







整理一下自己的笔记
是根据b站up主 大大的小番茄 的教程来看的,非常适合很新很新的新手。
首先要明白爬虫的思路:请求获取网页IP,根据已知的IP获取服务器返回的HTML,找到HTML里面自己需要的信息。
第一部分:HTML
大部分网页的构成分为三个部分:HTML(相当于骨架)、CSS(定义了外观)、JScript(表示功能)。爬虫主要针对的是HTML。
看到的HTML内容的<>称为标签。
常见的标签如下:
| 标签 | 用法或意义 |
|---|---|
<html><html/> |
中间的元素是网页 |
<body></body> |
用户可见内容 |
<div> |
框架 |
<p> |
段落 |
<li> |
列表 |
<img> |
图片 |
<a href ></a> |
超链接 |
- 其中一些成对出现的标签称为闭合标签,比如
<head> <head/> <div><div/>,也就是<></>成对出现的。 - 另外一些称为自闭和标签,比如
<input >,只有一个尖括号,没有与之对应的。
标签里都有一些标签的属性,比如id、style、class等等,标签拥有层级关系。


一个例子:


PS.关于URL
简而言之,就是网址。
http协议——端口80
https协议——端口443
这部分视频非常详细地简单阐述了一下,感兴趣或者有需要的可以看看。
第二部分:python中模拟请求的库
要注意的是:python访问HTML的时候会被拒绝,因此需要“伪装”成一个用户在浏览,因此需要修改头参数(user-agent),还要注意refer、cookie,这部分直接复制粘贴相应的代码即可。
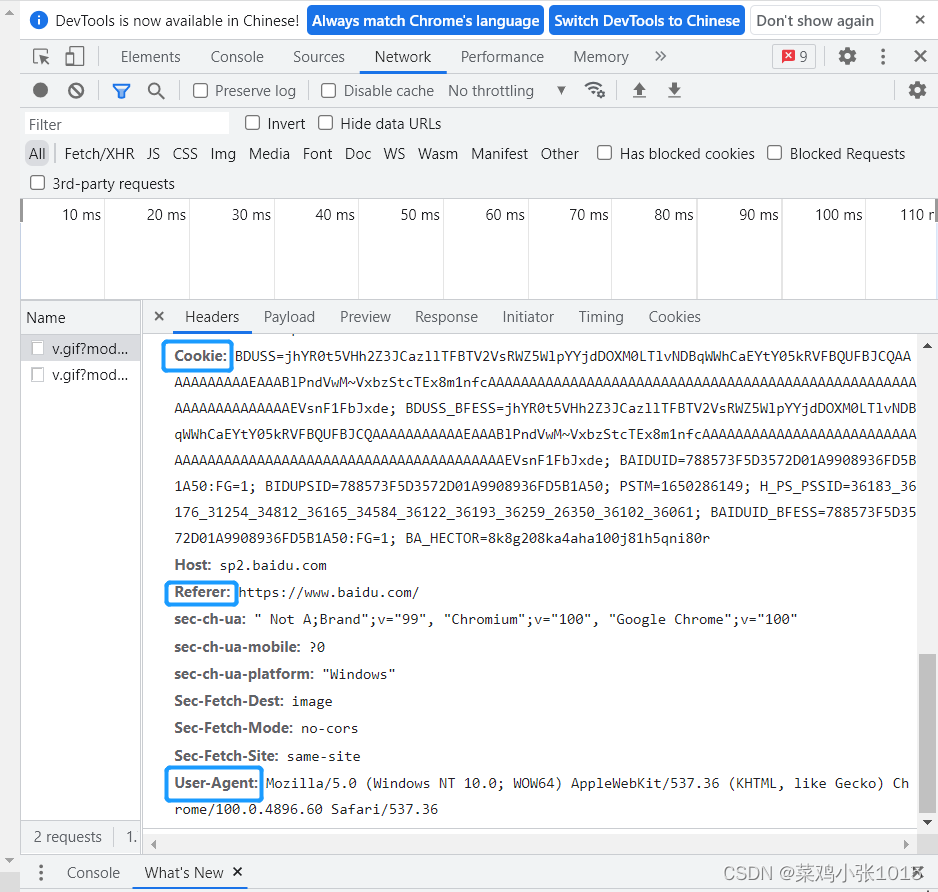
requests库
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 569
569











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









