









目的:模拟数据不断写入,同时不断处理
01.启动相关的服务
Hdfs文件系统
Zookeeper服务
Kafka(主题,生产,消费)
Hive数仓(元数据库mysql)
Spark能够直接sql操作Hive,不然使用jdbc方式
(base) [root@192 ~]# jps
3200 SecondaryNameNode
2835 NameNode
5011 ConsoleProducer
85045 Jps
2998 DataNode
4390 QuorumPeerMain
4535 Kafka
4057 RunJar
5465 ConsoleConsumer
(base) [root@192 ~]# jps -l
3200 org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode
2835 org.apache.hadoop.hdfs.server.namenode.NameNode
5011 kafka.tools.ConsoleProducer
2998 org.apache.hadoop.hdfs.server.datanode.DataNode
4390 org.apache.zookeeper.server.quorum.QuorumPeerMain
85063 sun.tools.jps.Jps
4535 kafka.Kafka
4057 org.apache.hadoop.util.RunJar
5465 kafka.tools.ConsoleConsumer
(base) [root@192 ~]#
02.模拟Kafka生产
思路:
step1:读取一个hdfs文件系统上的csv文件为RDD
step2:将RDD转换为一个列表,使用切片去除表头信息
step3:将该列表的数据不断作为Kafka的生产数据,使用time.sleep(1),控制每1秒生产一条数据
代码如下:
from pyspark.sql import SparkSession
from pyspark.streaming import StreamingContext
from kafka import KafkaProducer
from kafka.errors import KafkaError
import time
sc = SparkSession.builder.config("spark.driver.host","192.168.1.10")\
.config("spark.ui.showConsoleProgress","false").appName("HdfsKafka")\
.master("local[*]").getOrCreate().sparkContext
ssc = StreamingContext(sc,10)
producer = KafkaProducer(bootstrap_servers = "192.168.1.10:9092")
rdd = sc.textFile("hdfs://192.168.1.10:9000//HadoopFileS/DataSet/MLdataset/seeds_dataset.csv")
# rdd.foreach(print) 用于查看hdfs数据
print("---------------开始用hdfs数据模拟kafka生产----------------------")
lst = rdd.collect()[1:] #去除第一行的字段数据
for i in lst:
future = producer.send(topic="sparkapp",value=i.encode())
print("已生产数据:%s"%(i))
time.sleep(1)
try:
record = future.get(timeout=10)
except KafkaError as e:
print(e)
ssc.start()
ssc.awaitTermination()
property = property()
03.模拟Kafka消费
思路:
step1:使用spark操作hive创建一个表
step2:将stream中的数据不断插入到hive数据库中的表中,设置为每5秒处理一次
step3:对该表进行简单的汇总(可以看到数据的行数,方差,均值等信息的不断变化)
代码:
from pyspark.sql import SparkSession
from pyspark.streaming import StreamingContext
from pyspark.streaming.kafka import KafkaUtils
spark = SparkSession.builder.config("spark.driver.host","192.168.1.10")\
.config("spark.ui.showConsoleProgress","false").appName("KafkaFromHdfs")\
.master("local[*]").enableHiveSupport().getOrCreate()
sc = spark.sparkContext
sc.setLogLevel("ERROR")
ssc = StreamingContext(sc,5)
# 使用hive数据库
spark.sql("use hive_test_one")
spark.sql("""
create table if not exists kafkaTest(
`ID` int,
`area` double,
`perimeter` double,
`compactness` double,
`lengthOfKernel` double,
`widthOfKernel` double,
`asymmetryCoefficient` double,
`lengthOfKernelGroove` double,
`seedType` int
)
row format delimited fields terminated by ','
""")
def func(x):
for i in x:
str = "insert into kafkaTest values(%s)"%(i)
# print(str) 查看sql语句内容
spark.sql(str)
spark.sql("select * from kafkaTest").summary().show()
stream_rdd = KafkaUtils.createDirectStream(ssc,["sparkapp"],{"metadata.broker.list": "192.168.1.10:9092"})\
.map(lambda x:x[1])
stream_rdd.foreachRDD(lambda x: func(x.collect()))
ssc.start()
ssc.awaitTermination()
property = property()
04.结果展示
HdfsToKafka_producer.py写入数据到Kafka情况
这边是每1秒写入一条数据到kafka
HdfsFromKafka_consumer.py消费数据到hive并查看实时汇总情况
这边是每5秒处理一次数据入库到hive中,由于之前是一秒产生一条,所以从count中不难看出间隔是5

05.其他问题
从hdfs生产数据中不难看出我们的第一列数据是从1开始往下的,但是从汇总这边可以看到ID列的最大值max却总是比count数大一个。说明有个数据我们并没有消费到,将输出信息滑动到最上边查看一下,如图:
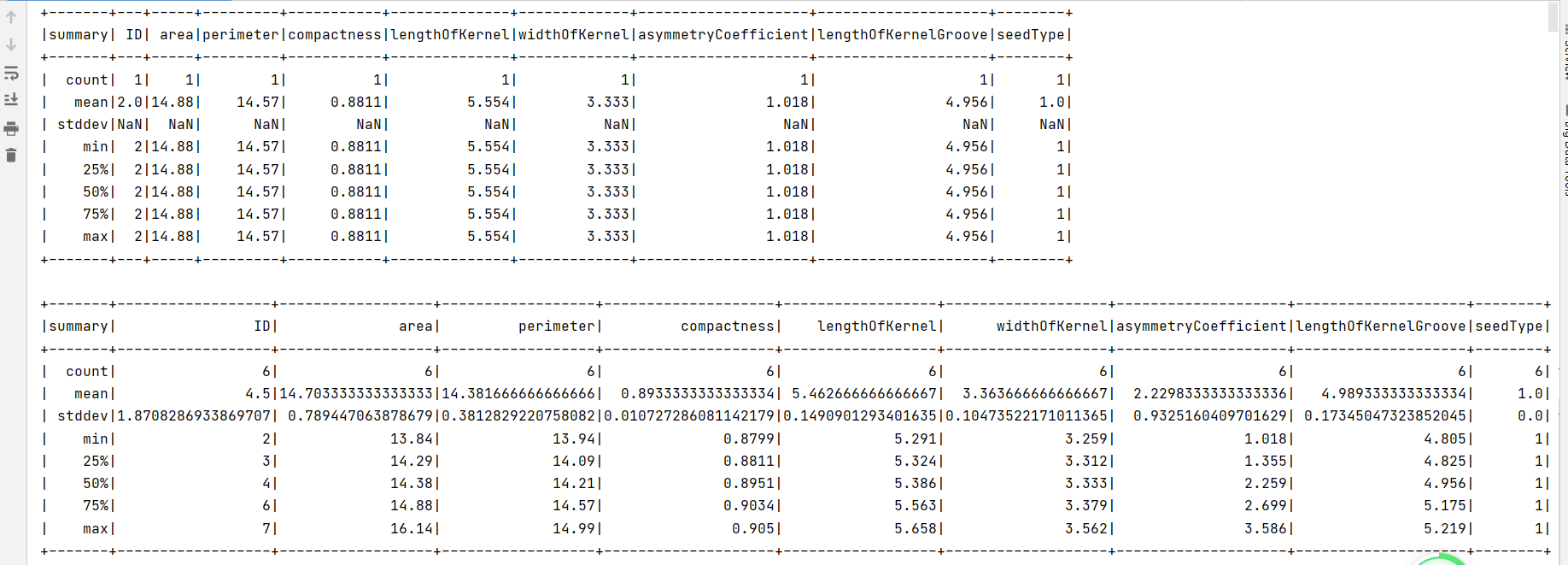
说明我们第一条数据并没有进行消费,可能是sparkstreaming后启动消费,导致之前生产的数据未能及时入库到hive,汇总的数据缺失前面的一部分,这应该怎么解决呢?之后有机会再记录吧。















 932
932











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









