






hive函数
hive的函数分为两大类:内置函数、用户自定义函数UDF;
内置函数分为:数值类型函数,日期类型函数,字符串类型函数,集合函数,条件函数等
用户自定义函数:UDF(普通函数,一进一出)、UDAF(聚合函数,多进一出)、UDTF(表生成函数,一进多出)
内置函数
字符串函数
字符串长度函数:length
字符串反转函数:reverse
字符串连接函数:concat
带分隔符字符串连接函数:concat_ws
字符串截取函数:substr/substring
字符串转大写函数:upper/ucase
字符串转小写函数:lower/lcase
去空格函数:trim
左边去空格函数:ltrim
右边去空格函数:rtrim
正则表达式替换函数:regexp_replace
正则表达式解析函数:regexp_extract
URL解析函数:parse_url
json解析函数:get_json_object
空格字符串函数:space
重复字符串函数:repeat
首字母ASCII函数:ascii
左补足函数:lpad
右补足函数:rpad
分割字符串函数:split
集合查找函数:find_in_set
---正则表达式替换函数 regexp_replace(str,regexp,rep)
select regexp_replace('100-200','(\\d+)','num');
---regexp_extract(str,regexp[,idx])提取指定组内容
select regexp_extract('100-200','(\\d+)-(\\d+)',2);
---parse_url提取url
select parse_url('www.baidu.com','HOST');
日期函数
获取当前日期:currrent_date
获取当前时间戳:current_timestamp
unix时间戳转日期函数:from_timestamp
获取当前unix时间戳函数:unix_timestamp
日期转unix时间戳函数:unix_timestamp
指定格式日期转unix’时间戳函数:unix_timestamp
抽取日期函数:to_date
日期转年函数:year
日期转月函数:month
日期转日函数:day
日期转小时函数:hour
日期转分钟函数:minute
日期转秒函数:second
日期转周函数:weekofyear
日期比较函数:datediff
日期增加函数:date_add
日期减少函数:date_sub
数学函数
取整函数:round
指定精度取整函数:round
向下取整函数:floor
向上取整函数:ceil
取随机数函数:rand
二进制函数:bin
进制转换函数:conv
绝对值函数:abs
集合函数
集合元素size函数:size(MAP<K,V>/Array< T >)
添加进数组:collect_set() 无序不重复,collect_list 有序重复
取map集合keys函数:map_keys(Map<K,V>)
取map集合values函数:map_values(Map<K,V>)
判断数组是否包含指定元素:array_contains(Array< T >,values)
数组排序函数:sort_array(Array< T>)
条件函数
if条件判断函数:if(boolean testCondition,T valueTrue,TvaluesFalseOrNull)
空值判断函数:isnull(a)
非空判断函数:isnotnull(a)
空值转换函数:nvl(T value,T deafult value)
非空查找函数:CAOLESCE(T v1,T v2,…)
条件转化函数:case when then…else…end
nullif(a,b):如果a=b,返回null,否则返回一个
assert_true(condition):如果’condition’不为真,则引发异常,否则返回null
类型转换函数
cast(12.14 as string)
数据脱敏函数
完成对数据脱敏转换,屏蔽原始数据,主要如下:
查询回的数据,大写字母转化为X,小写字母转化为x,数字转化为n:mask
select mask("123ABCdef");
select mask("123ABCdef",'-','.','^')---自定义转化字母
对于前n个进行脱敏:mask_frist_n(string str[ int n])
对于后n个进行脱敏:mask_last_n(string str[ int n])
除了前n个字符,其他进行掩码处理:mask_show_frist_n(string str[ int n])
除了后n个字符,其他进行掩码处理:mask_show_last_n(string str[ int n])
返回字符串hash码:mask_hash(string|char|vachar str)
杂项函数
hive调用java方法:java_method(class,method[ arg[arg2…]])
反射函数:reflect(class,method[arg[ arg2…]])
select java_method('java.lang.Math','max',11,12);
select reflect('java.lang.Math','max',11,12);
---如果调用方法不是hive自带的,需要使用 add jar添加
取hash值函数:hash
current_user(),logged_in_user(),current_database(),version()
SHA-1加密:sha1(string/binary)
SHA-2家族算法加密:sha2(string/binary,int)(SHA-224,SHA-256,SHA-384,SHA-512)
crc32加密
MD5加密:md5(string/binary)
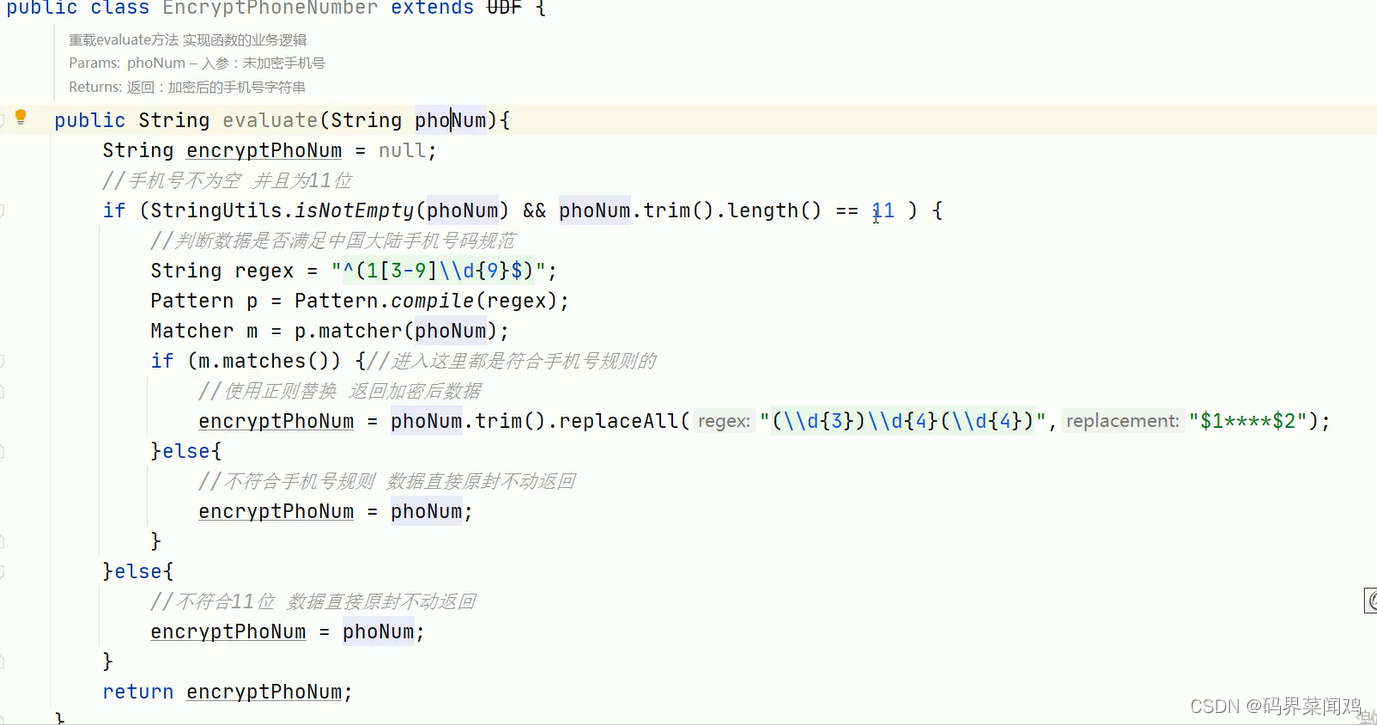
UDF实现步骤
1、写一个Java类,继承UDF,并重载evaluate方法,方法中实现函数的业务逻辑;
2、重载意味着可以在一个Java类中实现多个函数功能;
3、程序打成jar包,上传HS2服务器本地或者HDFS
4、客户端命令行中添加jar包到hive的classpath:hive>add jar>xxxx>udf.jar;
5、注册成为临时函数(给UDF命名):create temporary function 函数名 as ‘UDF类全路径’
6、HQL使用函数
explode函数
explode函数接收map、array类型的数据作为输入,然后把输入数据中的每个元素拆开变成一行数据,一个元素一行。explode的执行效果满足于输入一行输出多行
explode(array)、explode(map)
explode函数执行生成的结果可以理解为一张虚拟的表,数据来源于原表。在select条件时,explode字段旁边不支持其他字段同时出现。
解决方法:
1、从sql层面,需要对两张表进行join操作;
2、hive专门提供了语法 lateral view侧视图,专门用于explode及类似函数
---lateral view +explode
select a.team_name,b.year from the_nba_championship a lateral view explode(champion_year) b as year order by b.year desc;
lateral view 侧视图
lateral view是一种特殊的语法,主要搭配udtf类型的函数一起使用,用于解决udtf函数的一些查询限制问题。使用lateral view时也可以对udtf产生的记录设置字段名字,产生的字段可以用于groupby,orderby,limit等语句,不需要单独嵌套一层子查询;
聚合函数
基础聚合函数:sum(),avg(),max(),min()
增强聚合函数:grouping_sets(),cube(),rollup()
grouping_sets是一种将多个group by逻辑写在一个sql语句中的便利写法。等价于将不同的维度的group by结果进行union all,grouping_id表示结果属于哪一分组集合。
---grouping sets()
select month,day,count(distinct cookied) AS sums,grouping_id
from cookies_Info
group by month,day
grouping sets(month,day)
order by grouping_id;
---grouping_id表示这一组结果属于哪个分组集合
---根据grouping sets中分组条件month,day,1代表month,2代表day
---等价于
select month,null as day,count(distinct cookied) AS sums,1 as grouping_id from cookies_Info
group by month
union all
select null as month,day,count(distinct cookied) AS sums,1 as grouping_id from cookies_Info
group by day
cube 表示根据group by的维度的所有组合进行聚合
对于cube来说,如果有n个维度,则所有组合的情况有2^n种
比如cube有a,b,c 3个维度,则所有组合情况分别为:(a,b,c),(a,b),(a,c),(b,c),(a),(b),©,()
select month,day,count(distinct cookied) AS sums,grouping_id
from cookies_Info
group by month,day
with cube
order by grouping_id;
rollup 根据group by的维度的所有组合进行聚合
roll up 是cube的子集,以最左侧的维度为主,从该维度进行层级聚合
比如cube有a,b,c 3个维度,则所有组合情况分别为:(a,b,c),(a,b),(a,c),(a)
select month,day,count(distinct cookied) AS sums,grouping_id
from cookies_Info
group by month,day
with rollup
order by grouping_id;
窗口函数
输入值是从select语句的结果集中的一行或多行的“窗口”中获取。
如果函数具有over子句,则他就是窗口函数。
function(arg) over([partition by <…> ] [ order by <…> ] [< windows_expression >])
funtion可以是下面的任意一种:
—聚合函数 :sum,max,avg等
—排序函数 :rank,row_number等
—分析函数 :lead,lag,frist_value等
partition by 类似于group by,用于指定分组,若没有partition 那么整张表就是一组
order by用于指定分组内数据顺序排序,支持asc,desc
windows_expression 提供控制行范围的能力,比如向前3行,向后2行
关键字是 rows between,包含以下几个选项:
--preceding:往前
--following:向后
--current row:当前行
--unbounded:边界
--unbounded preceding :表示从前面的起点
--unbounded following :表示到后面的终点
row_number() ;
row_number:在每个分组中,为每行分配从1开始的唯一序列号,递增、不考虑重复。
rank:在每个分组中,为每行分配一个从1开始序列号,考虑重复,挤占后续位置
dense_rank:在每个分组中,为每行分配一个从1开始序列号,考虑重复,不挤占后续位置
ntile:窗口排序函数
将每个分组内数据分为指定的若干桶内(分为若干个部分),并且为每一个桶分配一个桶号;
如果不能平均分配,则优先分配较小编号的桶,并且各个桶中能放的行数最多相差1。
---将每组内数据分为3份
select cookieid,createtime,pv,ntile(3) over (partition by cookieid order by createtime ) as rn2
from website_info
order by cookieid,createtime
窗口分析函数
lag(col,n,default) 用于统计窗口内往上的第n行值.
lead(col,n,default) 用于统计窗口内往下的第n行值
frist_value 取分组内排序后,截止到当前行,第一个值
last_value 取分组内排序后,截止到当前行,最后一个值
抽样函数
一种用于识别和分析数据中的子集的技术,以发现整个数据集中的模式和趋势。
通过三种方式采样数据:随机采样、块采样和存储桶表采样
random随机抽样
随机抽样使用rand()函数来确保随机获取数据,limit来限制抽取数据个数。
随机的优点是随机,缺点是速度不快,尤其是表数据多的时候。
1、推荐distribute + sort,可以确保数据随机分布在mapper 和reducer之间,有助于底层执行效率
2、order by也可以达到相同目的,但是表现不好,orderby是全局 排序,只会启动执行一个reducer。
block数据块抽样
随机采样n行数据、百分比数据或者指定大小数据。采样粒度是HDFS块大小。
优点是速度快,但是缺点是不随机。
---根据行数抽样
select * from student tablesample(1 rows) ;
---根据数据百分比抽样
select * from student tablesample(50 percent) ;
---根据数据大小抽样
select * from student tablesample(1 K);
分桶表抽样
针对分桶表进行优化,既随机速度也快。
tablesample(bucket x out of y [on col])
——y必须是table总bucket数的倍数或者因子。hive根据y的大小决定抽样比例。
——x表示从哪个bucket开始抽取
——on col 表示基于什么抽
on rand() 表示随机抽
on 分桶字段 表示基于分桶字段抽样,效率更高
行专列
多行转多列
case when函数
方法一:
case when 条件1 then value… else 默认值 end
方法二:
case 列 when v1 then value… else 默认值 end
示例:原表
| col1 | col2 | col3 | |
|---|---|---|---|
| 1 | a | c | 1 |
| 2 | a | d | 2 |
| 3 | a | f | 3 |
| 4 | b | c | 4 |
| 5 | b | d | 5 |
| 6 | b | f | 6 |
目的表:
| c | d | f | |
|---|---|---|---|
| a | 1 | 2 | 3 |
| b | 4 | 5 | 6 |
实现过程:
select col1 as col1,
max(case col2 when 'c' then col3 else 0 end) as c,
max(case col2 when 'd' then col3 else 0 end) as d,
max(case col2 when 'f' then col3 else 0 end) as f
from
row2col1
group by
col1
多行转单列
concat 函数
concat_ws 函数 指定分隔符,实现字符串分割
特点:任意一元素不为null,结果不为null
collect_set 函数
collect_list 函数
示例:
| col1 | col2 | col3 |
|---|---|---|
| a | b | 1 |
| a | b | 2 |
| a | b | 3 |
| c | d | 4 |
| c | d | 5 |
| c | d | 6 |
目的表:
| col1 | col2 | col3 |
|---|---|---|
| a | b | 1,2,3 |
| c | d | 4,5,6 |
实现过程:
select col1 as col1,
col2 as col2,
concat_ws(',',collect_list(cast(col3 as string ))) as col3
from
row2col1
group by
col1,col2;
多列转多行
源表:
| col2 | col3 | col4 | |
|---|---|---|---|
| a | 1 | 2 | 3 |
| b | 4 | 5 | 6 |
目的表:
| col1 | col2 | col3 |
|---|---|---|
| a | c | 1 |
| a | d | 2 |
| a | f | 3 |
| b | c | 4 |
| b | d | 5 |
| b | f | 6 |
实现过程:
select col1 ,'c' as col2,col2 as col3 from row2col1
union all
select col1 ,'d' as col2,col3 as col3 from row2col1
union all
select col1 ,'f' as col2,col4 as col3 from row2col1;
单列转多行
源表:
| col1 | col2 | col3 |
|---|---|---|
| a | b | 1,2,3 |
| c | d | 4,5,6 |
目的表
| col1 | col2 | col3 |
|---|---|---|
| a | b | 1 |
| a | b | 2 |
| a | b | 3 |
| c | d | 4 |
| c | d | 5 |
| c | d | 6 |
实现过程:
select col1 ,
col2,
lv.col3 as col3
from row2col1
lateral view explode(split(clo3,',')) lv as clo3;
json的处理方式
方式一:使用json函数处理
get_json_object、json_tuple 这两个函数可以实现json数据中每个字段单独解析出来,单独成表
方式二: JSON serde加载数据
建表时指定Serde,加载json文件到表中,自动解析对应表格式
开窗函数的使用
连续登录的用户
select usrid,logintime,
---本次登录日期的第二天
date_add(logintime,2) as nextday,
-----按照 用户id分区,按照登陆日期排序,取下次登陆时间,取不到为0
lead(logintime,1,0) over (partition by usrid order by logintime) as nextlogin
from tb_login;
级联累加求和
分组统计每个用户每个月的消费金额,使用窗口聚合函数sum进行统计;
分组topN
row_number()家族
拉链表
通过时间标记发生变化数据的每种状态的时间周期。
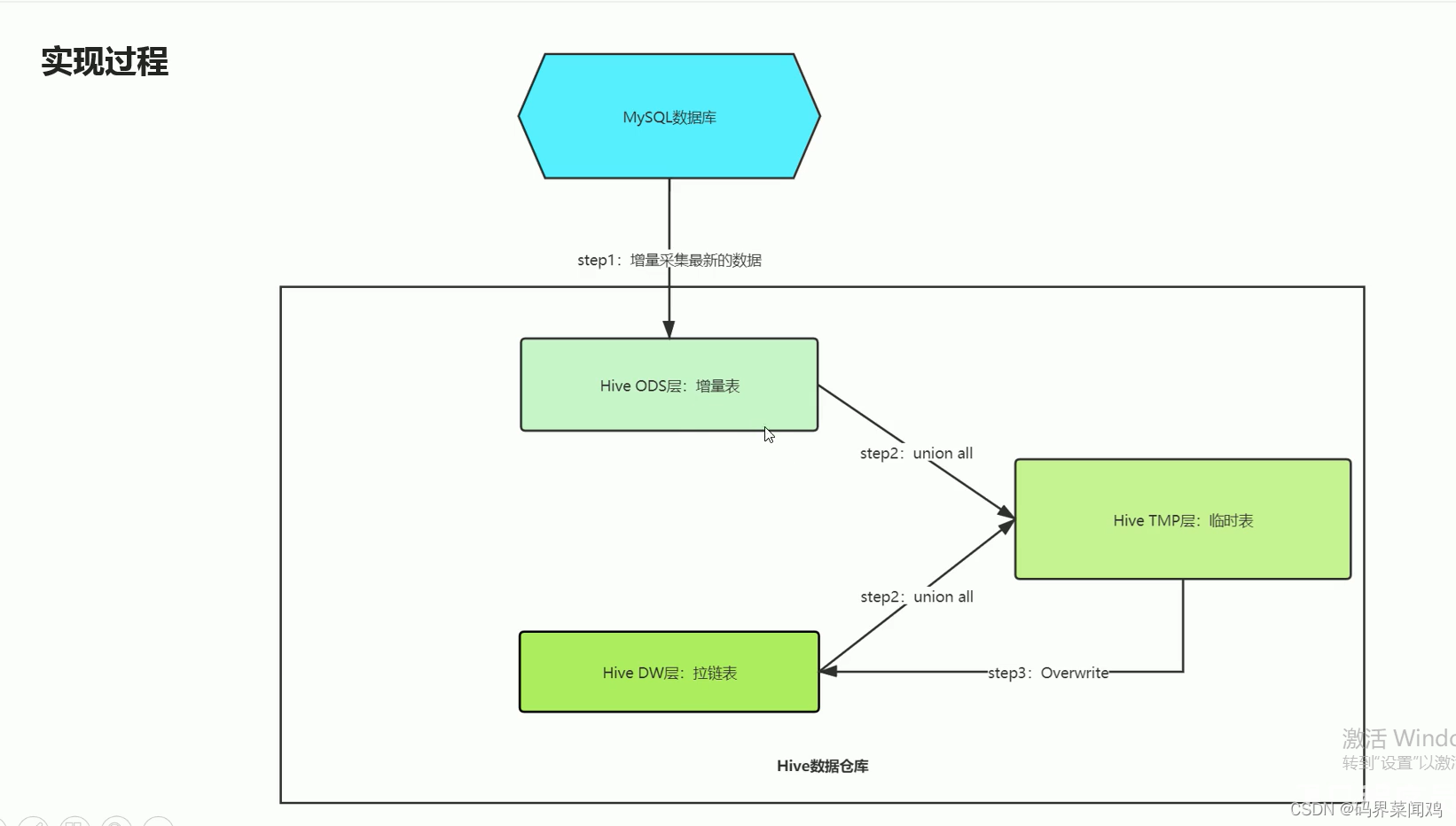 sql实现:
sql实现:
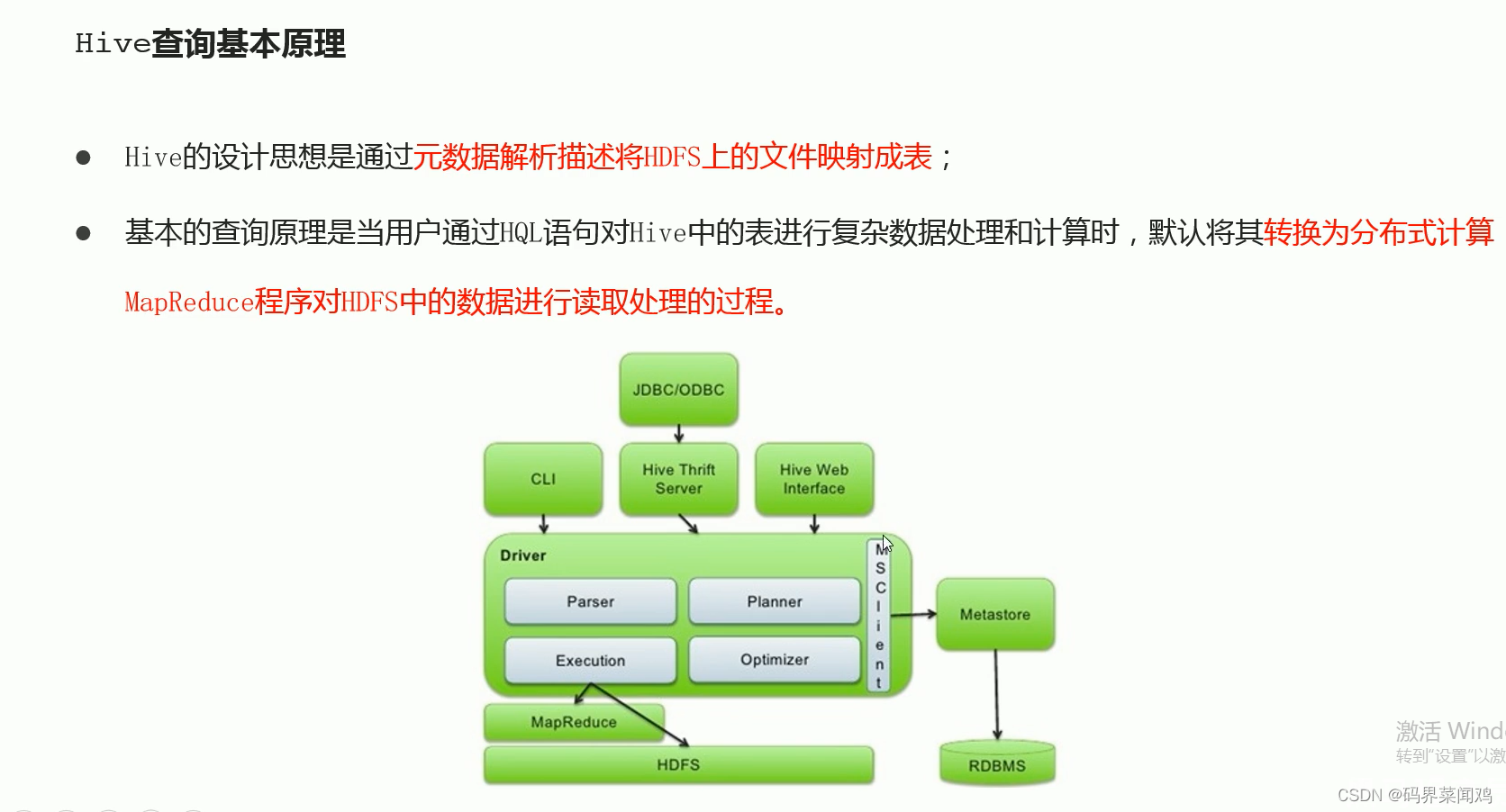 当执行查询计划时,hive会使用表的最后一级目录作为底层处理数据输入;
当执行查询计划时,hive会使用表的最后一级目录作为底层处理数据输入;
 由于hive的索引设计过于繁琐,从hive3.0开始,取消了对hive index的使用。
由于hive的索引设计过于繁琐,从hive3.0开始,取消了对hive index的使用。
实际工作场景中,一般不推荐使用hive index,推荐使用ORC文件格式中的索引、物化视图来代替hive index来提高性能。
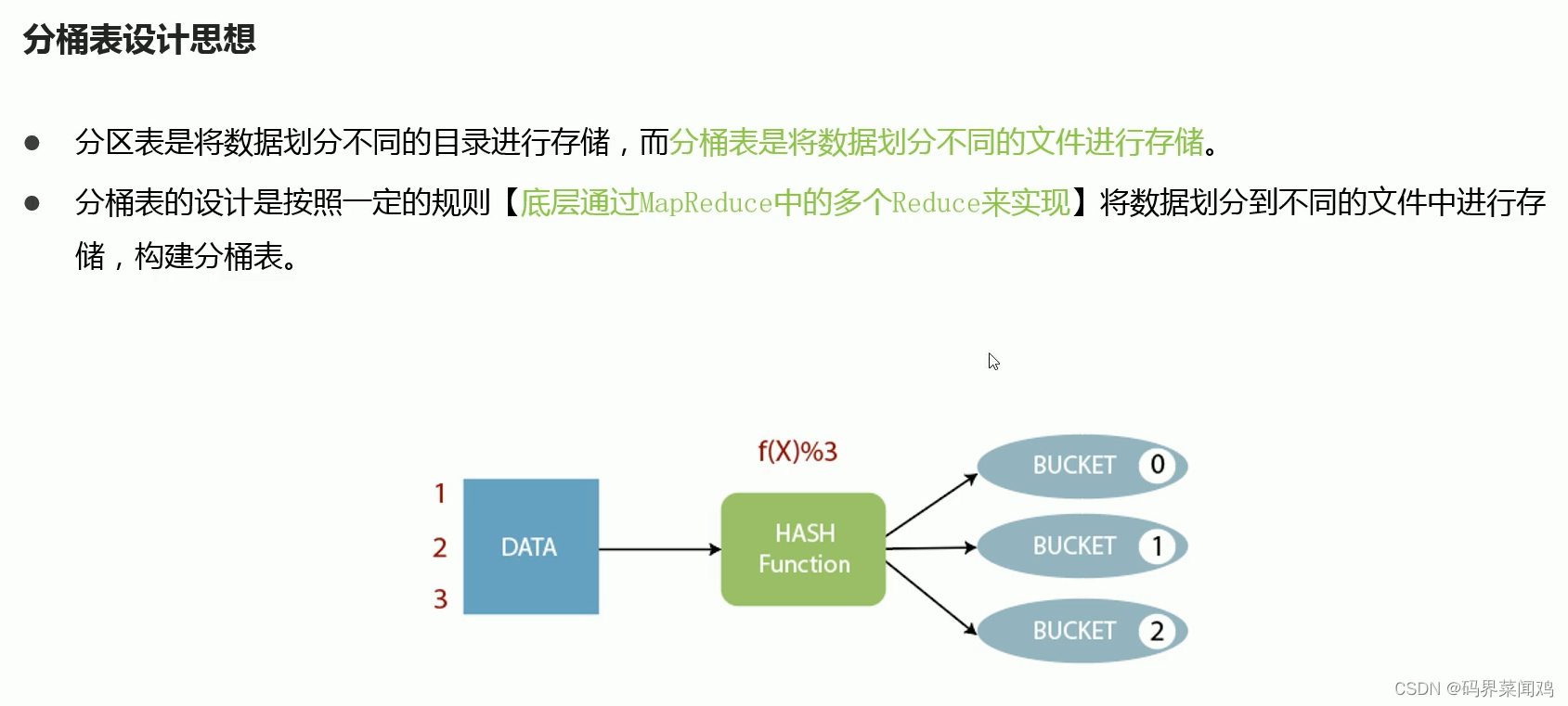
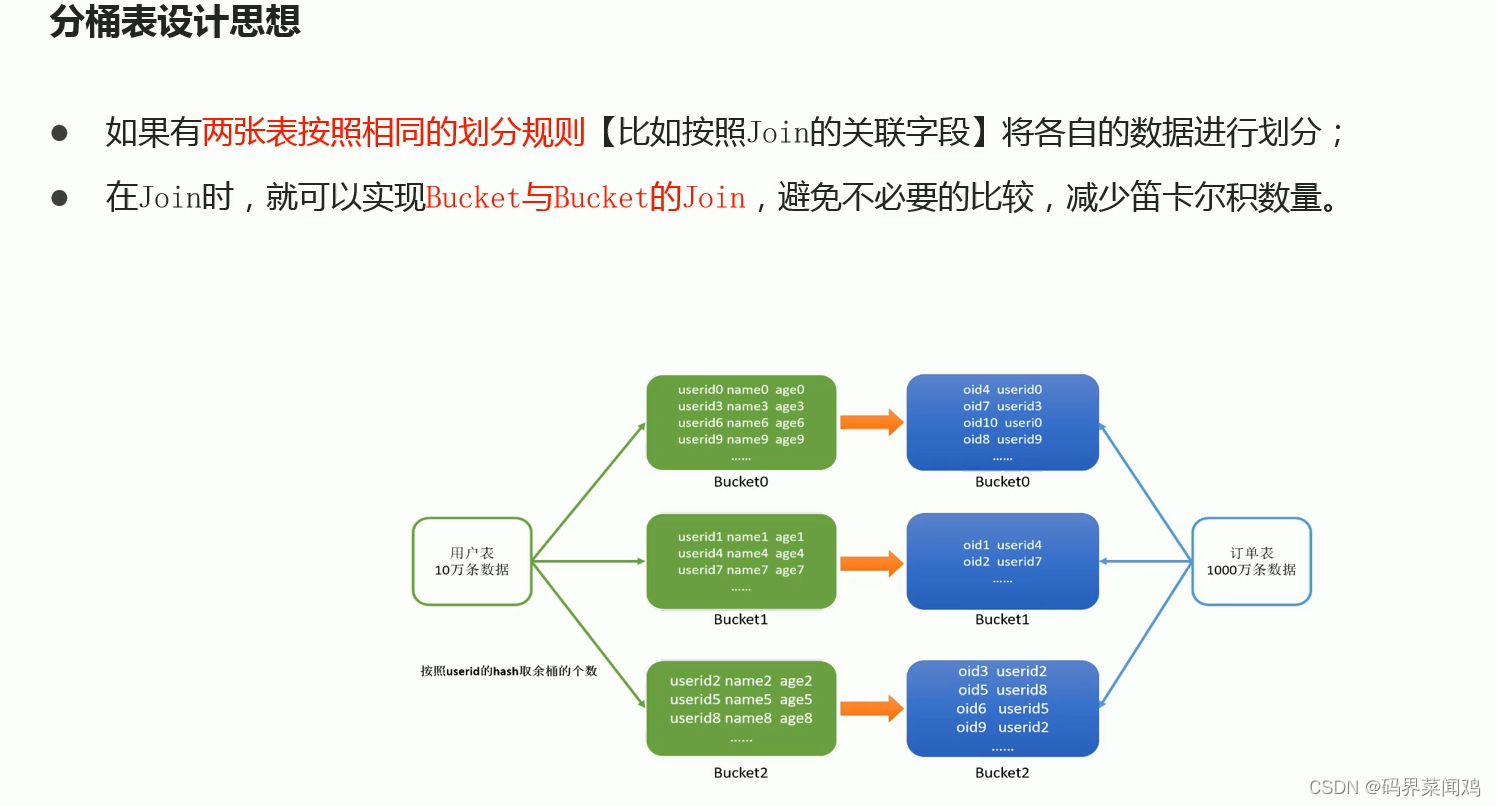
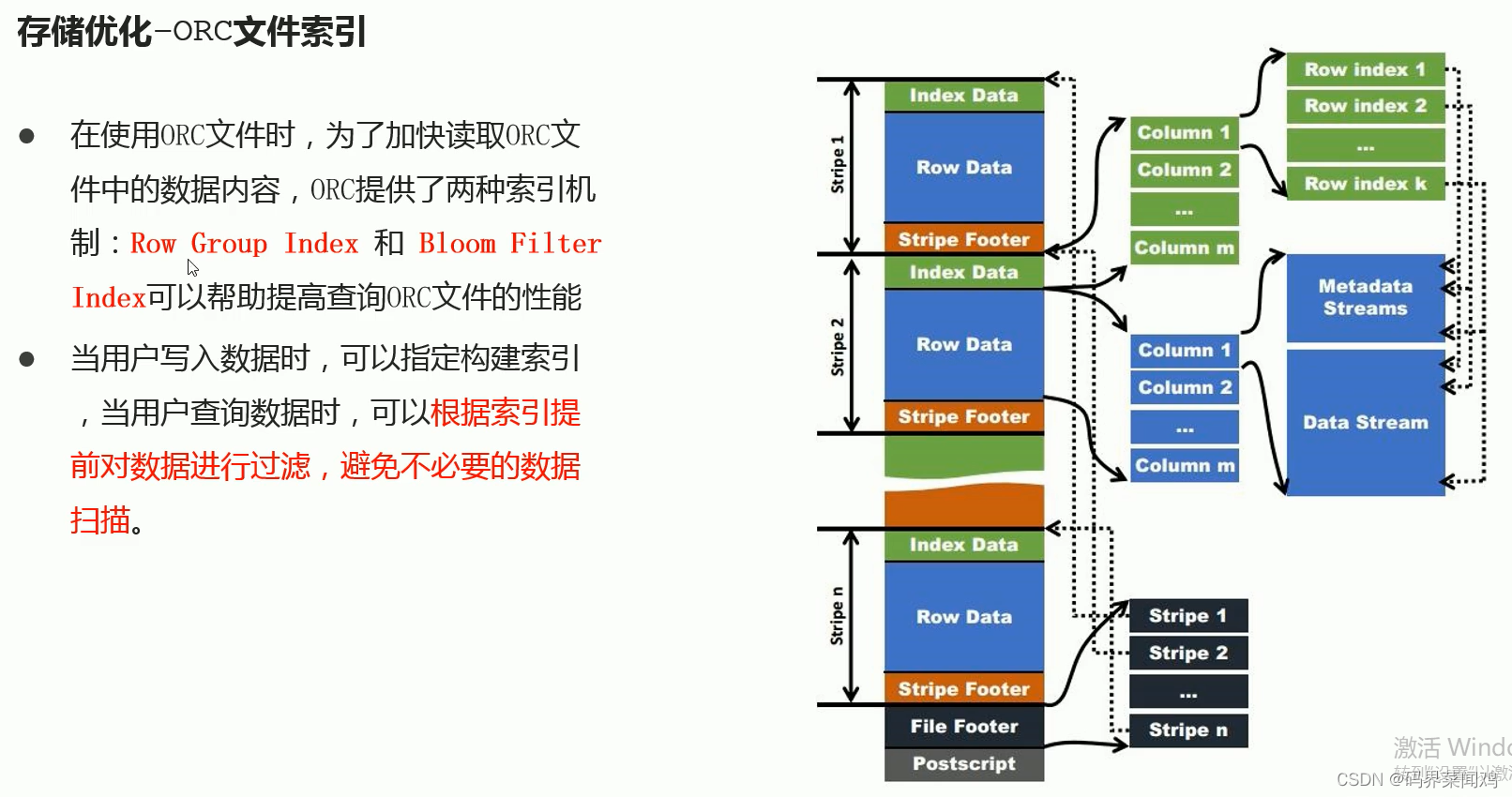
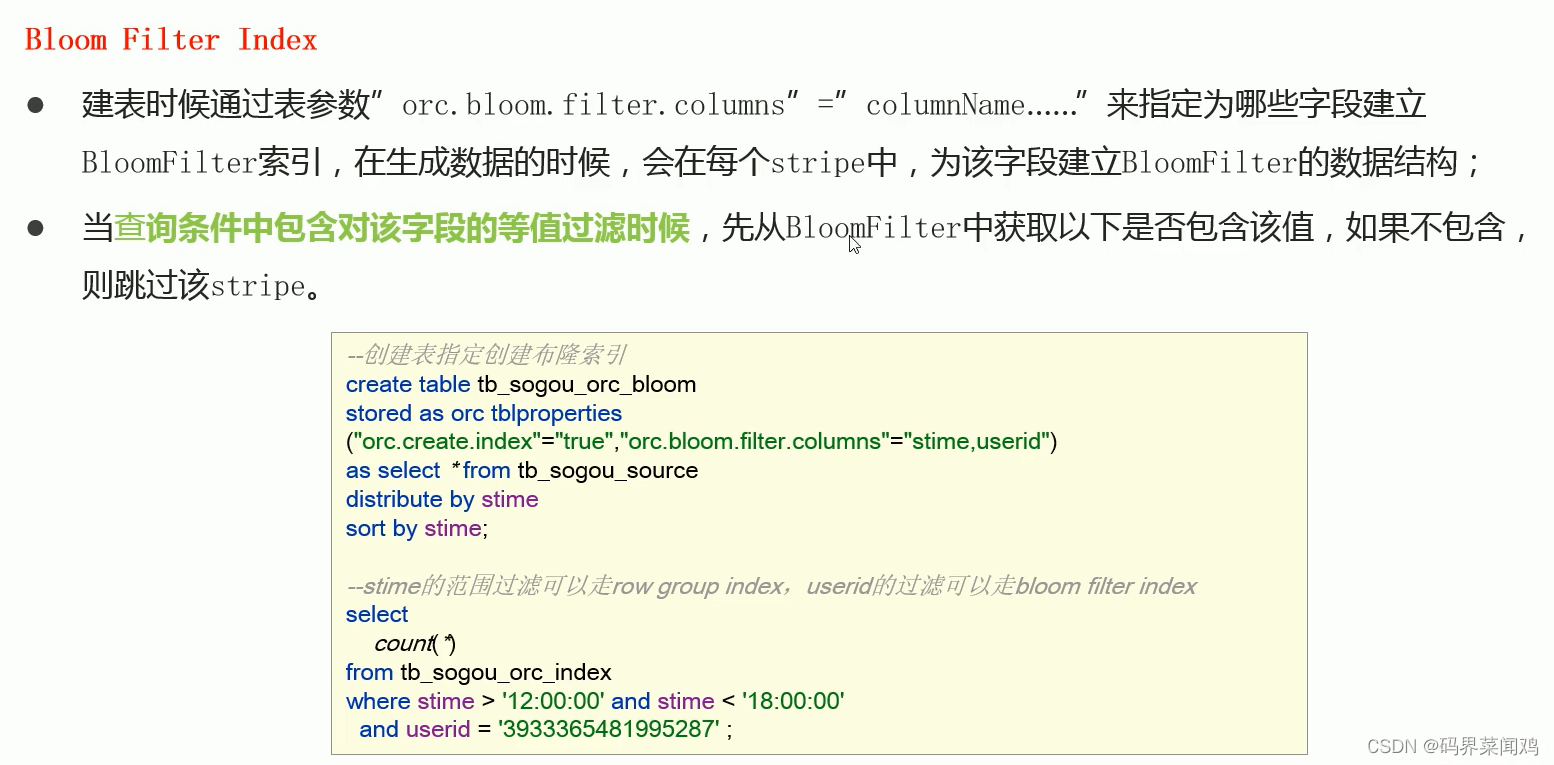
hive表数据优化
文件格式
hive的文件格式在建表时,默认是textFile,存储形式为按行存储。导入数据时把数据文件拷贝至HDFS不进行处理。
优点:
1、最简单的数据存储格式,可以直接查看
2、可以使用任意分隔符进行分割
3、便于其他工具共享数据,可以搭配压缩一起使用
缺点:
1、耗费存储空间,I/O性能低
2、结合压缩时HIVE不进行数据切分合并,不能进行行并行操作,查询效率低
3、按行存储,读取列的能力差
应用场景:
适用于小数据量的存储查询,一般用于第一层数据加载和测试使用。
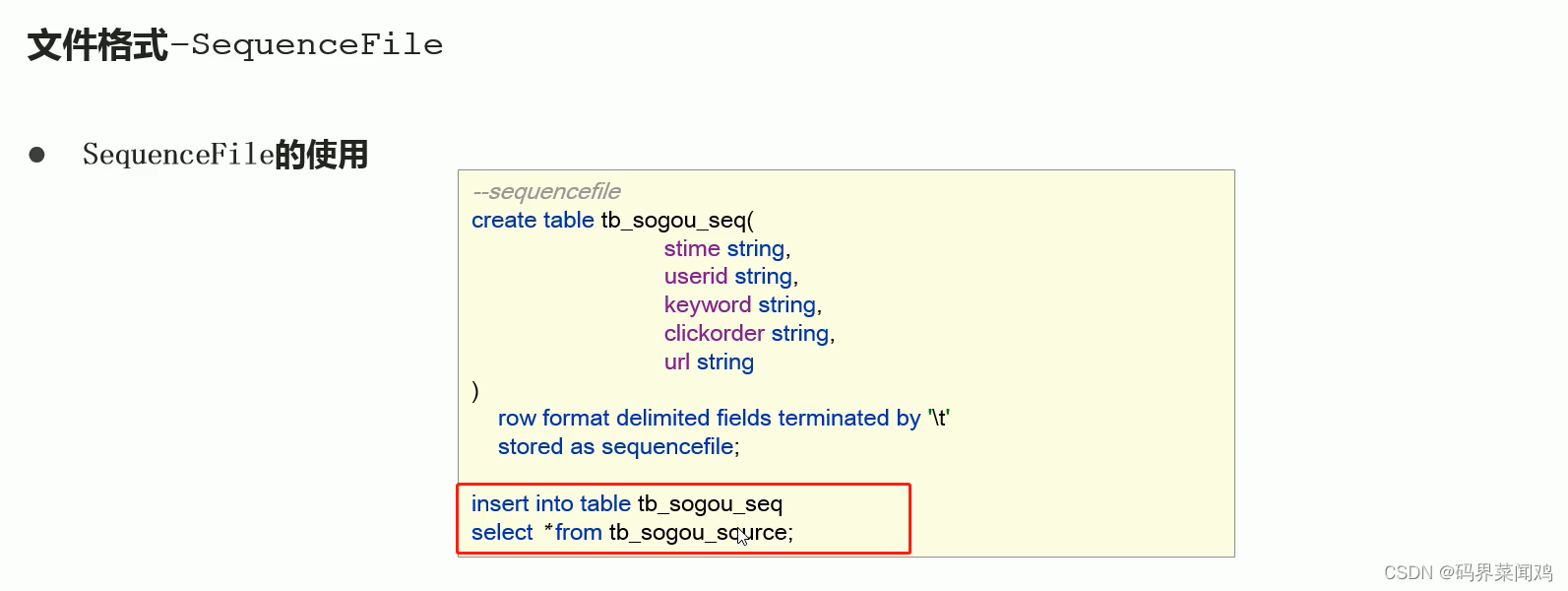
SequenceFile
SequenceFile是Hadoop里用来存储序列化的键值对(即二进制)的一种文件格式。该文件格式可以作为mapreduces作业的输入输出,hive也支持这种格式。
优点:
1、以二进制的KV形式存储数据
2、与底层交互更加友好,性能更佳
3、可压缩、可分割,优化磁盘利用率和I/O,可以用于存储多个小文件
缺点:
1、存储空间消耗最大
2、与非hadoop生态系统之外的工具不兼容
3、构建sequenceFile需要通过textFile文件转化加工
场景:
适用于小数据,但是列查询比较多的情况


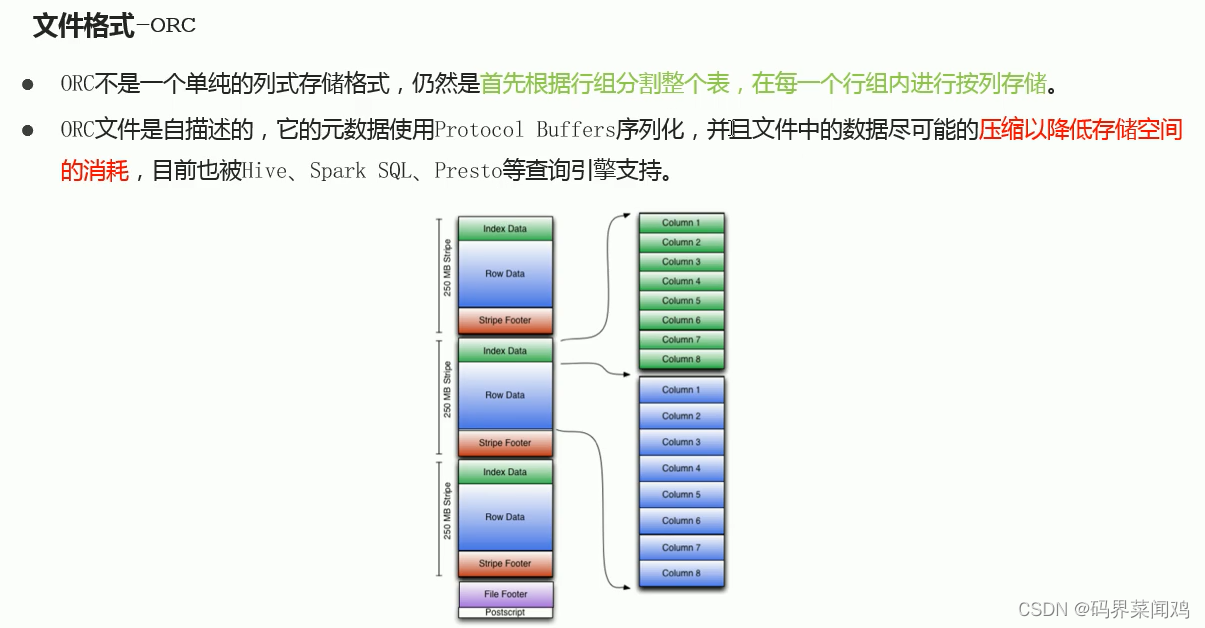




 explain查询计划:
explain查询计划:
explain [formatted|extended|dependency|authorization] query
formatted:对执行计划进行格式化,返回接送格式的执行计划
extended:提供一些格外的信息,比如文件的路径信息
dependency:以json格式返回查询所依赖的表和分区的列表
authorization:列出需要被授权的条目,包括输入和输出
每个计划由以下几个部分组成:
The Abstract Syntax Tree for the query
抽象语法树(AST):hive使用antlr解析生成器,可以自动地将sql生成抽象语法树。
The dependences between the different stages of the plan
Stage依赖关系:会列出运行查询划分的stage阶段以及之间的依赖关系
The description of each of the stages
Stage内容:包含了每个Stage非常重要的信息,比如运行时的operator和sort orders等具体信息。






谓词下推(ppd)
就是在不影响最终结果的情况下,尽量将过滤条件提前进行。hive中谓词下推后,过滤条件会推到map端,提前执行过滤,减少map到reduce的数据传输,提升整体性能。
默认参数开启: hive.optimize.pdd =true;
规则:
对于join(inner join)\full join,条件写在on后面,还是where后面,性能上没有影响。
对于left outer join,右边表的写在on后面,左边表写在where后面,性能上有提高。
对于right outer join,左侧表写在on后面,右侧表写在where后面,性能上有提高。
数据倾斜
现象:当提交运行一个程序时,这个程序的大多数的Task都已经结束运行,只有某一个task一直在运行,迟迟不能结束,导致整体进度卡在了99%或者100%
原因:数据分配不均
场景一:group by、count(distinct)
如果数据本身就是倾斜的,根据MapReduce的hash分区规则,肯定会出现数据倾斜现象
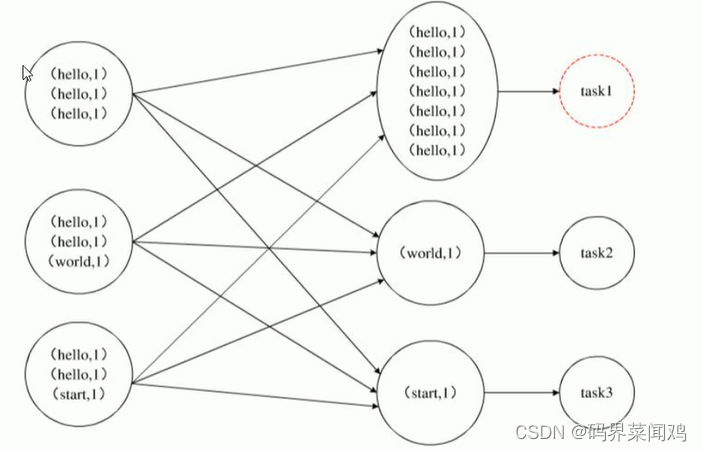
方案一:开启map端聚合
hive.map.aggr = true;
通过减少shuffle数据量和reducer阶段的执行时间,避免每个task数据差异过大导致数据倾斜
方案二:实现随机分区
select * from table distribute by rand();
distribute by用于指定底层按照哪些字段作为key实现分区、分组等;
通过rank函数随机值实现随机分区,避免数据倾斜
方案三:数据倾斜时自动负载均衡
hive.groupby.skewindata=true;
开启该函数之后,当前程序会自动通过两个mapreduce来运行
第一个mapreduce自动进行随机分布到reduce中,每个reducer做部分聚合操作,输出结果
第二个mapreduce将上一步聚合的结果再按照业务(group by key)进行处理,保证相同分布到一起,最终聚合得到结果
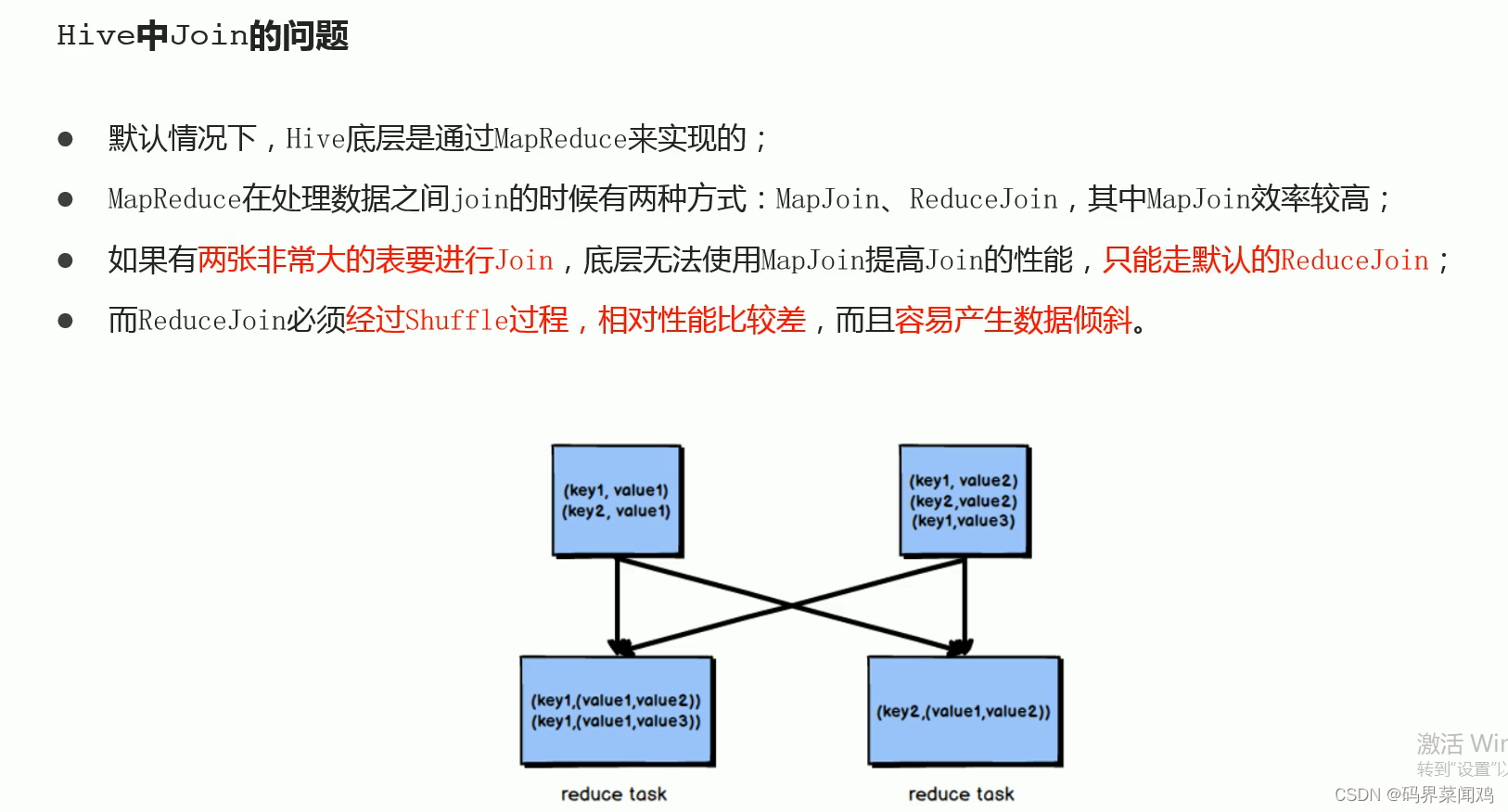
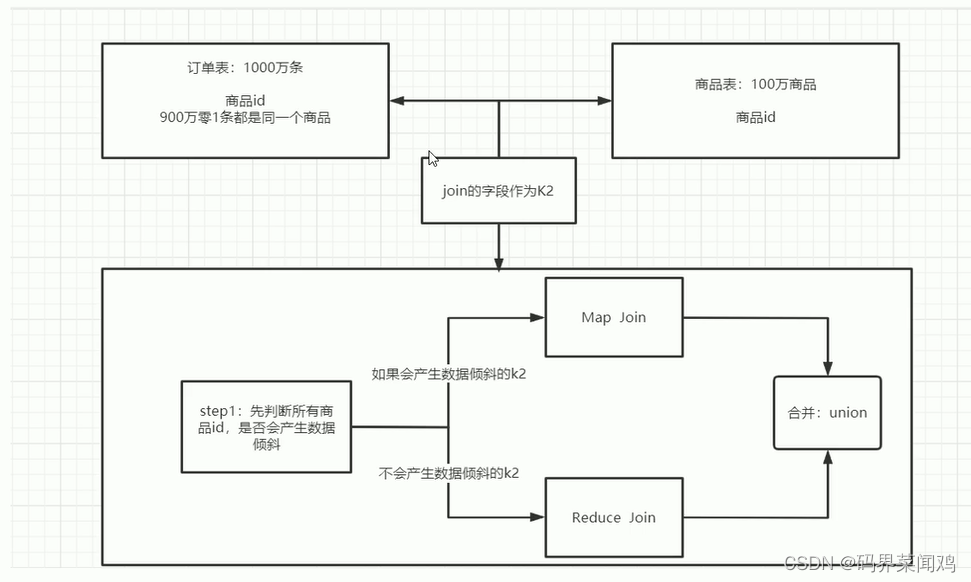
场景二:join
join操作时,如果两张表比较大,无法实现MAP join,只能走reduce join,那么当关联字段中某一种值过多的时候依旧会导致数据倾斜问题;
面对join产生的数据倾斜,核心思想时尽量避免reduce join产生,优先使用map join实现
方案一:提前过滤,将大数据变成小数据,实现map join
select a.id,a.value,b.value2 from table1 a join (select b.* from table2 b where b.ds>='20181201') c on (a.id=c.id)
方案二:使用bucket join
若方案一过滤后的数据仍然时一张大表,可以将两张表的数据构建为桶表,实现bucket map join,避免数据倾斜
方案三:使用skew join
skew join 是hive中专门为了避免数据倾斜而设计的特殊join过程
这种join的原理是将map join和reduce join进行合并,如果某个值出现了数据倾斜,就会产生数据倾斜的数据单独使用mapjoin使用
其他没有产生数据倾斜的数据由reduce join来实现,这样就避免了 reduce join中产生数据倾斜的问题
最终将map join结果和reducejoin结果进行union合并



















 872
872











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









