







 本文通过卷积神经网络(CNN)实现花卉图像的自动分类。实验涵盖了数据处理、模型构建及图像识别全流程,展示了如何利用TensorFlow搭建高效花卉识别系统。
本文通过卷积神经网络(CNN)实现花卉图像的自动分类。实验涵盖了数据处理、模型构建及图像识别全流程,展示了如何利用TensorFlow搭建高效花卉识别系统。
参考教材:人工智能导论(第4版) 王万良 高等教育出版社
实验环境:Python3.6 + Tensor flow 1.12
人工智能导论实验导航
实验一:斑马问题 https://blog.csdn.net/weixin_46291251/article/details/122246347
实验二:图像恢复 https://blog.csdn.net/weixin_46291251/article/details/122561220
实验三:花卉识别 https://blog.csdn.net/weixin_46291251/article/details/122561505
实验四:手写体生成 https://blog.csdn.net/weixin_46291251/article/details/122576478
实验源码: xxx
3.1实验介绍
3.1.1实验背景
深度学习为人工智能核心技术,本章主要围绕深度学习涉及的全连接神经网络、卷积神经网络和对抗神经网络而开设的实验。
卷积神经网络(Convolutional Neural Networks, CNN)是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks),是深度学习(deep learning)的代表算法之一 。卷积神经网络具有表征学习(representation learning)能力,能够按其阶层结构对输入信息进行平移不变分类(shift-invariant classification)
3.1.2实验目的
本章实验的主要目的是掌握深度学习相关基础知识点,了解深度学习相关基础知识,经典全连接神经网络、卷积神经网络和对抗神经网络。掌握不同神经网络架构的设计原理,熟悉使用Tensorflow 2.1深度学习框架实现深度学习实验的一般流程。
3.1.3实验简介
随着电子技术的迅速发展,人们使用便携数码设备(如手机、相机等)获取花卉图像越来越方便,如何自动识别花卉种类受到了广泛的关注。由于花卉所处背景的复杂性,以及花卉自身的类间相似性和类内多样性,利用传统的手工提取特征进行图像分类的方法,并不能很好地解决花卉图像分类这一问题。
本实验基于卷积神经网络实现的花卉识别实验与传统图像分类方法不同,卷积神经网络无需人工提取特征,可以根据输入图像,自动学习包含丰富语义信息的特征,得到更为全面的花卉图像特征描述,可以很好地表达图像不同类别的信息。
3.2概要设计
本实验将用户在客户端选取的花卉图像作为输入,运行花卉识别模型,实时返回识别结果作为输出结果并显示给用户。
3.2.1功能结构
花卉识别实验总体设计如下图所示,该实验可以划分为数据处理、模型构建、图像识别三个主要的子实验。
其中数据处理子实验包括数据集划分、图像预处理两个部分;
模型构建子实验主要包括模型定义、模型训练以及模型部署三个部分;
图像识别子实验内容主要包括读取花卉图像、运行推断模型进行图像特征提取,输出模型识别结果三个部分。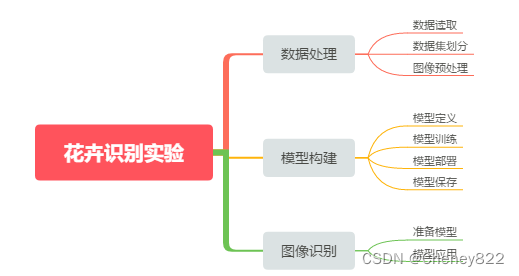
3.2.2体系结构
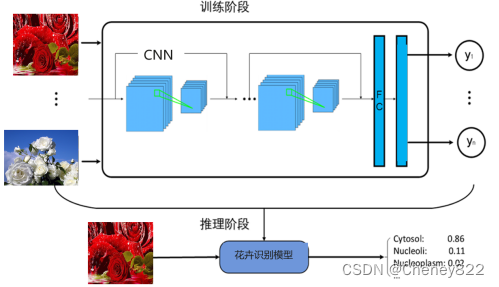
按照体系结构划分,整个实验的体系结构可以划分为三部分,分别为模型训练、模型保存和模型推理,如图5-3所示。各层侧重点各不相同。
训练层运行在安装有tensorflow框架的服务器,最好配置计算加速卡。
推断层运行于开发环境,能够支持卷积神经网络的加速。
展示层运行于客户端应用程序,能够完成图像选择并实时显示推断层的计算结果。
各层之间存在单向依赖关系。推断层需要的网络模型由训练层提供,并根据需要进行必要的格式转换或加速重构。相应的,展示层要显示的元数据需要由推断层计算得到。
3.3详细设计
3.3.1导入实验环境
步骤 1导入相应的模块
skimage包主要用于图像数据的处理,在该实验当中, io模块主要用于图像数据的读取(imread)和输出(imshow)操作,transform模块主要用于改变图像的大小(resize函数);
glob包主要用于查找符合特定规则的文件路径名,跟使用windows下的文件搜索相似;
os模块主要用于处理文件和目录,比如:获取当前目录下文件,删除制定文件,改变目录,查看文件大小等;
tensorflow是目前业界最流行的深度学习框架之一,在图像,语音,文本,目标检测等领域都有深入的应用,也是该实验的核心,主要用于定义占位符,定义变量,创建卷积神经网络模型;numpy是一个基于python的科学计算包,在该实验中主要用来处理数值运算;
time模块主要用于处理时间系列的数据,在该实验主要用于返回当前时间戳,计算脚本每个epoch运行所需要的时间。
# 导入模块
# -*- coding:uft-8
#from skimage
import glob
import os
import cv2
import tensorflow as tf
from tensorflow.keras import layers, optimizers, datasets, Sequential
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
步骤 2设置初始化环境
# 数据集的地址,改为自己的图片文件地址
path = './flower_photos/'
# 缩放图片大小为100*100,C为通道,彩色图片数值为3
w = 100
h = 100
c = 3
types = 0 # 所有花的种类数,也是标签的个数
flower = {
0: 'bee', 1: 'blackberry', 2: 'blanket', 3: 'bougainvillea', 4: 'bromelia', 5: 'foxglove'}
3.3.2数据准备
这里通过os.listdir判断给定目录下的是文件还是文件夹,如果是文件夹,那么就进入读取其中的所有文件,这些图像对应的标签就是他们所属的文件夹的编号,遍历完所有子文件夹(这里不限制文件夹数目,可以动态的识别出文件夹)之后便完成了数据集的读取,函数返回读取到的所有图片和图片对应的标签。
# 读取图片
def read_img(path):
global types
global flower
imgs = []
labels = []
if not os.path.isdir(path):
print("路径不正确")
exit(0)
for s in os.listdir(path):
print( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2085
2085

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











