






多语言协同的视频连续手语识别
问题1:多语言识别问题;
创新点、解决方法:不同手语有共享的视觉模式,提出了一种多语言手语识别框架。
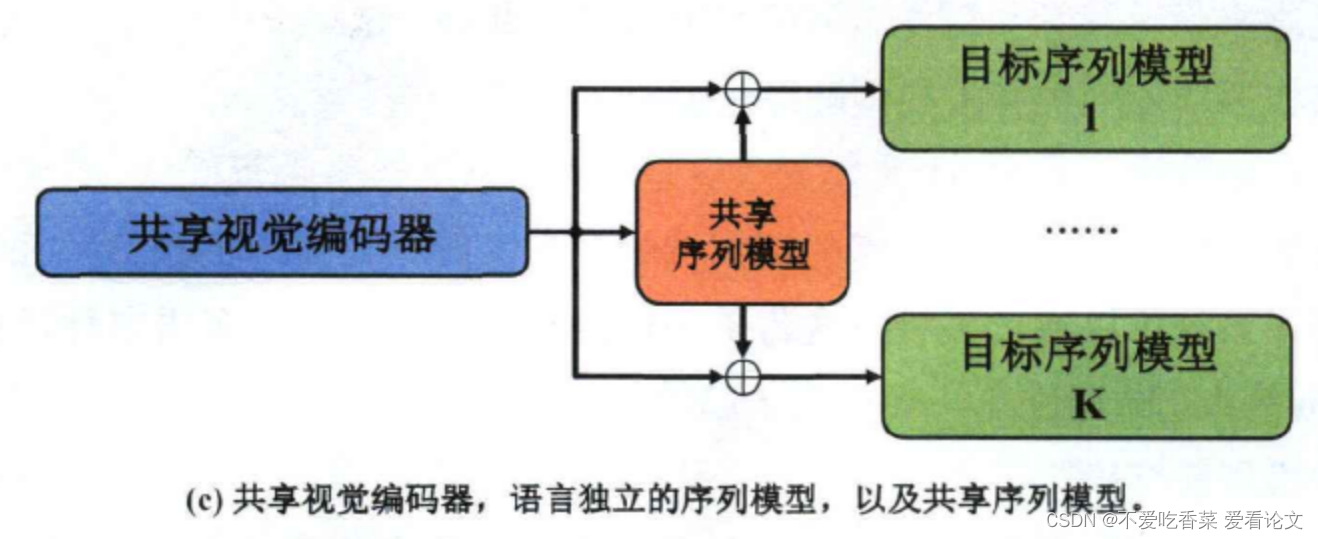
模型:一个共享的视觉特征编码器+多个针对不同语言的时序编码器+一个用于学习语言共性的通用时序编码器。
之前为了解决多语言识别问题,都是在相同的网络框架上训练若干个针对不同手语语种的模型参数,虽然能取得一定的效果,但是忽略了不同手语之间存在相似的视觉模式的问题,分开独立训练的做法也不利于模型对手语共性的挖掘。
流程:使用一个公共的视觉特征编码器提取特征表达,对于不同语种的手语,使用不同的时序建模网络学习对应手语语言特性,使用一个共享的时序编码器来表达不同手语语种之间相同的视觉模式
框架示意图:
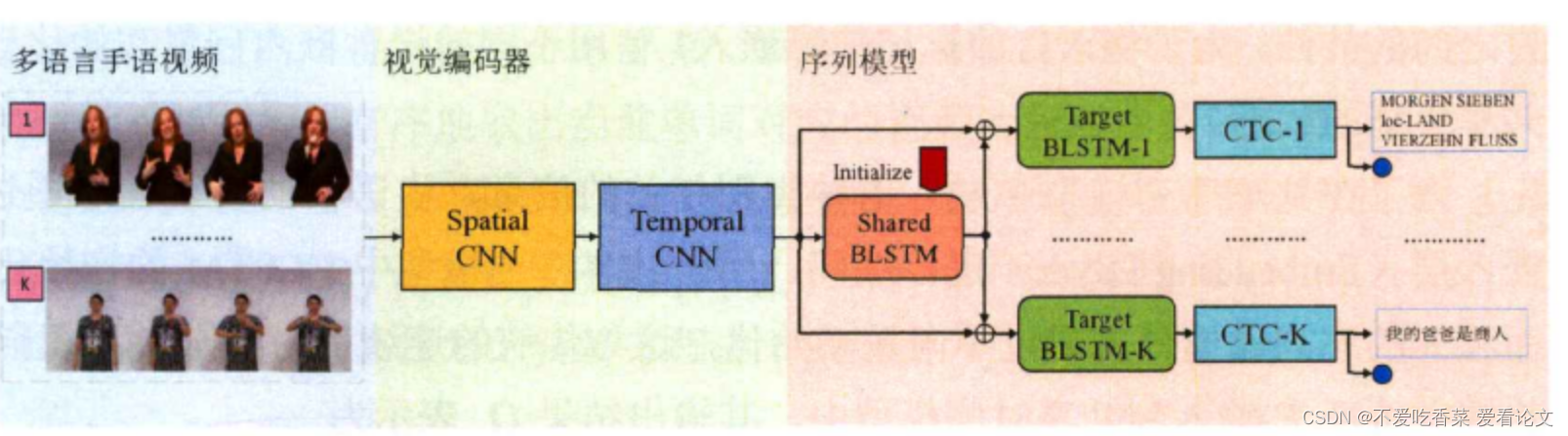
使用CNN-TCN用于特征提取,采用BLSTM作为序列模型,去学习视觉特征和手语词之间的对用关系。
手语识别模型:
迭代示意图:
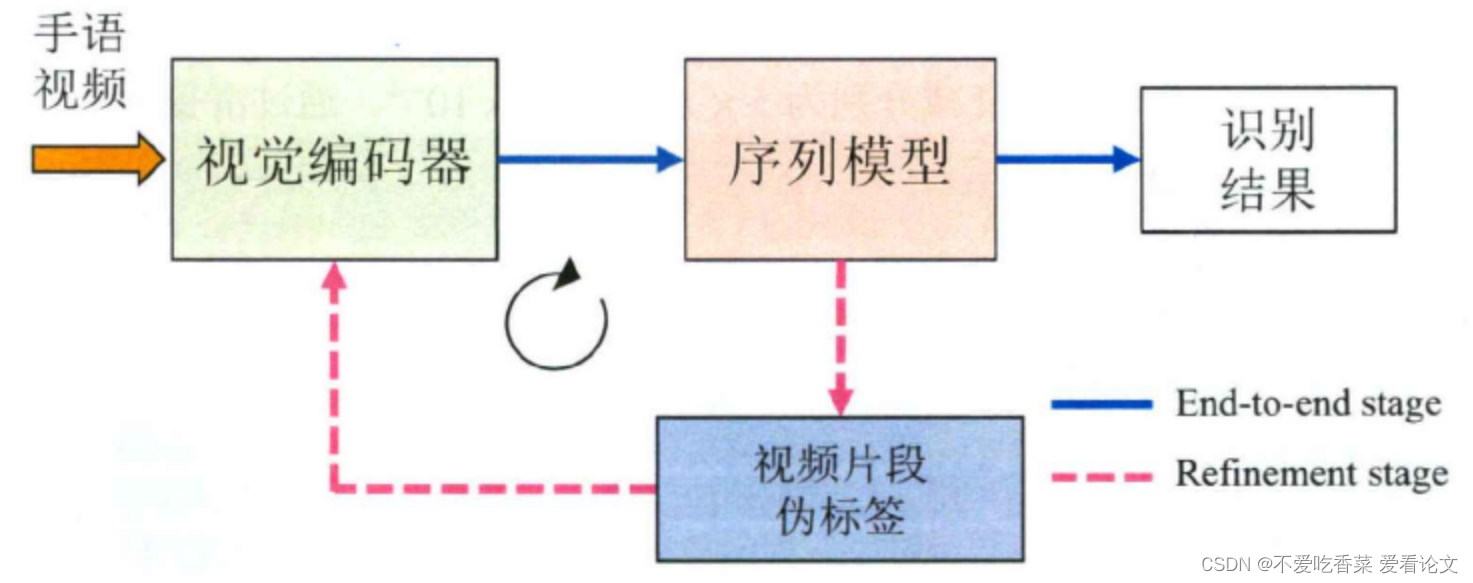
在网络优化时,提出基于最大概率路径的动态规划算法解码算法,提取视频与标注序列之间的对齐关系,用于视觉编码器的微和进一步的优化。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









