






文章动机
在多个数据源存在的情况下,使用第三方云设备去训练神经网络是一种非常好的方案。但是数据中的隐私信息和法律法规对隐私保护限制了这些隐私数据的使用。相比起传统的机器学习训练过程,在加密数据上训练深度神经网络(DNN)十分具有挑战性。原因如下:
- 这种情况需要在巨大的数据集上进行大规模的计算;
- 现有的在加密数据上计算的方法,如同态加密,效率不高。
另外,现有的隐私保护方法存在的问题:
3. 联邦学习和差分隐私技术可能会出现推理攻击;
4. 基于混淆电路的安全多方计算,由于需要传输大量数据,所以在使用上受限;
5. 多个数据源提供的数据,可能是横向分布(也就是不同的拥有方提供的数据包含了全部特征)或者是纵向分布(不同拥有方提供的数据可能只是包含了部分特征),在训练模型的时候可能不能同时顾及。
文章贡献
提出了一个在加密数据上进行训练的框架NN-EMD
- 能够根据数据集的类型(横向分布,或者纵向分布)选择不同的数据计算处理方式,也就是不仅能够使用横向分布的数据进行训练,也能使用纵向分布得数据进行训练,或者是这两种不同数据分布的混合。
- 这个框架不仅能够保护原始的输入数据,同时也能融合其他隐私保护的技术如SplitNN和联邦学习。
- 我们实现了NN-EMD系统。
- 分析了方法的安全性和隐私性。
- 实验结果表示:能大大减少训练时间,能达到不错的精度值;此外,神经网络的深度和复杂性并不影响训练时间。
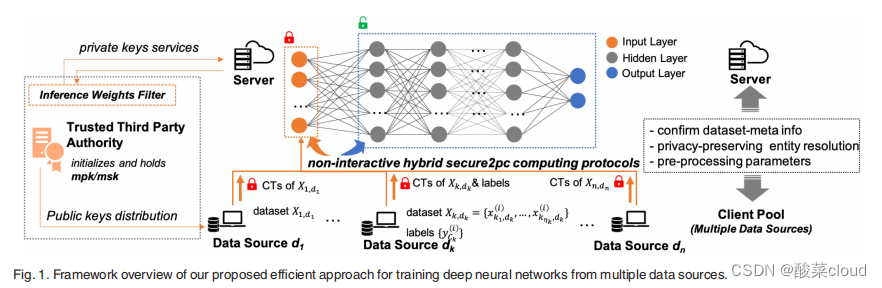
NN-EMD框架
系统实体
- 一个客户端池:拥有多个数据源,提供横向或者纵向分布的,或者两者混合的数据。每个数据源对其他实体保密自己的数据。
- 一个服务器:负责训练DNN模型。
- 一个可信的第三方TPA:初始化底层的密码学系统,将相关的公钥发给数据源和服务器,向服务器分布对应的解密密钥。TPA不能接触到加密的训练数据。
威胁模型
- 半诚实的服务器:执行协议或者算法,但是想要获知从加密的数据或者最后的结果得到隐私信息。
- 好奇并且枸杞的数据源:数据源勾结在一起去推断那些诚实的数据源。
安全两方横向分割计算协议

- TPA初始化系统:这里注意到横向的数据集用的是单输入函数加密。在这个阶段,输入了两个参数, λ λ λ表示安全凭证长度的安全参数, η η η表示的是输入向量的最大长度,然后输出两个密钥,一个是公共公钥common public key(这这个应该是用来加密数据的)以及主密钥master private key(这个应该是用来生成解密密钥的)。接着产生服务器和客户端池的安全通道。最后将公钥 p k S I − F E I P , c o m pk_{SI-FEIP,com} pkSI−FEIP,com和参数 η η η分发给客户端池和服务器。
- TPA生成解密密钥:从服务器获得 w w w检查是否符合条件(长度是不是没有超过,非零元素是不是足够多,避免太少,某个模型的数据被推理出来),执行生成算法,生成解密密钥 s k S I − F E I P sk_{SI-FEIP} skSI−FEIP发回给服务器。
- 参与方:所有数据源共同商定浮点数转化为整数的编码精度,对于每个数据源,接受了 p k c o m pk_{com} pkcom和 η η η之后,将数据转换为整数形式,检查数据集的长度是否不超过要求的,最后对每条数据进行加密,假如所有过程没有失败,那么将加密的密文和转化精度发送给服务器。
- 服务器执行计算阶段:接受 p k c o m pk_{com} pkcom和 η η η,收集加密的数据集,设置一个编码转化精度,将输入权重从浮点数转化为整数,看权重大小是不是符合要求。对权重的每一列提出来,发送给TPA生成解密密钥;计算阶段,提取每一条加密数据和每一个对应列权重的解密密钥,输出了对应输出层的结果,最后将结果从整数形式转化为浮点数形式。(伪代码中使用的 w i , j w_{i,j} wi,j很容易让人混淆,以为是新的权重,但其实不是,只是输出结果,这个结果作为第二层的输入。)
可能是复制粘贴的原因,我自己觉得Server部分在操作的时候没有encryption操作,而且server也不需要
p
k
c
o
m
pk_{com}
pkcom(因为横向的时候,这里是用作加密的密钥,但是纵向的计算中
p
k
c
o
m
pk_{com}
pkcom这个可以视为公共参数了,可以发送给server)

安全两方纵向分割计算协议

这个协议跟横向数据分布的挺像的。
- TPA初始化系统:这里注意到纵向的数据集用的是多输入函数加密。在这个阶段,输入了三个参数,
λ
λ
λ表示安全凭证长度的安全参数,
n
n
n表示的是最多能够有多少个数据源,
η
η
η(有个箭头)表示的是输入向量的最大长度,然后输出三个密钥,一个是公共公钥common public key(这这个应该是用来加密数据的)主公钥master public key(这个应该是公共参数,配合主密钥一起生成密钥的)以及主密钥master private key(这个应该是用来生成加密密钥和解密的)。
给每个数据源分发一个身份id;
接着产生服务器和客户端池的安全通道;
利用mpk,msk和id生成对应一个数据源的公钥 p k M I − F E I P , i d d k pk_{MI-FEIP,id_{dk}} pkMI−FEIP,iddk(我也不知道要这个干嘛,好像后面没有用到)把生成的 p k M I − F E I P , i d d k pk_{MI-FEIP,id_{dk}} pkMI−FEIP,iddk和 p k c o m pk_{com} pkcom以及 η i d d k η_{id_{dk}} ηiddk也就是( η η η)发给数据源
最后将公钥 p k M I − F E I P , c o m pk_{MI-FEIP,com} pkMI−FEIP,com和参数 η η η、 n n n发给服务器。
(这里参数变多了) - TPA生成解密密钥:从服务器获得
w
w
w检查是否符合条件(长度是不是没有超过,非零元素是不是足够多,避免太少,某个模型的数据被推理出来),输入,mpk,msk和w执行生成算法,生成解密密钥
s
k
M
I
−
F
E
I
P
sk_{MI-FEIP}
skMI−FEIP发回给服务器。
(这一步基本相同) - 参与方:接受参数,
p
k
M
I
−
F
E
I
P
,
i
d
d
k
pk_{MI-FEIP,id_{dk}}
pkMI−FEIP,iddk和
p
k
c
o
m
pk_{com}
pkcom以及
η
i
d
d
k
η_{id_{dk}}
ηiddk,所有数据源共同商定浮点数转化为整数的编码精度,对于每个数据源,将数据转换为整数形式,检查数据集的长度是否不超过要求的,最后对每条数据进行加密(加密伪代码写的用的
p
k
c
o
m
pk_{com}
pkcom,但我觉得可能是
p
k
M
I
−
F
E
I
P
,
i
d
d
k
pk_{MI-FEIP,id_{dk}}
pkMI−FEIP,iddk,假如加密密钥相同的话,那就变成了SI-FEIP方案了),假如所有过程没有失败,那么将加密的密文和转化精度发送给服务器。
(这个过程也差不多,但是就是加密密钥可能写错了) - 服务器执行计算阶段:接受
p
k
c
o
m
pk_{com}
pkcom和
η
η
η以及
n
n
n,收集加密的数据集,设置一个编码转化精度,将输入权重从浮点数转化为整数,看权重大小是不是符合要求。对权重的每一列提出来,发送给TPA生成解密密钥;根据密文ct的索引,对密文重新排序;计算阶段,提取每一条加密数据和每一个对应列权重的解密密钥,输出了对应输出层的结果,最后将结果从整数形式转化为浮点数形式。
(这里基本相同,就是有对密文重新排序,具体不知道为什么)
NN-EMD训练框架

前情:在反向传播计算梯度的时候,会对输入矩阵进行转置,从最后一层算起(具体跟机器学习相关,我也不是很清楚),所以这里有两种密文,带ff下标指的是前向传播使用的密文数据集,而带有bg指的是反向传播使用的密文数据集。
输入:参数,数据集
S
k
S_k
Sk
输出:一个训练好的模型
- 客户端那边:
对数据集中的每一条数据进行判断,假如特征的长度是全部都有,也就是属于横向分布的数据集,那么生成数据集(代码8-9);否则,那就是只有部分特征,纵向传播的数据集,那么生成密文数据集(代码13-14);(其实也就是,反向传播生成的数据集都是用横向计算协议生成的也就是S2PVC;正向传播就要根据什么类型数据集选择什么计算协议。) - 服务器端:初始化权重向量
假如是纵向数据集密文,选择纵向计算协议,得到输出结果;否则是横向,使用横向计算协议,得到第一层输出结果。利用第一层结果计算前向传播;后面就是梯度的计算,最新更新模型。
安全分析
这里的安全分析主要是依靠与函数加密方案的不可区分性
隐私分析
- 可能可以搜集很多等式进行求解,但是只要shuffle得足够快,就不能在对应的时间内获得足够多的等式来解方程(足够多的等式去解有 n f e a t u r e 的特征(也就是未知数) n_{feature}的特征(也就是未知数) nfeature的特征(也就是未知数))
- 通过控制 w w w来求得解密密钥,或者目标模型的相关信息,这里有一个过滤层(跟xu之前的文章一样)
实验评估
小提一下:这里不考虑数据分布的问题(比如非独立同分布或者不平衡的数据);在论文的5.2.1节提到了这个框架保护了原始数据,在第一层计算结束之后,结果以明文进行呈现,后面就继续以明文的方式进行训练了,所以这其实可能会泄露一些隐私风险,作者提到结合一种SplitNN的技术(建立在数据源有一定的计算能力,能够先计算一些层),来保护神经网络的更多层
这里提到的SplitNN可以参考一下知乎的链接:Split Learning及其在数据横/纵向切分场景的应用
其实跟这个类似的,有一个论文:Partially Encrypted Machine Learning using Functional Encryption,也是训练的神经网络,它就考虑了第一层输出的结果可能被利用训练其他支线任务,这个文章发在人工智能的顶会NeurIPS上,为了防止第一层输出的明文结果被用来训练其他任务,这个文章提出了一些方法:压缩权重参数,减少输出结果数量,使用对抗性训练,同时也是用了模型堆叠来防止中间结果泄露隐私。















 2000
2000











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









