






线性结构
线性结构:有序数据项的合集,其中每个数据都有一个唯一的前驱和后继(第一个无前驱,最后一个无后继)
栈
线性数据结构,先进先出,后进后出
python实现栈(append,pop)(利用栈先进后出可以用来实现进制转换)
class stack:
def __init__(self):
self.items = []
def isEmpty(self):
return self.items == []
def push(self,item):
self.items.append(item)
def pop(self):
self.items.pop()
栈的应用:括号匹配
class Solution:
def isValid(self, s: str) -> bool:
dic = {')':'(',']':'[','}':'{'}
stack = []
for i in s:
if i in dic and stack:
if stack[-1] == dic[i]:
stack.pop()
else:
return False
else:
stack.append(i)
return not stack
#https://leetcode.cn/problems/valid-parentheses/表达式--
队列
先进先出
class Queue():d
def __init__(self):
self.items=[]
def enqueue(self,item):
self.items.insert(0,item)
def dequeue(self):
self.items.pop()双端队列(判断是否是回文字符串/回文词)
将需要判定的词从队尾加到队列中。再从两端同时移除字符并判断字符是否相等,知道deque中剩下0个或1个字符
from pythonds.basic import Deque
def check(astring):
strDeque = Deque()
for i in astring:
strDeque.addRear(i)
flag = True
while strDeque.size() > 1 and flag:
left = strDeque.removeFront()
right = strDeque.removeRear()
if left != right:
flag = False
return flag#栈
class stack:
def __init__(self):
self.stack=[]
def push(self,item):
self.stack.append(item)
def pop(self):
return self.stack.pop()
#队列
class Queue():d
def __init__(self):
self.items=[]
def enqueue(self,item):
self.items.insert(0,item)
def dequeue(self):
self.items.pop()
#两个栈形成一个队列
class StackToQueue:
def __init__(self):
self.stack1=[]
self.stack2=[]
def push(self,data):
'''
push数据到stack1
append()数据是直接添加到列表的最后
:return:
'''
self.stack1.append(data)
def pop(self):
if len(self.stack2)==0 and len(self.stack1)==0:
return
elif len(self.stack2)==0:
while len(self.stack1)>1:
self.stack2.append(self.stack1.pop())
return self.stack2.pop()
s=StackToQueue()
#两个队列形成一个栈
class QueueToStack:
def __init__(self):
self.queue1=[]
self.queue2=[]
# 元素push进入queue1
def push(self,data):
self.queue1.append(data)
def pop(self):
if len(self.queue1)==0:
return None
while len(self.queue1)!=1:
# 则将queue1的数据的第一条数据append给queue2,这样queue2的最后一个数据一定是最后进入到列表中的
self.queue2.append(self.queue1.pop(0))
# 交换1和2 此时 ,queue1里面是有数据的,而queue2 是没有数据,那么下次pop的时候,还是会while 将queue1的数据全部添加到
# queue2 中,那queue2 将保持最先进入的数据在列表的最后,最后进入的数据在列表的第0项 所以这里应该是这么理解的。
self.queue1,self.queue2=self.queue2,self.queue1
return self.queue2.pop()
链表
递归
将问题分解为更小规模的问题;持续分解,直到问题规模小到可以用简单直接的方式解决;调用自身。
#求和
def listSum(alist):
sum = 0
for i in alist:
sum += i
return sum
#递归
def listSum(alist):
if len(alist) == 1:
return alist[0]
else:
return alist[0] + listSum(alist[1:])#汉诺塔
def moveTower(height, formPole, withPole, toPole):
if height >= 1:
moveTower(height-1, formPole, withPole, toPole)
moveDisk(height,formPole,toPole)
moveTower(height-1, withPole, formPole, toPole)
def moveDisk(disk, formPole, toPole):
print(f'Moving disk{disk} from {fromPole} to {toPole}')
分治策略:将问题分为若干规模更小的部分,通过解决每一个小规模部分问题,并将结果汇总得到问题的解
顺序查找
o(n)
#无需表查找
def search(alist, target):
idx = 0
flag = False
while idx < len(alist) and not flag:
if alist[idx] == target:
flag = True
else:
idx += 1
return flag#顺序表查找
def orderSearch(alist,target):
idx = 0
flag = False
stop = False
while idx < len(alist) and not found and not stop:
if alist[idx] == target:
flag = True
elif alist[idx] > target:
stop = True
else:
idx += 1
return flag
二分查找
二分查找也称折半查找(Binary Search),它是一种效率较高的查找方法。但是,折半查找要求线性表必须采用顺序存储结构,而且表中元素按关键字有序排列---分而治之 -o(log n)
#递归实现
def binarySearch(alist, target):
if len(alist) == 0:
return False
else:
mid = len(alist) // 2
if alist[mid] == target:
return True
else:
if alist[mid] > target:
return binarySearch(alist[:mid],target)
else:
return binarySearch(alist[mid+1:],target)def binarySearch(alist,target):
left,right = 0, len(alist) - 1
while left <= right:
mid = (left + right) // 2
if alist[mid] == target:
return mid
elif alist[mid] > target:
right = mid - 1
else:
left = mid + 1
else:
return None
冒泡排序
冒泡排序在于对无需表进行多趟比较交换;每趟包括了多次两两相邻比较,并将逆序的交换位置,最终将本趟最大值就位;经过n-1趟比较交换,实现整表排序
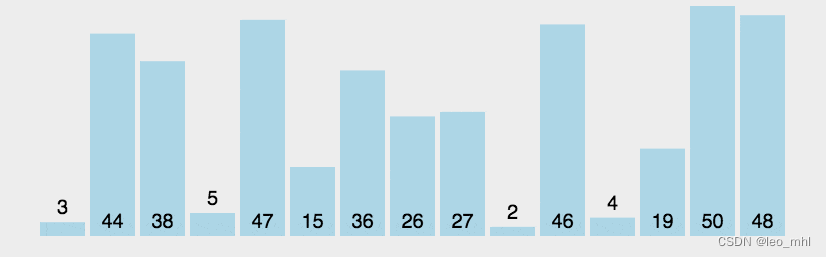
def bubbleSort(alist):
for i in range(len(alist)-1):#排序趟数
for j in range(i):
if alist[j] > alist[j+1]:
alist[j],alist[j+1] = alist[j+1], alist[j]
冒泡性能改进:通过监听每趟是否发生过交换,若无则已排好序,可提前结束
def shortBubbleSort(alist):
exchange = True
passnum = len(alist) - 1
while passnum > 0 and exchange:
exchange = False
for i in range(passnum):
if alist[i] > alist[i+1]:
exchange = True
alist[i], alist[i+1] = alist[i+1], alist[i]
passnum -= 1
选择排序
基于冒泡排序,但每趟仅进行一次交换,记录最大值(或者最小值)所在位置,再跟本趟最后一项(第一项)交换
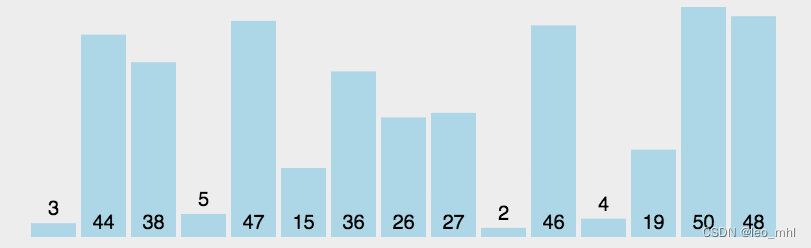
def selsectSort(alist):
new_alist = []
for i in range(len(alist)):
min_num = min(alist)
new_alist.append(min_num)
alist.remove(min_num)
return new_alist
def selectSort1(alist):
for i in range(len(alist)-1, 0, -1):
idx = 0
for j in range(1, i+1):
if alist[j] > alist[idx]:
idx = j
alist[i], alist[idx] = alist[idx], alist[i]
return alist插入排序
维持一个有序的子列表,其位置始终处理列表的前部,然后逐步扩大到整个列表
- 初始时,已排序部分只包含列表的第一个元素,而未排序部分包含剩下的元素。
- 从未排序部分取出第一个元素,即将要插入已排序部分的元素。
- 将该元素与已排序部分的元素逐个比较,找到合适的位置插入。比较过程中,如果已排序部分的元素大于当前元素,就将已排序部分的元素向后移动一位,为当前元素腾出插入位置。
- 将当前元素插入到找到的位置。
- 重复上述步骤,直到未排序部分为空,此时整个排序过程完成。
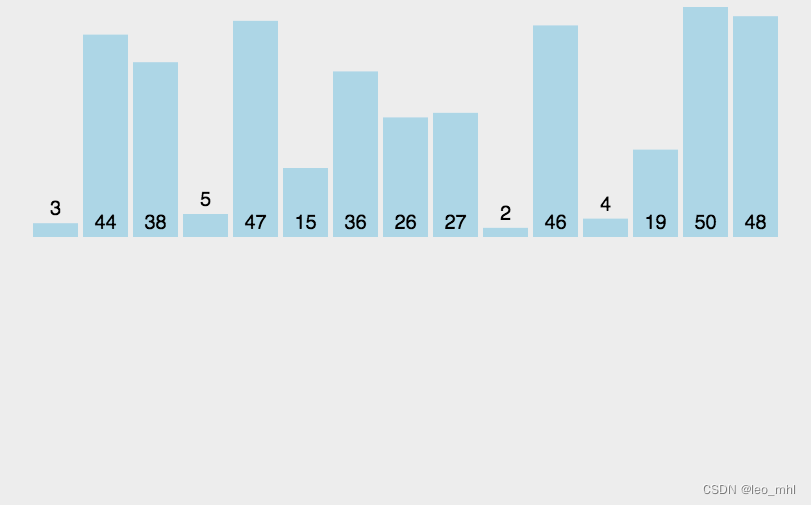
def insertSort(alist):
for i in range(1, len(alist)):
cur = alist[i] # 要插入的值
idx = i
while idx > 0 and alist[idx-1] > cur:
alist[idx] = alist[idx-1]
idx -= 1
alist[idx] = cur
return alist谢尔排序(希尔排序)
改进型的插入排序,其基本思想是先将待排序序列按一定的间隔分成多个子序列,然后对每个子序列进行插入排序。随着间隔的逐渐减小,子序列的规模逐渐增大,当间隔减至1时,整个序列被合并成一个子序列,此时再进行一次插入排序即可完成整个排序过程
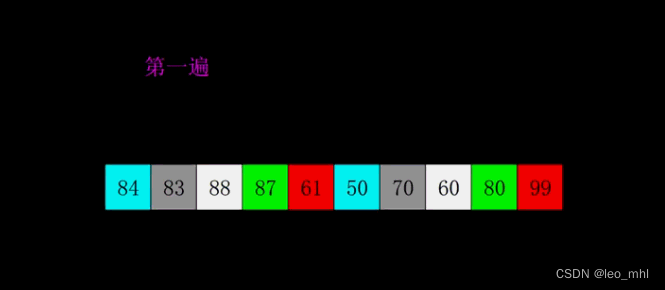
#切割列表,然后利用for循环进行插排
def shell_sort(alist):
sublistcount = len(alist) // 2 #切割子列表的步长
while sublistcount > 0: #只要还可以切割
# 通过循环遍历每个字列表
for i in range(sublistcount):
insert_sort(alist, i , sublistcount) #对每一个子列表进行插排
sublistcount = sublistcount // 2 #改变步长的长度
return alist
# 定义插排的函数
def insert_sort(alist, start, gap):
for i in range(start +gap, len(alist), gap):
currentvalue = alist[i] #记录当前循环列表里的值
position = i #记录当前位置
while position >= gap and alist[position - gap] > currentvalue:
alist[position] = alist[position - gap] #整体后移
position = position - gap # 记录当前位置
alist[position] = currentvalue#当前位置等于要插入的那个位置
li = [54,26,93,17,77,31,44,55,20]
print(shell_sort(li))
归并排序
分治策略(o(logn))
递归算法,将数据表持续分裂为两半,对两半分别进行归并排序-
递归的基本结束的条件是:数据表仅有一个数据项,此时是排好序的;缩小规模:将数据表分为相等的两半,规模减少为原来的二分之一;调用自身,两半分别调用自身排序,然后将分别排好序的两半归并,得到排好序的数据表
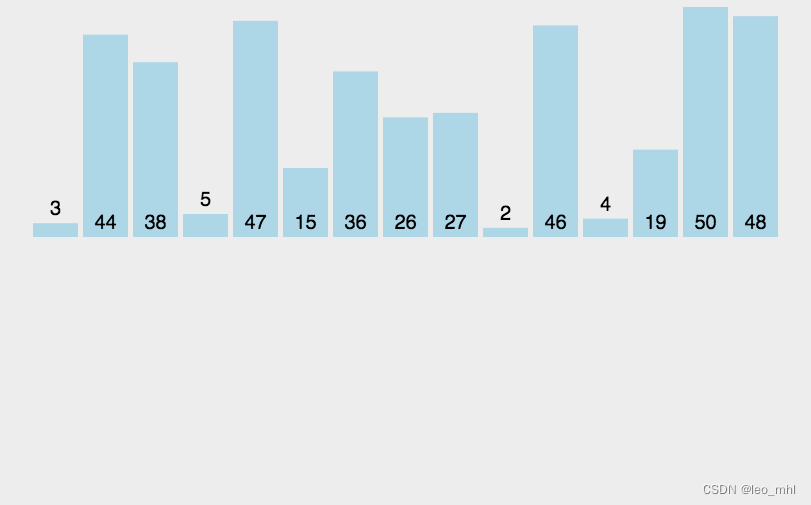
def mergeSot(alist):
if len(alist) > 1:
mid = len(alist) // 2
left = alist[:mid]
right = alist[mid:]
mergeSot(left)
mergeSot(right)
i = j = k = 0
while i < len(left) and j < len(right):
if left[i] < right[j]:
alist[k] = left[i]
i += 1
else:
alist[k] = right[j]
j += 1
k += 1
while i < len(left):
alist[k] = left[i]
i += 1
k += 1
while j < len(right):
alist[k] = right[j]
j += 1
k += 1
return alistdef mergeSort(alist):
#递归结束条件
if len(alist) <= 1:
return alist
#分解问题,递归调用
mid = len(alist) // 2
left = mergeSort(alist[:mid])#左半部排序
right = mergeSort(alist[mid:])#右半部排序
#合并左右半部,完成排序
mergerd = []
while left and right:
if left[0] <= right[0]:
merged.append(left.pop(0))
else:
merged.append(right.pop(0))
#若left或right由剩余
merged.extend(right if right else left)
return merged
快速排序
快速排序是依据一个中值的数据项把列表分为两半,小于中值和大于中值,然后分别对两半进行快速排序
快排的递归三要素:基本结束条件:数据项仅有一个数据;缩小规模:根据中值将列表分为两半,最好是相等规模的两半;调用自身:将两半分别调用自身进行排序
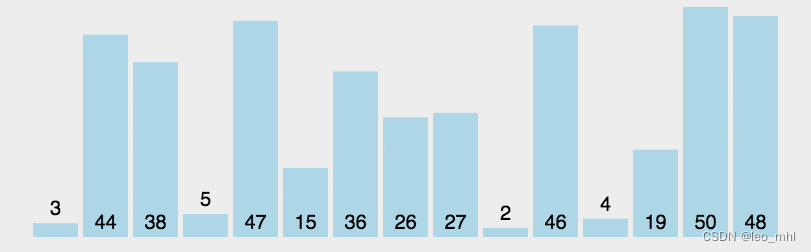
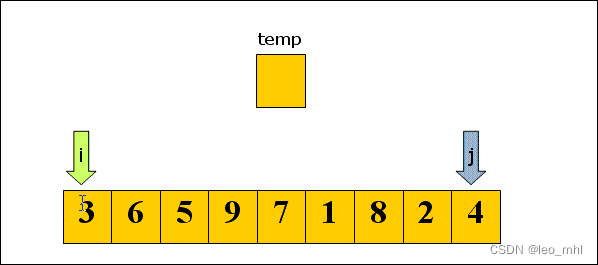
def partation(li,left,right):
tmp = li[left]
while left < right:
while left<right and li[right] >= tmp:
right -=1
li[left] = li[right]
while left < right and li[left] <= tmp:
left +=1
li[right] = li[left]
li[left] = tmp
return left
def quick(li,left,right):
if left < right:
mid = partation(li,left,right)
quick(li,left,mid-1)
quick(li,mid+1,right)
def QuickSort(num):
if len(num) <= 1: #边界条件
return num
key = num[0] #取数组的第一个数为基准数
llist,rlist,mlist = [],[],[key] #定义空列表,分别存储小于/大于/等于基准数的元素
for i in range(1,len(num)): #遍历数组,把元素归类到3个列表中
if num[i] > key:
rlist.append(num[i])
elif num[i] < key:
llist.append(num[i])
else:
mlist.append(num[i])
return QuickSort(llist)+mlist+QuickSort(rlist) #对左右子列表快排,拼接3个列表并返回
散列Hash
(无序顺序查找,有序二分查找)散列能使查找的次数降低到常数级别
散列表(hash表)(key-value)
实现从数据项到存储槽名称的转变的称为散列函数;常用的散列方法是求余法,将数据项大小除以散列表的大小,得到的余数为槽号(key),多个key重复时,会造成冲突,解决:扩大散列表的容量,大到所有可能出现的数据项都能有不同的key;
完美散列函数用于数据一致性的校验:数据文件一致性判断;为每个文件计算散列值,仅比较散列值即可知道文件是否一致;网络文件下载完成性校验;文件分享。网盘中相同的文件无需多次存储
数据一致性校验:加密形式保存密码;仅保存密码的散列值,用户输入密码后,计算散列值并比较,无需保存密码的明文即可判断密码是否正确















 3144
3144

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









