




测试数据
create table if not exists sales(
id int,
product_id int,
quantity int,
sale_date string);
INSERT INTO sales (id, product_id, quantity, sale_date) VALUES
(1, 101, 2, '2024-05-16'),
(2, 102, 1, '2024-05-15'),
(3, 101, 3, '2024-05-15'),
(4, 103, 4, '2024-05-14'),
(5, 102, 2, '2024-05-14'),
(6, 101, 1, '2024-05-13'),
(7, 103, 3, '2024-05-13'),
(8, 104, 5, '2024-05-12'),
(9, 102, 4, '2024-05-11'),
(10, 105, 2, '2024-05-11'),
(11, 104, 2, '2024-05-11'),
(12, 106, 2, '2024-05-10'),
(13, 102, 2, '2024-05-10'),
(14, 101, 2, '2024-05-08'),
(15, 101, 2, '2024-05-08'),
(16, 105, 2, '2024-05-05'),
(17, 104, 2, '2024-05-01'),
(18, 106, 2, '2024-04-29'),
(19, 102, 2, '2024-04-20'),
(20, 101, 2, '2024-04-15');
需求说明
统计最近 1 天/ 7 天/ 30 天各个商品的销量(假设今天为 2024-05-17)。
结果示例:
| product_id | recent_days | total_quantity | total_sales |
|---|---|---|---|
| 101 | 1 | 3 | 3 |
| 101 | 7 | 6 | 4 |
| 101 | 30 | 10 | 6 |
| … | … | … | … |
结果按 recent_days 升序、total_quantity 降序排列。
其中:
product_id表示商品 ID;recent_days表示最近n天;total_quantity表示该商品的销售数量;total_sales表示该商品的销售次数(用户一次性购买多件该商品,只记录一次销售)。
需求实现
-- 最近1天
select
product_id,
1 recent_days,
sum(quantity) total_quantity,
count(product_id) total_sales
from
sales
where
sale_date = "2024-05-16"
group by
product_id
union all
-- 最近7天
select
product_id,
7 recent_days,
sum(quantity) total_quantity,
count(product_id) total_sales
from
sales
where
sale_date >= date_sub("2024-05-16",6) and sale_date <= "2024-05-16"
group by
product_id
union all
-- 最近30天
select
product_id,
30 recent_days,
sum(quantity) total_quantity,
count(product_id) total_sales
from
sales
where
sale_date >= date_sub("2024-05-16",29) and sale_date <= "2024-05-16"
group by
product_id
order by
recent_days,total_quantity desc;
输出结果如下:
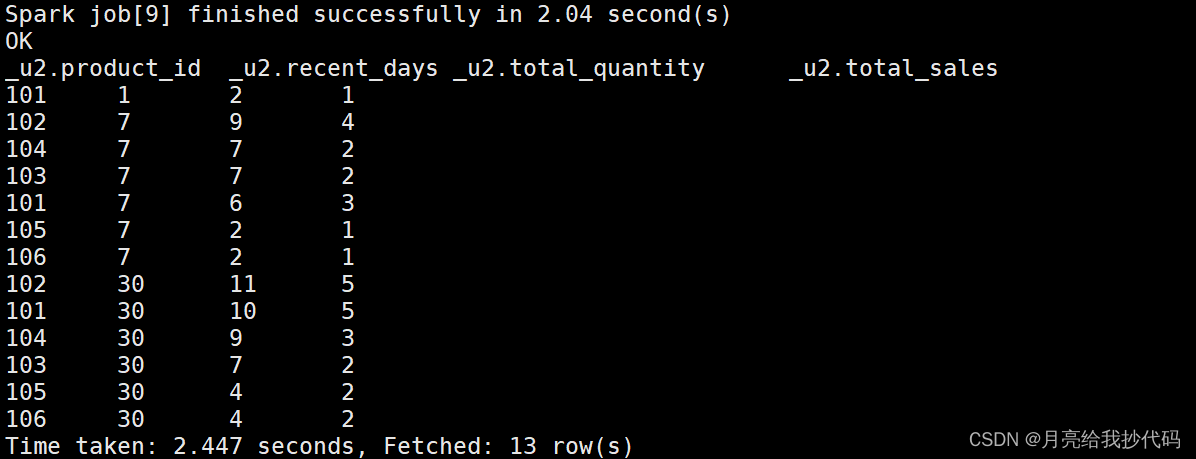
虽然这种方法可以算出结果,但是效率很低,我们需要算三次然后再进行合并,数据量一大的时候那就太慢了,那么有没有更好的方法呢?当然有!
首先来看优化完成后的 SQL 代码:
select
product_id,
rds recent_days,
sum(quantity) total_quantity,
count(product_id) total_sales
from
sales lateral view explode(array(1,7,30)) tmp as rds
where
sale_date >= date_sub("2024-05-16",rds - 1) and sale_date <= "2024-05-16"
group by
rds,product_id
order by
recent_days,total_quantity desc;
这里采用炸裂的方式,将一行数据变为了三行数据,(场景假设)如下所示:
炸裂前
| id | product_id | quantity | sale_date |
|---|---|---|---|
| 1 | 101 | 2 | 2024-05-16 |
| 2 | 102 | 1 | 2024-05-15 |
炸裂后
| id | product_id | quantity | sale_date | rds |
|---|---|---|---|---|
| 1 | 101 | 2 | 2024-05-16 | 1 |
| 1 | 101 | 2 | 2024-05-16 | 7 |
| 1 | 101 | 2 | 2024-05-16 | 30 |
| 2 | 102 | 1 | 2024-05-15 | 1 |
| 2 | 102 | 1 | 2024-05-15 | 7 |
| 2 | 102 | 1 | 2024-05-15 | 30 |
炸裂后,会新增一列 rds,也就是用来表示最近 n 天的标记。其中每行数据都会变成 3 行数据,即使数据量变多了也没有关系,因为我们设置了 where 条件进行过滤,它只会保留符合要求的数据,同样也不会对我们的结果造成影响。
这里不理解的话,可能是不了解 lateral view explode 方法的使用规则,可以百度了解一下。
假设今日为:
2024-05-17
例如:
-
商品
101在2024-05-16有用户进行了购买,所以该数据会保留在最近1天/7天/30天商品的销量结果中。 -
商品
102在2024-05-15有用户进行了购买,所以该数据会保留在最近7天/30天商品的销量结果中。 -
…
通过这种方法,我们不再需要写三个子查询然后再进行合并,一个查询即可搞定,提高了整体的运行速度。
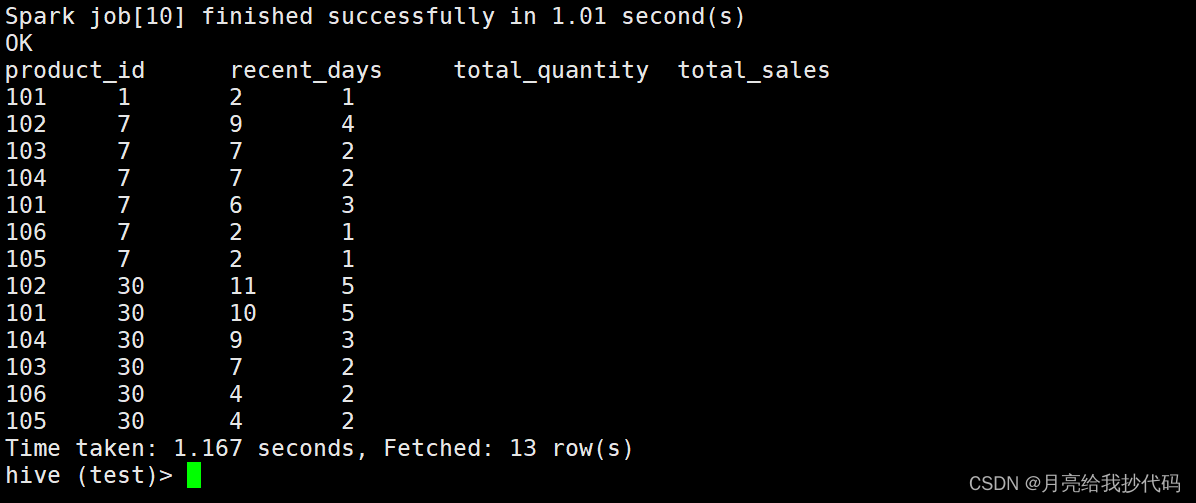
在这么小数据量的场景下都节省了 1 秒左右,可见一斑。



















 4548
4548

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











