







网站网址
https://www.qidian.com/all
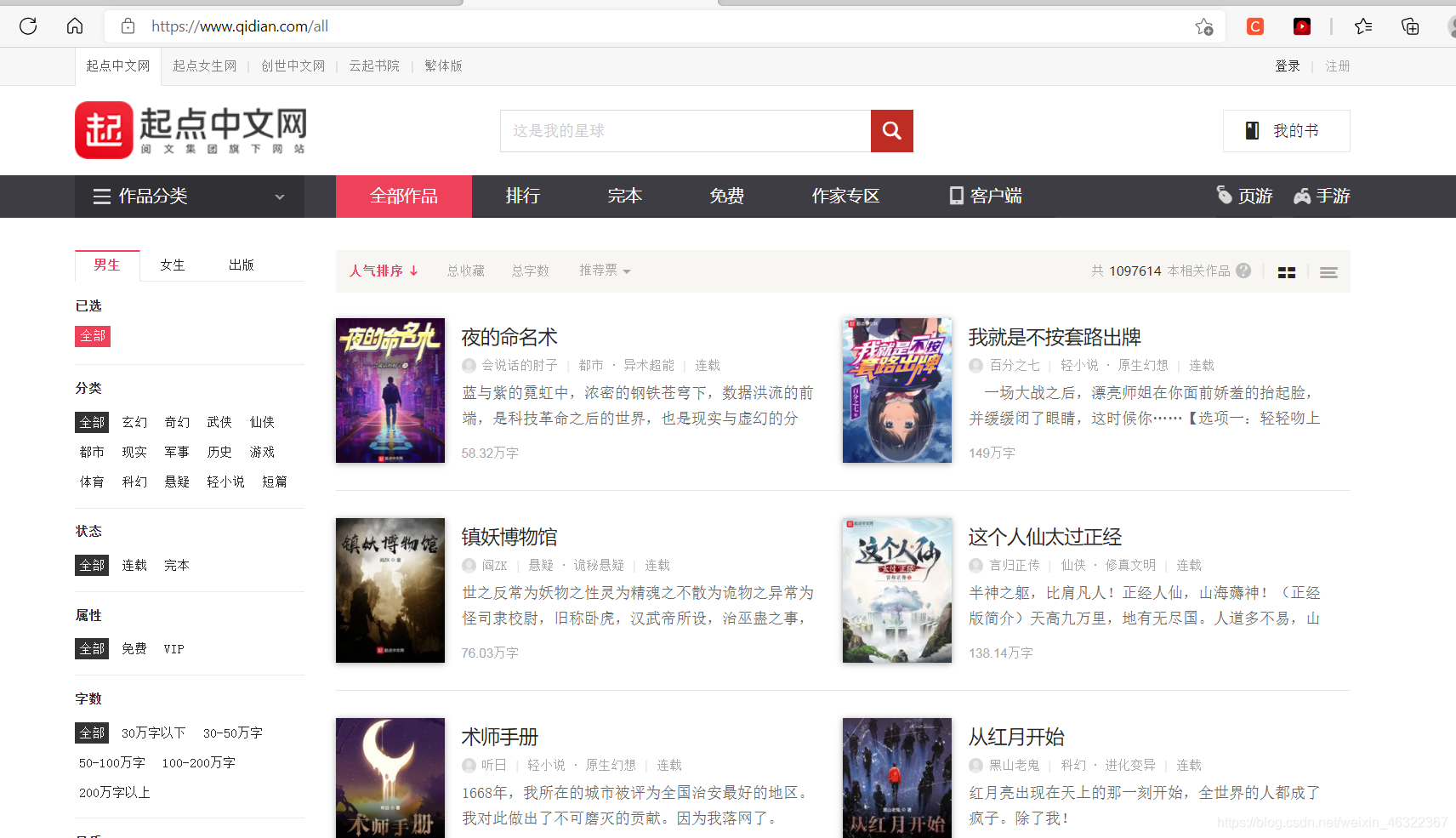
共有5个页面
分析
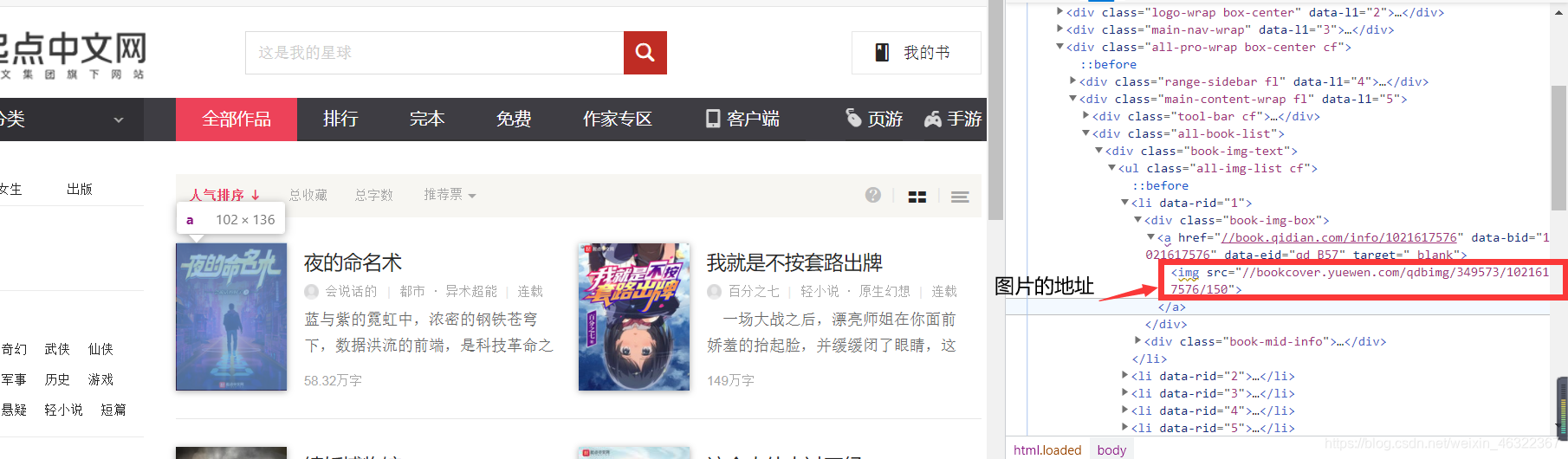
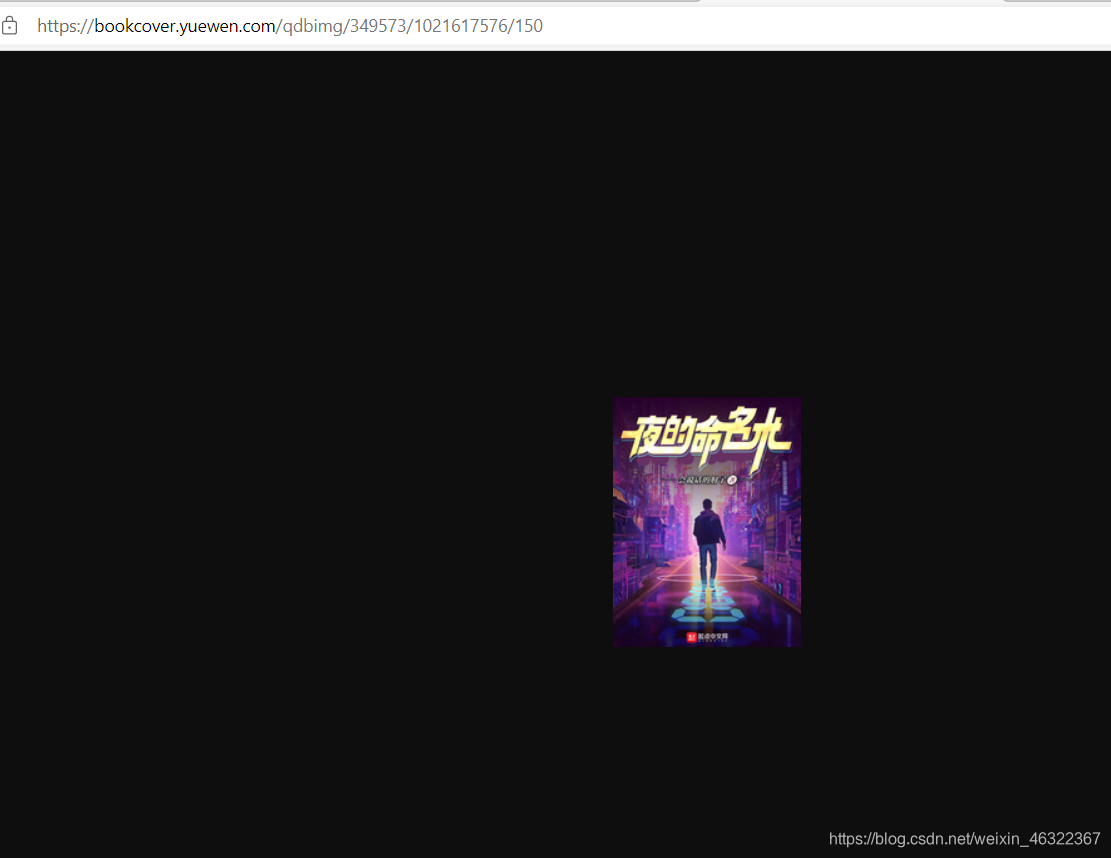
但是发现这个图片很小,那怎么办呢?
经过我的研究后发现,去掉地址后面的"/150",就好了
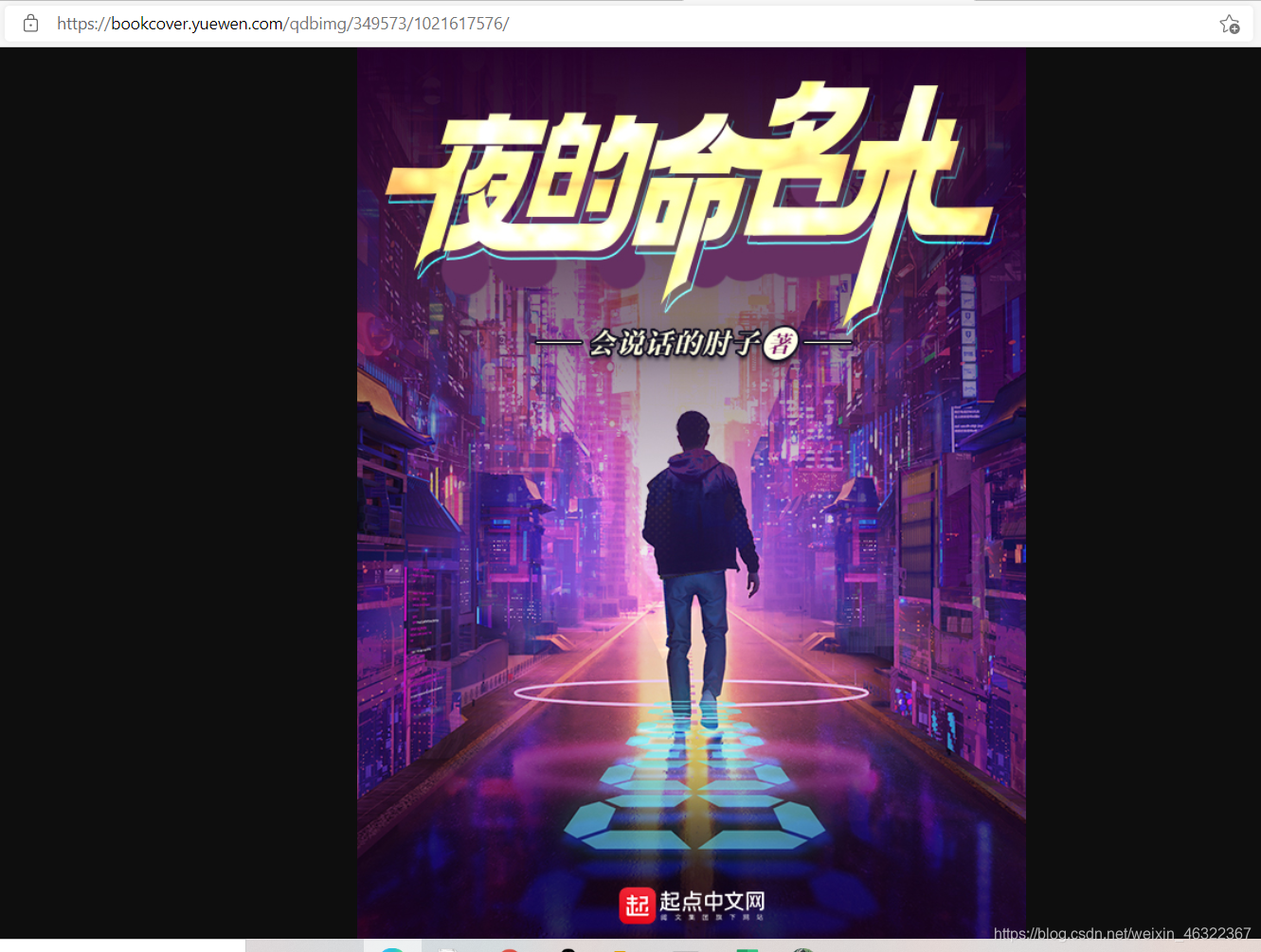
完美!!!
代码
我是在桌面创建了一个名为“爬取起点中文网”,的文件夹,然后把py文件放在里面运行。所以在你运行我的代码的时候,需要更改以下代码,更改为你自己的文件路径
os.chdir(r"C:\Users\dell\Desktop\爬取起点中文网")
同样你也可以修改存储图片的路径。
当然py文件的名称可以随意定义,不会影响程序的运行
完整代码如下:
# 导入相应的库文件
import xlwt
import requests
from lxml import etree
import os
# 初始化列表,存入爬虫数据
all_info_list = []
# 定义获取爬虫信息的函数
def get_info(url):
html = requests.get(url)
selector = etree.HTML(html.text)
# 定位大标签,以此循环
infos = selector.xpath('//ul[@class="all-img-list cf"]/li')
for info in infos:
title = info.xpath('div[2]/h4/a/text()')[0]
author = info.xpath('div[2]/p[1]/a[1]/text()')[0]
style_1 = info.xpath('div[2]/p[1]/a[2]/text()')[0]
style_2 = info.xpath('div[2]/p[1]/a[3]/text()')[0]
style = style_1+'·'+style_2
complete = info.xpath('div[2]/p[1]/span/text()')[0]
introduce = info.xpath('div[2]/p[2]/text()')[0].strip()
info_list = [title, author, style, complete, introduce]
# 把数据存入列表
all_info_list.append(info_list)
# 爬取小说封面图片
if not os.path.exists('./picture'):
os.mkdir('./picture')
img_src='https:'+info.xpath('div[1]/a/img/@src')[0]
img_src=img_src[0:-4]
img_name=title+'.jpg'
img_data=requests.get(img_src).content
img_path='picture/'+img_name
with open(img_path,'wb') as fp:
fp.write(img_data)
print(img_name,"下载成功")
os.getcwd()
os.chdir(r"C:\Users\dell\Desktop\爬取起点中文网")
# 程序主入口
if __name__ == '__main__':
urls = ['http://a.qidian.com/? page={}'.format(str(i)) for i in range(1, 6)]
# 获取所有数据
print("开始爬取起点中文网小说封面图片......")
for url in urls:
get_info(url)
print("起点中文网小说封面图片爬取完毕!")
print("开始爬取起点中文网小说信息......")
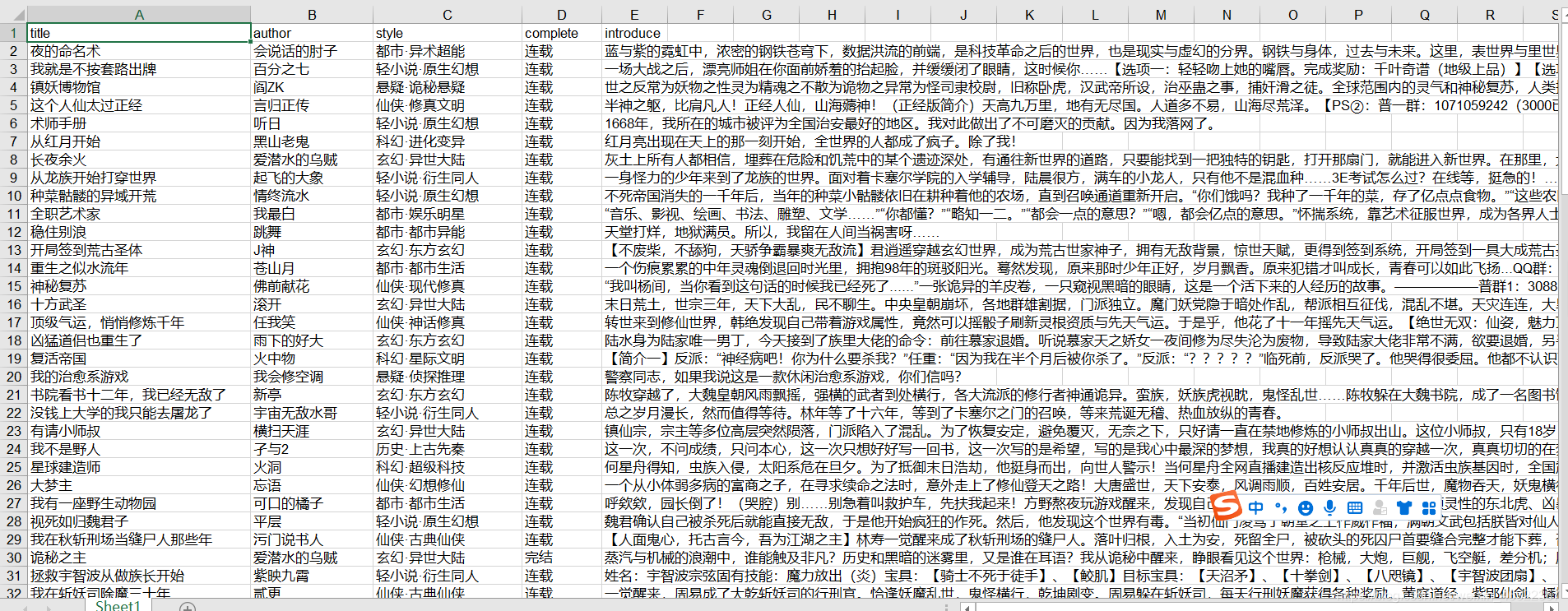
# 定义表头
header = ['title', 'author', 'style', 'complete', 'introduce']
# 创建工作簿
book = xlwt.Workbook(encoding='utf-8')
# 创建工作表
sheet = book.add_sheet('Sheet1')
for h in range(len(header)):
# 写入表头
sheet.write(0, h, header[h])
i = 1 # 行数
for list in all_info_list:
j = 0 # 列数
# 写入爬虫数据
for data in list:
sheet.write(i, j, data)
j += 1
i += 1
# 保存文件
book.save('xiaoshuo.xls')
print("起点中文网小说信息爬取完毕!")
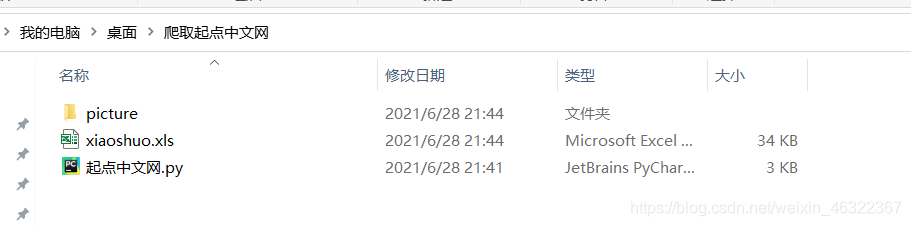
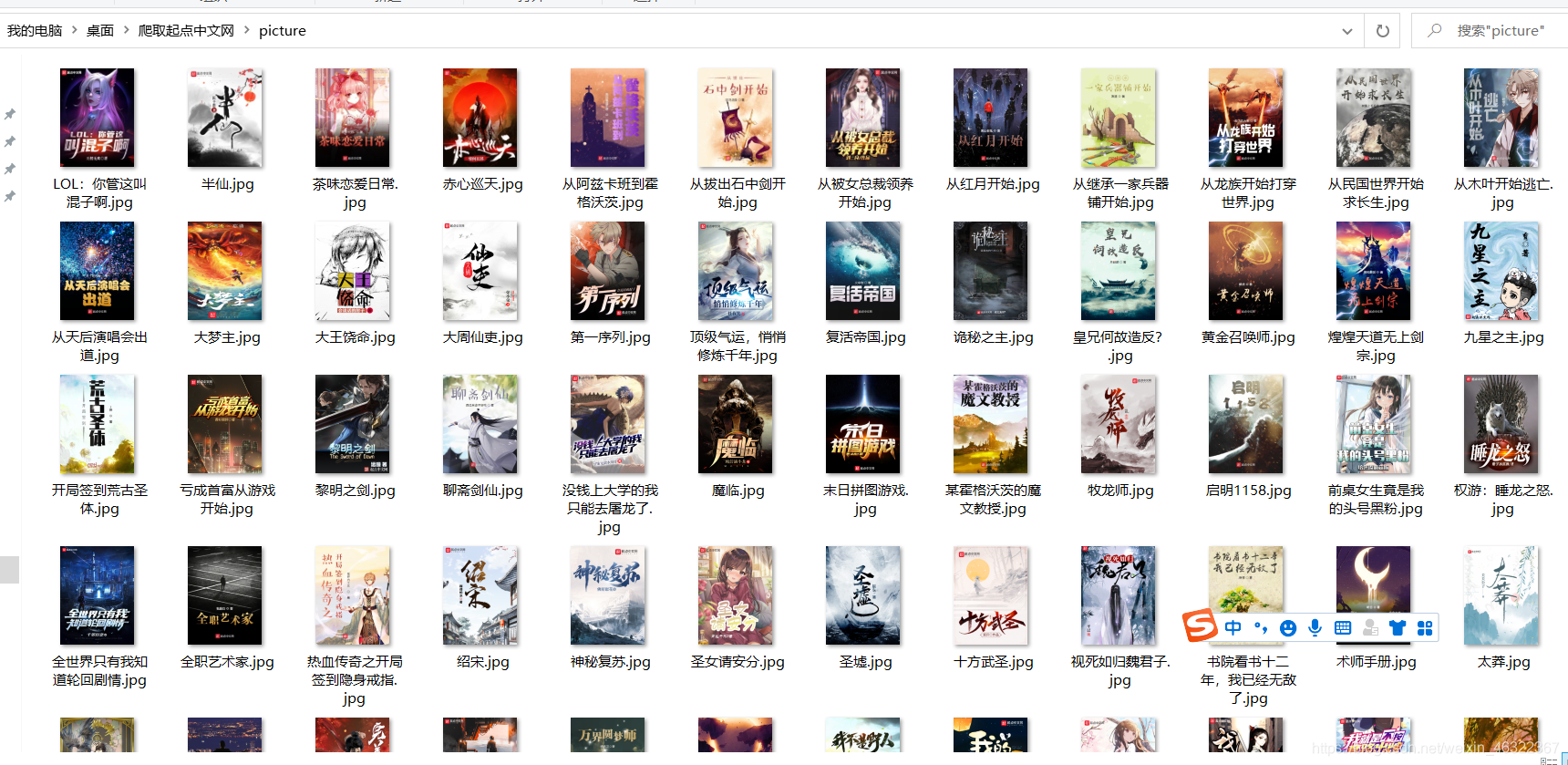
爬取结果

… …




















 2457
2457

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











