






搭建MPI并行计算环境,并使用迭代方法,计算当n取值为100,10000,1000000时PI的计算结果
一、实验目的
搭建MPI并行计算环境,利用课件中PI计算的公式,计算PI值,n分别使用100、10000、1000000计算结果。要求写出实验报告,并对实验结果进行分析,分析n值对精度的影响,并行进程的个数对计算速度的影响
二、实验环境
Vmware Workstation 15 Player + Ubuntu Kylin
三、实验原理
1、π 的计算公式
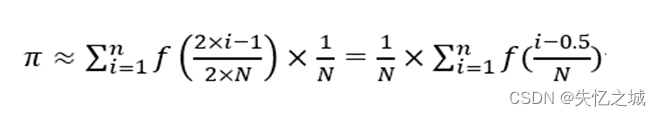
2、利用矩形求MPI

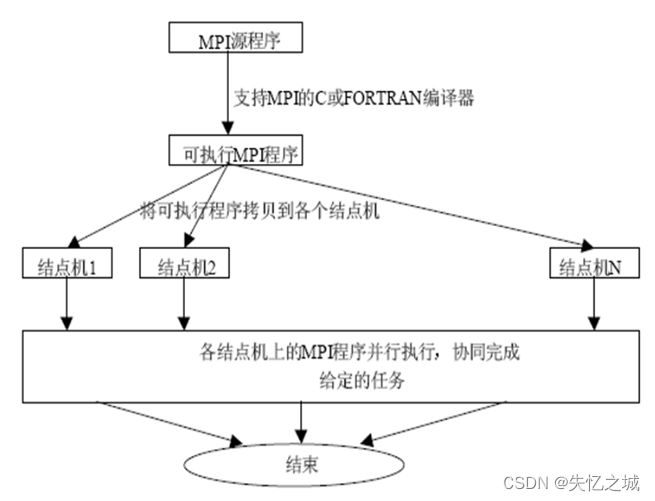
3、MPI流程
四、实验步骤
1、下载MPI、配置好相关运行环境,并测试环境是否配置成功
(1)解压:
sudo tar - zxvf mpich-3.4.2.tar.gz
(2)安装C、C++、gfortran
apt-get install gcc
apt-get install g++
apt-get install gfortran
(3)进入mpich-4.1.2文件夹:
cd mpich-4.1.2
(4)进行软件配置与检查:(注:prefix参数是表示安装路径。)
sudo ./configure --disable-fortran -prefix=/home/hadoop/mpi/mpi4
(5)使用make命令去执行编译:(注:make命令执行过程较长)
make
(6)当make完成之后,就可以使用make install命令进行安装了:
sudo make install
(7)配置环境变量
①编辑系统配置文件
vim ~/.bashrc
②在最后一行添加
export PATH= /home/hadoop/mpi/mpi4/bin:$PATH
③激活环境变量配置文件
source ~/.bashrc
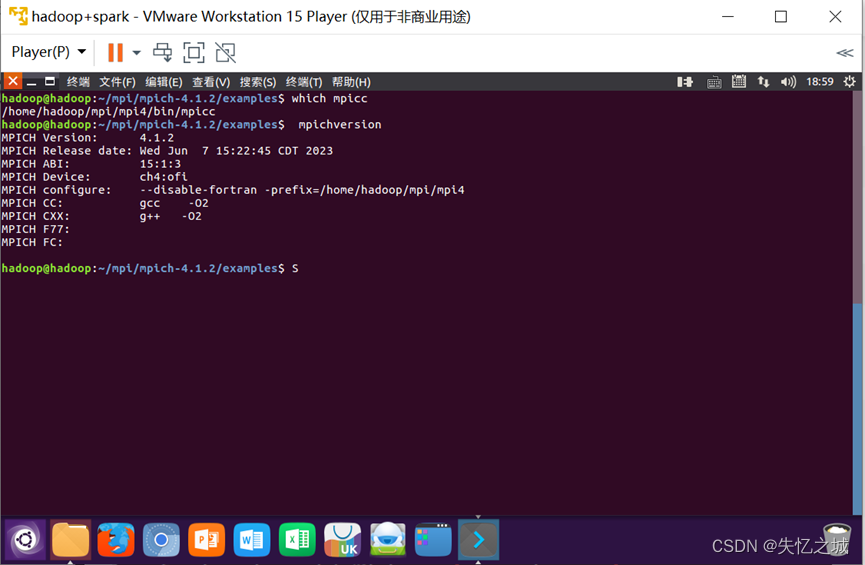
(8)判断是否安装成功
①查看位置信息
which mpicc
②查看版本号,若出现版本号说明安装成功
mpichversion
(9)运行一个实例
cd examples
mpirun -np 4 ./hellow

(10)附上用mpi变编译和运行的两条命令
mpicc -o compi compi.c
mpirun -np 4 ./compi
2、现在开始正式表演了
(1)改变n的值,记录时间和准确度的变化(进程数np=4没有变)
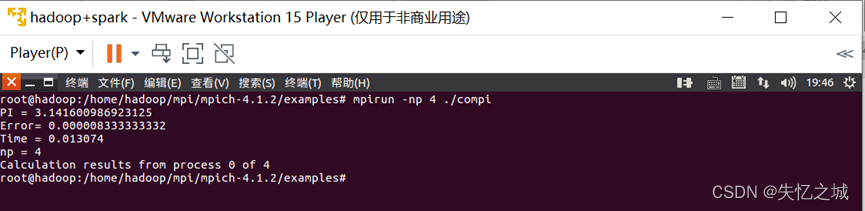
①n=100
②n=10000
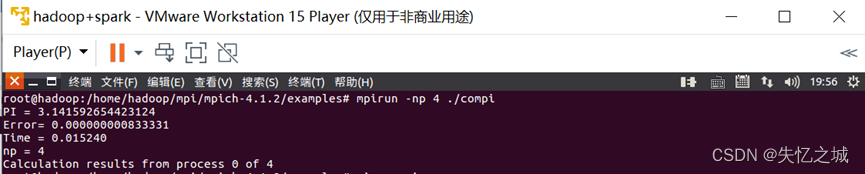
③n=1000000

(2)运行多线程程序,运行不同的np来看运行时间
①n=100时,np分别为4、8、12、16的运行结果
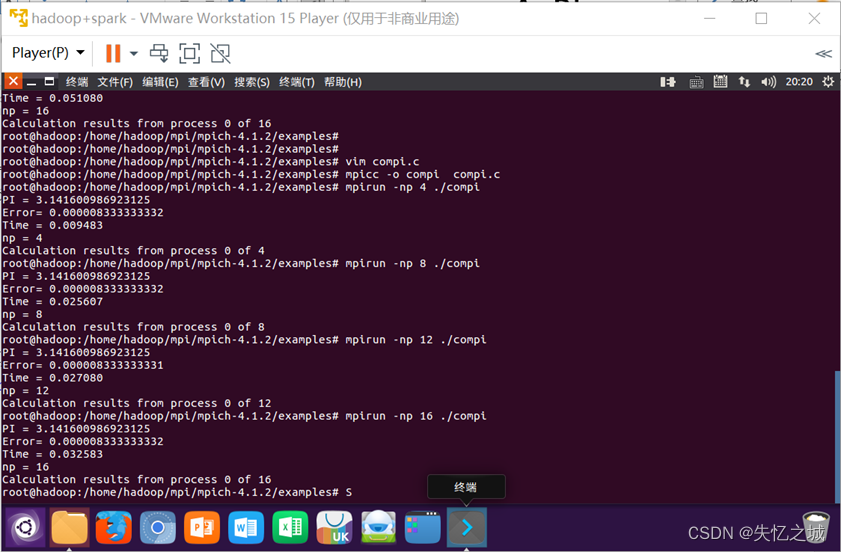
②n=10000时,np分别为4、8、12、16的运行结果

③n=1000000时,np分别为4、8、12、16的运行结果

五、实验数据记录
1、 表一:改变n的值,时间和准确度的变化(进程数np=4没有变)
| n | 100 | 10000 | 1000000 |
|---|---|---|---|
| PI | 3.141600986923125 | 3.141592654423124 | 3.141592653589903 |
| Error | 0.000008333333332 | 0.000000000833331 | 0.000000000000110 |
| Time | 0.009483 | 0.015240 | 0.001208 |
2、 表二:改变np的值,时间和PI值的变化(n的值没有变化)
1)N=100时
| n | 4 | 8 | 12 | 16 |
|---|---|---|---|---|
| Time | 0.009483 | 0.025607 | 0.027080 | 0.032583 |
2)N=10000时
| n | 4 | 8 | 12 | 16 |
|---|---|---|---|---|
| Time | 0.015240 | 0.040860 | 0.046599 | 0.062803 |
- N=1000000时
| n | 4 | 8 | 12 | 16 |
|---|---|---|---|---|
| Time | 0.001208 | 0.022595 | 0.038823 | 0.050756 |
六、 实验结果
1、改变n值对π精读的影响
由表一,我们可以看出,随着n值的增加,计算所得π的值开始逐渐精准,因为使用的是矩形切分法,由微积分知识我们就可以知道,切分的矩形越小越精准,而最后的极限便是真实值。
2、改变进程数对计算速度的影响
由表一,我们可以看到,当n较小时,每次运行时间上的增加并不明显,但当n足够大时,可以明显看出时间的增加。
通过截图再结合表二,当n值不变时,只增加并行程序数时,我们可以很清晰的看到,随着进程个数的增加,程序运行时间是一个慢慢下降的趋势。与此同时,对比表二的两个表,我们也可以看到,当n值比较小时,并行进程数对运行时间的影响并无明显的关系,甚至并行计算不会对运行时间提升有所帮助,只有当n比较大时,并行的效果才比较明显。
除此之外,还发现当n值与np值较大时,即使维持他们的值不变,重新运行几次,发现运行时间变化较大,存在振荡的情况,可以从运行截图中看出
附录
详细代码
#include<stdio.h>
#include<mpi.h>
#include<math.h>
double ppp = 3.141592653589793238462643383279 ;
int main(int argc, char* argv[])
{
int id, np, i, j;
int tag = 666;
double pi = 0.0;
double fVal;
int n =100;
MPI_Status status;
double h = (double)1 / n;
double local = 0.0;
double start, end;
double a;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &np);
MPI_Comm_rank(MPI_COMM_WORLD, &id);
start = MPI_Wtime();
for (i = id; i < n; i += np)
{
a = (i + 0.5) * h;
fVal = 4.0 / (1.0 + a * a);
local += fVal;
}
local = local * h;
if (id != 0)
{
MPI_Send(&local, 1, MPI_DOUBLE, 0, id, MPI_COMM_WORLD);
}
if (id == 0)
{
pi = local;
for (j = 1; j < np; j++)
{
MPI_Recv(&local, 1, MPI_DOUBLE, j, j, MPI_COMM_WORLD, &status);
pi += local;
}
}
end = MPI_Wtime();
if (id == 0)
{
printf("PI = %.15f\n", pi);
printf("Error= %.15f\n",fabs(ppp-pi));
printf("Time = %lf\n", end - start);
printf("np = %d\n", np);
printf("Calculation results from process %d of %d\n", id, np);
}
MPI_Finalize();
return 0;
}















 3940
3940











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









