






目录
一、实验要求
理解程序设计的整体框架
理解感知音频编码的设计思想
- 两条线
- 时-频分析的矛盾
理解心理声学模型的实现过程
- 临界频带的概念
- 掩蔽值计算的思路
理解码率分配的实现思路
二、实验原理
1.感知音频编码
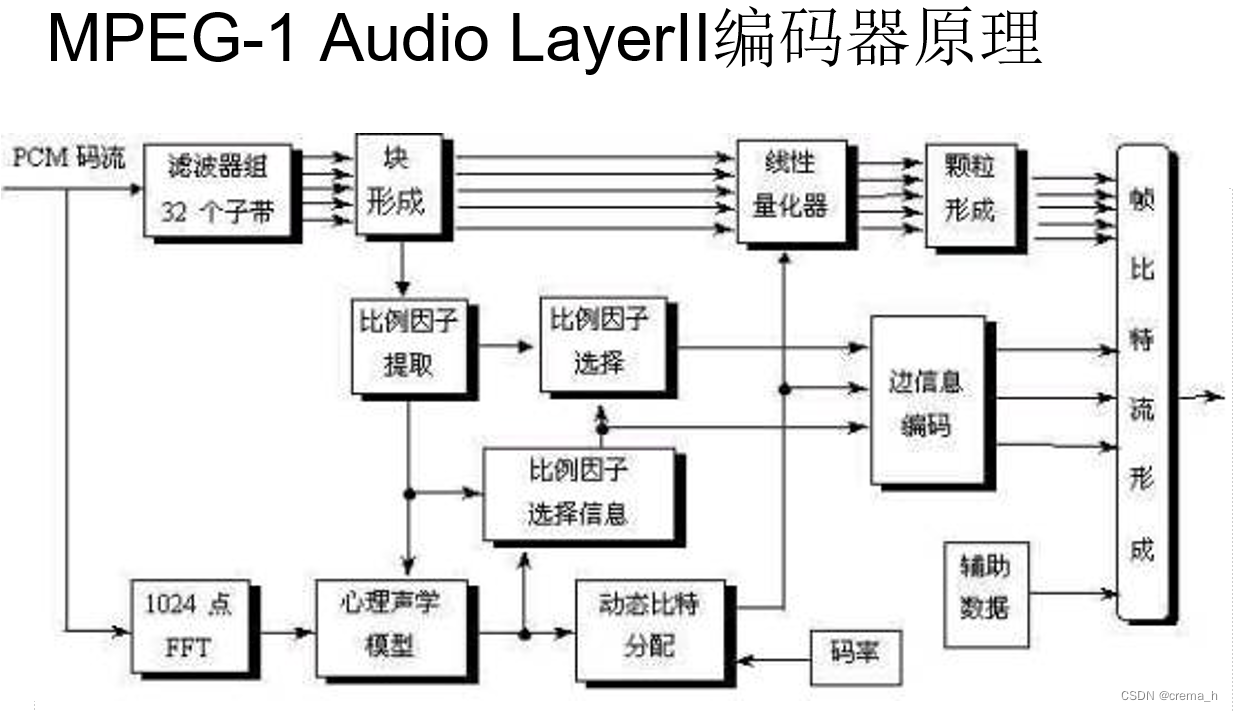
两条线
主干(子代分解):以1152个样本为单位,输入到滤波器组中进行32个子带的分解,即以32个样本为一个时间窗口,做36次自带分解,形成36个样本,形成以12个样本为单位的3个块(以12个样本为观察组,之间的差别不大),以此进行比例因子的提取和选择,通过频域分析线路的辅助,进行后续的量化等工作。
辅助(频域分析):输入的PCM码流进行1024点FFT变换,经过心理声学模型去除信号中被掩蔽的部分,确定动态比特分配和比例因子选择信息。最后相关信息进行边信息编码,一起封装成帧比特流进行传输。
时-频分析矛盾
时域分辨力和频域分辨力互相矛盾,增大频域分辨力的同时时域分辨力便相应减小。
根据这一矛盾,MPEG-1音频编码采取措施:通过子带分析滤波器组使信号具有高的时间分辨率,确保在短暂冲击信号情况下,编码的声音信号具有足够高的质量又可以使信号通过FFT运算具有高的频率分辨率,因为掩蔽阈值是从功率谱密度推出来的。
2.心理声学模型实现过程
心理声学模型所遵循原理即为人耳的听觉特性。对于特定的音频,人耳的感知存在一个听觉阈值电平,低于此电平的声音信号就听不到。故一个人是否听到声音取决于声音的频率,以及声音的幅度是否高于这种频率下的听觉阈值。同时,听觉阈值电平的大小也会随声音频率的改变而改变。
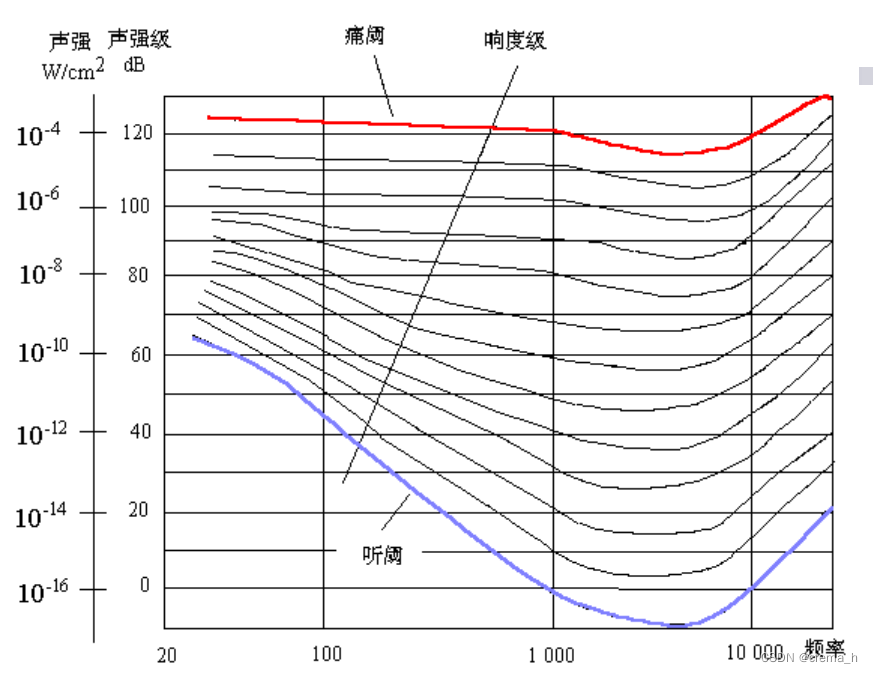
对于频率接近的音频分量,其中一个较强的频率成分会导致周围频率成分的听觉阈值升高,即为听觉掩蔽效应。
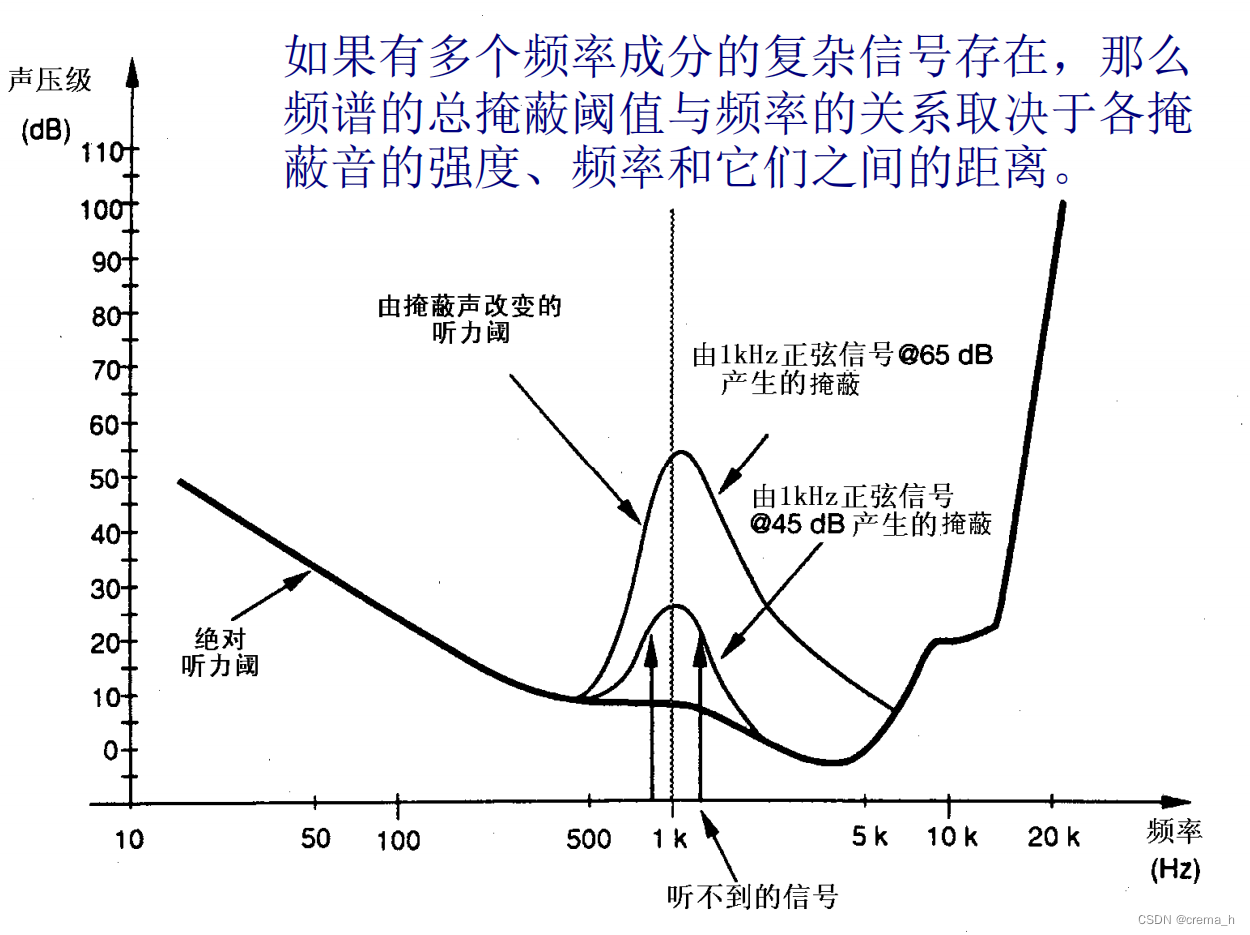
而当某个纯音被以它为中心频率、且具有一定带宽的连续噪声所掩蔽时,如果该纯音刚好被听到时的功率等于这一频带内的噪声功率,则这个带宽被称为临界频带宽度。换句话讲,纯音的听阈随着掩蔽噪声的带宽增大而增高,但当噪声的带宽达到临界频带后,纯音的听阈就不会再改变。凭借此规律,可以把听觉系统等效为多个固定临界频带所组合成的滤波器组。当聆听到多个频率特性的声音时,只要信噪比达到当前所在滤波器中的听阈,即可听到该频率成分。

MPEG-I 标准定义了两个模型
- 心理声学模型1: 计算复杂度低;但对假设用户听不到的部分压缩太严重
- 心理声学模型2 : 提供了适合Layer III编码的更多特征
心理声学模型1的实现
①将样本变换到频域
采用Hann加权和DFT,512 (Layer I) 或1024 (Layers II and III)样本窗口
②确定声压级别
子带n的声压级别计算包含了子带n频谱线的声压级别及该子带最大缩放因子。
③考虑安静时阈值
也即绝对阈值。在标准中有根据输入PCM信号的采样率编制的“频率、临界频带率和绝对阈值”表
④将音频信号分解成“乐音(tones)” 和“非乐音/噪声”部分
因为两种信号的掩蔽能力不同,根据音频频谱的局部功率最大值确定乐音成分局部峰值为乐音,然后将本临界频带内的剩余频谱合在一起,组成一个代表噪声频率(无调成份)。
⑤音调和非音调掩蔽成分的消除
利用标准中给出的绝对阈值消除被掩蔽成分;考虑在每个临界频带内,小于0.5Bark的距离中只保留最高功率的成分。
⑥单个掩蔽阈值的计算
音调成分和非音调成分单个掩蔽阈值根据标准中给出的算法求得。
⑦全局掩蔽阈值的计算
某一频率点的总掩蔽值可通过该点的绝对掩蔽值与单独掩蔽阈值相加获得。
⑧每个子带的掩蔽阈值
选择出本子带中最小的阈值作为子带阈值
⑨计算每个子带信号掩蔽比(signal-to-mask ratio, SMR)
SMR = 信号能量 / 掩蔽阈值,并将SMR传递给编码单元
此时编码上下两条线,上线均匀32个子带,计算了每个子带的声压级(能量);下线低频一个子带可能包含多个临界频带,高频一个临界频带可能包含多个子带。以临界频带为单位,低频密,高频疏。计算了掩蔽阈值。由此可计算出SMR。
3.码率分配实现思路
目的:使整帧和每个子带的总噪声—掩蔽比MNR最小
在调整到固定的码率之前
- 先确定可用于样值编码的有效比特数。
- 这个数值取决于比例因子、比例因子选择信息、比特分配信息以及辅助数据所需比特数。
比特分配的过程
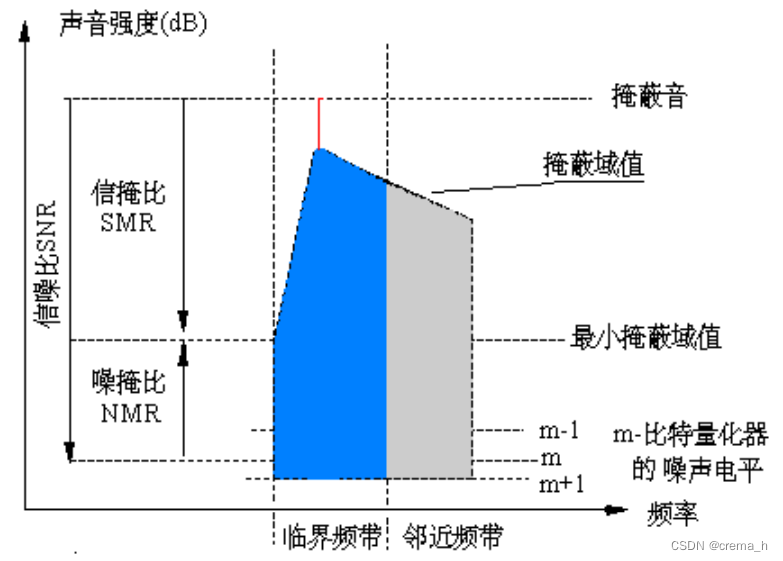
- 对每个子带计算噪声-掩蔽比MNR,信噪比SNR–信掩比SMR NMR=SMR–SNR(dB)
对最高NMR的子带分配比特,每提升1比特,信噪比提升6dB。
三、实验程序设计与结果
- main函数
int main(int argc, char** argv)
{
/********************************参数初始化***************************************************/
programName = argv[0];//argv[0]表示输入文件
if (argc == 1)
short_usage();
else
parse_args(argc, argv, &frame, &model, &num_samples, original_file_name,
encoded_file_name);//解析命令行参数
print_config(&frame, &model, original_file_name, encoded_file_name);//输出配置信息
hdr_to_frps(&frame);//加载信息头中解压出来的信息
nch = frame.nch;
error_protection = header.error_protection;
//按帧获取信息
while (get_audio(musicin, buffer, num_samples, nch, &header) > 0) {
if (glopts.verbosity > 1)
if (++frameNum % 10 == 0)
fprintf(stderr, "[%4u]\r", frameNum);
fflush(stderr);
win_buf[0] = &buffer[0][0];
win_buf[1] = &buffer[1][0];
adb = available_bits(&header, &glopts);//在码率分配前首先要计算码率预算,把计算所得的该帧总分配比特数赋给了adb,在adb获得值以后直接进行输出。
lg_frame = adb / 8;
if (header.dab_extension) {
if (header.sampling_frequency == 1)
header.dab_extension = 4;
if (frameNum == 1)
minimum = lg_frame + MINIMUM;
adb -= header.dab_extension * 8 + header.dab_length * 8 + 16;
}
{
int gr, bl, ch;
for (gr = 0; gr < 3; gr++)
for (bl = 0; bl < 12; bl++)
for (ch = 0; ch < nch; ch++)
WindowFilterSubband(&buffer[ch][gr * 12 * 32 + 32 * bl], ch,
&(*sb_sample)[ch][gr][bl][0]);//多相滤波器组
}
scale_factor_calc(*sb_sample, scalar, nch, frame.sblimit);//计算比例因子
pick_scale(scalar, &frame, max_sc);//选择其中最大的比例因子
if (frame.actual_mode == MPG_MD_JOINT_STEREO) {
combine_LR(*sb_sample, *j_sample, frame.sblimit);
scale_factor_calc(j_sample, &j_scale, 1, frame.sblimit);//计算比例因子选择信息
}
if ((glopts.quickmode == TRUE) && (++psycount % glopts.quickcount != 0)) {
for (ch = 0; ch < nch; ch++) {
for (sb = 0; sb < SBLIMIT; sb++)
smr[ch][sb] = smrdef[ch][sb];
}
}
else
{
//根据心理声学模型计算掩蔽电平
switch (model) {
case -1:
psycho_n1(smr, nch);
break;
case 0://心理声学模型A计算掩蔽电平
psycho_0(smr, nch, scalar, (FLOAT)s_freq[header.version][header.sampling_frequency] * 1000);//注意这里 输入比例因子,fft,输出SMR
break;
case 1:
psycho_1(buffer, max_sc, smr, &frame);
break;
case 2:
for (ch = 0; ch < nch; ch++) {
psycho_2(&buffer[ch][0], &sam[ch][0], ch, &smr[ch][0], //snr32,
(FLOAT)s_freq[header.version][header.sampling_frequency] *
1000, &glopts);
}
break;
case 3:
psycho_3(buffer, max_sc, smr, &frame, &glopts);
break;
case 4:
for (ch = 0; ch < nch; ch++) {
psycho_4(&buffer[ch][0], &sam[ch][0], ch, &smr[ch][0], // snr32,
(FLOAT)s_freq[header.version][header.sampling_frequency] *
1000, &glopts);
}
break;
case 5:
psycho_1(buffer, max_sc, smr, &frame);
fprintf(stdout, "1 ");
smr_dump(smr, nch);
psycho_3(buffer, max_sc, smr, &frame, &glopts);
fprintf(stdout, "3 ");
smr_dump(smr, nch);
break;
case 6:
for (ch = 0; ch < nch; ch++)
psycho_2(&buffer[ch][0], &sam[ch][0], ch, &smr[ch][0], //snr32,
(FLOAT)s_freq[header.version][header.sampling_frequency] *
1000, &glopts);
fprintf(stdout, "2 ");
smr_dump(smr, nch);
for (ch = 0; ch < nch; ch++)
psycho_4(&buffer[ch][0], &sam[ch][0], ch, &smr[ch][0], // snr32,
(FLOAT)s_freq[header.version][header.sampling_frequency] *
1000, &glopts);
fprintf(stdout, "4 ");
smr_dump(smr, nch);
break;
case 7:
fprintf(stdout, "Frame: %i\n", frameNum);
psycho_1(buffer, max_sc, smr, &frame);
fprintf(stdout, "1");
smr_dump(smr, nch);
psycho_3(buffer, max_sc, smr, &frame, &glopts);
fprintf(stdout, "3");
smr_dump(smr, nch);
for (ch = 0; ch < nch; ch++)
psycho_2(&buffer[ch][0], &sam[ch][0], ch, &smr[ch][0], //snr32,
(FLOAT)s_freq[header.version][header.sampling_frequency] *
1000, &glopts);
fprintf(stdout, "2");
smr_dump(smr, nch);
for (ch = 0; ch < nch; ch++)
psycho_4(&buffer[ch][0], &sam[ch][0], ch, &smr[ch][0], // snr32,
(FLOAT)s_freq[header.version][header.sampling_frequency] *
1000, &glopts);
fprintf(stdout, "4");
smr_dump(smr, nch);
break;
case 8:
/* Compare 0 and 4 */
psycho_n1(smr, nch);
fprintf(stdout, "0");
smr_dump(smr, nch);
for (ch = 0; ch < nch; ch++)
psycho_4(&buffer[ch][0], &sam[ch][0], ch, &smr[ch][0], // snr32,
(FLOAT)s_freq[header.version][header.sampling_frequency] *
1000, &glopts);
fprintf(stdout, "4");
smr_dump(smr, nch);
break;
default:
fprintf(stderr, "Invalid psy model specification: %i\n", model);
exit(0);
}
if (glopts.quickmode == TRUE)
/* copy the smr values and reuse them later */
for (ch = 0; ch < nch; ch++) {
for (sb = 0; sb < SBLIMIT; sb++)
smrdef[ch][sb] = smr[ch][sb];
}
if (glopts.verbosity > 4)
smr_dump(smr, nch);
}
transmission_pattern(scalar, scfsi, &frame);
main_bit_allocation(smr, scfsi, bit_alloc, &adb, &frame, &glopts);//进行比特分配
if (error_protection)
CRC_calc(&frame, bit_alloc, scfsi, &crc);//如果需要就添加CRC纠错
encode_info(&frame, &bs);
if (error_protection)
encode_CRC(crc, &bs);
encode_bit_alloc(bit_alloc, &frame, &bs);//将比特分配打包到比特流中
encode_scale(bit_alloc, scfsi, scalar, &frame, &bs);//将比例因子打包到比特流中
subband_quantization(scalar, *sb_sample, j_scale, *j_sample, bit_alloc,
*subband, &frame);//量化子带
sample_encoding(*subband, bit_alloc, &frame, &bs);//将子带打包到比特流中
...
exit (0);
}
- 比例因子提取
void scale_factor_calc (double sb_sample[][3][SCALE_BLOCK][SBLIMIT],
unsigned int scalar[][3][SBLIMIT], int nch,
int sblimit)
{
int k, t;
/* Using '--' loops to avoid possible "cmp value + bne/beq" compiler */
/* inefficiencies. Below loops should compile to "bne/beq" only code */
for (k = nch; k--;)
for (t = 3; t--;) {
int i;
for (i = sblimit; i--;) {//12个一组寻找子带中的最大值
int j;
unsigned int l;
register double temp;
unsigned int scale_fac;
register double cur_max = fabs (sb_sample[k][t][SCALE_BLOCK - 1][i]);
for (j = SCALE_BLOCK - 1; j--;) {
if ((temp = fabs (sb_sample[k][t][j][i])) > cur_max)
cur_max = temp;
}
for (l = 16, scale_fac = 32; l; l >>= 1) {//查找比例因子表中比这个最大值大的最小值作为比例因子
if (cur_max <= multiple[scale_fac])
scale_fac += l;
else
scale_fac -= l;
}
if (cur_max > multiple[scale_fac])
scale_fac--;
scalar[k][t][i] = scale_fac;//得到比例因子
}
}
}
- 选取最大比例因子
void pick_scale (unsigned int scalar[2][3][SBLIMIT], frame_info * frame,
double max_sc[2][SBLIMIT])
{
int i, j, k, max;
int nch = frame->nch;
int sblimit = frame->sblimit;
for (k = 0; k < nch; k++)
for (i = 0; i < sblimit; max_sc[k][i] = multiple[max], i++)
for (j = 1, max = scalar[k][0][i]; j < 3; j++)
if (max > scalar[k][j][i])//循环找最大的比例因子
max = scalar[k][j][i];
for (i = sblimit; i < SBLIMIT; i++)
max_sc[0][i] = max_sc[1][i] = 1E-20;
}
- 心理声学模型
void psycho_0(double SMR[2][SBLIMIT], int nch, unsigned int scalar[2][3][SBLIMIT], FLOAT sfreq) {
int ch, sb, gr;
int minscaleindex[2][SBLIMIT];//较小的指标意味着较大的比例因子
static FLOAT ath_min[SBLIMIT];
int i;
static int init = 0;
if (!init) {
FLOAT freqperline = sfreq / 1024.0;
for (sb = 0; sb < SBLIMIT; sb++) {
ath_min[sb] = 1000; /* set it huge */
}
//在每个子带中找到最小的ATH
for (i = 0; i < 512; i++) {
FLOAT thisfreq = i * freqperline;
FLOAT ath_val = ATH_dB(thisfreq, 0);
if (ath_val < ath_min[i >> 4])
ath_min[i >> 4] = ath_val;
}
init++;
}
//找到这32个子带中最小的比例因子
for (ch = 0; ch < nch; ch++)
for (sb = 0; sb < SBLIMIT; sb++)
minscaleindex[ch][sb] = scalar[ch][0][sb];
for (ch = 0; ch < nch; ch++)
for (gr = 1; gr < 3; gr++)
for (sb = 0; sb < SBLIMIT; sb++)
if (minscaleindex[ch][sb] > scalar[ch][gr][sb])
minscaleindex[ch][sb] = scalar[ch][gr][sb];
for (ch = 0; ch < nch; ch++)
for (sb = 0; sb < SBLIMIT; sb++)
SMR[ch][sb] = 2.0 * (30.0 - minscaleindex[ch][sb]) - ath_min[sb];
}
- 动态码率分配
void main_bit_allocation(double perm_smr[2][SBLIMIT],
unsigned int scfsi[2][SBLIMIT],
unsigned int bit_alloc[2][SBLIMIT], int* adb,
frame_info* frame, options* glopts)
{
...
//选择动态分配码率模式
if (glopts->vbr == FALSE) {
/* Just do the old bit allocation method */
noisy_sbs = a_bit_allocation(perm_smr, scfsi, bit_alloc, adb, frame);
}
else {
/* do the VBR bit allocation method *//动态分配码率
frame->header->bitrate_index = lower;
*adb = available_bits(frame->header, glopts);
{
int brindex;
int found = FALSE;
/* Work out how many bits are needed for there to be no noise (ie all MNR > 0.0 + VBRLEVEL) */计算如果全部消除噪声情况下所需要的比特数
int req =
VBR_bits_for_nonoise(perm_smr, scfsi, frame, glopts->vbrlevel);
/* Look up this value in the bitrateindextobits table to find what bitrate we should use for
this frame */在bitrateindextobits表中查找对此帧使用的比特率
for (brindex = lower; brindex <= upper; brindex++) {
if (bitrateindextobits[brindex] > req) {
guessindex = brindex;
found = TRUE;
break;
}
}
if (found == FALSE)
guessindex = upper;
}
frame->header->bitrate_index = guessindex;
*adb = available_bits(frame->header, glopts);
/* update the statistics */
vbrstats[frame->header->bitrate_index]++;
if (glopts->verbosity > 2) {
static int count = 0;
int i;
if ((count++ % 1000) == 0) {
for (i = 1; i < 15; i++)
fprintf(stdout, "%4i ", vbrstats[i]);
fprintf(stdout, "\n");
}
if (glopts->verbosity > 5)
fprintf(stdout,
"> bitrate index %2i has %i bits available to encode the %i bits\n",
frame->header->bitrate_index, *adb,
VBR_bits_for_nonoise(perm_smr, scfsi, frame,
glopts->vbrlevel));
}
noisy_sbs =
VBR_bit_allocation(perm_smr, scfsi, bit_alloc, adb, frame, glopts);
}
}
- 输出音频信息
void print_config(frame_info* frame, int* psy, char* inPath,
char* outPath)
{
frame_header* header = frame->header;
if (glopts.verbosity == 0)
return;
fprintf(stderr, "--------------------------------------------\n");
fprintf(stderr, "Input File : '%s' %.1f kHz\n",
(strcmp(inPath, "-") ? inPath : "stdin"),
s_freq[header->version][header->sampling_frequency]);//输入文件路径和音频采样率
fprintf(stderr, "Output File: '%s'\n",
(strcmp(outPath, "-") ? outPath : "stdout"));//输出文件路径
fprintf(stderr, "%d kbps ", bitrate[header->version][header->bitrate_index]);//音频采样率
fprintf(stderr, "%s ", version_names[header->version]);
if (header->mode != MPG_MD_JOINT_STEREO)
fprintf(stderr, "Layer II %s Psycho model=%d (Mode_Extension=%d)\n",
mode_names[header->mode], *psy, header->mode_ext);//采用的心理声学模型
else
fprintf(stderr, "Layer II %s Psy model %d \n", mode_names[header->mode],
*psy);
fprintf(stderr, "[De-emph:%s\tCopyright:%s\tOriginal:%s\tCRC:%s]\n",
((header->emphasis) ? "On" : "Off"),
((header->copyright) ? "Yes" : "No"),
((header->original) ? "Yes" : "No"),
((header->error_protection) ? "On" : "Off"));
fprintf(stderr, "[Padding:%s\tByte-swap:%s\tChanswap:%s\tDAB:%s]\n",
((glopts.usepadbit) ? "Normal" : "Off"),
((glopts.byteswap) ? "On" : "Off"),
((glopts.channelswap) ? "On" : "Off"),
((glopts.dab) ? "On" : "Off"));
if (glopts.vbr == TRUE)
fprintf(stderr, "VBR Enabled. Using MNR boost of %f\n", glopts.vbrlevel);
fprintf(stderr, "ATH adjustment %f\n", glopts.athlevel);
fprintf(stderr, "--------------------------------------------\n");
}
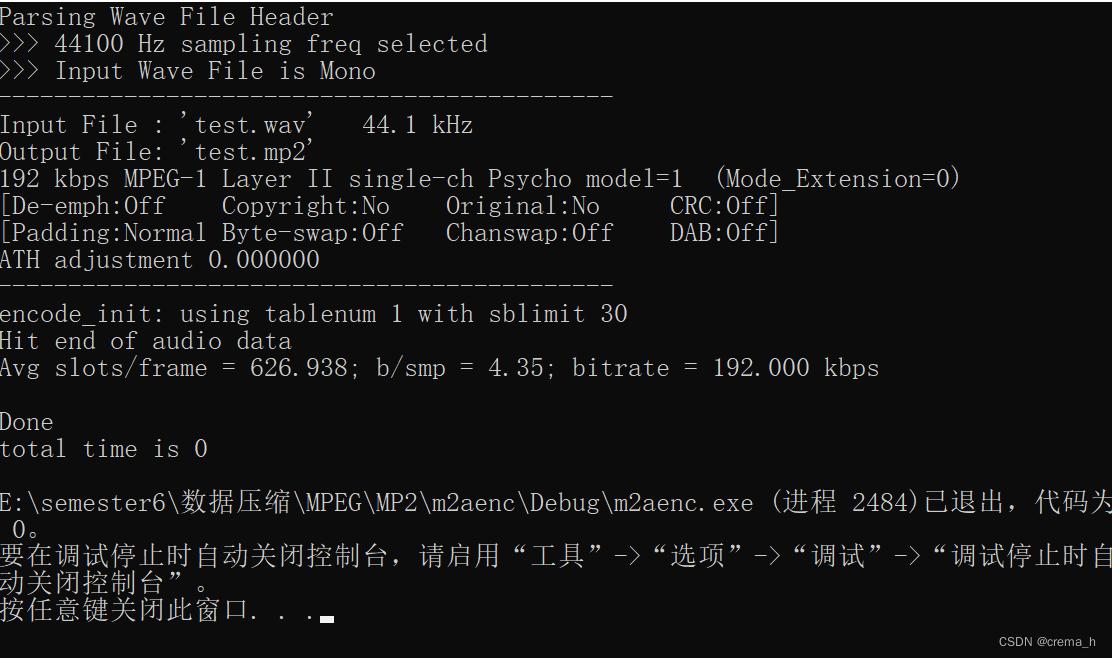
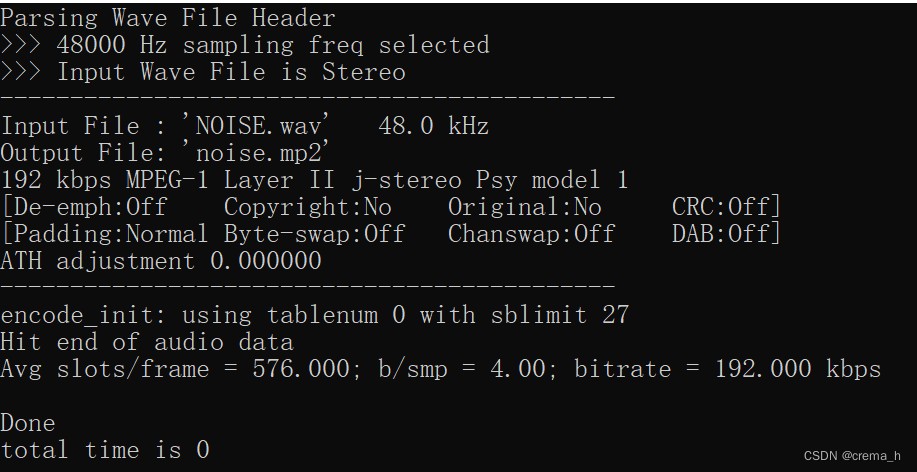
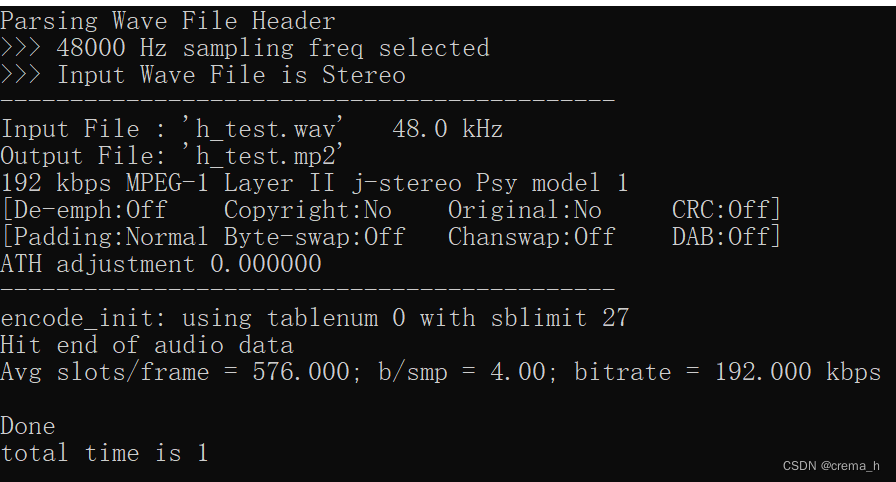
直接运行程序,得到结果,可看到输入.wav文件采样率分别为44.1kHz、48kHz、48kHz,输出.mp2文件的目标码率均为192kbps。
test乐音
NOISE噪声
h_test乐音+噪声混合
- 修改程序输出数据帧信息
在源文件m2aenc.c的开头加入define语句:#define FRAME_TRACE 1
在main()函数中添加代码
#if FRAME_TRACE
FILE* output;
output = fopen("output.txt", "a");
if (frameNum == 900) {
fprintf(output, "声道数:%d\n", nch);
fprintf(output, "目前观测第 %d 帧\n", frameNum);
fprintf(output, "本帧比特预算:%d bits\n", adb);
fprintf(output, "\n");
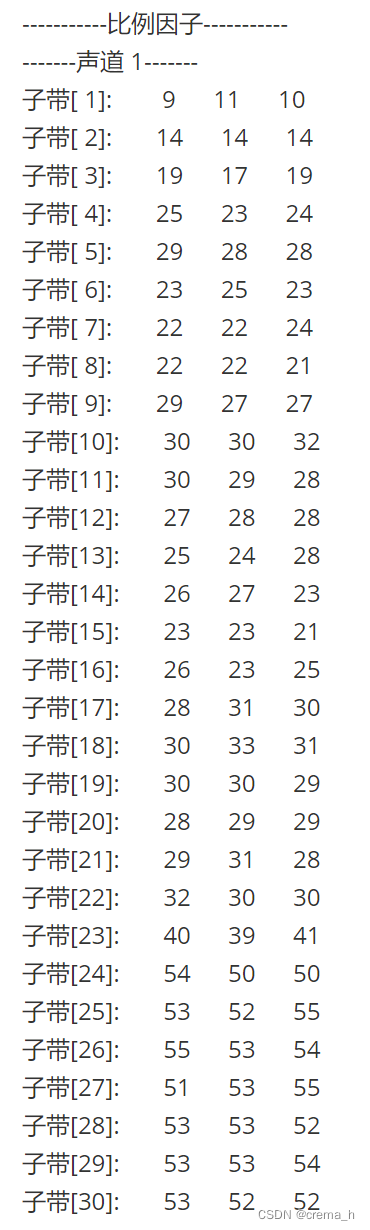
/* 比例因子 */
fprintf(output, "========== 比例因子 ==========\n");
for (ch = 0; ch < nch; ch++) // 每个声道单独输出
{
fprintf(output, "------ 声道%2d ------\n", ch + 1);
for (sb = 0; sb < frame.sblimit; sb++) // 每个子带
{
fprintf(output, "子带[%2d]:\t", sb + 1);
for (int gr = 0; gr < 3; gr++) {
fprintf(output, "%2d\t", scalar[ch][gr][sb]);
}
fprintf(output, "\n");
}
}
fprintf(output, "\n");
/* 比特分配表 */
fprintf(output, "========== 比特分配表 ==========\n"); //输出比特分配结果
for (ch = 0; ch < nch; ch++) {
fprintf(output, "------ 声道%2d ------\n", ch + 1); //按声道分配
for (sb = 0; sb < frame.sblimit; sb++) {
fprintf(output, "子带[%2d]:\t%2d\n", sb + 1, bit_alloc[ch][sb]);
}
fprintf(output, "\n");
}
}
fclose(output);
#endif // FRAME_TRACE
————————————————
得到结果
输入文件:test.wav
输出文件:test.mp2
采样频率:44.1 kHz 目标码率:192 kbps
声道数:1
当前是第 2 帧
该帧比特预算:5016 bits

输入文件:NOISE.wav
输出文件:NOISE.mp2
采样频率:48.0 kHz
目标码率:192 kbps
声道数:2
当前是第 2 帧
该帧比特预算:4608 bits


输入文件:h_test.wav(乐音+噪声混合)
输出文件:h_test.mp2
采样频率:48.0 kHz
目标码率:192 kbps
声道数:2
当前是第 2 帧
该帧比特预算:4608 bits
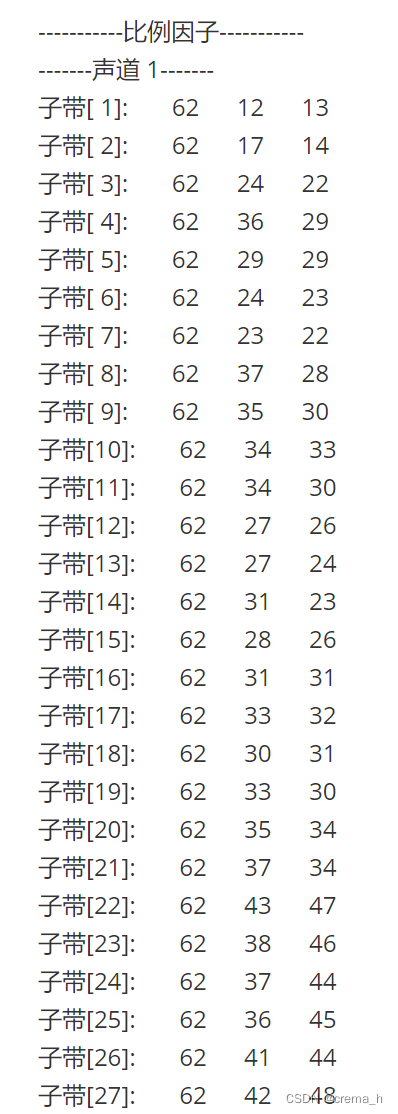
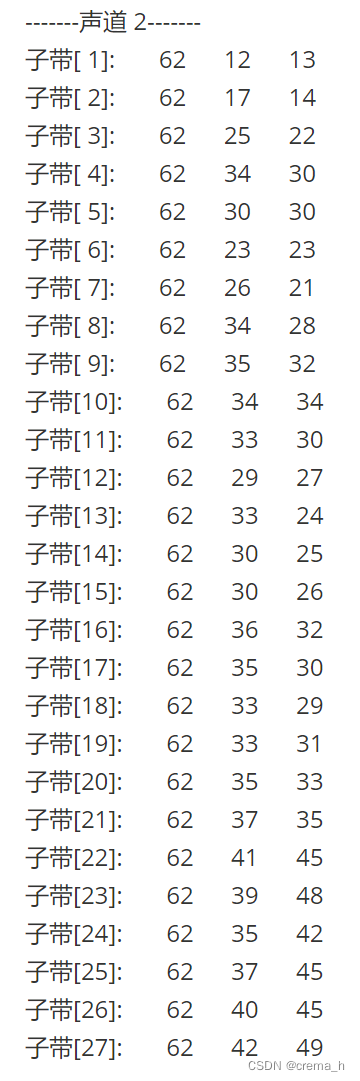

















 907
907











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









