







const和引用的关系
文章目录
1.1如何以C或者C++的方式编译代码
1.1.1 C的方式进行编译
- 更改代码后缀
- 默认方式以C的格式编译
- 配合C++的条件编译指令使用#else
1.1.2 以C++的方式编译
- 更改后缀为cpp
- 添加条件编译指令#ifndef __cpluscplus
#ifdef __cplusplus
#include<iostream>
using namespace std;
#else
#include<stdio.h>
#endif
int main()
{
const int a = 10;
int b = 0;
int *p = (int *)&a; //能力扩展错误,需要强制转换后才能使用,后面会有说明
*p = 100;
b = a;
#ifdef __cplusplus
cout << "a: " << a << "b:" << b << "*p: " << p << endl;
//10,10,100
#else
printf("a = %d, b = %d, *p = %d", a, b, *p);
#endif
return 0;
}
以_c++编译结果如下:

将文件后缀改为.c,并且将头文件引为<stdio.h>,以C的方式进行编译,结果如下:

为什么以c语言编译和以c++编译会得到不同的结果呢?
我们在VS2019上得到反汇编代码:
C++编译的反汇编如下:

通过观察第一行const int a = 10;下的反汇编代码,我们发现它是将通过mov指令将0Ah值直接传递给a。

在int *p = (int *)&a;下可以看出,首先将a的地址装载到eax中,然后将eax的地址保存到p中。

*p = 100; 我们可以看出,首先将p的值传递给eax寄存器,然后将100传递给寄存器eax保存的内存地址。并没有对a的值进行任何修改。

最后,将0Ah直接mov给b。

C语言的反汇编代码如下:

仔细对比,发现最后一行的mov指令,并非将0Ah立即数传递给b。而是将eax寄存器中保存的值传递给b。
而此时,eax寄存器在倒数第三个mov指令中已经被改编为64h(十进制的100)。
这时,就产生了答案,问题就产生在c语言和c++对常量的认知。
C++处理常量的机制是,在编译间段把用到常量的地方全部替换为常量的初始化的值。
C中处理const修饰的变量规则是,在编译间段看常变量有没有做左值,如果做了左值,以后就将此常变量当做普通变量来处理。综上所述,不能把常变量当做常量表达式来使用。
1.2 const 和引用的关系
1.2.1 首先看一下没有const 的情况:
int main()
{
int a = 10;
int &b = a;
int &c = a;
return 0;
}
在C++或C语言中,上述代码都没有任何问题。但是在变量中或引用中添加const 结果会改变。
变量添加const:
//变量添加const
int main()
{
const int a = 10;
int &b = a;
int &c = a;
}
报错如下:

原因是我们对a进行了能力扩展。b是a的别名,通过b可以修改a的值,但是a已经被限定为const 表示不可修改,再修改必定会引起冲突。
1.2.2 那如果我们非要这样使用怎么办?
-
可以使用强制转换。
int main() { const int a = 10; int &c = (int &)a; } -
可以通过const_cast<int *>进行转换。
int main() { const int a = 10; int &c = (int &)a; }
上述两种方式均可通过编译。
1.2.3 指针类型的引用
总体代码:
//int *p = &a为前提的四种情况
//int a = 10;
//int b = 200;
//int *p = &a;
//int *&p1 = p;
//int* const &p3 = p;
//const int* const &p4 = p;
#if 0
int main()
{
int a = 10;
int b = 200;
int *p = &a;
int *&p1 = p;
//const int* &p2 = p; //??????g++显示报错,VC成功 编译器造成的差异 c++的语法不依赖C++的标准文件,依赖于编译器所能完成的程度
//*p2 = 100; //error,因为p2解引用后的值被修饰为const,不可修改
//p2 = &b;
cout << "a = " << a << endl; //如果p2改变了指向,那么原先的p也要改变指向,因为p2是p的别名,它们两个指向同一个地址空间
cout << "b = " << b << endl;
//cout << "p2 = " << p2 << endl;
int* const &p3 = p; //指针本身不可修改,但是可以修改解引用后的值
*p3 = 100; //right
//p3 = &b; //error
cout << "*p3 = " << *p3 << " *p =" << *p << " a = "<< a << endl;
const int* const &p4 = p; //前一个const修饰指针解引用不可被修改,后一个const修饰真正本身不可修改
//*p4 = 100; //error
//p4 = &b; //error
return 0;
}
为了更清晰的观察,我们将代码拆成4个部分。
1.2.3.1 int *& p1 = p;
这个代码看上去有些难以理解,实际上是指针类型的引用。
int main()
{
int a = 10;
int b = 20;
int *p = &a; //p存放的是a的地址
int *s = p; //s也存放的是a的地址,如果p = &b,不会影响s,s依然存放a的地址
int *&p1 = p; //p1就是指针p的别名
return 0;
}
我们给指针p起一个别名,叫做rs。通过对rs的修改,p也会产生相应的变化。
理解了这个,就可以进一步加深难度,为引用添加不同的const修饰。
我们在指针p的前提上,引入了如下代码:
int *p = &a;
int *&p1 = p;
const int* &p2 = p;
int* const &p3 = p;
const int* const &p4 = p;
1.2.3.2 const int* &p2 = p;
int main()
{
int a = 10;
int b = 200;
int *p = &a;
const int *&p2 = p;
*p2 = 100; //error,因为p2解引用后被修改为const
p2 = &b; //right:没有规定p2本身。
cout << "a = " << a << endl;
cout << "*p2 = " << *p2 << endl;
cout << "b = " << b << endl;
return 0;
}
测试如下:
g++ 编译报错:

VC 编译通过:
原因:编译器造成的差异 c++的语法不依赖C++的标准文件,依赖于编译器所能完成的程度。
1.2.3.3 int* const &p3 = p;
int main()
{
int a = 10;
int b = 200;
int *p = &a;
int *const &p3 = p;
*p3 = 100; //right
//p3 = &b; //error
cout << "*p3 = " << p3 <<" *p = " << *p << " a = " << a << endl;
return 0;
}
p3作为p的别名,const修饰p3本身,p3也就不可修改,但是可以修改解引用后的值。
1.2.3.4 const int* const &p4 = p;
int main()
{
int a = 10;
int b = 200;
int *p = &a;
const int* const &p4 = p;
*p4 = 100; //error
p4 = &b; //error
cout << "*p4 = " << p4 << << " a = " << a << endl;
}
p4本身不可进行修改,也不可修改解引用后的值。
问题1:通过指针和引用修改a的值
*p += 100; //right
//const int *&p2 = p;
*p2 += 100; //error:const 修饰了指针p2(或者p)解引用后不可修改
*p3 += 100; //right:const 仅仅修饰了p3指向的地址
*p4 += 100; //error:指针指向的地址和解引用都不可修改
问题2:通过指针和引用修改指向的地址(程序分开)
p = &b; //right
p2 = &b; //right:const限定的是解引用后的值
p3 = &b; //error:const限定的是指针指向的地址
p4 = &b; //error:指针的两个属性都被限制
问题3:通过p可以修改自身以及p3解引用后的值
int b = 200;
p = &b; //此处连同p3一起修改
int* const &p3 = p;
cout <<"问题3:" <<endl;
cout << "p = " << *p << endl;
cout << " p3 = " << *p3 << endl;
//原始值:
//p = 200 p3 = 200;
*p = 1; //可以修改*p与*p3的值
cout << "p = " << *p << endl;
cout << "p3 = " << *p3 << endl;
//修改后:
//p = 1, p3 = 1
因为const限定问题,导致p3不能修改指向指针指向的地址,但是可以修改指针解引用后的值。p3和p可以看作一个指针,当一个的解引用改变,另一个也发生相应的改变。
1.2.3.5 特殊情况 int *&const p5 = p;
这个与 int *const &p3 = p;看似相似,实则大为不同。
int main()
{
int a = 10;
int b = 20;
int *p = &a;
int *&const p1 = p; //修饰引用符号是一个常性,符号本身是一个常性,因此,此处的const无任何意义
p = &b;
}
1.2.4 深入指针类型的引用
当指针p加上不同的const 限定时,会发生什么情况?
1.2.4.1 const int *p = &a;
//const int *p = &a;带来的四种情况
int main()
{
int a = 10;
int b = 20;
const int *p = &a;
//int* &p1 = p; //error:语义和编译都不可通过,能力扩展
const int* &p2 = p; //right
//int* const &p3 = p; //error:
//int* & const p3
const int* const &p3 = p; //right
system("pause");
return 0;
}
1.2.4.2 int *const s = &a;
int main()
{
int a = 10;
int b = 20;
int *const p = &a;
int *&p1 = p; //error:可通过p1的指向修改p
const int *&p2 = p; //error:通过p2可以修改p的指向
int *const &p3 = p; //right
const int * const &p4 = p; //right
system("pause");
return 0;
}
1.2.5 引用的本质
到目前为止,我们对引用有了一个比较清晰的了解。下面我们从代码层面和编译层面来探索引用的本质。
1.2.5.1 代码层面分析
有如下代码:
void fun(int &a)
{
int *p = &a;
a = 100;
*p = 200;
}
int main()
{
int x = 10;
int &y = x;
fun(x);
fun(y);
return 0;
}
上下代码等价
void fun(int *const a)
{
//if(a == null) return;
int *p = a; //int *p = *&a;
//此处无报错原因:p保存的是指针a指向的地址,p自身的改变并不会影响到a的改变
*a = 100;
*p = 200;
}
int &y = x 被编译器翻译为int *const y = &x。这个const修饰的是指针本身。所以指针y不能指向x之外的地址,这也就说明了引用必须初始化的问题。
如果说引用不需要初始化,在编译之后被翻译为int *const y;y不能做出任何指向,显然引用就没有了意义。
1.2.5.2 汇编层面分析
指针和引用相同。
VS2019下:
int main()
{
int a = 10;
int &b = a;
int *p = &a;
*p = 200;
//eax,dword ptr [p]
//dword ptr[eax],0C8h
b = 100;
//eax,dword ptr [b]
//dword ptr[eax],64h
return 0;
}
1.2.5.3 引用本质总结
- 从语法层面上看,引用就是一个变量的别名,相当于一个实体的两个名字。从汇编层面上看,引用相当于一个常性的指针。
- 形参是引用的时候,我们需要使用实参进行初始化。
- 如果是形参是引用,我们不需要进行对引用为空的判断,如果是指针,需要进行对指针是否为空的判断。从这个角度看来引用比指针更加安全。
1.2.6 返回值为引用
int fun()
{
int a = 10;
return a;
}
int &funref()
{
int a = 20;
return a;
}
int main()
{
int x = fun();
int y = funref();
int &z = funref();
cout << x << " " << y <<" "<< z << endl;
return 0;
}
funref函数的类型是int &,更据1.2.5的结论,函数int &funref()可以相当于 int *const funref()。返回的是值的地址。
int *const funref()
{
int a = 20;
return &a;
}
int y = *funref();
编译:
对返回的局部变量’a’的引用,返回局部变量或者临时变量地址:a

g++运行失败闪退:

VS2019运行:

为什么呢?
首先我们引入一个概念,地址扰动 和 失效指针。
1.2.6.1 失效指针和地址扰动
int *fun()
{
int arr[10] = {14,5,6,77,64,7,45,89,23,53};
return arr;
}
int main()
{
int *p = fun();
for(int i = 0; i < 10; i++)
{
printf("%p => %d\n",p,*p);
p += 1;
}
system("pause");
return 0;
}
函数运行流程如下:

- 首先从主函数运行,为主函数分配栈帧。
- 调用fun,为fun分配栈帧,将数组入栈。由于是局部的数组,数组的首地址放在一个临时量里,函数结束会被销毁。
- 当函数调用结束后,会将arr的地址返回给指针p。此时fun的函数栈帧已经被销毁,但p仍然指向销毁前arr的地址。p被称作为失效指针。
运行结果:

问题:为什么会出现随机值呢?
prinft也是函数,当调用printf的时候,占据main后的栈帧,会对原有的空间进行骚扰,也就是会覆盖之前已经销毁的fun函数的栈帧。接着把原先存储arr内容的地址进行修改。所以打印的时候,会出现随机值。
现在我们进行一些小修改:将数组大小修改为1000
int *fun()
{
int arr[1000] = {14,5,6,77,64,7,45,89,23,53};
return arr;
}
int main()
{
int *p = fun();
for(int i = 0; i < 10; i++)
{
printf("%p => %d\n",p,*p);
p += 1;
}
system("pause");
return 0;
}
运行结果如下:

这时就不会出现随机值了。
问题:为什么增加了数组大小又没有随机值了?
由于数组的长度比较大,分配的空间也比较多。没有进行初始化的空间会默认为0。当fun函数调用结束后,栈帧会被销毁。原先的地址会交给printf函数来使用,printf使用栈帧的空间是数组初始化从后往前的。并不会影响到开头的10个空间。所以它们没有随机值。
这里的描述非常简洁也不严谨。如要深究可以看今后的博文《函数的调用过程分析》。会添加链接
1.2.6.2 深入地址扰动
我们回过头来看刚开始的代码
int fun()
{
int a = 10;
return a; //将亡值
}
int &funref()
{
int a = 20;
return a;
}
//int *const funref()
//{
// int a = 20;
// return &a;
//}
int main()
{
int x = fun();
int y = funref();
//int y = *funref();
int &z = funref(); //看这个
//int* const z = funref(); //图片3
//fun(); //添加的函数
cout << x << " " << y << " " << z <<endl;
//输出结果:10 20 20
//为什么没有地址扰动添加 523行的fun()函数
//添加后:输出结果:10 20 -858993460
return 0;
}
 这里看似没有发生地址扰动,原因是没有人工干预。我们将27行的注释添加上。
这里看似没有发生地址扰动,原因是没有人工干预。我们将27行的注释添加上。
int fun()
{
int a = 10;
return a; //将亡值
}
int &funref()
{
int a = 20;
return a;
}
//上面的代码相当于:
//int *const funref()
//{
// int a = 20;
// return &a; //返回a的地址,由于调用结束后销毁栈,可能会被地址扰动
//}
int main()
{
int x = fun();
int y = funref();
//相当于:int y = *funref();
int &z = funref(); //看这个
//相当于:int* const z = funref(); //图片3
fun(); //添加的函数
cout << x << " " << y << " " << z <<endl;
//为什么没有地址扰动添加 523行的fun()函数
//添加后:输出结果:10 20 -858993460
return 0;
}
运行结果如下:

这里我们看到z的值变为了随机数。25行调用funref函数创建了栈帧,当调用结束后栈被自动销毁,但是原先的地方还存储这funref函数的返回值。当调用fun函数,开辟的栈帧会占用原先funref的栈帧,会覆盖funref的返回值。原先的地址会被覆盖,成为随机值。
问题:那我们就想保存这个函数值,最好是以指针为参数传递给这个值吗?
void fun(int *p)
{
int a = 10;
p = &a;
}
void fun2()
{
int arr[1000] = {193,41,44,4,3,4,3}; //空间扰动
}
int main()
{
int *s = NULL;
fun(s);
fun2();
cout << *s << endl;
system("pause");
return 0;
}
程序崩溃,返回值异常:
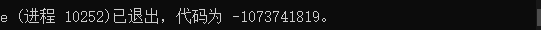
传递指针参数失败方式。
问题:如何通过传递参数来修改指针解引用后的值?
回答:将函数的形参改为 引用类型的指针。
void fun(int* &p)
{
int a = 10;
p = &a;
}
int main()
{
int* s = NULL;
fun(s);
cout << *s << endl;
cout << *s << endl; //通过多个cout来扰动空间
cout << *s << endl;
cout << *s << endl;
return 0;
}
结果:

可以看出,调用fun函数后,* s的值变为10。但是后面的*s的值变为随机数。还是因为空间扰动问题:fun函数运行完毕销毁栈,但是实际并不是直接销毁,而是将之前的区域变为可覆盖的。当我们第一次输出 *s,原先的值没有被改变,是10。但是后面多次的时候会将原来的地方覆盖,从而找不到s的地址,产生随机值。
引用也不一定可以完全正确的返回参数。
问题:函数能把什么样的数据以引用的方式返回?
回答:此变量的生存区不被函数的生存区影响。
例子:
int &fun1()
{
//1、静态局部变量
static int a = 10; //.data
return a;
}
//2、全局变量
int Max = 100; //.data
int &fun2()
{
return Max;
}
int &fun3(int &x) //3、引用进入的变量,函数死亡,引用变量不会消失
//引用进,可以引用出
{
return x;
}















 241
241











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









