






文章目录
- FlushJob::Run()
- FlushJob::WriteLevel0Table()
- BuildTable()
- BlockBasedTableBuilder::Add()
- BlockBasedTableBuilder::Flush()
- BlockBasedTableBuilder::WriteBlock()
- BlockBasedTableBuilder::WriteMaybeCompressedBlock()
- WritableFileWriter::Append()
- WritableFileWriter::Flush()
- WritableFileWriter::WriteDirect()
- PosixWritableFile::PositionedAppend()
- PosixPositionedWrite()
- 回答问题
引流: 个人博客:https://yesiyuan.cn/
本篇博客将以 Flush 为切入口探究 RocksDB 中 SST 的写入流程,函数调用链要一直深入到 pwrite。参考资料较少,几乎纯看源码独自分析,如有错误,希望能私聊我或在评论区指正,一起学习共同进步,谢谢~
带着四个问题进行分析:
- 把调用链找到,从
FlushJob::Run()开始,到pwrite()结束; - 每次调用
pwrite(),写入的大小有什么区别,取决于什么; - 每次构建 SST,会调用多少次
pwrite(),取决于什么; - Flush 和 Compaction 的写入 SST 过程,是否不一样;
FlushJob::Run()
一个 FlushJob 就是一个 Flush 线程,Run() 函数代表 Flush 开始工作,SST 的写入从此开始调用。在调用 Run() 之前,RocksDB 已经通过 PickMemTable() 选出了需要 Flush 的 imm memtable,存放在 FlushJob 对象的相关字段中:
class FlushJob {
// ......
private:
// Variables below are set by PickMemTable():
FileMetaData meta_;
autovector<MemTable*> mems_; // 本次FlushJob负责下刷的imm memtables
VersionEdit* edit_;
Version* base_;
// ......
}
来看 Run() 函数,其内容较多,但大部分都是字段的更新、数据的统计、状态的记录等与核心关系不大的内容。把不重要的都剥离开来,该函数主要就做了一件事:
- 调用
WriteLevel0Table()构建 L0 的 SST;
核心源码如下:
Status FlushJob::Run(LogsWithPrepTracker* prep_tracker, FileMetaData* file_meta,
bool* switched_to_mempurge) {
// ......
if (mempurge_s.ok()) {
base_->Unref();
s = Status::OK();
} else {
// This will release and re-acquire the mutex.
s = WriteLevel0Table();
}
// ......
}
可以看到,其就是通过调用 WriteLevel0Table() 来进行 SST 的构建。注意,此时的调用单位仍然是 FlushJob,即一个 FlushJob 调用一次 WriteLevel0Table()。
FlushJob::WriteLevel0Table()
如其名,该函数负责写入 L0 层的 SST。其源码内容也较多,但大部分是字段的更新和数据的统计,而其核心内容只有两个:
- 调用
BuildTable()来构建 SST,该函数将一直负责到 SST 完全落盘才返回; - 调用
VersionEdit::AddFile()将上一步构建的 SST 加入 L0;
核心源码如下:
Status FlushJob::WriteLevel0Table() {
// ......
std::vector<InternalIterator*> memtables;
// ......
for (MemTable* m : mems_) {
ROCKS_LOG_INFO(
db_options_.info_log,
"[%s] [JOB %d] Flushing memtable with next log file: %" PRIu64 "\n",
cfd_->GetName().c_str(), job_context_->job_id, m->GetNextLogNumber());
memtables.push_back(m->NewIterator(ro, &arena));
auto* range_del_iter = m->NewRangeTombstoneIterator(
ro, kMaxSequenceNumber, true /* immutable_memtable */);
if (range_del_iter != nullptr) {
range_del_iters.emplace_back(range_del_iter);
}
total_num_entries += m->num_entries();
total_num_deletes += m->num_deletes();
total_data_size += m->get_data_size();
total_memory_usage += m->ApproximateMemoryUsage();
}
// ......
ScopedArenaIterator iter(
NewMergingIterator(&cfd_->internal_comparator(), memtables.data(),
static_cast<int>(memtables.size()), &arena));
// ......
s = BuildTable(
dbname_, versions_, db_options_, tboptions, file_options_,
cfd_->table_cache(), iter.get(), std::move(range_del_iters), &meta_,
&blob_file_additions, existing_snapshots_,
earliest_write_conflict_snapshot_, job_snapshot_seq,
snapshot_checker_, mutable_cf_options_.paranoid_file_checks,
cfd_->internal_stats(), &io_s, io_tracer_,
BlobFileCreationReason::kFlush, seqno_to_time_mapping_, event_logger_,
job_context_->job_id, io_priority, &table_properties_, write_hint,
full_history_ts_low, blob_callback_, base_, &num_input_entries,
&memtable_payload_bytes, &memtable_garbage_bytes);
// ......
if (s.ok() && has_output) {
TEST_SYNC_POINT("DBImpl::FlushJob:SSTFileCreated");
// if we have more than 1 background thread, then we cannot
// insert files directly into higher levels because some other
// threads could be concurrently producing compacted files for
// that key range.
// Add file to L0
edit_->AddFile(0 /* level */, meta_.fd.GetNumber(), meta_.fd.GetPathId(),
meta_.fd.GetFileSize(), meta_.smallest, meta_.largest,
meta_.fd.smallest_seqno, meta_.fd.largest_seqno,
meta_.marked_for_compaction, meta_.temperature,
meta_.oldest_blob_file_number, meta_.oldest_ancester_time,
meta_.file_creation_time, meta_.epoch_number,
meta_.file_checksum, meta_.file_checksum_func_name,
meta_.unique_id, meta_.compensated_range_deletion_size);
edit_->SetBlobFileAdditions(std::move(blob_file_additions));
}
// ......
}
其中,AddFile() 暂且不关注,本篇只关注 SST 是如何构建的。
先看第一个 for 循环,mems_ 是 FlushJob 要下刷的所有 imm memtable(以下简称 mem),其元素个数是 1 还是 1+ 这里不管,因为是 PickMemtable() 负责的事情。这里遍历了所有的 mem,并把它们的迭代器全部生成,push 进一个迭代器向量 memtables 中。
接下来,通过 NewMergingIterator() 将这些迭代器合并成一个大的迭代器 iter,该迭代器将涵盖本次 Flush 要负责的所有 k-v。
重点来了,调用 BuildTable() 来构建 SST。可以看到,传入的参数很多,但最重要的是第 7 个参数 iter.get(),即上述生成的大迭代器,SST 输入的所有 k-v 均来源于此。
BuildTable()
该函数位于 builder.cc 中,不属于任何类,所有 rocksdb 命名空间中均可使用它。
BuildTable() 是 Flush 写入 SST 的入口。需要注意的是,BuildTable() 只有 Flush 会调用,Compaction 走的是另外一条线。因为 BuildTable() 是单线程作业,但 Compaction 可能被分为多个 SubCompaction 来多线程作业,所以不能调用线性的 BuildTable()。每一个 SubCompaction 写 SST 的入口函数名为 ProcessKeyValueCompaction(),这里不去分析它,因为到 BlockBasedTableBuilder::Add() 的那一步还是会进入相同的调用链。
只关注 BuildTable() 函数的核心部分,其主要工作如下:
- 创建 SST 文件,通过 OS;
- 构建 SST 的 TableBuilder,名为 builder;
- 将 iter 重新封装一下,名为 c_iter;
- 通过 c_iter 一条条取出 k-v 对,通过
builder->Add()往 SST 中写 k-v 对; builder->Finish()收尾;
在解释代码之前,要先说明一点。builder 中的落盘是实时的,而不是通过 Finish() 进行统一落盘。每一次 Add() 都会查看已经写入的大小(暂存在内存中)是否超过一个 block_size_,如果是,就将该 data block 落盘。Finish() 的工作只是将 SST 除了 data block 之外的内容落盘,包括 meta block、metaindex block、footer。
通过打印日志可知,默认的 block_size 为 4KB
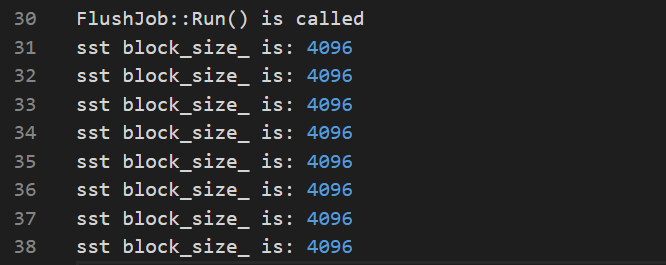
BuildTable() 核心源码如下:
Status BuildTable(
const std::string& dbname, VersionSet* versions,
const ImmutableDBOptions& db_options, const TableBuilderOptions& tboptions,
const FileOptions& file_options, TableCache* table_cache,
InternalIterator* iter,
std::vector<std::unique_ptr<FragmentedRangeTombstoneIterator>>
range_del_iters,
FileMetaData* meta, std::vector<BlobFileAddition>* blob_file_additions,
std::vector<SequenceNumber> snapshots,
SequenceNumber earliest_write_conflict_snapshot,
SequenceNumber job_snapshot, SnapshotChecker* snapshot_checker,
bool paranoid_file_checks, InternalStats* internal_stats,
IOStatus* io_status, const std::shared_ptr<IOTracer>& io_tracer,
BlobFileCreationReason blob_creation_reason,
const SeqnoToTimeMapping& seqno_to_time_mapping, EventLogger* event_logger,
int job_id, const Env::IOPriority io_priority,
TableProperties* table_properties, Env::WriteLifeTimeHint write_hint,
const std::string* full_history_ts_low,
BlobFileCompletionCallback* blob_callback, Version* version,
uint64_t* num_input_entries, uint64_t* memtable_payload_bytes,
uint64_t* memtable_garbage_bytes) {
// ......
// iter使用前都要SeekToFirst
iter->SeekToFirst();
// ......
// 创建SST文件
IOStatus io_s = NewWritableFile(fs, fname, &file, file_options);
// ......
// 生成TableBuilder
TableBuilder* builder;
builder = NewTableBuilder(tboptions, file_writer.get());
// ......
// 重新封装iter
CompactionIterator c_iter(
iter, ucmp, &merge, kMaxSequenceNumber, &snapshots,
earliest_write_conflict_snapshot, job_snapshot, snapshot_checker, env,
ShouldReportDetailedTime(env, ioptions.stats),
true /* internal key corruption is not ok */, range_del_agg.get(),
blob_file_builder.get(), ioptions.allow_data_in_errors,
ioptions.enforce_single_del_contracts,
/*manual_compaction_canceled=*/kManualCompactionCanceledFalse,
/*compaction=*/nullptr, compaction_filter.get(),
/*shutting_down=*/nullptr, db_options.info_log, full_history_ts_low);
// ......
// 从c_iter中逐条取出k-v对,插入SST
c_iter.SeekToFirst();
for (; c_iter.Valid(); c_iter.Next()) {
const Slice& key = c_iter.key();
const Slice& value = c_iter.value();
const ParsedInternalKey& ikey = c_iter.ikey();
builder->Add(key, value);
// .......
}
// ......
// 收尾
s = builder->Finish();
// ......
}
可以看出,调用链由 BuilderTable() 转移至 Add(),调用单位由 FlushJob 转变为每条 k-v 对。接下来,开始分析 Add() 是怎么让 k-v 落盘的。
BlockBasedTableBuilder::Add()
在分析该函数前,需要去了解 RocksDB 的 SST 格式,和 LevelDB 基本相同,由 data block、meta block、metaindex block、footer 这四个部分组成,网上一搜资料一堆,这里就不细说了。其中,Add() 就是插入并落盘 data block 的。
先来看看 BlockBasedTableBuilder 类(以下统称 TableBuilder)的核心字段:
class BlockBasedTableBuilder : public TableBuilder {
// .......
private:
struct Rep;
Rep* rep_;
// .......
}
Rep 封装了最核心的内容,其中有两个字段叫作 data_block 和 flush_block_policy:
struct BlockBasedTableBuilder::Rep {
// ......
private:
BlockBuilder data_block;
std::unique_ptr<FlushBlockPolicy> flush_block_policy;
// ......
}
而 FlushBlockPolicy 是一个抽象类,其默认的实现类为 FlushBlockBySizePolicy,部分内容如下:
class FlushBlockBySizePolicy : public FlushBlockPolicy {
// ......
private:
const uint64_t block_size_;
const uint64_t block_size_deviation_limit_;
const bool align_;
const BlockBuilder& data_block_builder_;
// ......
}
至此,我们可以知道的是,一个 TableBuilder 在内存中只会暂存一个 data block,而 SST 是有很多 data block 连续构成的,为什么只需要暂存一个呢?这就是 SST 的写入逻辑,满一个 data block 就落盘一个。具体的逻辑,让我们来分析 Add() 函数,其核心流程如下:
- 调用
r->flush_block_policy->Update()判断是否需要落盘; - 如果是,则调用
Flush()来将 data block 落盘,继续; - 调用
r->data_block.AddWithLastKey()将 k-v 追加进暂存于内存的 data block 中;
核心源码如下:
void BlockBasedTableBuilder::Add(const Slice& key, const Slice& value) {
Rep* r = rep_;
// ......
auto should_flush = r->flush_block_policy->Update(key, value);
if (should_flush) {
// ......
Flush();
// ......
}
// ......
r->data_block.AddWithLastKey(key, value, r->last_key);
r->last_key.assign(key.data(), key.size());
// ......
}
先来看一下 Update() 的判断逻辑,完整源码如下:
bool Update(const Slice& key, const Slice& value) override {
// it makes no sense to flush when the data block is empty
if (data_block_builder_.empty()) {
return false;
}
auto curr_size = data_block_builder_.CurrentSizeEstimate();
// Do flush if one of the below two conditions is true:
// 1) if the current estimated size already exceeds the block size,
// 2) block_size_deviation is set and the estimated size after appending
// the kv will exceed the block size and the current size is under the
// the deviation.
std::cout << "sst block_size_ is: " << block_size_ << std::endl;
return curr_size >= block_size_ || BlockAlmostFull(key, value);
}
可以看到,其逻辑就是判断暂存于内存中的 data block 大小是否达到阈值 block_size_,即使是 BlockAlmostFull() 也是通过 block_size _ 来进行比较。到这里,就可以梳理清 Add() 的逻辑了:
- 以 data block 在内存中暂存数据,每当其大小超过 block_size_ 后,调用
Flush()将其落盘,一旦落盘,这片内存就会清空用作接下来写入 k-v 的缓冲区。每一次判断落盘的时机在Add()调用的最初期,每一个 k-v 对都是先加入 data block 缓冲区,满了再一并落盘的。
因此,调用链由 Add() 转移至 Flush(),调用单位也由 k-v 对转变为 data block。
BlockBasedTableBuilder::Flush()
注意区分这个 Flush 和 LSM-Tree 的 Flush 完全是两个东西,只是名字一样而已。其源码很简单,如下:
// data_block的落盘
void BlockBasedTableBuilder::Flush() {
Rep* r = rep_;
assert(rep_->state != Rep::State::kClosed);
if (!ok()) return;
if (r->data_block.empty()) return;
if (r->IsParallelCompressionEnabled() &&
r->state == Rep::State::kUnbuffered) {
r->data_block.Finish();
ParallelCompressionRep::BlockRep* block_rep = r->pc_rep->PrepareBlock(
r->compression_type, r->first_key_in_next_block, &(r->data_block));
assert(block_rep != nullptr);
r->pc_rep->file_size_estimator.EmitBlock(block_rep->data->size(),
r->get_offset());
r->pc_rep->EmitBlock(block_rep);
} else {
WriteBlock(&r->data_block, &r->pending_handle, BlockType::kData);
}
}
可以看到,就是调用 WriteBlock() 来将一整个 data block 落盘。
BlockBasedTableBuilder::WriteBlock()
该函数会首先对 data block 进行一此压缩,以降低其大小,接着就是调用另一个 WriteBlock() 来进一步写入了,源码比较简单,如下:
void BlockBasedTableBuilder::WriteBlock(BlockBuilder* block,
BlockHandle* handle,
BlockType block_type) {
block->Finish();
std::string uncompressed_block_data;
uncompressed_block_data.reserve(rep_->table_options.block_size);
block->SwapAndReset(uncompressed_block_data);
if (rep_->state == Rep::State::kBuffered) {
assert(block_type == BlockType::kData);
rep_->data_block_buffers.emplace_back(std::move(uncompressed_block_data));
rep_->data_begin_offset += rep_->data_block_buffers.back().size();
return;
}
WriteBlock(uncompressed_block_data, handle, block_type);
}
新调用的 WriteBlock() 也是对更进一步的调用进行封装,完整源码如下:
void BlockBasedTableBuilder::WriteBlock(const Slice& uncompressed_block_data,
BlockHandle* handle,
BlockType block_type) {
Rep* r = rep_;
assert(r->state == Rep::State::kUnbuffered);
Slice block_contents;
CompressionType type;
Status compress_status;
bool is_data_block = block_type == BlockType::kData;
CompressAndVerifyBlock(uncompressed_block_data, is_data_block,
*(r->compression_ctxs[0]), r->verify_ctxs[0].get(),
&(r->compressed_output), &(block_contents), &type,
&compress_status);
r->SetStatus(compress_status);
if (!ok()) {
return;
}
// 这里
WriteMaybeCompressedBlock(block_contents, type, handle, block_type,
&uncompressed_block_data);
r->compressed_output.clear();
if (is_data_block) {
r->props.data_size = r->get_offset();
++r->props.num_data_blocks;
}
}
可以看到,调用链转移至 WriteMaybeCompressedBlock,调用单位仍然没变。
BlockBasedTableBuilder::WriteMaybeCompressedBlock()
该函数有点长,但核心就几句话,通过对 file 进行 Append 来将 data block,核心源码如下:
void BlockBasedTableBuilder::WriteMaybeCompressedBlock(
const Slice& block_contents, CompressionType type, BlockHandle* handle,
BlockType block_type, const Slice* uncompressed_block_data) {
// ......
{
IOStatus io_s = r->file->Append(block_contents);
if (!io_s.ok()) {
r->SetIOStatus(io_s);
return;
}
}
// ......
}
至此,调用链转移至 Append() ,但是调用单位仍然为 data block。
WritableFileWriter::Append()
该函数位于类 WritableFileWriter,其也是通过缓冲区 buf_ 来缓存一定的写入:
class WritableFileWriter {
// ......
private:
AlignedBuffer buf_;
// ......
}
首先,写入分为 direct_io 和非 direct_io,其是两个分支,但不管是哪个都需要用到 buf_。这里我们只分析 direct_io 的情况,相对简单些。Append 的主要流程如下:
- 对写入进行一定的准备工作;
- 判断 buf_ 剩余的空间够不够传进来的 data block 写入,如果不够,分配更多的空间,当然,不能一直分配,有个上限,叫作 max_buffer_size_;
- 如果没有 direct_io,xxx(这里先不考虑),后续都是 direct_io 的分支;
- 再次判断 buf_ 的空间够不够,如果 buf_ 的空间足够,把传进来的 data block 给 Append() 进去;
- 如果不够,一点点将 data block 给 Append() 进去。注意,什么叫
一点点,而不是全部 Append()。Append() 函数最高只能将 buf_ 追加到上限,因此到 buf_ 空间不够时,剩余多少就追加多少。 - 继续 5,如果 data block 还有剩,说明 buf_ 满了,需要落盘,这是就调用 Flush() 将其落盘,然后清空 buf_,将剩下的 data block 追加进去。
核心源码如下:
IOStatus WritableFileWriter::Append(const Slice& data, uint32_t crc32c_checksum,
Env::IOPriority op_rate_limiter_priority) {
// ......
// 要写入的 data block
const char* src = data.data();
size_t left = data.size();
// ......
// 准备工作
{
IOOptions io_options;
io_options.rate_limiter_priority =
WritableFileWriter::DecideRateLimiterPriority(
writable_file_->GetIOPriority(), op_rate_limiter_priority);
IOSTATS_TIMER_GUARD(prepare_write_nanos);
TEST_SYNC_POINT("WritableFileWriter::Append:BeforePrepareWrite");
writable_file_->PrepareWrite(static_cast<size_t>(GetFileSize()), left,
io_options, nullptr);
}
// 判断是否需要分配给 buf 更多的空间
// See whether we need to enlarge the buffer to avoid the flush
if (buf_.Capacity() - buf_.CurrentSize() < left) {
for (size_t cap = buf_.Capacity();
cap < max_buffer_size_; // There is still room to increase
cap *= 2) {
// See whether the next available size is large enough.
// Buffer will never be increased to more than max_buffer_size_.
size_t desired_capacity = std::min(cap * 2, max_buffer_size_);
if (desired_capacity - buf_.CurrentSize() >= left ||
(use_direct_io() && desired_capacity == max_buffer_size_)) {
buf_.AllocateNewBuffer(desired_capacity, true);
break;
}
}
}
// ......
if (perform_data_verification_ && buffered_data_with_checksum_ &&
crc32c_checksum != 0) {
// Since we want to use the checksum of the input data, we cannot break it
// into several pieces. We will only write them in the buffer when buffer
// size is enough. Otherwise, we will directly write it down.
if (use_direct_io() || (buf_.Capacity() - buf_.CurrentSize()) >= left) {
if ((buf_.Capacity() - buf_.CurrentSize()) >= left) {
// 分支1:buf_空间够
size_t appended = buf_.Append(src, left);
if (appended != left) {
s = IOStatus::Corruption("Write buffer append failure");
}
buffered_data_crc32c_checksum_ = crc32c::Crc32cCombine(
buffered_data_crc32c_checksum_, crc32c_checksum, appended);
} else {
// 分支2:direct_io但buf_空间不够
while (left > 0) {
size_t appended = buf_.Append(src, left);
buffered_data_crc32c_checksum_ =
crc32c::Extend(buffered_data_crc32c_checksum_, src, appended);
left -= appended;
src += appended;
if (left > 0) {
s = Flush(op_rate_limiter_priority);
if (!s.ok()) {
break;
}
}
}
}
} else {
// 分支3:没有direct_io且buf_空间不够
assert(buf_.CurrentSize() == 0);
buffered_data_crc32c_checksum_ = crc32c_checksum;
s = WriteBufferedWithChecksum(src, left, op_rate_limiter_priority);
}
}
// ......
}
可以看到,重点在于 while (left > 0) 部分,该循环体意为:buf_ 满了就下刷,没满就不管。因此,调用链转移至 WritableFileWriter::Flush() ,调用单位由 data block 转移至 WritableFileWriter 中的 buf_ 。注意,调用 Flush() 时传递了个参数名为 op_rate_limiter_priority,这个时 RocksDB 的限制器,介绍可以翻阅 RocksDB 的 Wiki:RocksDB 的 Rate Limiter。参数很关键,直接决定该函数本次要调用多少次 pwrite()。
WritableFileWriter::Flush()
它仅仅是一层封装而已,核心源码如下:
IOStatus WritableFileWriter::Flush(Env::IOPriority op_rate_limiter_priority) {
// ......
if (buf_.CurrentSize() > 0) {
if (use_direct_io()) {
if (pending_sync_) {
if (perform_data_verification_ && buffered_data_with_checksum_) {
s = WriteDirectWithChecksum(op_rate_limiter_priority);
} else {
s = WriteDirect(op_rate_limiter_priority);
}
}
} else {
if (perform_data_verification_ && buffered_data_with_checksum_) {
s = WriteBufferedWithChecksum(buf_.BufferStart(), buf_.CurrentSize(),
op_rate_limiter_priority);
} else {
s = WriteBuffered(buf_.BufferStart(), buf_.CurrentSize(),
op_rate_limiter_priority);
}
}
if (!s.ok()) {
set_seen_error();
return s;
}
}
// ......
}
其中,WriteDirectWithChecksum() 和 WriteDirect() 内容几乎一样,只是前者多了校验和的内容。我们看后者即可,至此,调用链转移至 WriteDirect() ,调用单位仍然为 WritableFileWriter 中的 buf_。
WritableFileWriter::WriteDirect()
该函数的工作为:一点一点 地逐步将 buf_ 给写入文件,具体每次写多少,由传入的 op_rate_limiter_priority 来决定,直接看源码吧,核心内容如下:
// This flushes the accumulated data in the buffer. We pad data with zeros if
// necessary to the whole page.
// However, during automatic flushes padding would not be necessary.
// We always use RateLimiter if available. We move (Refit) any buffer bytes
// that are left over the
// whole number of pages to be written again on the next flush because we can
// only write on aligned
// offsets.
IOStatus WritableFileWriter::WriteDirect(
Env::IOPriority op_rate_limiter_priority) {
// ......
size_t left = buf_.CurrentSize();
// ......
// 开始写入
while (left > 0) {
size_t size = left;
// 从IO限制器中得到本次写入的大小
if (rate_limiter_ != nullptr &&
rate_limiter_priority_used != Env::IO_TOTAL) {
size = rate_limiter_->RequestToken(left, buf_.Alignment(),
rate_limiter_priority_used, stats_,
RateLimiter::OpType::kWrite);
}
// ......
{
// 执行写入
if (perform_data_verification_) {
Crc32cHandoffChecksumCalculation(src, size, checksum_buf);
v_info.checksum = Slice(checksum_buf, sizeof(uint32_t));
s = writable_file_->PositionedAppend(Slice(src, size), write_offset,
io_options, v_info, nullptr);
} else {
s = writable_file_->PositionedAppend(Slice(src, size), write_offset,
io_options, nullptr);
}
}
// ......
}
}
可以看到,rate_limiter 分配的 size,就是 PositionedAppend() 一次要写入的 size。至此,调用链转移至 PositionedAppend() ,调用单位由 buf_ 转移至 rate_limiter 分配的 size。但是,RequestToken() 是如何分配的,我暂时还没弄明白,这点就要去深究 rate_limiter 的逻辑了。
PosixWritableFile::PositionedAppend()
该函数就是一层简单的封装,完整源码如下:
IOStatus PosixWritableFile::PositionedAppend(const Slice& data, uint64_t offset,
const IOOptions& /*opts*/,
IODebugContext* /*dbg*/) {
if (use_direct_io()) {
assert(IsSectorAligned(offset, GetRequiredBufferAlignment()));
assert(IsSectorAligned(data.size(), GetRequiredBufferAlignment()));
assert(IsSectorAligned(data.data(), GetRequiredBufferAlignment()));
}
assert(offset <= static_cast<uint64_t>(std::numeric_limits<off_t>::max()));
const char* src = data.data();
size_t nbytes = data.size();
if (!PosixPositionedWrite(fd_, src, nbytes, static_cast<off_t>(offset))) {
return IOError("While pwrite to file at offset " + std::to_string(offset),
filename_, errno);
}
filesize_ = offset + nbytes;
return IOStatus::OK();
}
至此,调用链转移至 PosixPositionedWrite() ,调用单位没变。
PosixPositionedWrite()
恭喜,到这一步,调用链就结束了,这是对 pwrite() 的最后一层封装。直接上源码:
bool PosixPositionedWrite(int fd, const char* buf, size_t nbyte, off_t offset) {
const size_t kLimit1Gb = 1UL << 30;
const char* src = buf;
size_t left = nbyte;
while (left != 0) {
size_t bytes_to_write = std::min(left, kLimit1Gb);
// ysy add
std::cout << "pwrite is called, content size is " << strlen(buf) << std::endl;
ssize_t done = pwrite(fd, src, bytes_to_write, offset);
if (done < 0) {
if (errno == EINTR) {
continue;
}
return false;
}
left -= done;
offset += done;
src += done;
}
return true;
}
可以看到,最终调用了 pwrite(),一次写入的大小就是上一步 rate_limiter 分配的 size。
至此,SST 构建的骨架函数调用链分析完毕。
回答问题
- Flush 构建 SST 的函数调用链。
答:FlushJob::Run() -> FlushJob::WriteLevel0Table() -> BuildTable() -> BlockBasedTableBuilder::Add() -> BlockBasedTableBuilder::Flush() -> BlockBasedTableBuilder::WriteBlock() -> BlockBasedTableBuilder::WriteMaybeCompressedBlock() -> WritableFileWriter::Append() -> WritableFileWriter::Flush() -> WritableFileWriter::WriteDirect() -> PosixWritableFile::PositionedAppend() -> PosixPositionedWrite() -> pwrite()
- 每次调用
pwrite(),传递的参数有什么区别,取决于什么;
答:传递的参数由 rate_limiter 决定,这个值是不固定的,不管是否开启 direct_io 均是不固定的,可以通过在 pwrite 之前打日志看到。
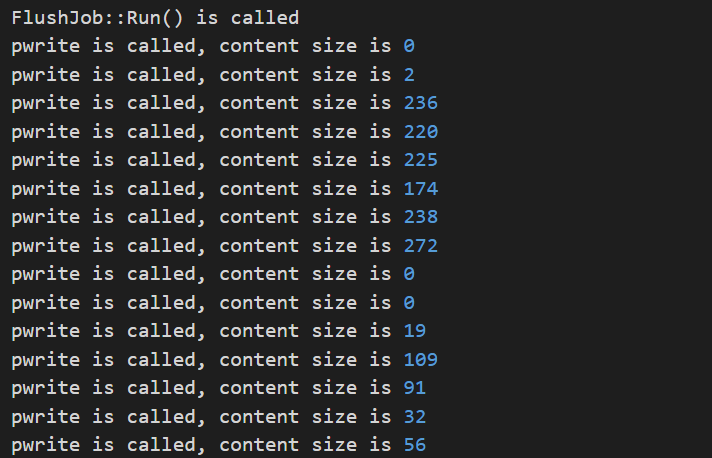
具体的分配我还没有弄清,与 rate_limiter 的策略有关,要看 RequestToken() 是怎么实现的,这点我后续会分析,将在下一篇博客中记录分析以及实验结果。
- 每次构建 SST,会调用多少次
pwrite(),取决于什么
答:由于每次 pwrite 是按照 rate_limiter 分配的 size 进行调用的,而每一次大小实际与 SST 的大小无关。只能说,当这些 size 刚好把 SST 全部写完后,就算完毕。因此,目标 SST 越大,或者说传入的 k-v 对越多,那么 pwrite() 的次数就越多。
- Flush 和 Compaction 的写入 SST 过程,是否不一样;
答:不一样。
- 入口不一样。Flush 的入口为 BuildTable() ,而 Compaction 的入口为 ProcessKeyValueCompaction()。因为 Compaction 可能被分为多个 SubCompaction,所以不能调用线性的 BuildTable(),要处理的事情多了很多。但是,二者会在 BlockBasedTableBuilder::Add() 处交汇,即向 SST 中插入 k-v 对的方式还是一样的。从 Add() 开始,两者使用相同的调用链。
- pwrite 的 size 不一样。每次 pwrite 的 size 由 rate_limiter 分配(RequestToken),rate_limiter 是用来区分优先级的,因此其会按照不同的优先级去给 Flush 或者 Compaction 分配不同的 size。















 3088
3088











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









