







 本文介绍了字符编码的历史和发展,从ASCII码的128个字符到Unicode字符集的广泛包容性。UTF-8编码作为解决方案,它兼容ASCII,使用可变长度节省空间,但也会增加某些语言的存储需求。讨论了UTF-8编码的规则和优缺点,以及其在现代编码系统中的重要地位。
本文介绍了字符编码的历史和发展,从ASCII码的128个字符到Unicode字符集的广泛包容性。UTF-8编码作为解决方案,它兼容ASCII,使用可变长度节省空间,但也会增加某些语言的存储需求。讨论了UTF-8编码的规则和优缺点,以及其在现代编码系统中的重要地位。
我们为什么要使用UTF-8编码?
计算机只能识别二进制数字,因此我们使用和看到的字母,数字,汉字,符号,emoji等 都需要用某种方式转换成二进制数字进行储存,需要我们用的时候在转换为相应的字母,数字,汉字,符号,emoji等
ASCII码出现了
支持:
0-9
a-z
A-Z
!"#$%^&*()
等128个字符
每个字符都有对应的码点,是0~127之间的数字,所支持的所有字符及其对应码点的集合,叫做字符集,所以ASCII字符集出现了:

从 字符 A 到 二进制 01000001的过程叫做编码
反之
从 二进制 01000001 到 字符 A 的过程叫做解码
但是ASCII只支持常用的符号和英文字母,其它国家的文字和新的符号并不支持,所以其它国家就开始制定自己的编码标准,比如大陆就有GB2312,港澳台的Big5,后来统一简繁日韩文字的GBK,这就造成同一篇文章,写和查看的编码方式不同,导致乱码,为了解决这个问题,统一所有的字符,
Unicode字符集出现了,目前已包含了超过14w的字符,需要注意的是,字符集只是字符及字符对应码点的集合,不代表字符会以对应码点被储存在计算机中,字符编码才真正定义了从字符到计算机储存内容的映射
![[(img-BVphQVRp-1640626776070)(C:\Users\mi\AppData\Roaming\Typora\typora-user-images\image-20211228005726732.png)]](https://i-blog.csdnimg.cn/blog_migrate/5c05930aa41f86b51aa909d9f962403e.png)
当然,最简单的编码方式就是将字符对应的码点直接以二进制存储在计算机中,ASCII和UTF-32就是这样做的
ASCII只有128个,占用一个字节,直接使用码点编码十分方便,但是Unicode字符集储存了十几万的字符
比如这个字符,在Unicode中

十进制:
128169
二进制:
11111010010101001
二进制有17比特,而且还不能让二进制数字直接跟在别的字符的二进制数字后面,因为这样无法区分每个字符是从哪里开始,到哪里结束
所以UTF-32就让每个字符以32比特,四字节长度来存储,不够的高位补零

32byte足够包含unicode字符集中所有字符,固定的长度,也能帮助计算机识别每个字符的截断范围(4字节),但是这就造成英文使用者,他们曾经用Ascii字符集,每个字符只用一个字节储存,但现在用UTF-32,每个字符必须用4个字节储存,文件大小直接扩张到了4倍
汉字使用者,GBK中一个汉字只占2个字节,现在也要4个字节,文件大小扩张到了2倍,这显然无法接受,为了拯救空间效率
UTF-8编码诞生了,UTF-8是针对Unicode的可变长编码,针对不同的字符,可以用1~4字节储存
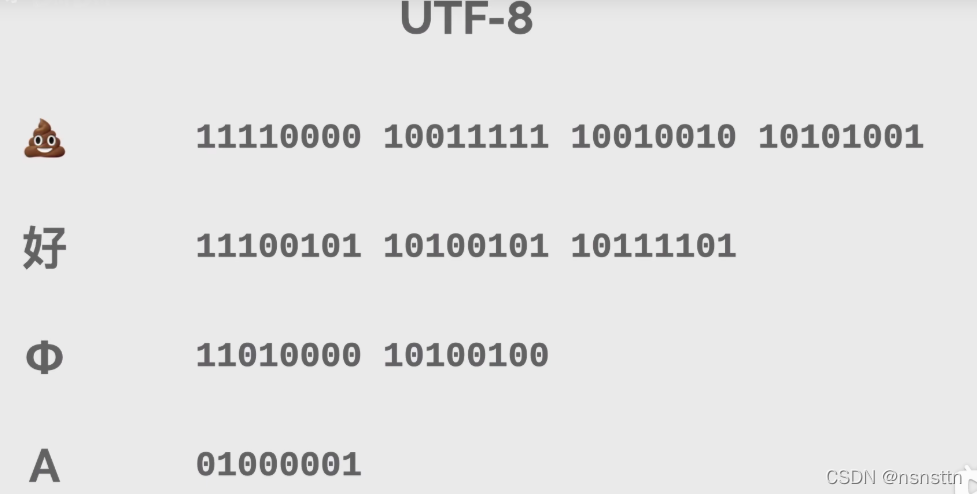
具体规则为:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LLfAqDFj-1640626663955)(C:\Users\mi\AppData\Roaming\Typora\typora-user-images\image-20211228011742196.png)]](https://i-blog.csdnimg.cn/blog_migrate/5dca056eafd2b9c480fbe0b59aaf3b40.png)
简单说看到
0开头,就往后找一个字节
110开头,就往后找两个字节
1110开头,就往后找三个字节
11110开头,就往后找四个字节
后面的字节都为10开头
范围计算:
2的(8-1)次 - 1 = 127
2的(16-5)次 - 1= 2047
2的(24-8)次 - 1= 65535
2的(32-11)次 - 1= 1114111
优点:
兼容ASCII
可变长度,节约空间
扩展性好,以后有更多的字符也不怕
缺点:
汉字需要3个字节,不如GBK2个字节
计算一个字符的字节长度,不方便
欢迎补充~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









