







python爬虫(四)之九章智算汽车文章爬虫
闲来没事就写一条爬虫抓取网页上的数据,现在数据已经抓完,将九章智算汽车文章的爬虫代码分享出来。当前代码采用python编写,可抓取所有文章,攻大家参考。
import requests
import json
import csv
from lxml import etree
import time
class JiuzhangAI:
def __init__(self):
self.article_list_pre_url = "http://jiuzhang-ai.com/col.jsp?id=105"
self.start_page = 1
self.end_page = 1000
self.headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Cookie': '_siteStatVisitorType=visitorType_28545812; _siteStatRedirectUv=redirectUv_28545812; _cliid=ui9MLktTy5IU8qQF; _checkSiteLvBrowser=true; _siteStatId=d6211b21-c0af-4f93-a5df-91f51871188d; _siteStatDay=20240313; _siteStatVisit=visit_28545812; _lastEnterDay=2024-03-13; _siteStatReVisit=reVisit_28545812; _reqArgs=; _siteStatVisitTime=1710339315683',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36'
}
self.article_detail_headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Cookie': '_siteStatVisitorType=visitorType_28545812; _siteStatRedirectUv=redirectUv_28545812; _cliid=ui9MLktTy5IU8qQF; _checkSiteLvBrowser=true; _siteStatId=d6211b21-c0af-4f93-a5df-91f51871188d; _siteStatDay=20240313; _siteStatVisit=visit_28545812; _lastEnterDay=2024-03-13; _siteStatReVisit=reVisit_28545812; _reqArgs=%7B%22args%22%3A%7B%22id%22%3A233%7D%2C%22anchor%22%3A%22_np%3D0_633_7%22%2C%22type%22%3A10%7D; _siteStatVisitTime=1710343180119',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36'
}
def post_request(self, url):
# response = requests.request("GET", url, headers=headers, data=payload)
# return response.text
pass
def get_request(self, url, headers):
response = requests.request("GET", url, headers=headers)
return response.text
def do_work(self):
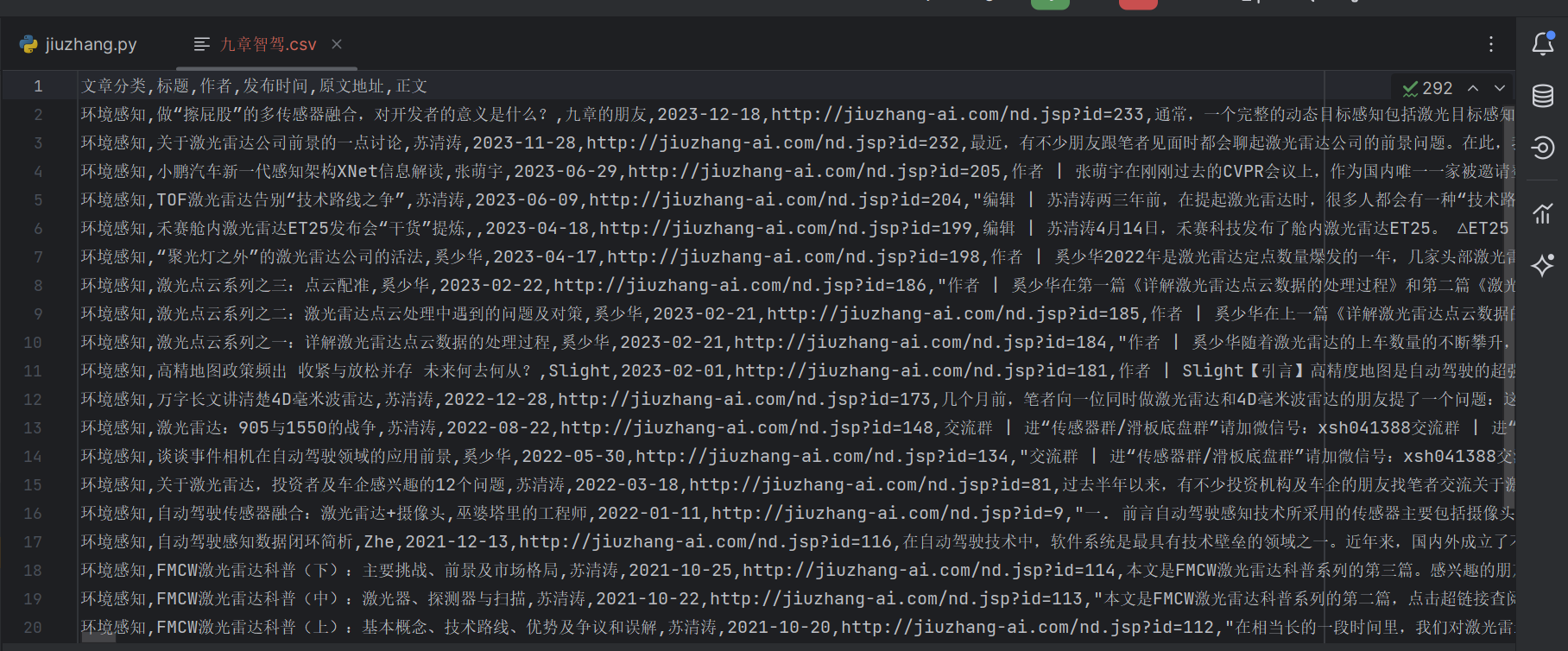
with open('九章智驾.csv', 'w', newline='', encoding='utf-8-sig') as file:
writer = csv.writer(file)
csv_title = ["文章分类", "标题", "作者", "发布时间", "原文地址", "正文"]
writer.writerow(csv_title)
text = requests.get(self.article_list_pre_url, headers=self.headers).text
html = etree.HTML(text)
# tag_hrefs = html.xpath("//div/div[1]/span/a/@href")
tags = html.xpath("//div/div[1]/span/a")
# 遍历所有类别
for tag in tags:
tag_href = tag.xpath("./@href")[0]
tag_title = tag.xpath("./text()")[0].replace("\n", "").replace(" ", "")
# 1. 写第一页
article_text = requests.get(tag_href, headers=self.headers).text
articles_html = etree.HTML(article_text)
article_list_html = articles_html.xpath('//*[@id="newsList31"]/div[@topclassname="top1"]')
print(tag_href)
# 遍历所有文章列表
self.write_page(writer, article_list_html, tag_title)
# 2. 从2页开始写
max_page = articles_html.xpath('//span[@class="pageNo"]/a/span/text()')
if len(max_page) > 0:
max_page = int(max_page[0])
for current_page in range(2, max_page):
article_text = requests.get(tag_href + "&m31pageno=" + current_page, headers=self.headers).text
articles_html = etree.HTML(article_text)
article_list_html = articles_html.xpath('//*[@id="newsList31"]/div[@topclassname="top1"]')
print(tag_href)
# 遍历所有文章列表
self.write_page(writer, article_list_html, tag_title)
# page_no = 1
# pageCallback = self.init_page_callback
# while True:
# print("================> 当前第" + str(page_no) + "页 ============")
#
# text = self.post_request(self.article_list_pre_url)
# data = json.loads(text)["data"]
# pageCallback = data["pageCallback"]
# itemList = data["itemList"]
# # self.write_page(writer, itemList)
#
# page_no += 1
def write_page(self, writer, article_list_html, tag_title):
for article_html in article_list_html:
article_href = article_html.xpath("./table/tr/td[@class='newsTitle']/a/@href")[0]
publish_date = article_html.xpath("./table/tr/td[@class='newsCalendar']/a/text()")[0]
article_title = article_html.xpath("./@newsname")[0]
# print(article_href)
# print(article_title)
# print(publish_date)
article_text = requests.get(url=article_href, headers=self.article_detail_headers).text
article_detail_html = etree.HTML(article_text)
article_detail_text = article_detail_html.xpath(
"normalize-space(//div[@class='richContent richContent0'])")
article_author = article_detail_html.xpath("//span[@class='newsInfo newsInfo_author']/text()")
if len(article_author) > 0:
article_author = article_author[0]
else:
article_author = ""
# print(article_detail_text)
# print(article_author)
row = [tag_title, article_title, article_author.replace("作者:", ""), publish_date, article_href,
article_detail_text]
writer.writerow(row)
print("===========> 当前文章 " + article_href + " 写入完毕", )
if __name__ == '__main__':
jiuzhangAI = JiuzhangAI()
jiuzhangAI.do_work()
运行代码在同级目录下会出现一个九章智算.csv文件的,这个就是所有的汽车文章数据啦。
写在最后
代码精选(www.codehuber.com),程序员的终身学习网站已上线!
如果这篇【文章】有帮助到你,希望可以给【JavaGPT】点个赞👍,创作不易,如果有对【后端技术】、【前端领域】感兴趣的小可爱,也欢迎关注❤️❤️❤️ 【JavaGPT】❤️❤️❤️,我将会给你带来巨大的【收获与惊喜】💝💝💝!















 20万+
20万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











