







写在前面
本节主要介绍了线性回归原理以及它的可行性,最后与前面学过的线性分类进行了对比分析。
1. 线性回归问题
∙
\bullet
∙ 引入:我们假设现在有些用户已经申请到了信用卡,但是银行决定给他们发放多少钱。此时返回的结果就是一个实数区间。
∙
\bullet
∙ 实现:
▹ \triangleright ▹ 现在我们有用户的信息,包括以下内容:年龄、年收入、工作年龄、当前负债。
▹ \triangleright ▹ 我们还是像(二)中感知机模型提到的一样,为每一个维度分配一个权重,然后求得总和,最后在减去一个偏差(阈值)。为了优化,把这个偏差放到了第0维度。(具体实现看机器学习基石二中第一块内容)
所以当有d个维度时,自变量
x
=
(
x
0
,
x
1
,
.
.
.
x
d
)
x=(x_{0},x_{1},...x_{d})
x=(x0,x1,...xd),返回值
y
≈
∑
i
=
0
d
w
i
x
i
y≈\sum_{i=0}^{d}w_{i}x_{i}
y≈i=0∑dwixi
线性回归假设:
h
(
x
)
=
w
T
x
h(x)=w^{T}x
h(x)=wTx
(它很像感知机模型,但是感知机模型最终求的是符号)
▹
\triangleright
▹ 当
x
x
x 只有一个维度或者两个维度时,做出来的直线如下:

对于一维、二维的
x
x
x 来说,线性回归最终要找到的就是误差最小的直线以及平面。每个点到直线或者平面的竖直距离就是该点的误差。
▹
\triangleright
▹ 计算误差的方法:最小二乘法。我们求解误差的平方和对应的权重,对于单点来说就是:
e
r
r
(
y
^
,
y
)
=
(
y
^
−
y
)
2
err(\hat{y},y )=(\hat{y}-y)^{2}
err(y^,y)=(y^−y)2
对于样本数据来说,计算方法为(选择对应误差最小的一组权重值):
E
i
n
(
w
)
=
1
N
∑
n
=
1
N
(
w
T
x
n
−
y
n
)
2
E_{in}(w)=\frac{1}{N} \sum_{n=1}^{N}(w^{T}x_{n}-y_{n})^{2}
Ein(w)=N1n=1∑N(wTxn−yn)2
对于整体数据来说,计算方法为(整体数据对应的误差结果):
E
o
u
t
(
w
)
=
ε
(
x
,
y
)
∼
P
(
w
T
x
−
y
)
2
E_{out}(w)= \underset{(x,y)\sim P}{\varepsilon} (w^{T}x-y)^{2}
Eout(w)=(x,y)∼Pε(wTx−y)2
我们接下来需要实现的就是如何找到较小的 E i n ( w ) E_{in}(w) Ein(w)。
2. 求解最小的 E i n ( w ) E_{in}(w) Ein(w) 对应的 w w w
∙
\bullet
∙上面我们已经得到了
E
i
n
(
w
)
E_{in}(w)
Ein(w) 的计算方法,接着我们对其进行转换:
E
i
n
(
w
)
=
1
N
∑
n
=
1
N
(
w
T
x
n
−
y
n
)
2
=
1
N
∑
n
=
1
N
(
x
n
T
w
−
y
n
)
2
=
1
N
∥
x
1
T
w
−
y
1
x
2
T
w
−
y
2
.
.
.
x
n
T
w
−
y
n
∥
2
=
1
N
∥
[
−
x
1
T
−
−
x
2
T
−
−
.
.
.
−
−
x
N
T
−
]
w
−
[
y
1
y
2
.
.
.
y
N
]
∥
2
=
1
N
∥
X
⏟
N
×
d
+
1
w
⏟
d
+
1
×
1
−
y
⏟
N
×
1
∥
\begin{matrix} E_{in}(w)&= &\frac{1}{N} \sum_{n=1}^{N}(w^{T}x_{n}-y_{n})^{2}= &\frac{1}{N} \sum_{n=1}^{N}(x_{n}^{T}w-y_{n})^{2} \\ & = & \frac{1}{N}\begin{Vmatrix} x_{1}^{T}w-y_{1} \\ x_{2}^{T}w-y_{2}\\ ...\\ x_{n}^{T}w-y_{n} \end{Vmatrix}^{2} & \\ & = &\frac{1}{N}\begin{Vmatrix} \begin{bmatrix} -& x_{1}^{T} & -\\ -& x_{2}^{T} & - \\ -& ... & -\\ -& x_{N}^{T} & - \end{bmatrix}w-\begin{bmatrix} y_{1}\\ y_{2} \\ ...\\ y_{N} \end{bmatrix} \end{Vmatrix}^{2} & \\ & = & \frac{1}{N}\left \| \underset{N×d+1}{\underbrace{X} } \underset{d+1×1}{\underbrace{w} } -\underset{N×1}{\underbrace{y} } \right \| & \end{matrix}
Ein(w)====N1∑n=1N(wTxn−yn)2=N1∥∥∥∥∥∥∥∥x1Tw−y1x2Tw−y2...xnTw−yn∥∥∥∥∥∥∥∥2N1∥∥∥∥∥∥∥∥⎣⎢⎢⎡−−−−x1Tx2T...xNT−−−−⎦⎥⎥⎤w−⎣⎢⎢⎡y1y2...yN⎦⎥⎥⎤∥∥∥∥∥∥∥∥2N1∥∥∥∥∥∥N×d+1
Xd+1×1
w−N×1
y∥∥∥∥∥∥N1∑n=1N(xnTw−yn)2
我们将其展开为矩阵形式,最后得到的表达式中有矩阵 X X X,它是样本数据矩阵,它有 N N N 个样本数据,每个样本数据有 d d d 维,再加上第0维,一共 d + 1 d+1 d+1 维;向量 w w w 为权重向量,本来是 d d d 维,再加上第0维,一共 d + 1 d+1 d+1 维;向量 y y y 为线性回归直线上对应的值,为 N N N 行1列。
∙
\bullet
∙ 那么先在要求的就是:
m
i
n
w
E
i
n
(
w
)
=
1
N
∥
X
w
−
y
∥
2
\underset{w}{min} \ E_{in}(w)=\frac{1}{N} \left \| Xw-y\right \|^{2}
wmin Ein(w)=N1∥Xw−y∥2
其中矩阵
X
X
X 和向量
y
y
y 都是已知的,那么我们现在做出
w
w
w 与
E
i
n
(
w
)
E_{in}(w)
Ein(w) 的坐标图:
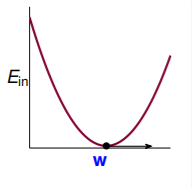
我们要寻找
w
w
w 的值,使得
E
i
n
E_{in}
Ein 的函数值最小,表现在梯度为0上。
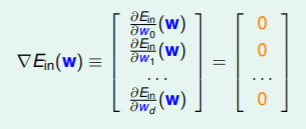
∙
\bullet
∙ 将上式展开可得:
E
i
n
(
w
)
=
1
N
(
w
T
X
T
X
⏟
A
w
−
2
w
T
X
T
y
⏟
b
+
y
T
y
⏟
c
)
E_{in}(w)=\frac{1}{N}(w^{T} \underset{A}{\underbrace{X^{T}X}}w-2w^{T} \underset{b}{\underbrace{X^{T}y}}+\underset{c}{\underbrace{y^{T}y}})
Ein(w)=N1(wTA
XTXw−2wTb
XTy+c
yTy)
它的梯度为:
∇
E
i
n
(
w
)
=
2
N
(
X
T
X
w
−
X
T
y
)
\nabla E_{in}(w)=\frac{2}{N}(X^{T}Xw-X^{T}y)
∇Ein(w)=N2(XTXw−XTy)
令偏导等于0,可以得到解为(最终权重向量):
w
L
I
N
=
(
X
T
X
)
−
1
X
T
y
w_{LIN}=(X^{T}X)^{-1}X^{T}y
wLIN=(XTX)−1XTy
我们把
(
X
T
X
)
−
1
X
T
(X^{T}X)^{-1}X^{T}
(XTX)−1XT 叫做伪逆矩阵(pseudo-inverse),记作
X
†
X^{\dagger}
X†,所以有:
w
L
I
N
=
X
†
y
w_{LIN}=X^{\dagger}y
wLIN=X†y
当
N
N
N 远大于
d
+
1
d+1
d+1时,可以求得伪逆矩阵。当我们得到
w
L
I
N
w_{LIN}
wLIN 以后,那么线性回归直线就为:
y
^
=
w
L
I
N
T
x
n
=
X
X
†
y
\hat{y}=w_{LIN}^{T}x_{n}=XX^{\dagger}y
y^=wLINTxn=XX†y
3. 泛化问题
∙ \bullet ∙ 通过上面推出来的公式我们可以直接得到 w L I N w_{LIN} wLIN,感觉就没有机器自己学习进步的过程,那么是不是就以为着此类方法不属于机器学习呢?
其实在实现的过程中也对 E i n E_{in} Ein 和 E o u t E_{out} Eout 进行了最小化的求解,从结果来看,确实属于机器学习。
∙
\bullet
∙ 下面通过一种方法来证明线性回归可以得到较好的
E
i
n
E_{in}
Ein 和
E
o
u
t
E_{out}
Eout。
E
i
n
(
w
L
I
N
)
=
1
N
∥
y
−
y
^
∥
2
=
1
N
∥
y
−
X
X
†
y
∥
2
=
1
N
∥
(
I
−
X
X
†
)
y
∥
E_{in}(w_{LIN}) = \frac{1}{N} \left \| y-\hat{y} \right \|^{2} = \frac{1}{N}\left \| y-XX^{\dagger}y \right \|^{2} =\frac{1}{N} \left \| (I-XX^{\dagger})y \right \|
Ein(wLIN)=N1∥y−y^∥2=N1∥∥y−XX†y∥∥2=N1∥∥(I−XX†)y∥∥
我们把
X
X
†
XX^{\dagger}
XX† 叫做帽子矩阵(hat matrix)
H
H
H,下面具体来具体
H
H
H 的具体含义(在N维实例中):

▹
\triangleright
▹
y
^
=
X
w
L
I
N
\hat{y}=Xw_{LIN}
y^=XwLIN 位于
d
+
1
d+1
d+1 维平面的一条直线。
▹ \triangleright ▹ 那么 y − y ^ y-\hat{y} y−y^ 就是将y向量投影在 y ^ \hat{y} y^ 平面时结果最小。
▹ \triangleright ▹ 机器学习就是想找到最接近y的直线 y ^ \hat{y} y^。记录 t r a c e ( I − H ) = N − ( d + 1 ) trace(I-H)=N-(d+1) trace(I−H)=N−(d+1), t r a c e ( I − H ) trace(I-H) trace(I−H) 为 I − H I-H I−H 的迹。
当存在 n o i s e noise noise 时,发生改变:
E
i
n
(
)
w
L
I
N
=
1
N
∥
(
I
−
H
)
n
o
i
s
e
∥
2
=
1
N
(
N
−
(
d
+
1
)
)
∥
n
o
i
s
e
∥
2
E_{in}()w_{LIN}=\frac{1}{N} \left \| (I-H)noise \right \|^{2}=\frac{1}{N}(N-(d+1))\left \| noise \right \|^{2}
Ein()wLIN=N1∥(I−H)noise∥2=N1(N−(d+1))∥noise∥2
最后可以分别求得
E
i
n
ˉ
\bar{E_{in}}
Einˉ 和
E
o
u
t
ˉ
\bar{E_{out}}
Eoutˉ:
E
i
n
ˉ
=
n
o
i
s
e
l
e
v
e
l
⋅
(
1
−
d
+
1
N
)
\bar{E_{in}}=noise \ level \cdot (1-\frac{d+1}{N})
Einˉ=noise level⋅(1−Nd+1)
E
o
u
t
ˉ
=
n
o
i
s
e
l
e
v
e
l
⋅
(
1
+
d
+
1
N
)
\bar{E_{out}}=noise \ level \cdot (1+\frac{d+1}{N})
Eoutˉ=noise level⋅(1+Nd+1)
将它们画出来如下:
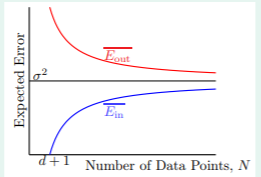
其中
σ
2
\sigma ^{2}
σ2 就是
n
o
i
s
e
l
e
v
e
l
noise \ level
noise level,当
N
N
N 趋于无穷大时,我们可以看到
E
i
n
ˉ
\bar{E_{in}}
Einˉ 和
E
o
u
t
ˉ
\bar{E_{out}}
Eoutˉ 逐渐接近
n
o
i
s
e
l
e
v
e
l
noise \ level
noise level,也证明了这种方式时可以进行机器学习的。
4. 与线性分类的对比
可以发现它们的结果
y
y
y 定义域不同,线性分类只能为-1或+1,线性回归为整个实数域;
h
(
x
)
h(x)
h(x) 也不同,线性分类只要符号,线性回归需要具体的值;它们计算误差的方法也不同。

下面给出了两种错误的比较:

可以发现无论在什么情况下,线性分类的误差都不大于线性回归的误差。而且线性回归的方法同样也可以求解线性分类的问题。
















 6268
6268











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











