






文章目录
查询优化
在 Hive 中查询字段时使用列裁剪的方式进行查询,而不要使用 select * from ... 这种语法。列裁剪:写明要查询的字段,即使你查询的是该表的所有字段,这样能够有效提高查询效率,提高内存使用率。
在进行分区查询的时候要避免全盘扫描,通过增加过滤条件,提高查询效率。
谓词下推
谓词下推是许多数据库引擎中都具有的一种优化策略,通过条件进行过滤,将在 map 端提前执行,减少 map 端输出,降低了数据传输 IO,节约资源,提升性能。
谓词下推设置(默认为开启状态):
set hive.optimize.ppd = true;
下面通过一个案例来直接讲述什么是谓词下推。
我在 Hive 中创建了如下两张表格:
student 学生表
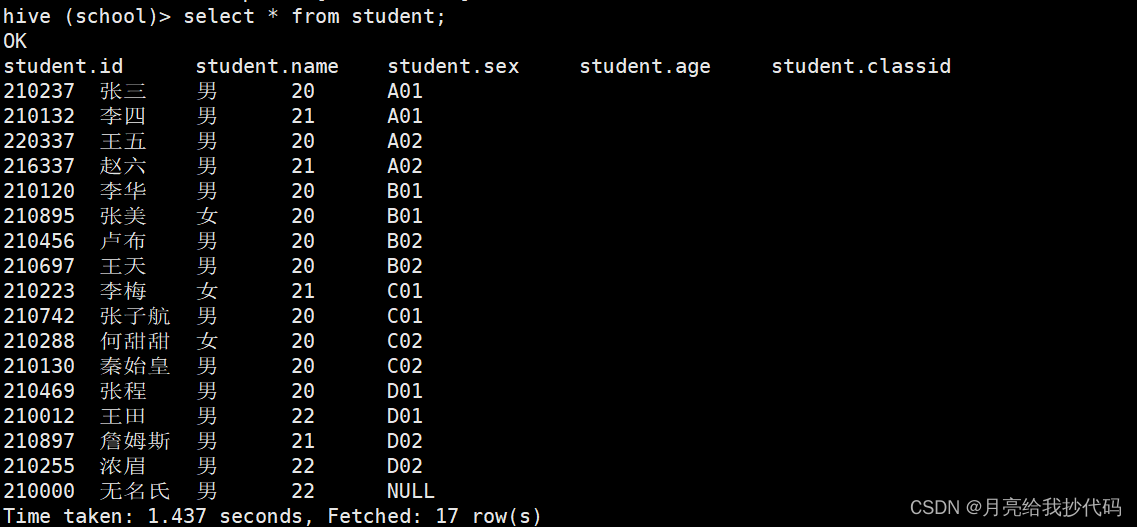
class 班级表
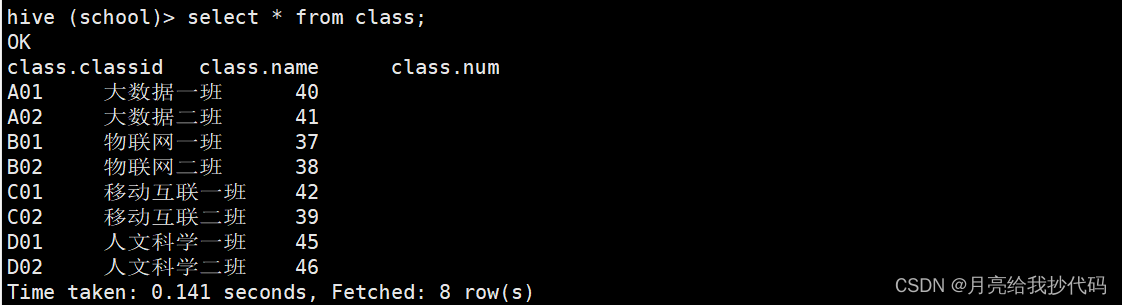
现在将两张表通过 classid 字段进行连接,获取学生 id 在 210255 以上的所有数据,根据学生 id 升序排列。
select
s.id,
s.name,
s.sex,
s.age,
s.classid,
c.name
from
student s
join
class c
on s.classid = c.classid
where s.id > 210255
order by s.id;
查询结果如下:
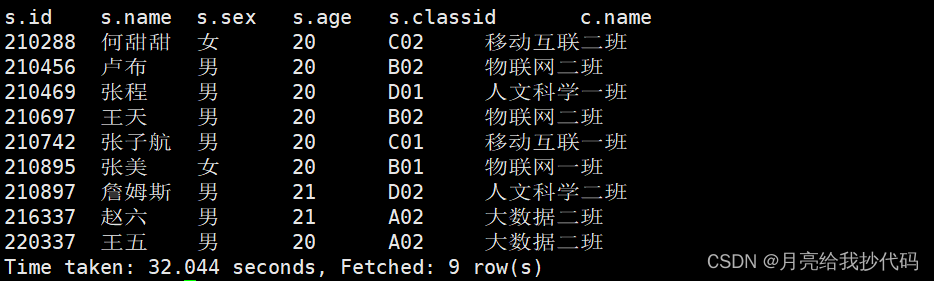
稍作思考,你觉得这句 SQL 是怎样执行的呢?
再你没有了解谓词下推之前,我猜一下,你可能是这样想的:
-
先对两张表进行
join操作; -
执行
where进行过滤; -
select; -
order by。
现在我们来一探究竟,我们直接来查看 Hive 对这句 SQL 的执行计划,在 SQL 语句前加一个关键词 explain 即可。
class 表执行计划:
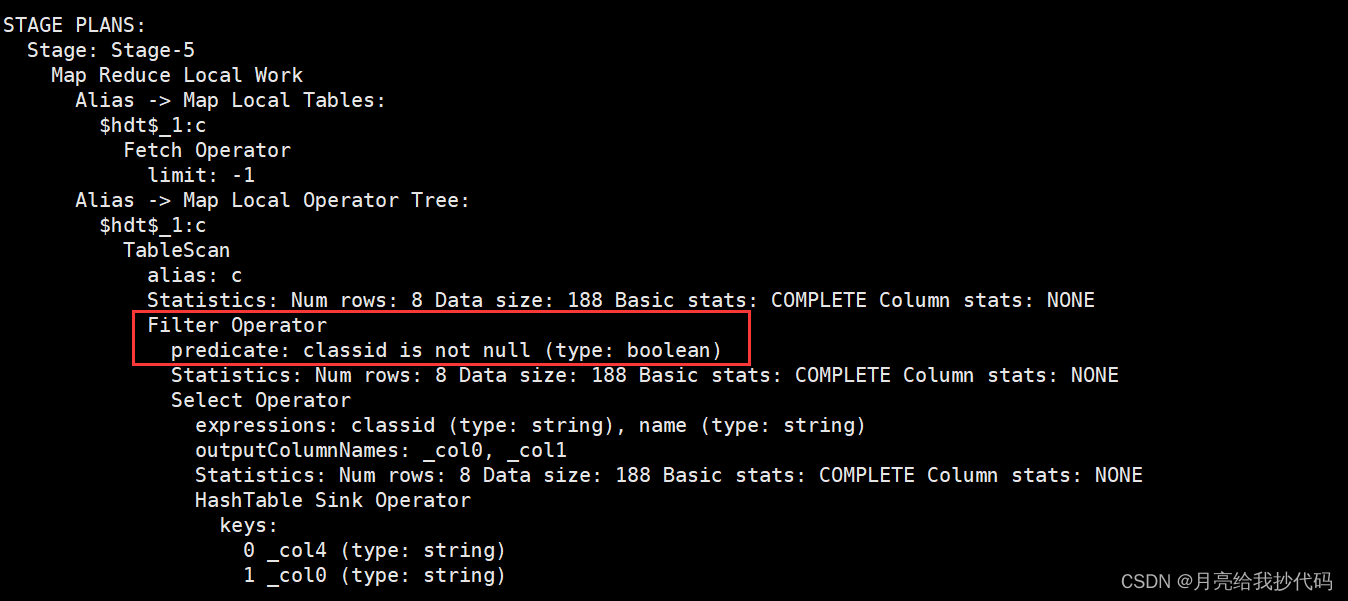
student 表执行计划:
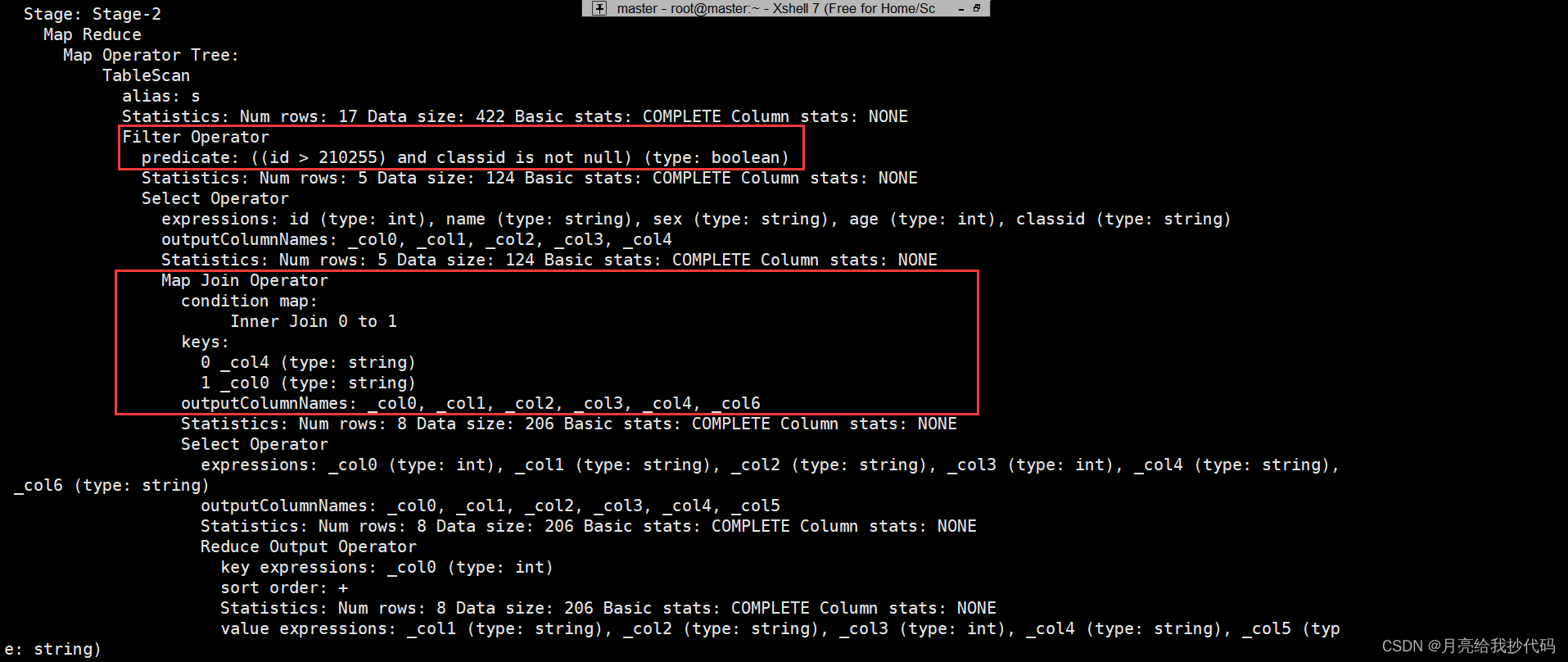
通过对执行计划的阅读,我们会发现它先对连接的 class 表 进行过滤。然后来看 student 表 的执行计划,在进行表的 join 操作之前,它也会先进行条件过滤,然后再进行 join 操作,最后就是 select 和 order by 的操作了。
这样就有效的减少了 join 时的数据量,节约资源,提高了 SQL 的整体运行效率,这就叫谓词下推。
笛卡尔积
笛卡尔积会使数据量以倍数增大,造成数据爆炸。我们必须避免笛卡尔积,如:join 操作的时候不加 on 条件或无效的条件。
我们可以通过开启 Hive 严格模式来设置避免笛卡尔积。
// 查看当前严格模式的状态
set hive.mapred.mode;
// 设置为严格模式
set hive.mapred.mode=strict;
// 设置为非严格模式
set hive.mapred.mode=nostrict;
需要注意的是,如果开启了 Hive 严格模式,还应当避免一下场景:
-
禁止分区表全表扫描;
-
禁止排序不加
limit; -
禁止笛卡尔积;
开启后如果违反上述场景,将会直接报错。
MR 程序优化参数
客户端显示以及 job 任务名和优先级
打印表头
set hive.cli.print.header=true;
显示当前数据库
set hive.cli.print.current.db=true;
job 任务名
set mapreduce.job.name=p_${v_date};
job 优先级
set mapred.job.priority=HIGH;
设置 job 的队列名
set mapreduce.job.queuename;
使⽤ Hive 的正则表达式,过滤掉不需要的列名
set hive.support.quoted.identifiers=none;
SELECT `(id|100name)?+.+` from st;
map 与 reduce 内存调整
⼀个 MapTask 可使⽤的资源上限。内存溢出了,原因是数据量太⼤,导致在 map 的阶段内存不⾜
set mapreduce.map.memory.mb=9000;
set mapreduce.map.java.opts=-Xmx4096m-XX:+UseConcMarkSweepGC;
可能出现在 reduce 的阶段,reduce 设置的内存通常⽐ map 端设置的要大
set mapreduce.reduce.memory.mb=9000;
set mapreduce.reduce.java.opts=-Xmx8196m;
环形缓冲区⼤⼩,⼀般为1/3、1/2的 map 的 java 堆栈内存,减⼩ spill 溢写次数。
set mapreduce.task.io.sort.mb=512
map 阶段减少合并 meger 次数默认10,如果⽂件数很多,增大减少合并次数
set io.sort.factor
动态分区参数设置
-- 是否开启动态分区,默认true
set hive.exec.dynamic.partition=true;
-- 是否开启非严格模式,默认strict
set hive.exec.dynamic.partition.mode=nonstrict;
-- 每个 mr 可以创建的最大动态分区个数,默认100
set hive.exec.max.dynamic.partitions.pernode = 100;
-- mr 总共可创建的最⼤分区数,默认1000
set hive.exec.max.dynamic.partition.partitions = 1000;
-- 一个 mapreduce 作业能创建的 HDFS 文件最大数,默认100000
set hive.exec.max.created.files=100000;
-- 是否开启⾃动分区。适⽤于动态分区数过多插⼊的优化,默认false,(动态分区列将进⾏全局排序)
set hive.optimize.sort.dynamic.partition=true
开启支持正则表达式
set hive.support.quoted.identifiers=none;
mapper 输入文件合并的参数
每个 Map 最大输入大小
set mapred.max.split.size=256000000;
⼀个节点上 split 的最小值(这个值决定了多个 DataNode 上的文件是否需要合并) ,单位 kb。
set mapred.min.split.size.per.node=100000000;
⼀个交换机下 split 的最小值(这个值决定了该机架下的文件是否需要合并) ,单位 kb。
set mapred.min.split.size.per.rack=100000000;
执行 Map 前进行小文件合并,默认开启
set hive.input.format=org.apache.Hadoop.hive.ql.io.CombineHiveInputFormat;
设置 map 输出和 reduce 输出进行合并的参数设置
map 输出和 reduce 输出进行合并的相关参数
hive.merge.mapfiles= true
设置 reduce 端输出进行合并,默认为false
hive.merge.mapredfiles= true
设置合并文件的大小,合并之后每个文件大小为 256M
hive.merge.size.per.task= 256 *1000 * 1000
输出文件的平均大小小于该值时,启动⼀个独立的 MapReduce 任务进行文件合并
hive.merge.smallfiles.avgsize=16000000
设置 reduce 个数
强制设置 reducer 个数
set mapred.reduce.tasks
Hive 根据每个 reducer 处理的数据量大小,自动推算 reducer 个数
-- 默认每个 reducer 为 1G
hive.exec.reducers.bytes.per.reducer = 1000000000;
-- hive 推算的最大值,默认999
hive.exec.reducers.max = 999;
设置的参数在以下情况出现时会失效:
- sql 语句中没有 group by 的汇总
- 使用了 order by
- 有笛卡尔积
- map端输出的数据量小于
hive.exec.reducers.bytes.per.reducer参数值
设置 map 个数
强制设置 map 个数
set mapred.map.tasks
这个两个参数联合起来用,主要是为了方便控制 mapreduce 的 map 数量。比如:我设置为1073741824,就是为了让每个 map 处理 1GB 的文件。默认 265M ⼀个块大小。
-- 切片最大值,默认值Long.MAXValue,因此,默认情况下,切片大小=blocksize。
set mapreduce.input.fileinputformat.split.maxsize
-- 切片最小值,默认为1
set mapreduce.input.fileinputformat.split.minsize
set mapreduce.input.fileinputformat.split.minsize.per.node=256000000;
set mapreduce.input.fileinputformat.split.minsize.per.rack=256000000;
map 个数和来源表文件压缩格式有关,.gz格式的压缩文件无法切分,每个文件会生成⼀个 map 只有这个参数打开,下面的 3 个参数才能生效
set hive.hadoop.supports.splittable.combineinputformat=true;
-- 每个map负载
set mapred.max.split.size=16000000;
--每个节点map的最⼩负载,这个值必须⼩于set mapred.max.split.size的值 (这个值决定了多个DataNode上的⽂件是否需要合并)
set mapred.min.split.size.per.node=100000000;
-- 每个机架map的最⼩负载(这个值决定了该机架下的⽂件是否需要合并)
set mapred.min.split.size.per.rack=100000000;
join 统计聚合之类的 sql ,防止数据倾斜
set hive.optimize.skewjoin=true;
set hive.skewjoin.key=500000;
set hive.skewjoin.mapjoin.map.tasks=10000;
set hive.skewjoin.mapjoin.min.split=33554432;
(1)是否在Map端进⾏聚合,默认为True hive.map.aggr = true
(2)在Map端进⾏聚合操作的条⽬数⽬hive.groupby.mapaggr.checkinterval = 100000
(3)有数据倾斜的时候进⾏负载均衡(默认是false) hive.groupby.skewindata = true
当选项设定为 true,⽣成的查询计划会有两个MR Job。第⼀个MR Job中,Map的输出结果会随机分布到Reduce中,每个Reduce做部分聚合操作,并输出结果,这样处理的结果是相同的Group By Key有可能被分发到不同的Reduce中,从⽽达到负载均衡的⽬的;第⼆个MR Job再根据预处理的数据结果按照Group By Key分布到Reduce中(这个过程可以保证相同的Group By Key被分布到同⼀个Reduce 中),最后完成最终的聚合操作
(4)hive.map.groupby.sorted=true 默认true map端groupby 排序,不必要的可以关闭
开启 map 输出阶段压缩可以减少 job 中 map 和 Reduce task 间数据传输量。
set hive.exec.compress.intermediate=true;
set mapreduce.map.output.compress=true;
set mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;
开启 Reduce 输出阶段压缩
set hive.exec.compress.output=true;
set mapreduce.output.fileoutputformat.compress=true;
set mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;
set mapreduce.output.fileoutputformat.compress.type=BLOCK;
并行执行
开启任务并行执行,默认false
set hive.exec.parallel=true;
同⼀个 sql 允许并行任务的最大线程数
set hive.exec.parallel.thread.number=16;
JVM 重利用
开启 JVM 重用
set mapreduce.job.jvm.numtasks=10;
-- 或者
set mapred.job.reuse.jvm.num.tasks=15
JVM重利⽤可以是Job长时间保留slot,直到作业结束,这对于有较多任务和较多⼩⽂件的任务是⾮常有意义的,因为减少了JVM的启动和初始化时间,从⽽减少执⾏时间。当然这个值不能设置过⼤,因为有些作业会有reduce任务,如果reduce任务没有完成,则map任务占用的slot不能释放,其他作业可能就需要等待。
本地模式
Hive可以通过本地模式在单台机器上处理所有的任务。对于小数据集,执行时间可以明显被缩短。
set hive.exec.mode.local.auto=true;
set hive.exec.mode.local.auto.inputbytes.max=50000000; set hive.exec.mode.local.auto.input.files.max=10;
yarn 优化
-- 给应⽤程序Container分配的最⼩内存,默认值:1024
yarn.scheduler.minimum-allocation-mb
-- 给应⽤程序Container分配的最⼤内存,默认值:8192
yarn.scheduler.maximum-allocation-mb
-- 每个Container申请的最⼩CPU核数,默认值:1
yarn.scheduler.minimum-allocation-vcores
-- 每个Container申请的最⼤CPU核数,默认值:32
yarn.scheduler.maximum-allocation-vcores
-- 给Containers分配的最⼤物理内存,默认值:8192
yarn.nodemanager.resource.memory-mb
容错性优化
-- 每个Map Task最⼤重试次数,⼀旦重试参数超过该值,则认为Map Task运⾏失败,默认值:4。
mapreduce.map.maxattempts
-- 每个Reduce Task最⼤重试次数,⼀旦重试参数超过该值,则认为Map Task运⾏失败,默认值: 4。
mapreduce.reduce.maxattempts
mapreduce.task.timeout
-- Task超时时间,经常需要设置的⼀个参数,该参数表达的意思为:如果⼀个Task在⼀定时间内没有任何进⼊,即不会读取新的数据,也没有输出数据,则认为该Task处于Block状态,可能是卡住了,也许永远会卡住,为了防⽌因为⽤户程序永远 Block住不退出,则强制设置了⼀个该超时时间(单位毫秒),默认是600000。如果你的程序对每条输⼊数据的处理时间过长(⽐如会访问数据库,通过⽹络拉取数据等),建议将该参数调⼤,该参数过⼩常出现的错误提⽰是 “AttemptID:attempt_14267829456721_123456_m_000224_0 Timed out after 300 secsContainer killed by the ApplicationMaster.”。
MapJoin
-- 设置⾃动选择 MapJoin,默认为true。
set hive.auto.convert.join = true;
-- ⼤表⼩表的阀值设置(默认25M⼀下认为是⼩表)注:⾼版本可能不起作⽤了。
set hive.mapjoin.smalltable.filesize=25000000;
--表⽰是否启⽤ hive 根据输⼊⽂件的⼤⼩,将普通的表连接转化为MapJoin, 默认值true。
hive.auto.convert.join.noconditionaltask:
-- 如果输⼊⽂件的⼤⼩⼩于该参数设定的值,则将普通的表连接转化为MapJoin,默认值10000000(字节数)。
hive.auto.convert.join.noconditionaltask.size:
压缩算法对比
| 压缩格式 | 工具 | 算法 | 文件扩展名 | 是否可切分 |
|---|---|---|---|---|
| DEFLATE | 无 | DEFLATE | .deflate | 否 |
| Gzip | gzip | DEFLATE | .gz | 否 |
| bzip2 | bzip2 | bzip2 | .bz2 | 是 |
| LZO | lzop | LZO | .lzo | 否 |
| LZ4 | 无 | LZ4 | .lz4 | 否 |
| Snappy | 无 | Snappy | .snappy | 否 |

















 2167
2167











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











