






我所使用的版本信息如下:
- Spark 3.0.0
- HBase 2.2.3
- Scala 2.12
- JDK 1.8
pom 依赖:
注意改成自己对应的版本。
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>2.2.3</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-mapreduce</artifactId>
<version>2.2.3</version>
</dependency>
Spark 写入 HBase
我们先创建一个文件用于写入,文件类型无所谓,我这里将文件名取为:test.csv。
city_name,province_name,total_amount,total_count,sequence,year,month
上海市,上海市,121773688,28456,1,2022,4
上海市,上海市,37040482,8635,1,2022,3
上海市,上海市,31189394,7429,1,2022,5
浙江省杭州市,浙江省,14136866,3344,1,2022,4
江苏省南京市,江苏省,12868037,2999,1,2022,4
写入代码文件示例:
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.hbase.client._
import org.apache.hadoop.hbase.util.Bytes
import org.apache.hadoop.hbase.{HBaseConfiguration, NamespaceDescriptor, TableName}
import org.apache.spark.sql.{DataFrame, SparkSession}
object MyWriteHBase {
// 创建一个全局的 HBaseConf
private val hbaseConf: Configuration = HBaseConfiguration.create()
// 连接对象
hbaseConf.set("hbase.zookeeper.quorum","master,slave1,slave2")
// 连接端口
hbaseConf.set("hbase.zookeeper.property.clientPort","2181")
// 跳过版本验证
hbaseConf.set("hbase.default.for.version.skip","true")
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.
builder()
.appName("MyWriteHBase")
.master("local[*]")
.getOrCreate()
// 读取写入的测试数据集
val dataFrame: DataFrame = spark.read.option("header", "true").csv("test.csv")
// 创建连接对象
val conn: Connection = ConnectionFactory.createConnection(hbaseConf)
// TODO 在 HBase 中创建库表
// 获取管理员权限
val admin: Admin = conn.getAdmin
// 判断表是否存在,demo 表示库名,order 表示表名
val tableName: TableName = TableName.valueOf("demo:order")
if(!admin.tableExists(tableName)){
// 创建库
val descriptor: NamespaceDescriptor = NamespaceDescriptor.create("demo").build()
admin.createNamespace(descriptor)
// 创建表对象
val table: TableDescriptorBuilder = TableDescriptorBuilder.newBuilder(tableName)
// 添加列族
val columnFamilyDescriptor: ColumnFamilyDescriptor = ColumnFamilyDescriptorBuilder.newBuilder("info".getBytes()).build()
// 将列族添加到表中
table.setColumnFamily(columnFamilyDescriptor)
// 创建表
admin.createTable(table.build())
}
admin.close()
conn.close()
// TODO 写入数据
// 指定列族
val cloumnName = "info"
dataFrame.rdd.foreachPartition(iter=>{
// 创建连接对象
val conn: Connection = ConnectionFactory.createConnection(hbaseConf)
// 获取指定表连接
val table: Table = conn.getTable(TableName.valueOf("demo:order"))
iter.foreach(r=>{
val put = new Put(Bytes.toBytes(UUID.randomUUID().toString)) // RowKey
// 指定列族,列名,值
put.addColumn(Bytes.toBytes(cloumnName),Bytes.toBytes("city_name"),Bytes.toBytes(r.getString(0)))
put.addColumn(Bytes.toBytes(cloumnName),Bytes.toBytes("province_name"),Bytes.toBytes(r.getString(1)))
put.addColumn(Bytes.toBytes(cloumnName),Bytes.toBytes("total_amount"),Bytes.toBytes(r.getString(2)))
put.addColumn(Bytes.toBytes(cloumnName),Bytes.toBytes("total_count"),Bytes.toBytes(r.getString(3)))
put.addColumn(Bytes.toBytes(cloumnName),Bytes.toBytes("sequence"),Bytes.toBytes(r.getString(4)))
put.addColumn(Bytes.toBytes(cloumnName),Bytes.toBytes("year"),Bytes.toBytes(r.getString(5)))
put.addColumn(Bytes.toBytes(cloumnName),Bytes.toBytes("month"),Bytes.toBytes(r.getString(6)))
// 向 HBase 提交,如果遇到报错就关闭表连接
Try(table.put(put)).getOrElse(table.close())
})
// 关闭连接
conn.close()
table.close()
})
spark.stop()
}
}
Spark 读取 HBase
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.hbase.HBaseConfiguration
import org.apache.hadoop.hbase.client._
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapreduce.TableInputFormat
import org.apache.hadoop.hbase.util.Bytes
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
object MyReadHBase {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.
builder()
.appName("MyReadHBase")
.master("local[*]")
.getOrCreate()
// 创建一个全局的 HBaseConf
val hbaseConf: Configuration = HBaseConfiguration.create()
// 连接对象
hbaseConf.set("hbase.zookeeper.quorum","master,slave1,slave2")
// 连接端口
hbaseConf.set("hbase.zookeeper.property.clientPort","2181")
// 跳过版本验证
hbaseConf.set("hbase.default.for.version.skip","true")
// 指定连接表
hbaseConf.set(TableInputFormat.INPUT_TABLE,"demo:order")
// 获取 HBase 数据 rdd
val hbaseRdd: RDD[(ImmutableBytesWritable, Result)] = spark.sparkContext.newAPIHadoopRDD(hbaseConf, classOf[TableInputFormat], classOf[ImmutableBytesWritable],
classOf[Result])
// TODO 读取数据
// 指定列族
val cloumnName = "info"
import spark.implicits._
hbaseRdd.map{
case (_,result: Result) =>
val row: String = Bytes.toString(result.getRow) // 获取 RowKey
// 获取指定列族的相关列数据
val city_name: String = Bytes.toString(result.getValue(cloumnName.getBytes(), "city_name".getBytes()))
val province_name: String = Bytes.toString(result.getValue(cloumnName.getBytes(), "province_name".getBytes()))
val total_amount: String = Bytes.toString(result.getValue(cloumnName.getBytes(), "total_amount".getBytes()))
val total_count: String = Bytes.toString(result.getValue(cloumnName.getBytes(), "total_count".getBytes()))
val sequence: String = Bytes.toString(result.getValue(cloumnName.getBytes(), "sequence".getBytes()))
val year: String = Bytes.toString(result.getValue(cloumnName.getBytes(), "year".getBytes()))
val month: String = Bytes.toString(result.getValue(cloumnName.getBytes(), "month".getBytes()))
(row,city_name,province_name,total_amount,total_count,sequence,year,month)
}
.toDF("row","city_name","province_name","total_amount","total_count","sequence","year","month")
.show()
spark.stop()
}
}
读取结果如下:
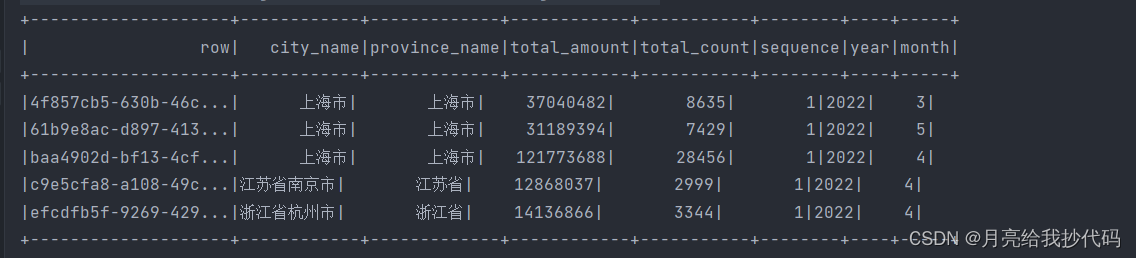
使用过程中如果报错,请检查相关包是否导入正确。

















 2065
2065











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











