






文章目录
前言:本篇文章主要分享一些 Hive 相关的知识点,欢迎纠错指正。
创建外部表
create external table loyalty_program(
cust_id STRING,
fname STRING,
lname STRING,
email STRING,
level STRING,
phone MAP<STRING,STRING>, # 键值对
order_ids ARRAY<STRING>, # 数组
order_value STRUCT<min:int,max:int,average:int,total:int> # 结构体
)
row format delimited
fields terminated by '|'
collection items terminated by ','
map keys terminated by ':' ;
# 从 HDFS 中加载数据
load data inpath("/dualcore/loyalty_data.txt") overwrite into table loyalty_program;
# 从本本地加载数据
load data local inpath("/dualcore/loyalty_data.txt") overwrite into table loyalty_program;
分隔符解析:
| 名称 | 含义 |
|---|---|
| ROW FORMAT DELIMITED | 分隔符设置开始语句 |
| FIELDS TERMINATED BY | 设置字段与字段之间的分隔符 |
| COLLECTION ITEMS TERMINATED BY | 设置一个复杂类型(array,struct)字段的各个 item 之间的分隔符 |
| MAP KEYS TERMINATED BY | 设置一个复杂类型(Map)字段的key value之间的分隔符 |
| LINES TERMINATED BY | 设置行与行之间的分隔符 |
Hive 执行顺序

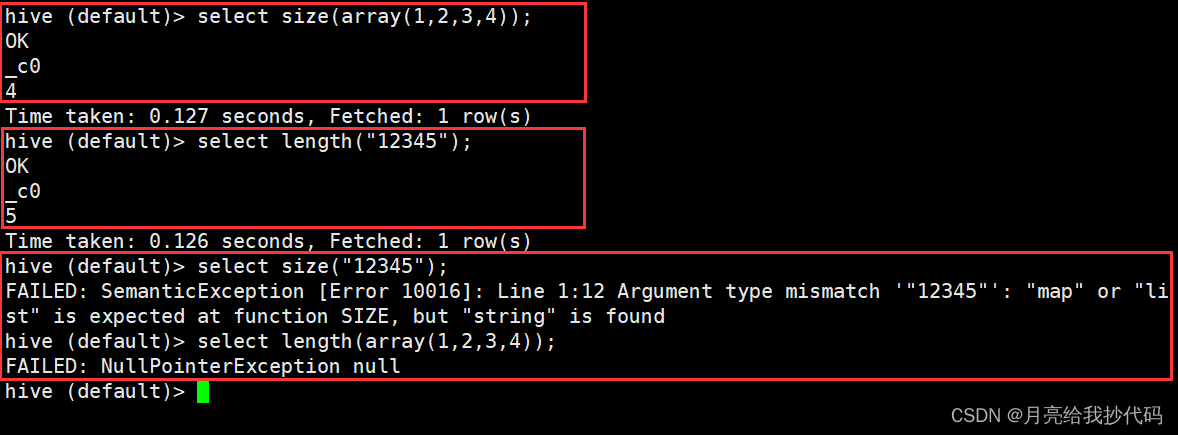
size 与 length
-
size 获取集合类型长度
-
length 获取字符串的长度
连接
示例数据:
# 创建库
drop database if exists school;
create database school;
use school;
# 创建学生表
create table if not exists student(
id int comment "学号id",
name string comment "姓名",
sex string comment "性别",
age int comment "年龄",
classid string comment "班级 id");
# 创建班级表
create table if not exists class(
classid string comment "班级 id",
name string comment "班级名称",
num int comment "班级人数");
# 向学生表中插入数据
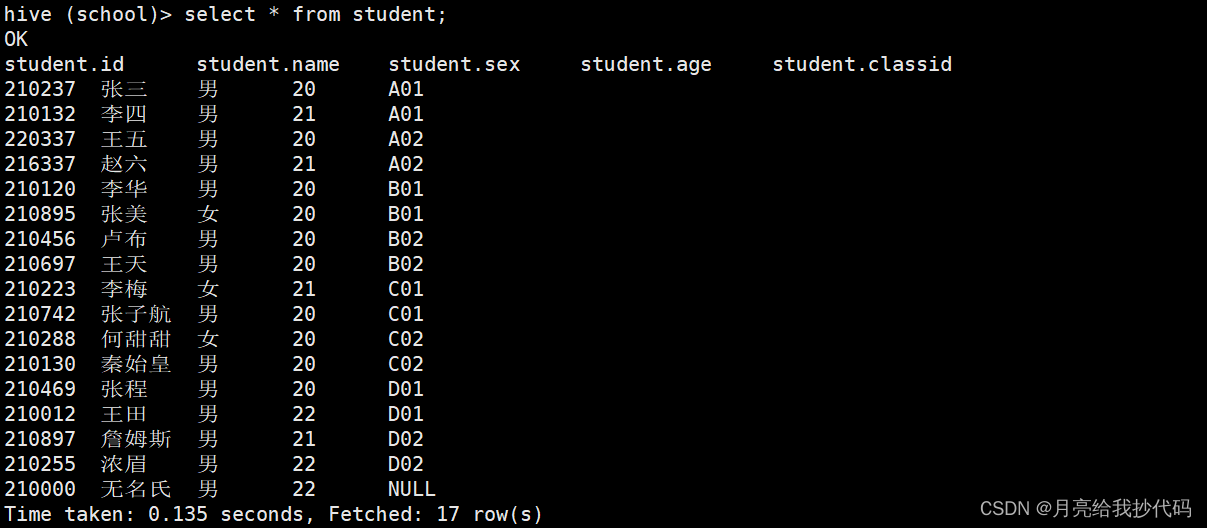
insert into student values(210237,"张三","男",20,"A01"),(210132,"李四","男",21,"A01"),(220337,"王五","男",20,"A02"),(216337,"赵六","男",21,"A02"),(210120,"李华","男",20,"B01"),(210895,"张美","女",20,"B01"),(210456,"卢布","男",20,"B02"),(210697,"王天","男",20,"B02"),(210223,"李梅","女",21,"C01"),(210742,"张子航","男",20,"C01"),(210288,"何甜甜","女",20,"C02"),(210130,"秦始皇","男",20,"C02"),(210469,"张程","男",20,"D01"),(210012,"王田","男",22,"D01"),(210897,"詹姆斯","男",21,"D02"),(210255,"浓眉","男",22,"D02"),(210000,"无名氏","男",22,NULL);
# 向班级表中插入数据
insert into class values("A01","大数据一班",40),("A02","大数据二班",41),("B01","物联网一班",37),("B02","物联网二班",38),("C01","移动互联一班",42),("C02","移动互联二班",39),("D01","人文科学一班",45),("D02","人文科学二班",46);
基础连接(内连接) —— join(inner join)
inner join 其实就是 join,join 是它的简写方式。
根据连接条件,最终输出只符合条件的数据。
根据班级 id 进行连接,输出所有数据。
select * from student join class on student.classid = class.classid;
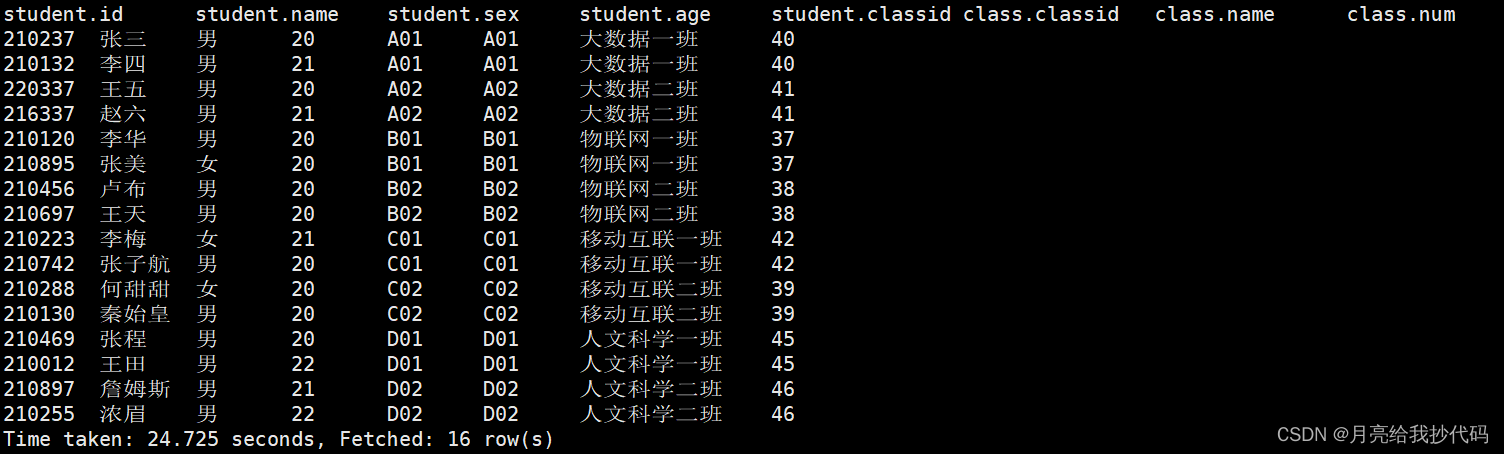
从结果中可以看到,通过连接条件,我们过滤掉了班级 id 中为 null 的值。
左连接 —— left join
根据连接条件,获取到左表的全部数据和右表符合条件的数据,左表始终都会输出。
根据班级 id 进行左连接,输出所有数据。
select * from student left join class on student.classid = class.classid;

右连接 —— right join
根据连接条件,获取到右表的全部数据和左表符合条件的数据,右表始终都会输出。
根据班级 id 进行右连接,输出所有数据。
select * from student right join class on student.classid = class.classid;

全连接 —— full join
不管条件是否符合,最终都会获取到两个表的所有数据。
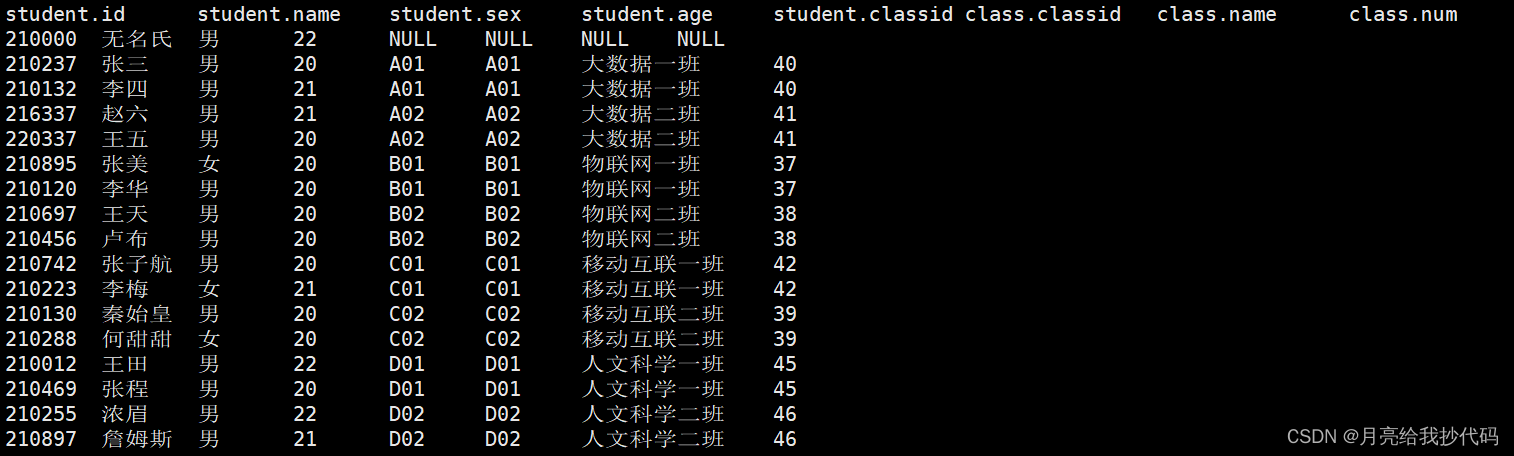
根据班级 id 进行全连接,输出所有数据。
select * from student full join class on student.classid = class.classid;
多表连接
多个表之间进行连接操作。
select 表名.列名
from 表名1
inner join 表名2
on 表名1.列=表名2.列
inner join 表3
on 表名2.列=表名3.列
子查询连接 —— with
关键词 with 主要用于子查询时使用,语法如下:
with 表别名 as (子查询),
表别名 as (子查询),
......
select
......
需要注意的是,多个子查询之间使用逗号 , 进行隔开。
函数
Hive 中的关键词不区分大小写,空值 null 不参与 UDAF 计算 、聚合函数等等!
count
在 SQL 中常用的聚合统计函数,用于统计个数。
在 Hive 中创建了如下表:
select count(1),count(2),count(0),count(classid),count(null) from student;
输出结果为:
count(1) count(2) count(0) count(classid) count(null)
17 17 17 16 0
结论:count 中的参数只要不为 null 值都会按 1 进行统计。空值 null 不参与 UDAF 计算 、聚合函数!
分区与排序
在 Hive 中一般分区会与排序函数一起使用。
语法:distribute by col sort by col2,distribute by 用于指定分区字段,sort by 用于指定排序字段。
示例:
在 Hive 中创建了如下数据表:
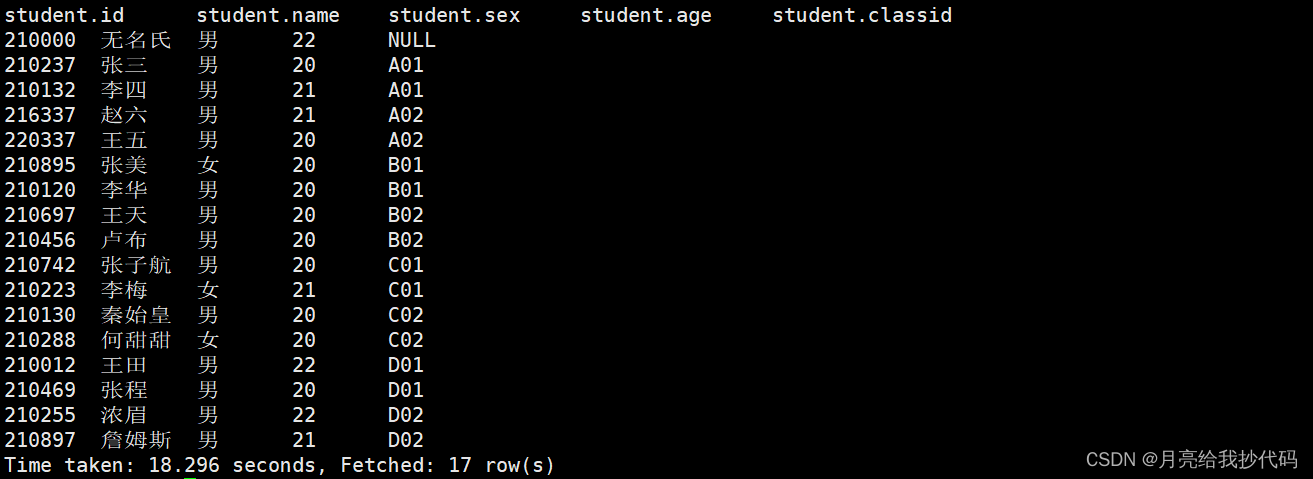
需求:按 classid 进行分区,然后根据 classid 进行升序排列。
select * from student distribute by classid sort by classid;
输出结果:
nvl 空值替换
顾名思义,就是替换空值 null。
示例:
select nvl(null,"nvl test!");
输出结果为:
nvl test!
coalesce 空值替换
和 nvl 一样也是空值替换,但是其有点特殊,coalesce 是返回传入参数中第一个为 true 的值。
示例:
select coalesce(null,"coalesce test!",null,"hello world.");
输出结果为:
coalesce test!
如果传入的参数都为空值,那么最终返回的结果也为空值 null。
条件分支
if
if 条件判断语句,相信大家都比较熟悉了。
语法:if (boolean, result1, result2) 如果 boolean 为真,返回 result1,否则返回 result2
示例:
select if(null,"if test!","hello world");
输出结果为:
hello world
case
case 在 Hive 中有两种形式,一种是像开关语句一样使用,还有一种就是像条件判断语句使用。
语法1(开关语句):
case col
when val1 then result1
when val2 then result2
else result3
end
语法2(条件判断语句):
case
when boolean then result1
when boolean then result2
else result3
end
学过编程的应该都容易理解,这里使用语法 2 作为示例:
select case when 1 > 2 then "这不可能" when 1 > 1 then "这似乎也不可能" else "我觉得可以~" end;
输出结果为:
我觉得可以~
字符串拼接
在 Hive 中字符串拼接有两个函数:
concat:concat(val,val2,val3...)
concat_ws:concat_ws(sep, array | val,val2,val3...),可以指定分隔符。
示例:
select concat("hello","world");
select concat_ws("-",array("hello","world"));
select concat_ws("-","hello","world");
按顺序输出结果为:
helloworld
hello-world
hello-world
字符串分割
split:split(str, sep) ,将字符串根据指定分隔符进行切割,结果返回一个数组。
示例:
select split("hello,world",",");
输出结果为:
["hello","world"]
字符串截取
substring:substring(str,pos,len),根据指定的开始下标和长度,对字符串进行切割。
需要注意的是下标从 1 开始。
示例:
select substring("hello,world",1,5);
select substring("hello,world",1);
按顺序输出结果为:
hello
hello,world
列转行
在 Hive 中列转行有两个函数:
collect_list:collect_list(col)
collect_set:collect_set(col),会对聚合的结果进行去重。
示例:
在 Hive 中创建了如下数据表:
需求:将各班的学生姓名在一行中显示输出。
select classid,collect_list(name) names from student group by classid;
输出结果:

行转列
在 Hive 中行转列分为几个步骤,先用 explode(array | map) 对行数据转换为列数据,然后再通过 lateral view ... 创建临时视图表(侧视图)进行输出。
示例:
在 Hive 中创建了一张电影表,如下所示:

通过该表,我们先来看一下 explode 的用法:
select explode(split(category,",")) from movies;
输出结果:
爱情
动作
虚幻
情感
在实际应用中行转列一般会配合 lateral view 一起使用。
需求:根据电影表中的类型,通过逗号进行分割转换为行,最终输出如下。
怦然心动 爱情
怦然心动 动作
楚门的世界 虚幻
楚门的世界 情感
select m.name,tmp.category from movies m lateral view explode(split(category,",")) tmp as category;
解析:
select
m.name,
tmp.category
from
movies m
lateral view
explode(split(category,",")) tmp as category;
# tmp 表示侧视图的名称
# category 表示侧视图的字段名称
最终输出结果如下:

窗口函数
over:相当于对某一个分析函数做前置处理。
语法1:分析函数 over(partition by 列名 order by 列名 rows between 开始位置 and 结束位置)
语法2:分析函数 over(distribute by 列名 sort by 列名 rows between 开始位置 and 结束位置)
over() 函数中有三个函数:分区:partition by | distribute by ,排序: order by | sort by 列名,指定窗口范围:rows between 开始位置 and 结束位置。
在 rows between 开始位置 and 结束位置 中有六个参数可选:
-
CURRENT ROW:当前行
-
n PRECEDING:往前 n 行数据
-
n FOLLOWING:往后 n 行数据
-
UNBOUNDED:起点
-
UNBOUNDED PRECEDING 表示从前面的起点
-
UNBOUNDED FOLLOWING 表示到后面的终点
如果不指定任何函数,则默认对整个表进行操作,反之则是对指定的范围进行操作。
示例:
在 Hive 中创建了如下数据表:
需求:根据 classid 统计出每个班级的人数。
select distinct classid,count(1) over(partition by classid) from student;
输出结果:

现在我们对这个需求进行的升级,统计出每个专业的人数,如:A01,A02 都为 A 专业。
select distinct substring(classid,1,1) classid,count(1) over(partition by substring(classid,1,1)) from student;
输出结果:

lag 与 lead
在窗口函数中,lag 与 lead 用于获取指定字段前第 n 行的数据或者后第 n 行的数据,一般情况在排序后使用。
lag:lag(col, n, default_value) over(有序窗口),获取字段前第 n 行的数据,如果为空则是默认值。
lead:lead(col, n, default_value) over(有序窗口),获取字段后第 n 行的数据,如果为空则是默认值。
ntile
ntile:ntile(n) over(有序窗口),排序分桶,将数据分为 n 组,返回当前行的组号,常用于抽样查询。
示例:
在 Hive 中创建了如下数据表:

需求:根据性别进行分组,求出前 20% 的学生信息。
select
id,
name,
sex,
age,
classid
from
(select
id,
name,
sex,
age,
classid,
ntile(5) over(partition by sex order by id) n
from
student)t1
where n = 1;
输出结果:

思路: 因为我们需要根据性别进行分组,获取前 20% 的学生信息。我们可以先将其分为 5 组,然后直接取组号为 1 的数据,这样就完成需求啦。
窗口排序
在窗口函数中,有三个排序函数:
rank:rank() over(有序窗口),会跳过排名,如:1,2,2,4…
dense_rank:dense_rank() over(有序窗口),不会跳过排名,如:1,2,2,3…
row_number:row_number() over(有序窗口),行号标记,永不重复。如:1,2,3,4…
first_value / last_value
first_value:first_value(col, boolean) over(有序窗口),如果条件为假,返回这个窗口中 col 的第一行,为真返回这个窗口中 col 不为 null 的第一行。
last_value:last_value(col, boolean) over(有序窗口),如果条件为假,返回这个窗口中 col 的最后一行,为真返回这个窗口中 col 不为 null 的最后一行。
持续更新中…

















 536
536











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











