






1、http协议 是什么?
超文本传输协议(Hyper Text Transfer Protocol,HTTP)是一个简单的请求-响应协议,它通常运行在TCP之上。它指定了客户端可能发送给服务器什么样的消息以及得到什么样的响应。请求和响应消息的头以ASCII形式给出;而 [9] 消息内容则具有一个类似MIME的格式。这个简单模型是早期Web成功的有功之臣,因为它使开发和部署非常地直截了当。
HTTP状态码大致分为5类:
1xx : 消息,这一类型的状态码,代表请求已被接受,需要继续处理。但是一般服务器禁止向客户端发送此类状态码;
2xx : 成功,这一类型的状态码,代表请求已成功被服务器接收、理解、并接受;
3xx : 重定向,这类状态码代表需要客户端采取进一步的操作才能完成请求;
4xx : 请求错误,这类的状态码代表了客户端看起来可能发生了错误,妨碍了服务器的处理;
5xx : 服务器错误,这类状态码代表了服务器在处理请求的过程中有错误或者异常状态发生,也有可能是服务器意识到以当前的软硬件资源无法完成对请求的处理。
常用状态码
200 : 成功,表示访问成功,正常状态。
301 : 永久移动,表示本网页已经永久性的移动到一个新的地址,在客户端自动将请求地址改为服务器返回的新地址。
302 : 临时重定向,表示网页暂时性的转移到一的新的地址,客户端在以后可以继续向本地址发起请求。
303 : 表示必须临时重定向,并且必须使用GET方式请求。
304 : 重定向至浏览器本身,当浏览器多次发起同一请求,且内容未更改时,使用浏览器缓存,这样可以减少网络开销。
401 : 表示协议格式出错,可能是此IP地址被禁止访问该资源,与403类似。
403 : 表示没有权限,服务器拒绝访问请求。
404 : 这是最常见的错误,表示找不到系统资源,但是只是暂时性地。
500 : 表示服务器程序错误,一个通用的错误信息。
503 : 表示服务器繁忙,或者服务器负载,通常这只是一个临时状态。
2、lamp架构运行的原理
LAMP的工作原理
LAMP其实是指Linux+Apache+Mysql+PHP的结构体系。其工作原理如下:
浏览器向服务器发送http请求,服务器 (Apache) 接受请求,由于php作为Apache的组件模块也会一起启动,它们具有相同的生命周期。Apache会将一些静态资源保存,然后去调用php处理模块进行php脚本的处理。脚本处理完后,Apache将处理完的信息通过http response的方式发送给浏览器,浏览器解析,渲染等一系列操作后呈现整个网页。
两者的区别
在LNMP中,Nginx本身对脚本不做任何的处理,而是去调用一个PHP-FPM的进程,二者是相互独立的。
在LAMP中,PHP是Apache的一个模块,具有相同的生命周期。
3、GTID主从
3.1 GTID概念介绍
GTID即全局事务ID (global transaction identifier), 其保证为每一个在主上提交的事务在复制集群中可以生成一个唯一的ID。GTID最初由google实现,官方MySQL在5.6才加入该功能。mysql主从结构在一主一从情况下对于GTID来说就没有优势了,而对于2台主以上的结构优势异常明显,可以在数据不丢失的情况下切换新主。使用GTID需要注意: 在构建主从复制之前,在一台将成为主的实例上进行一些操作(如数据清理等),通过GTID复制,这些在主从成立之前的操作也会被复制到从服务器上,引起复制失败。也就是说通过GTID复制都是从最先开始的事务日志开始,即使这些操作在复制之前执行。比如在server1上执行一些drop、delete的清理操作,接着在server2上执行change的操作,会使得server2也进行server1的清理操作。
GTID实际上是由UUID+TID (即transactionId)组成的。其中UUID(即server_uuid) 产生于auto.conf文件(cat /data/mysql/data/auto.cnf),是一个MySQL实例的唯一标识。TID代表了该实例上已经提交的事务数量,并且随着事务提交单调递增,所以GTID能够保证每个MySQL实例事务的执行(不会重复执行同一个事务,并且会补全没有执行的事务)。GTID在一组复制中,全局唯一。 下面是一个GTID的具体形式 :
mysql> show master status;
+-----------+----------+--------------+------------------+-------------------------------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+-----------+----------+--------------+------------------+-------------------------------------------+
| on.000003 | 187 | | | 7286f791-125d-11e9-9a9c-0050568843f8:1-362|
+-----------+----------+--------------+------------------+-------------------------------------------+
1 row in set (0.00 sec)
GTID:7286f791-125d-11e9-9a9c-0050568843f8:1-362
UUID:7286f791-125d-11e9-9a9c-0050568843f8
transactionId:1-362
在整个复制架构中GTID 是不变化的,即使在多个连环主从中也不会变。
例如:ServerA --->ServerB ---->ServerC
GTID从在ServerA ,ServerB,ServerC 中都是一样的。
了解了GTID的格式,通过UUID可以知道这个事务在哪个实例上提交的。通过GTID可以极方便的进行复制结构上的故障转移,新主设置,这就很好地解决了下面这个图所展现出来的问题。

如图, Server1(Master)崩溃,根据从上show slave status获得Master_log_File/Read_Master_Log_Pos的值,Server2(Slave)已经跟上了主,Server3(Slave)没有跟上主。这时要是把Server2提升为主,Server3变成Server2的从。这时在Server3上执行change的时候需要做一些计算。
这个问题在5.6的GTID出现后,就显得非常的简单。由于同一事务的GTID在所有节点上的值一致,那么根据Server3当前停止点的GTID就能定位到Server2上的GTID。甚至由于MASTER_AUTO_POSITION功能的出现,我们都不需要知道GTID的具体值,直接使用CHANGE MASTER TO MASTER_HOST=‘xxx’, MASTER_AUTO_POSITION命令就可以直接完成failover的工作。
====== GTID和Binlog的关系 ======
- GTID在binlog中的结构

- GTID event 结构

- Previous_gtid_log_event
Previous_gtid_log_event 在每个binlog 头部都会有每次binlog rotate的时候存储在binlog头部Previous-GTIDs在binlog中只会存储在这台机器上执行过的所有binlog,不包括手动设置gtid_purged值。换句话说,如果你手动set global gtid_purged=xx; 那么xx是不会记录在Previous_gtid_log_event中的。 - GTID和Binlog之间的关系是怎么对应的呢? 如何才能找到GTID=? 对应的binlog文件呢?
假设有4个binlog: bin.001,bin.002,bin.003,bin.004
bin.001 : Previous-GTIDs=empty; binlog_event有: 1-40
bin.002 : Previous-GTIDs=1-40; binlog_event有: 41-80
bin.003 : Previous-GTIDs=1-80; binlog_event有: 81-120
bin.004 : Previous-GTIDs=1-120; binlog_event有: 121-160
假设现在我们要找GTID=$A,那么MySQL的扫描顺序为: - 从最后一个binlog开始扫描(即: bin.004)
- bin.004的Previous-GTIDs=1-120,如果$A=140 > Previous-GTIDs,那么肯定在bin.004中
- bin.004的Previous-GTIDs=1-120,如果$A=88 包含在Previous-GTIDs中,那么继续对比上一个binlog文件 bin.003,然后再循环前面2个步骤,直到找到为止.
====== GTID 重要参数的持久化 =======
- GTID相关参数
| 参数 | comment |
|---|---|
| gtid_executed | 执行过的所有GTID |
| gtid_purged | 丢弃掉的GTID |
| gtid_mode | GTID模式 |
| gtid_next | session级别的变量,下一个gtid |
| gtid_owned | 正在运行的GTID |
| enforce_gtid_consistency | 保证GTID安全的参数 |
====== 开启GTID的必备条件 ======
gtid_mode=on (必选)
enforce-gtid-consistency=1 (必选)
log_bin=mysql-bin (可选) #高可用切换,最好开启该功能
log-slave-updates=1 (可选) #高可用切换,最好打开该功能
3.2 GTID工作原理
从服务器连接到主服务器之后,把自己执行过的GTID (Executed_Gtid_Set: 即已经执行的事务编码) 、获取到的GTID (Retrieved_Gtid_Set: 即从库已经接收到主库的事务编号) 发给主服务器,主服务器把从服务器缺少的GTID及对应的transactions发过去补全即可。当主服务器挂掉的时候,找出同步最成功的那台从服务器,直接把它提升为主即可。如果硬要指定某一台不是最新的从服务器提升为主, 先change到同步最成功的那台从服务器, 等把GTID全部补全了,就可以把它提升为主了。
GTID是MySQL 5.6的新特性,可简化MySQL的主从切换以及Failover。GTID用于在binlog中唯一标识一个事务。当事务提交时,MySQL Server在写binlog的时候,会先写一个特殊的Binlog Event,类型为GTID_Event,指定下一个事务的GTID,然后再写事务的Binlog。主从同步时GTID_Event和事务的Binlog都会传递到从库,从库在执行的时候也是用同样的GTID写binlog,这样主从同步以后,就可通过GTID确定从库同步到的位置了。也就是说,无论是级联情况,还是一主多从情况,都可以通过GTID自动找点儿,而无需像之前那样通过File_name和File_position找点儿了。
简而言之,GTID的工作流程为:
- master更新数据时,会在事务前产生GTID,一同记录到binlog日志中。
- slave端的i/o 线程将变更的binlog,写入到本地的relay log中。
- sql线程从relay log中获取GTID,然后对比slave端的binlog是否有记录。
- 如果有记录,说明该GTID的事务已经执行,slave会忽略。
- 如果没有记录,slave就会从relay log中执行该GTID的事务,并记录到binlog。
- 在解析过程中会判断是否有主键,如果没有就用二级索引,如果没有就用全部扫描。
3.3 GTID主从配置
环境说明:
| 数据库角色 | IP | 应用与系统版本 |
|---|---|---|
| 主数据库 | 172.16.12.128 | centos8/redhat8 mysql-5.7 |
| 从数据库 | 172.16.12.129 | centos8/redhat8 mysql-5.7 |
主库配置。vi /etc/my.cnf,添加以下配置,重启mysql
[root@localhost ~]# vim /etc/my.cnf
server-id=44
gtid_mode=on
enforce-gtid-consistency=true
log-slave-updates=on
[root@localhost ~]# service mysqld restart
Shutting down MySQL.. SUCCESS!
Starting MySQL. SUCCESS!
从库配置。vi /etc/my.cnf, 添加以下配置,重启mysql。
[root@localhost ~]# vim /etc/my.cnf
server-id=66
relay-log=myrelay
gtid_mode=on
enforce-gtid-consistency=true
log-slave-updates=on
read_only=on
master-info-repository=TABLE
relay-log-info-repository=TABLE
[root@localhost ~]# service mysqld restart
Shutting down MySQL.. SUCCESS!
Starting MySQL. SUCCESS!
主库授权复制用户。
root@localhost ~]# mysql
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 2
Server version: 5.7.37 MySQL Community Server (GPL)
Copyright (c) 2000, 2022, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql>
mysql> grant replication slave on *.* to 'haha'@'%' identified by 'haha123';
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)
mysql>
从库设置要同步的主库信息,并开启同步。
mysql> change master to master_host='192.168.40.99',master_user='haha',master_password='haha123',master_port=3306,master_auto_position=1;
mysql> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.40.99
Master_User: haha
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql_bin.000001
Read_Master_Log_Pos: 154
Relay_Log_File: myrelay.000002
Relay_Log_Pos: 367
Relay_Master_Log_File: mysql_bin.000001
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
配置完之后,通过查看slave的状态,可以看是否配置成功。同时可以在主库进行一些操作,提交一些事务(insert,update),之后数据就会自动同步到从
4、lamp简介
有了前面学习的知识的铺垫,今天可以来学习下第一个常用的web架构了。
所谓lamp,其实就是由Linux+Apache+Mysql/MariaDB+Php/Perl/Python的一组动态网站或者服务器的开源软件,除Linux外其它各部件本身都是各自独立的程序,但是因为经常被放在一起使用,拥有了越来越高的兼容度,共同组成了一个强大的Web应用程序平台。
LAMP指的是Linux(操作系统)、Apache(HTTP服务器)、MySQL(也指MariaDB,数据库软件)和PHP(有时也是指Perl或Python)的第一个字母,一般用来建立web应用平台。
5.、web服务器工作流程
在说lamp架构平台的搭建前,我们先来了解下什么是CGI,什么是FastCGI,什么是…
web服务器的资源分为两种,静态资源和动态资源
- 静态资源就是指静态内容,客户端从服务器获得的资源的表现形式与原文件相同。可以简单的理解为就是直接存储于文件系统中的资源
- 动态资源则通常是程序文件,需要在服务器执行之后,将执行的结果返回给客户端
那么web服务器如何执行程序并将结果返回给客户端呢?下面通过一张图来说明一下web服务器如何处理客户端的请求
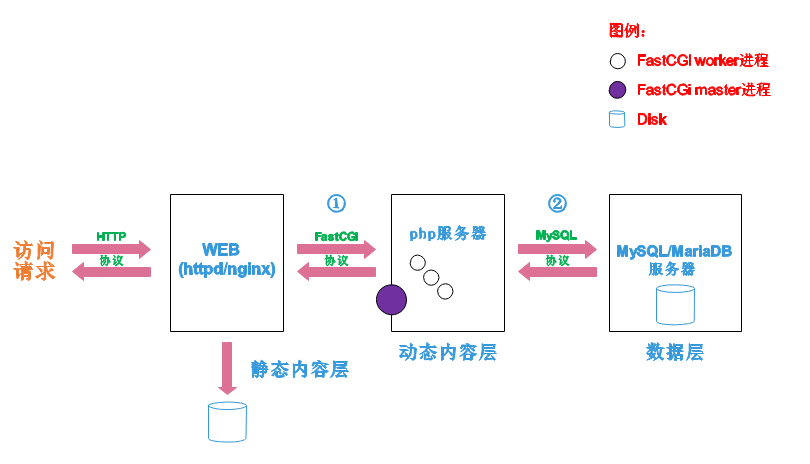
如上图所示
阶段①显示的是httpd服务器(即apache)和php服务器通过FastCGI协议进行通信,且php作为独立的服务进程运行
阶段②显示的是php程序和mysql数据库间通过mysql协议进行通信。php与mysql本没有什么联系,但是由Php语言写成的程序可以与mysql进行数据交互。同理perl和python写的程序也可以与mysql数据库进行交互
5.1 cgi与fastcgi
上图阶段①中提到了FastCGI,下面我们来了解下CGI与FastCGI。
CGI(Common Gateway Interface,通用网关接口),CGI是外部应用程序(CGI程序)与WEB服务器之间的接口标准,是在CGI程序和Web服务器之间传递信息的过程。CGI规范允许Web服务器执行外部程序,并将它们的输出发送给Web浏览器,CGI将web的一组简单的静态超媒体文档变成一个完整的新的交互式媒体。
FastCGI(Fast Common Gateway Interface)是CGI的改良版,CGI是通过启用一个解释器进程来处理每个请求,耗时且耗资源,而FastCGI则是通过master-worker形式来处理每个请求,即启动一个master主进程,然后根据配置启动几个worker进程,当请求进来时,master会从worker进程中选择一个去处理请求,这样就避免了重复的生成和杀死进程带来的频繁cpu上下文切换而导致耗时
5.2 httpd与php结合的方式
httpd与php结合的方式有以下三种:
- modules:php将以httpd的扩展模块形式存在,需要加载动态资源时,httpd可以直接通过php模块来加工资源并返回给客户端
- httpd prefork:libphp5.so(多进程模型的php)
- httpd event or worker:libphp5-zts.so(线程模型的php)
- CGI:httpd需要加载动态资源时,通过CGI与php解释器联系,获得php执行的结果,此时httpd负责与php连接的建立和断开等
- FastCGI:利用php-fpm机制,启动为服务进程,php自行运行为一个服务,https通过socket与php通信
较于CGI方式,FastCGI更为常用,很少有人使用CGI方式来加载动态资源
5.3 web工作流程
通过上面的图说明一下web的工作流程:
- 客户端通过http协议请求web服务器资源
- web服务器收到请求后判断客户端请求的资源是静态资源或是动态资源
- 若是静态资源则直接从本地文件系统取之返回给客户端。
hp解释器联系,获得php执行的结果,此时httpd负责与php连接的建立和断开等
- 若是静态资源则直接从本地文件系统取之返回给客户端。
- FastCGI:利用php-fpm机制,启动为服务进程,php自行运行为一个服务,https通过socket与php通信
较于CGI方式,FastCGI更为常用,很少有人使用CGI方式来加载动态资源
5.3 web工作流程
通过上面的图说明一下web的工作流程:
- 客户端通过http协议请求web服务器资源
- web服务器收到请求后判断客户端请求的资源是静态资源或是动态资源
- 若是静态资源则直接从本地文件系统取之返回给客户端。
- 否则若为动态资源则通过FastCGI协议与php服务器联系,通过CGI程序的master进程调度worker进程来执行程序以获得客户端请求的动态资源,并将执行的结果通过FastCGI协议返回给httpd服务器,httpd服务器收到php的执行结果后将其封装为http响应报文响应给客户端。在执行程序获取动态资源时若需要获得数据库中的资源时,由Php服务器通过mysql协议与MySQL/MariaDB服务器交互,取之而后返回给httpd,httpd将从php服务器收到的执行结果封装成http响应报文响应给客户端。















 4537
4537











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









