






第一步,环境配置
首先,你要确保你的集群可以正常运行。
我们在 Windows 电脑中安装 Hadoop,并配置环境变量。注意,Hadoop 的版本必须和集群中的对应,然后将压缩包解压到你想要存放的地方。

我集群是 hadoop-2.7.7,所以 Windows 中也装这个版本。
将 Hadoop 的 Windows 依赖 winutils.exe、hadoop.dll 放入 bin 目录下。

依赖下载:Hadoop 的 Windows 依赖
注意,我在上面这个下载链接里放的依赖文件只支持 hadoop-3.1.0 及其以下的版本,如果比这个版本高的可以去官网下载依赖文件。
其它版本依赖下载: https://gitee.com/fulsun/winutils-1
配置 Windows 环境变量。
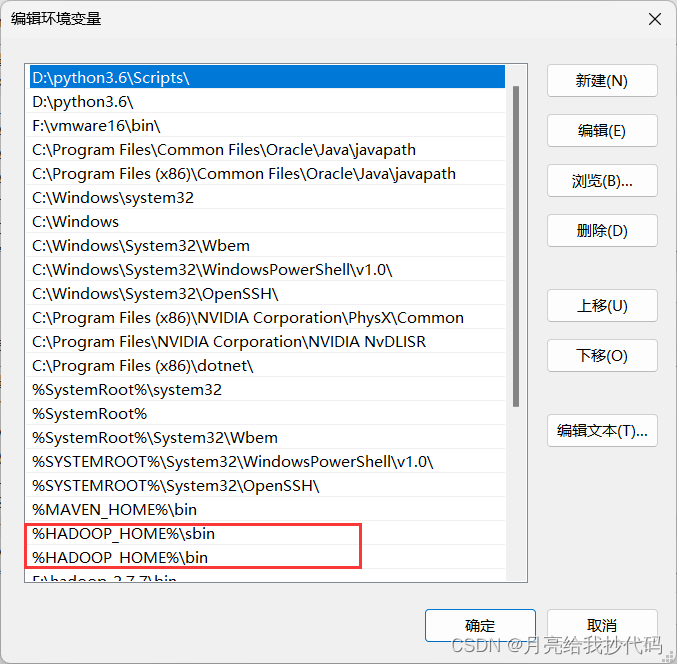
在 Windows 系统变量中新建 Hadoop 主目录和用户,以及添加 Path。
# 本地的安装目录
HADOOP_HOME
# 指定访问用户,建议用 root
HADOOP_USER_NAME

下滑找到 Path 变量,双击进入,然后新建两个 PATH,以指定 Hadoop 脚本路径。

%HADOOP_HOME%\sbin
%HADOOP_HOME%\bin
注意,环境变量需要重启电脑后才会生效。
第二步,IDEA 配置
将 Hive 的配置文件拷贝一份到 IDEA 项目中的 resource 目录下:

修改一下其中的连接地址:

改成集群的地址。
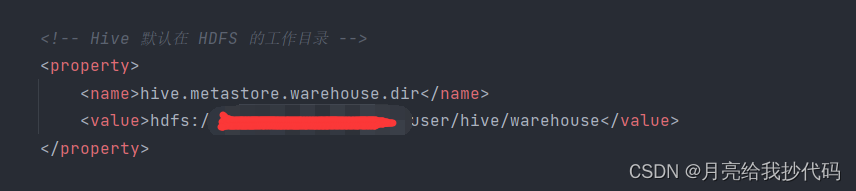
Hive 的存储路径前面加上 HDFS 的路径。
我看网上说还要放 core-site.xml 和 hdfs-site.xml,纯属扯淡。
在项目的 pom 文件中添加依赖:
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.27</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>3.0.0</version>
</dependency>
</dependencies>
第三步,授权
进入集群中的 MySQL,授予权限。
grant all privileges on *.* to hive@'%' identified by "root";
第四步,连接测试

扩展——华为云/阿里云集群
如果你使用的集群在华为云或者阿里云上,你需要先配置好集群的 hosts 映射文件,这就不用多说了吧。
如下所示:

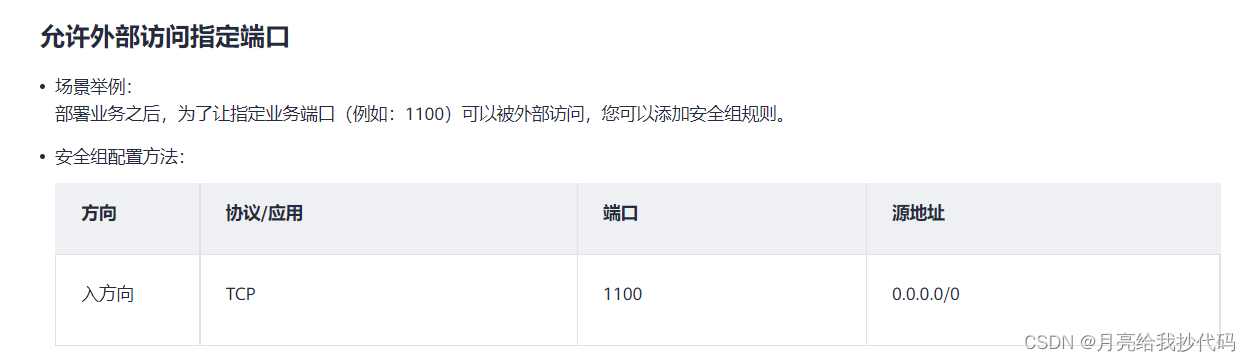
其次就是你要对你的端口进行放行,配置安全规则。
如下所示:
报错
在往 Hive 中插入数据时可能会报如下错误:
could only be replicated to 0 nodes instead of minReplication (=1). There are 1 datanode(s) running
修改集群中 Hadoop 的配置文件 hdfs-site.xml,添加如下参数:
<property>
<name>dfs.datanode.use.datanode.hostname</name>
<value>true</value>
</property>
表示 DataNode 之间的通信也通过域名方式。
然后在代码中也添加上这个参数,如下:
val spark: SparkSession = SparkSession
.builder()
.appName("test")
.master("local[*]")
.config("dfs.client.use.datanode.hostname", "true")
.enableHiveSupport()
.getOrCreate()
完美解决这个问题。
任务完成了,但返回了如下错误:
ERROR KeyProviderCache: Could not find uri with key [dfs.encryption.key.provider.uri] to create a keyProvider !!
这个是由于你的路径中存在中文所引起的,不会对程序结果造成影响。在 Hadoop 2.8 版本以后这个错误则不会出现。
















 87
87











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











