含root的行删除,生成为b文件
sed -i '/root/d' a.txt # 将a.txt中包含root的行删除并写回a.txt文件
# 删除
sed -r '/root/d' a.txt # 删除包含root的行
sed -r '3{d}' a.txt # 删除第三行
sed -r '3d' a.txt # 同上
sed -r '3,10d' a.txt # 删除三行及后面所有行 或者 '3,$d'
sed -r '$d' a.txt # 删除最后一行
# 替换 ''中的///可替换为###
sed -r 's/root/abc/' a.txt # root替换为abc,每一行第一个
sed -r 's#root#abc#' a.txt # 同上
sed -r 's/root/abc/g' a.txt # root替换为abc,每一行所有的(包含一行有多个)
sed -r 's/^root/abc/' a.txt # root替换为abc,其中root开头的行
sed -r 's/root/&abc/' a.txt # root替换为rootabc,&表示前面匹配到的
sed -r 's/(root)/\1abc/' a.txt # 同上
# 读文件插入
sed -r '$r b.txt' a.txt # 将b.txt的内容插入到a.txt的最后一行,$表示最后
sed -r 'r b.txt' a.txt # 将b.txt的内容插入到a.txt的每一行下面
sed -r '/root/r b.txt' a.txt # 将b.txt的内容插入到所有包含root行的下面
sed -r '/^root/r b.txt' a.txt # 将b.txt的内容插入到所有包含root且root开头的行的下面
# 保存结果 也可以使用 >> 生成文件
sed -r 'w b.txt' a.txt # 将a.txt内容保存为b.txt
sed -r '/root/w b.txt' a.txt # 将a.txt内容中带root的行保存为b.txt
sed -r '1,5w b.txt' a.txt # 将a.txt内容中1到5行保存为b.txt
# 上方插入
sed -r '/^root/a abc' a.txt # 在root开头的行的下面插入abc
sed -r '1a abc' a.txt # 在第1行下面插入abc
sed -r '1a abc\
def\
gh' a.txt # 在第1行下面插入3行分别为abc def gh
sed -r '2i abc' a.txt # 在第2行上面插入abc
sed -r '2c abc' a.txt # 第2行替换为abc
sed -r '/root/{n;d}' a.txt # 删除root的下一行
sed -r '5,$!d' a.txt # 删除5到最后一行之外的其他行,即删除1-4行
# 多语句
sed -r -e '1,3d' -e '4s/aaa/bbb/' a.txt # 删除1-3行,且第4行的aaa换成bbb
sed -r '1,3d;4s/aaa/bbb/' a.txt # 同上
sed -r "1a$var1" a.txt # 使用变量,要用""
sed -r "\$a$var1" a.txt # 使用变量,要用""
7.4 awk(按列分隔获取结果)
awk是一种编程语言,用于linux下对文本和数据处理,数据可以来自标准的输入、一个或多个文件、或者其他指令的输出,它支持用户自定义函数和动态正则。awx的处理的方式是逐行扫描文件,从第一行扫描到最后一行,寻找匹配的特定模式的行,并在这些行上进行你想要的操作,如果没有指定处理动作,则把匹配的行显示到标准输出终端。
之前的都是行处理,这个可以使用列处理,-F可以指定以什么为分隔符如-F:表示以:为分隔符
#!/bin/bash
awk '{print $0}' a.txt # 打印所有内容,空格为分隔符
awk -F: '{print $1}' a.txt # 打印第一列,:为分隔符 $1 表示第一列
# BEGIN{}发生在行处理前 END{}发生在行处理后
awk -F: 'BEGIN{print hello}{print $1}END{print world}' a.txt # 在输出的最前面输出hello,最后输出world
echo $line | awk '{print $2}' # 输出第二个位置信息,空格分隔 如内容为jack f,输出f
echo $line | awk -F: '{print $2}' # 输出第二个位置信息,-F指定分隔符(此处分隔符为:) 如内容为jack:f,输出f















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









