






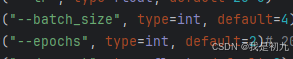
上图为代码中的部分,起初以为是batch_size的问题,于是默认值往小了改。
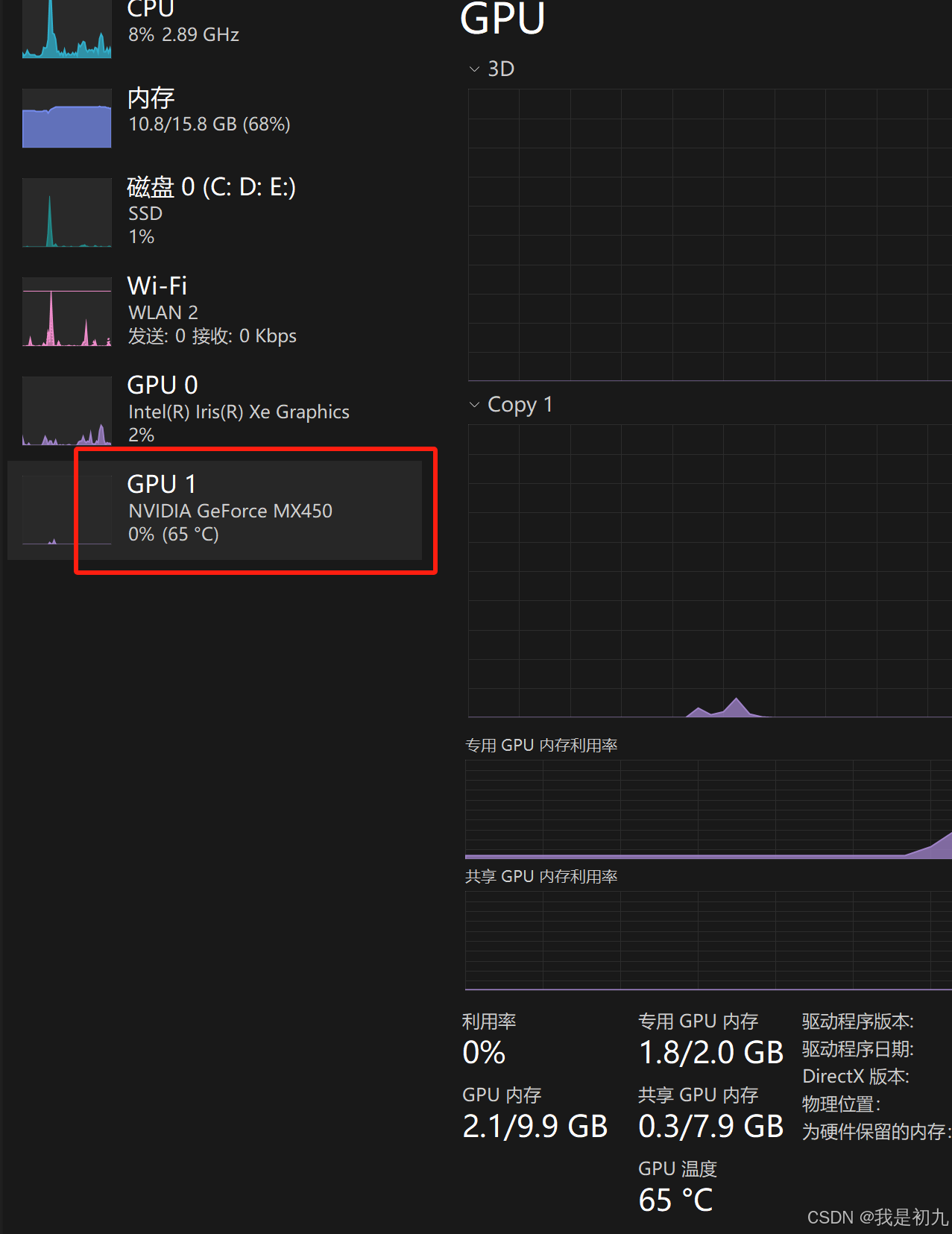
结果GPU1 的利用率仍为0%...没有用啊。
询问了LLMs给了如下回答。
import torch
# 检查CUDA是否可用
if torch.cuda.is_available():
# 设置默认的CUDA设备
torch.cuda.set_device(1) # 设置为使用GPU 1
device = torch.device("cuda:1")
# 将模型和数据移动到GPU 1
model.to(device)
inputs, labels = inputs.to(device), labels.to(device)于是乎,修改代码。继续运行,GPU利用率仍为0。
怎样让电脑使用独立显卡?参考这篇文章,有了思路。
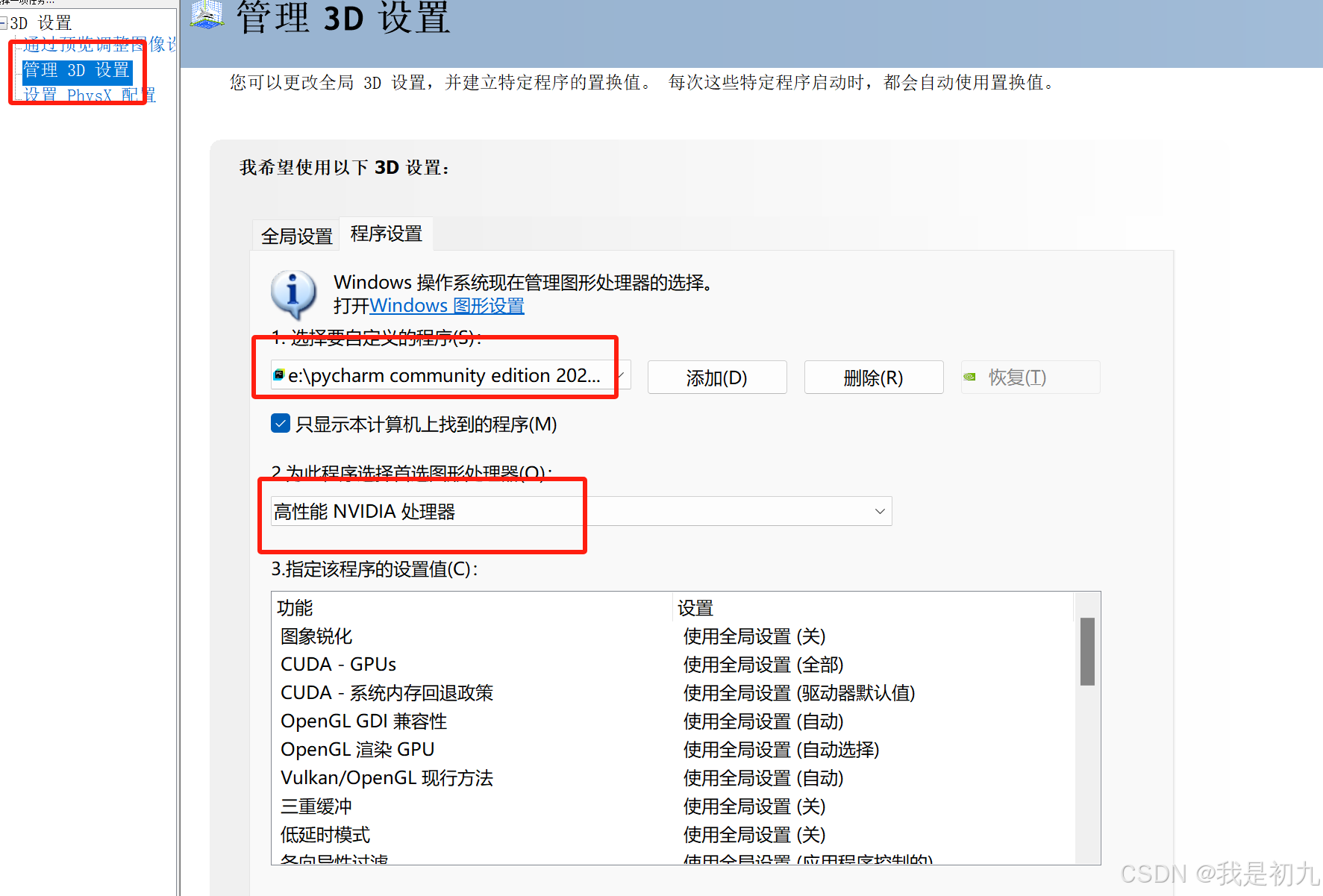
1.选择让Pycharm使用NVIDIA处理器
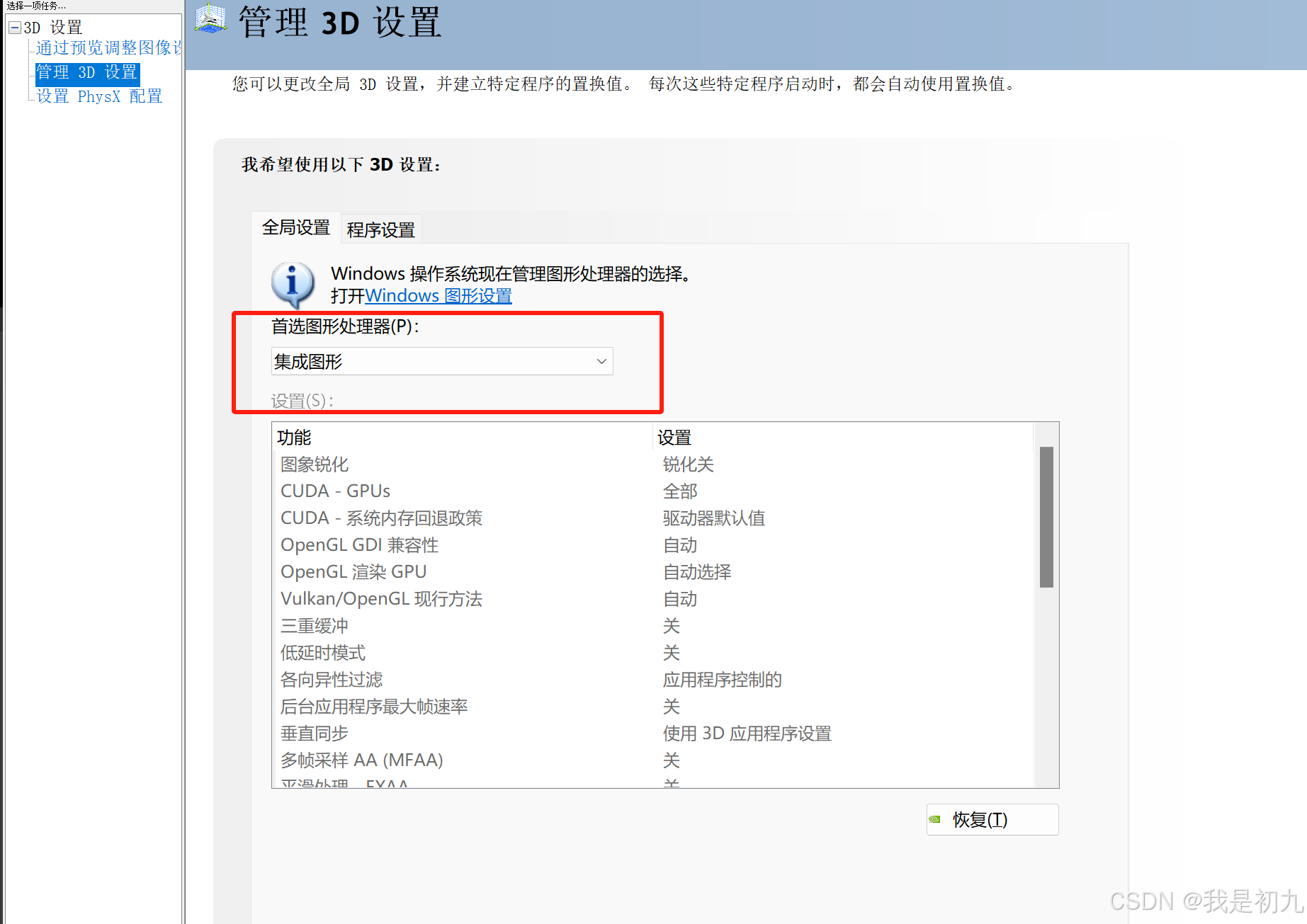
2.全局-集成图形
3.运行代码,监测性能。
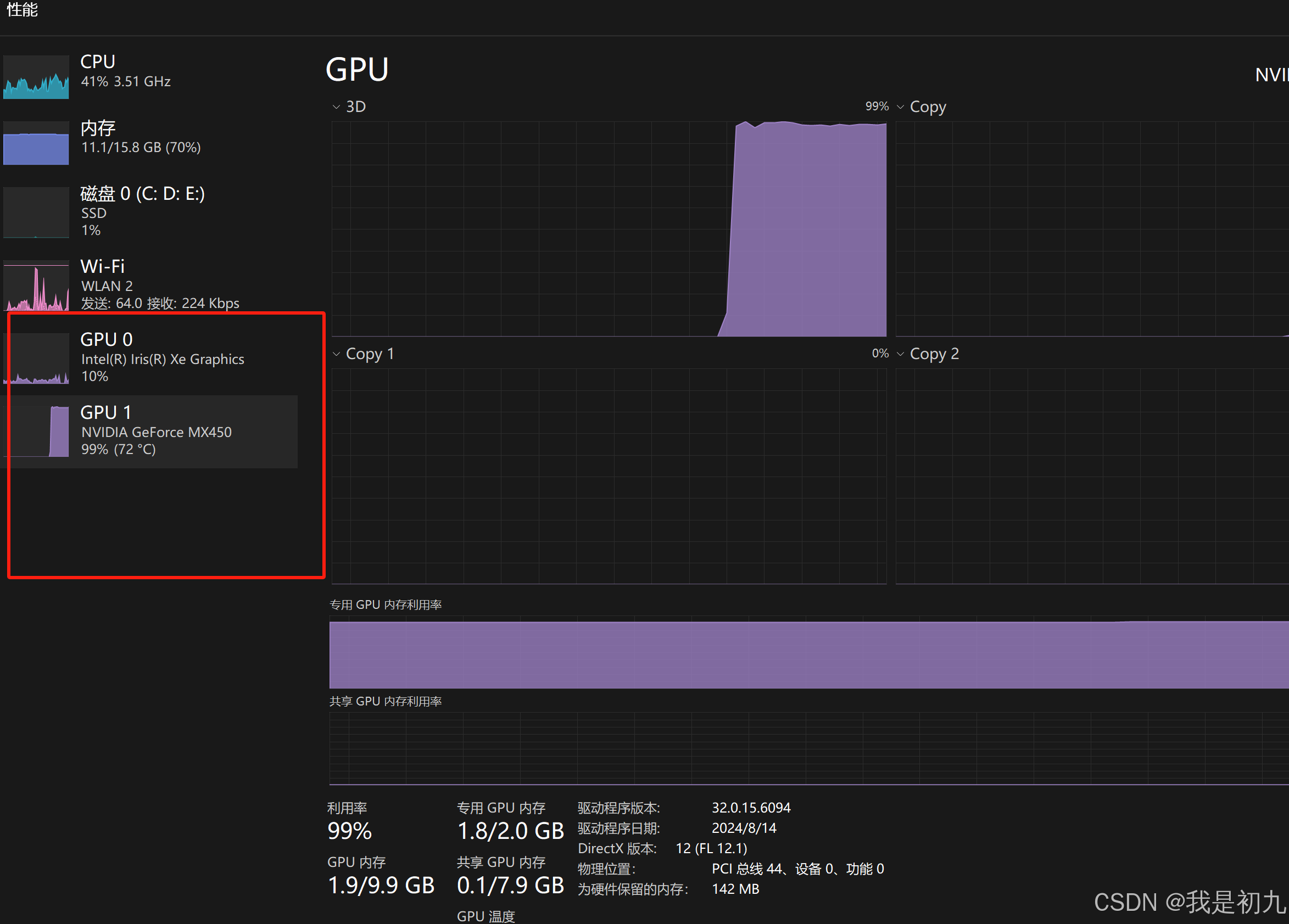
可以看到,此时的GPU1已经利用起来了,且利用率惊人,达到了99%。(自己的显卡性能不太行,跑这种深度学习模型还是太勉强了)
以上,仅为此次问题的个人解法,仅供参考。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











