







支持向量机SVM
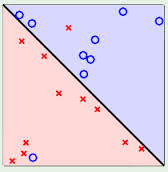
首先我们在之间的学习中,在已知一些数据将他们划分为不同种类的数据,找到最合适的函数直线或者曲线或者超平面,比如下面的:

而SVM的目的也在于去分类,但是其目的是找到区分两类最大边际的超平面:

观察上面的图像,wx+b=1和wx+b=-1是两条边际线,那么我们下面做一些推导:

这里会用到向量内积:


那么最后推导出来d=2/||w||,因为d是两条边界线的距离,我们使用SVM就是寻找最大两条边际线,所以就把问题转化为求d的最大值,也就是求||w||/2的最小值

对于求min||w||/2下面引入一些方法:

其中对于拉格朗日乘子法也可以去处理带有不等号的约束条件

所以我们的问题是求||w||/2的最小值并且在条件y(wx+b)-1>=0的情况下,从而构造L(w,b,a)函数:

之后我们对L(w,b,a)进行对w和b分别求导,求得:

再将求导之后的带回原函数得到

SMO算法:

可以得到最优解:

松弛变量与惩罚函数
又是分类的时候我们会出现线性不可分的情况,那么我们要引入松弛变量和惩罚函数。松弛变量用于约束条件没有体现错误分类的点要尽量接近分类边界。惩罚函数使得分错的点越少越好,距
离分类边界越近越好。
修改公式为:
𝑦𝑖 𝑤𝑖 ∙ 𝑥𝑖 + 𝑏 ≥ 1 − 𝜀𝑖, 𝜀𝑖 ≥ 0
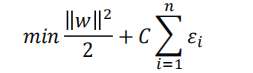
非线性情况
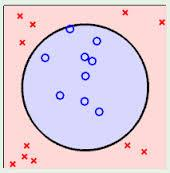
针对非线性情况,我们要把非线性转化成线性,用到把低维空间的非线性问题映射到高维空间。
变为

变为

低维变高维大家可以从这个网站感受一下低维变成高维。
这个视频就是将平面散乱的二维点变成三维的立体点,在三维我们就可以找到一个平面去截取这个三维平面尽心分类,之后再将三维度和找到的分类平面投影到二维平面再次重高维变成低维。


针对上面的式子变形:
1.维度灾难
红色的地方要使用映射后的样本向量做内积假如最初的特征是n维的,我们把它映射到n2维,然后再计算。这样需要的时间从原来的的O(n),变成了O(n2)
2.如何选择合理的非线性转换?
我们可以构造核函数使得运算结果等同于非线性映射,同时运算量要远远小于非线性映射。
上面提到引入核函数,主要用于运用一个合理的非线性转化,我们下面举个例子:
假设定义两个向量: x = (x1, x2, x3); y = (y1, y2, y3) 定义高维映射方程:
f(x) = (x1x1,x1x2, x1x3, x2x1, x2x2, x2x3, x3x1, x3x2, x3x3)
假设x = (1, 2, 3),y =4, 5, 6).
f(x) = (1, 2, 3, 2, 4, 6, 3, 6, 9) f(y) = (16, 20, 24, 20,25, 36, 24, 30, 36)
求内积<f(x), f(y)> = 16 + 40 + 72 + 40 + 100+ 180 + 72 + 180 + 324 = 1024
但我们定义一个核函数:
定义核函数:K(x,y) = (<f(x), f(y)>)^2
K(x,y) = (4 + 10 + 18)^2 = 1024
我们发现:同样的结果,使用核方法计算容易得多。
SVM优点:
• 训练好的模型的算法复杂度是由支持向量的个数决定的,而不是由数据的维度决定的。所以SVM不太容易产生overfitting
• SVM训练出来的模型完全依赖于支持向量(Support Vectors), 即使训练集里面所有非支持向量的点都被去除,重复训练过程,结果仍然会得到完全一样的模型。
• 一个SVM如果训练得出的支持向量个数比较小,SVM训练出的模型比较容易被泛化。
代码部分我们下一节写入。















 725
725











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









