






RocksDB 的写流程比读流程要复杂很多,其中涉及到了多线程写入与 RocksDB 采用的很多优化,比如 unordered_write、pipelined_write 等等,还有一些可选策略,比如 2pc、parallel 等等,所以写入过程的分支非常多,如果直接磕源码会很没方向。
本篇博客将先理清 RocksDB 的基本写入框架,不考虑 pipelined_write 优化,并且不讨论源码实现,用以为后续的源码分析做前言。
框架
RocksDB 的写入口为 DBImpl::WriteImpl(),这个函数相当复杂,写操作的所有分支流程基本都被封装进去了,该函数的核心入参为一个 WriteBatch* 和一个 WriteOptions& 。RocksDB 每个线程发起的写事务均以一个 WriteBatch 对象为载体,WriteBatch 记录了要写入的所有数据。接着,WriteBatch 会被封装为一个 WriteThread::Writer 结构体,该结构体将存储 WriteBatch、WriteOptions 中的配置以及前后向指针等等,所以一个写线程配备一个 Writer。可以看下这个结构的源码:
struct Writer {
WriteBatch* batch;
bool sync;
bool no_slowdown;
bool disable_wal;
Env::IOPriority rate_limiter_priority;
bool disable_memtable;
size_t batch_cnt; // if non-zero, number of sub-batches in the write batch
size_t protection_bytes_per_key;
PreReleaseCallback* pre_release_callback;
PostMemTableCallback* post_memtable_callback;
uint64_t log_used; // log number that this batch was inserted into
uint64_t log_ref; // log number that memtable insert should reference
WriteCallback* callback;
bool made_waitable; // records lazy construction of mutex and cv
std::atomic<uint8_t> state; // write under StateMutex() or pre-link
WriteGroup* write_group;
SequenceNumber sequence; // the sequence number to use for the first key
Status status;
Status callback_status; // status returned by callback->Callback()
std::aligned_storage<sizeof(std::mutex)>::type state_mutex_bytes;
std::aligned_storage<sizeof(std::condition_variable)>::type state_cv_bytes;
Writer* link_older; // read/write only before linking, or as leader
Writer* link_newer; // lazy, read/write only before linking, or as leader
// ...
}
简单的来讲,该结构记录了如下信息:
- 本次 write 的配置,比如是否要做 sync,要写入的 WAL 日志编号等等
- 本次要 write 的数据,即 WriteBatch 对象
- 本次 write 所属的 WiteGroup
- 本次 write 的第一个数据对象的 sequence number
- 前置 Writer
- 后置 Writer
WriteGroup 构建
因为随时都会有接连不断的写请求涌入,为了处理并发, RocksDB 将多个 Writer 对象用链表串起来,组成一个WiteGroup,一个 WriteGroup 会选出一个 Leader 来管理当前 group 的写过程。而任意时刻只会有一个WriteGroup被写入。
每个 Writer 写入前要先加入一个 WriteGroup。加入的过程其实将 Writer 对象加入到 WriteGroup 链表尾端。每个 DB 对象一次只能存在一个 WriteGroup,只有当该 WriteGroup 全部写入完成后,才会开始建立新的 WriteGroup。
首先关注下 WriteGroup 的建立过程。
在 DBImpl::WriteImpl() 封装每一个 Writer 之后,都会把它加进当前 DB 对象的 Writer 的单向链表中,不妨把该该链表称为 WriteLink(实际没有这个结构),link_older 就是该链表的指针,由后往前指。而这个 WriteLink 并不是 WriteGroup,二者是包含关系,每次生成 WriteGroup 都是从 WriteLink 的 Leader 开始连续选择一定数量的 Writer 构成的子双向链表。在 WriteLink 中,由 newest_writer_ 代表最后一个 Writer,在 WriteGroup 中,由 last_writer 代表最后一个 Writer。
Writer 加入 WriteLink 的过程,由 WriteThread::JoinBatchGroup() 实现,主要完成两点作用:
- 如果加入时链表为空,则将该 Writer 标记为 Leader;
- 如果加入时链表不为空,则阻塞等待该 Writer 的状态被设置;
WriteGroup 的建立位于 WriteThread::EnterAsBatchGroupLeader() 中,由 Leader 执行,它会首先遍历整个 WriteLink,把单向链表变成双向链表,由 WriteThread::CreateMissingNewerLinks() 实现。接着,重新从 Leader 开始往后遍历,逐个加入 WriteGroup,直到遇见一个 Writer 的配置与 Leader 的配置不符,就算作构建完成。因此,一个 WriteGroup 中所有的 Writer 都是配置相符合的。

WriteGroup 构建完毕后,由 Leader 来处理其向 WAL 以及 Memtable 中的写入,具体怎么写入先略过。
当本次 WriteGroup 写入完毕后,它需要做一些收尾工作,由 Leader 完成,主要为两点:
- 更新全局的 sequence number;
- 设置新的 WriteGroup
第一点由 VersionSet::SetLastSequence() 实现,第二点由 WriteThread::ExitAsBatchGroupLeader() 来实现,这里只关注后者。虽然 WriteThread::CreateMissingNewerLinks() 已经将单向链表变为双向链表,但是在 WriteGroup 写入的过程中,可能有新的 Writer 加入 WriteLink 中,而新的这一段仍然是单向链表,所以 Exit 会重新调用一遍 WriteThread::CreateMissingNewerLinks() 来完善双向链表。接着,设置下一个 WriteGroup 的新Leader(为本组最后一个 Writer 的后置 Writer),并将新 Leader 的前置指针设为 null。

上述流程的源码分析在下一篇博客会详细说明:WriteGroup 源码分析。接下来,我们关注 WriteGroup 的写入。
WriteGroup 写入
这里不考虑 pipelined_write,不考虑 2pc。WriteGroup 的写入分为两步,一是写入 WAL,二是写入 memtable。前者由 DBImpl::WriteToWAL() 实现,后者主要由 WriteBatchInternal::InsertInto() 实现。
WAL
WAL 主要的功能是当 RocksDB 异常退出后,能够恢复出错前的内存中(memtable)数据,因此 RocksDB 默认是每次用户写都会刷新数据到 WAL。每次当当前 WAL 对应的 memtable 刷新到磁盘之后,都会新建一个WAL,即一个 WAL 对应一个memtable。
每一个 WAL 最后都会被写入对应的 WAL 文件中,所有的 WAL 文件均保存在 WA L目录(options.wal_dir),为了保证数据的状态,所有的 WAL 文件的名字都是按照顺序的(log_number)。
写 WAL 可以简单分为三个阶段,第一阶段往 WritableFileWriter 的 buf_ 里面写,第二阶段写到系统缓存,第三阶段是将系统缓存刷盘,也就是让写文件操作落盘。WAL 写入的具体流程会在源码分析时详细说明:WAL 写源码分析(待填坑。
memtable
在 RocksDB 中,每个 CF 都有自己的 memtable,互不影响。每当 WriteGroup 写完 WAL 之后,就会向 memtable 中去写。具体的写入流程将分为两种情况, !parallel 和 parallel,由 allow_concurrent_memtable_write 来决定。
在没有并行的情况下,Leader 全权负责整个 WriteGroup 的写入,在并行的情况下,Leader 会唤醒该 WriteGroup 中的所有 Writer,然后各自负责自己的写入,并发执行。不管哪种情况,写memtable的入口函数为WriteBatchInternal::InsertInto(),它会根据传入的是 WriteGroup、Writer 还是 WriteBatch 来进行重载。
memtable 写入的具体流程会在源码分析时详细说明:
总结
这里贴两张总结图,是网上找的,版本为 2018年7月11日版本(commit:35b38a232c1d357a7a885b9b4b8442e24a8433d7 ),不过我没搜到这一版。原图所在仓库:https://github.com/wisehead/myrocks_notes
1、当开启 allow_concurrent_memtable_write 并且关闭 pipelined_write 的写入流程图:
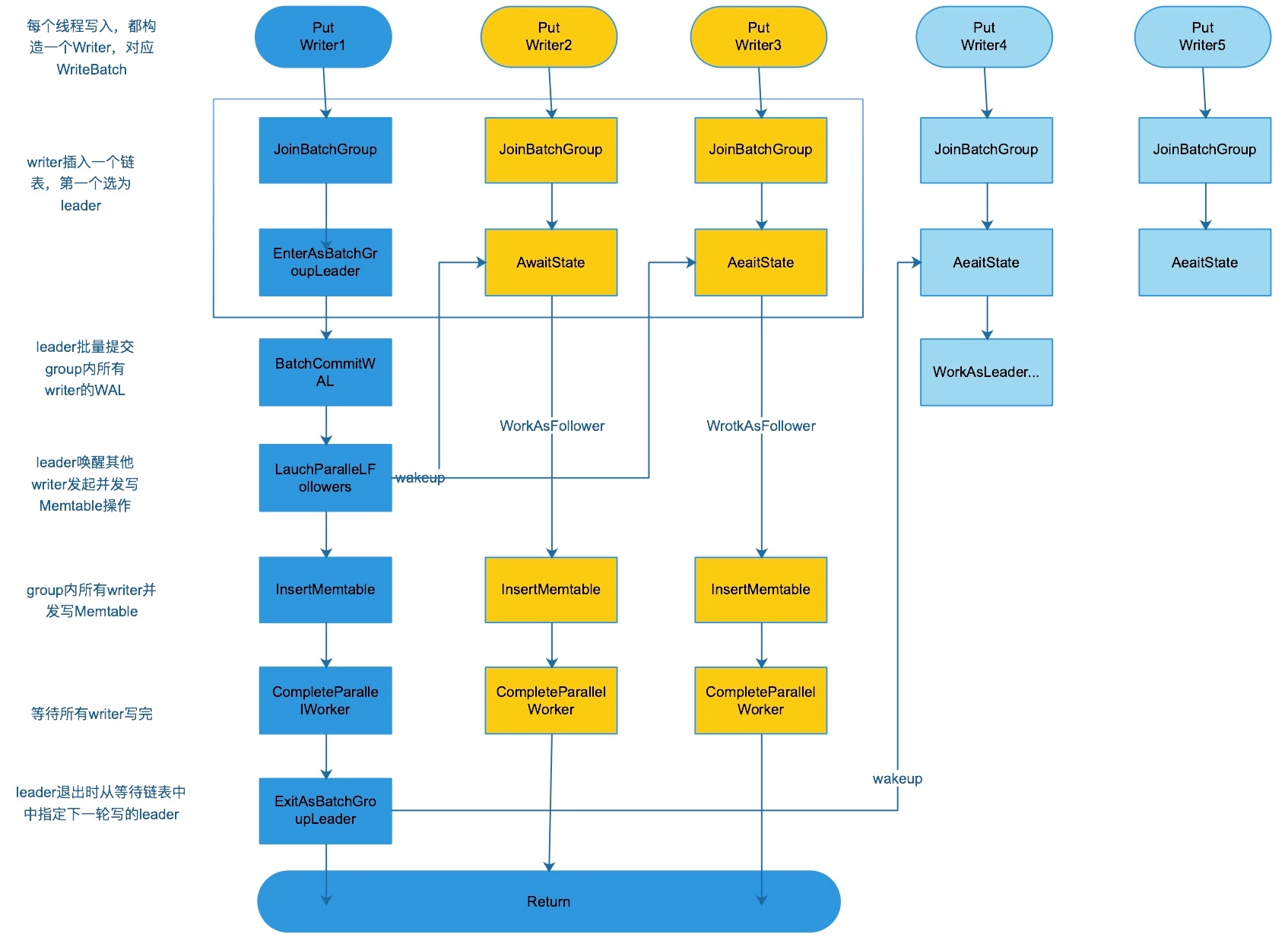
2、从 WriteImpl() 开始的函数调用链图,图片太大了,地址如下:
https://s1.ax1x.com/2022/10/25/xRT6JA.jpg















 2483
2483

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









