







文章目录
Redis的了解
在认识Redis之前,先来认识一个NoSQL(非关系型数据库)以及SQL的区别:
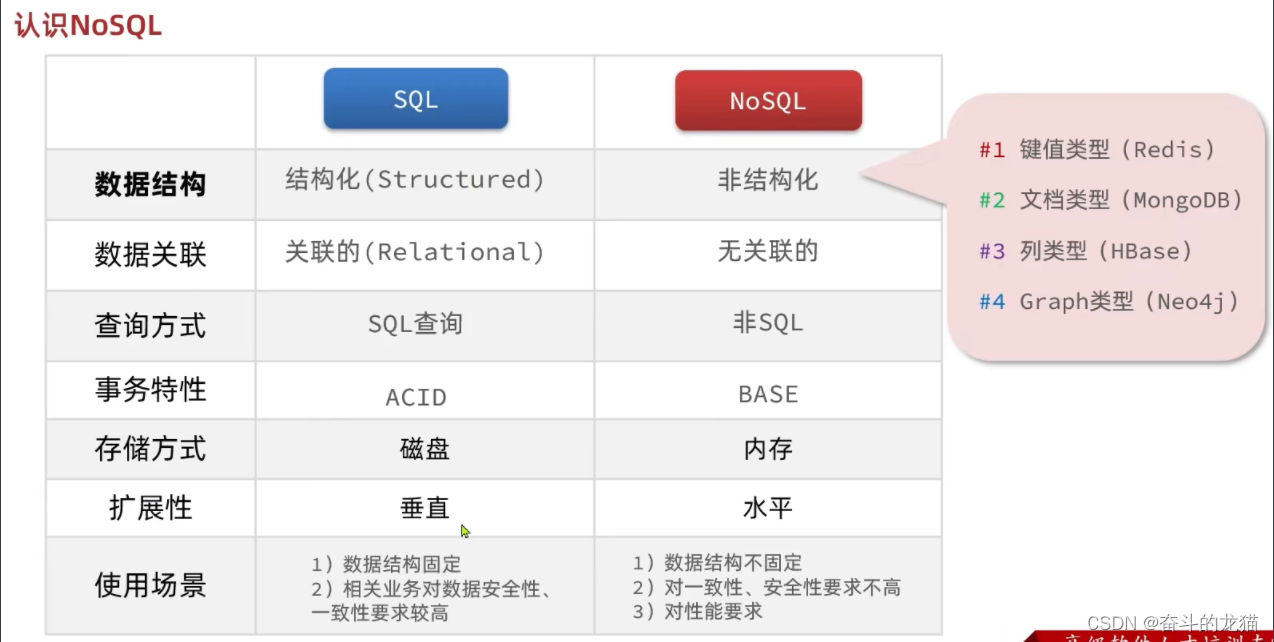
Redis就是Remote dictionary server(远程词典服务器),是基于内存的键值型NoSQL数据库。拥有以下特征:
- 键值型,value可以是不同的类型
- 单线程,每个线程具有原子性
- 低延迟,速度快(主要是因为它是基于内存的)
- 支持数据持久化
- 支持主从集群,分片集群
- 支持多语言的客户端
Redis的数据结构
Redis的数据结构中主要有以下几种:

Redis中的常用命令
-
keys pattern :来查找符合pattern形式的key。并且pattern中使用
*表示任意个任意字符,?表示一个任意字符 -
del key1 [key2 key3 key4…]:删除key1 key2,然后返回已经删除的key的个数。
-
exists key1 [key2 key3 key4 …]: 判断key1 key2 key3 …这些key是否存在,结果返回的是存在的key的个数
-
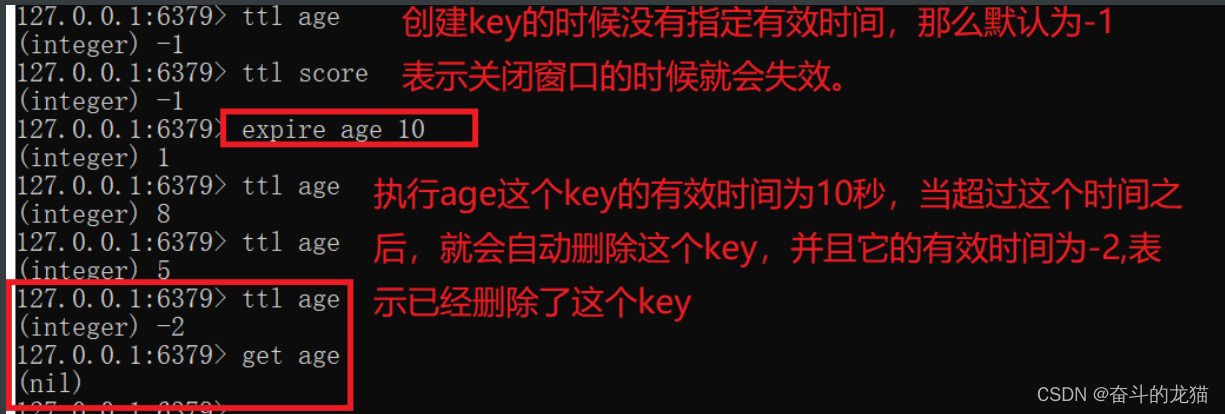
expire key_name seconds: 设置key_name这个名字的key的有效时间,它是以秒为单位的,当有效时间到达之后,就会自动删除这个key。如果在创建这个名字的key的时候,需要指定这个key的有效时间,那么需要通过
set key_name key_value ex expire_time来设置,当然也可以执行setex key_name expire_time key_value来实现。当它的值为-2的时候,表示这个key的有效时间已经到达,然后自动删除这个key。 -
ttl key_name: 查看key_name这个名字的key的剩余有效时间。如果在创建key的时候,没有设置它的有效时间,那么这时候它的默认剩余有效时间为-1,表示这个key是一直有效的。
Redis中String类型的常用命令
-
set key_name key_value: 设置名字为key_name的key,并且它的value为key_value
-
get key_name :获取名字为key_name的值
-
mset key_name1 key_value1 key_name2 key_value2 …: 设置多个key
-
mget key_name1 key_name2 key_name3 …: 获取多个key的值
-
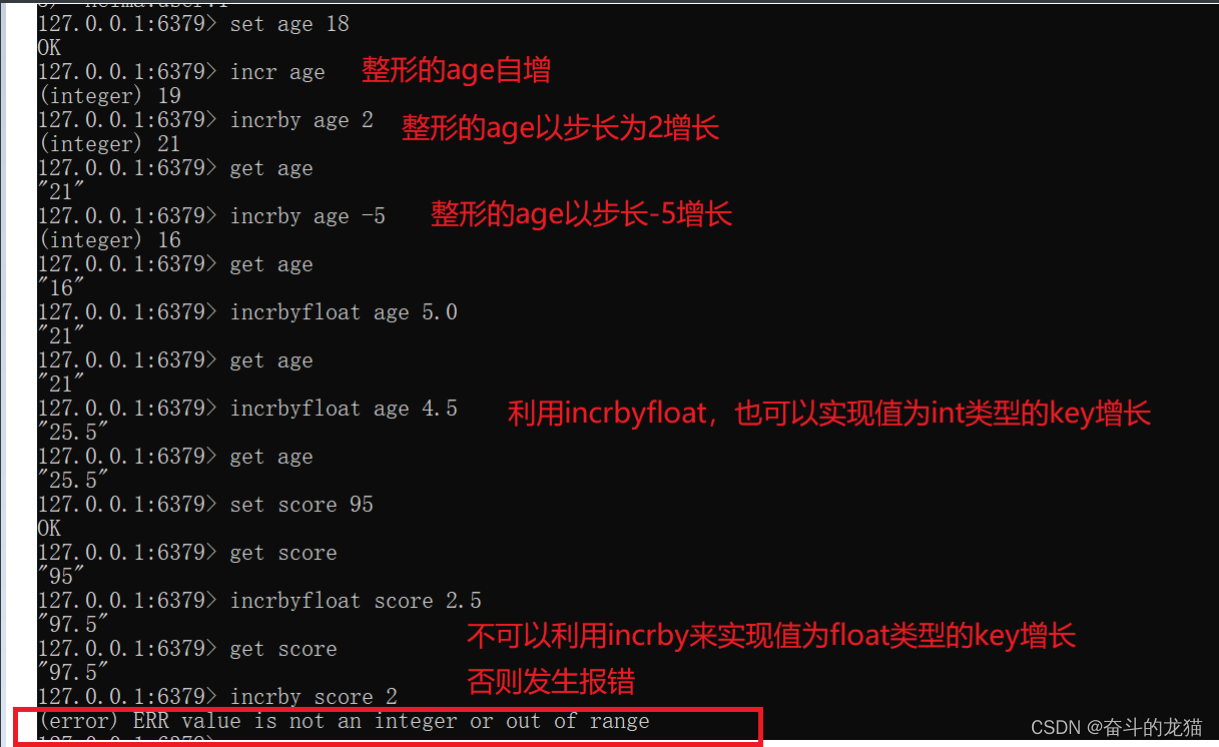
incr key_name : 名字为key_name的key实现自增,并且它的类型是整形的。如果key_name对应的类型是一个float类型,那么执行这个命令的时候就会发生报错。
-
incrby key_name step: 名字为key_name的key以步长step来进行增长,并且类型为整形的。其中step可正可负,用来实现自增或者自减。
-
incrbyfloat key_name step: 名字为key_name的key以步长为step进行增长,并且类型可以是float,也可以是int,但是如果是int类型的话,那么最后会使得这个key的类型变成了float。
-
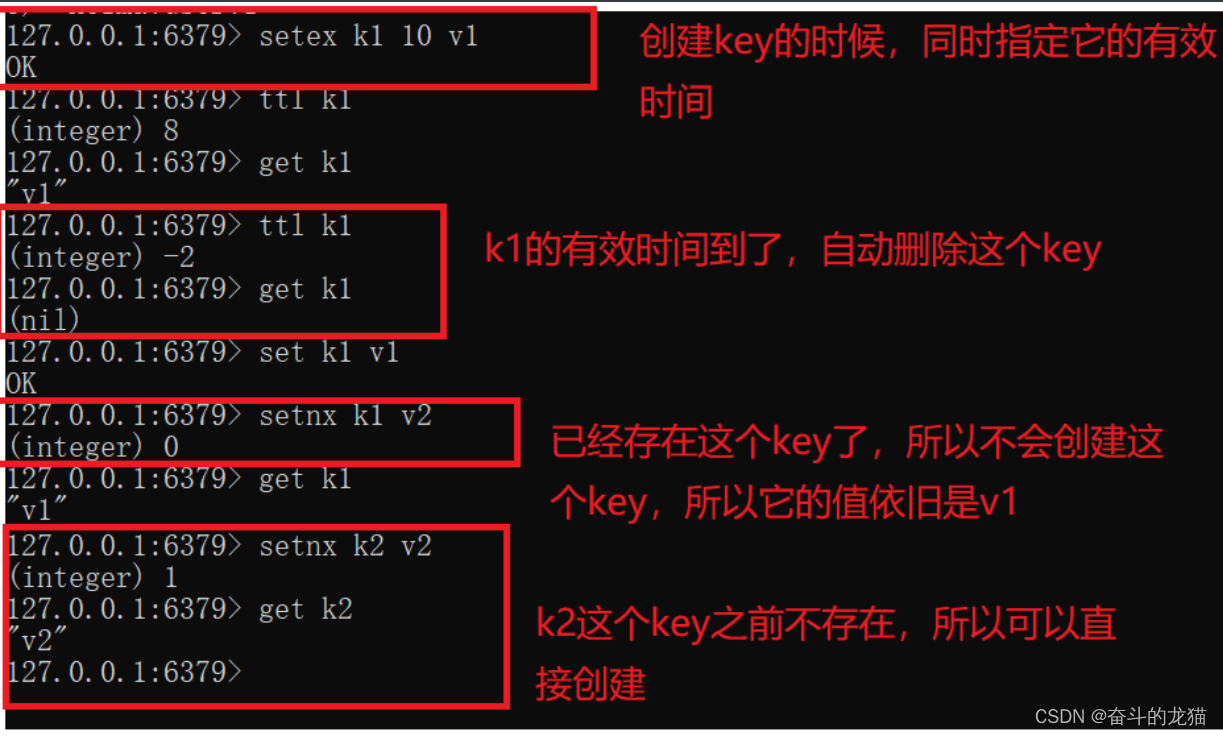
setex key_name second value: 创建key_name的key,并且它的值为value,有效时间为seconds
-
setnx key_name value: 如果名字为key_name的key不存在的时候,就会创建这个key,否则不会创建.
但是如果有多个名字相同的key,例如user中的id以及produce中的id,虽然我们可以通过名字来修改这个不同的名字,但是我们也可以通过:来定义不同的key的层次结构,它的格式一般为:项目名:业务:id,然后它的值就是一个json格式的字符串,这时候,就可以封装一个user或者produce的数据了。
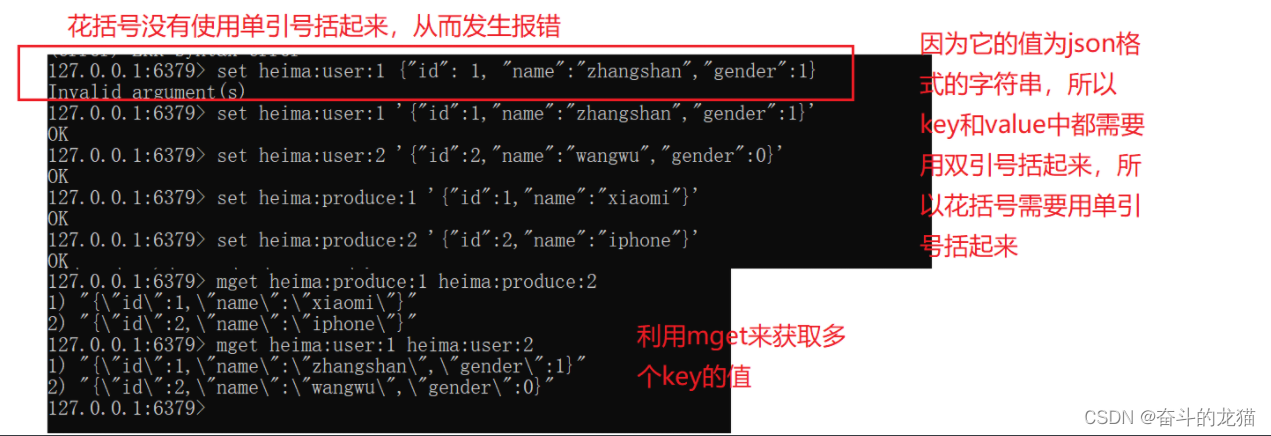
Redis中Hash类型的常用命令
在上面介绍层次结构中,一个键对应的value是一个json格式的字符串,这时候我们是没有办法来获取其中对应的字段,例如name的值的,但是在Hash类型中,一个键可以对应多个filed,而每一个field则有相应的值,那么这时候我们要获取某一个字段的值的时候,只要知道这个字段对应哪一个key,然后根据hget key_name file_name就可以获取对应的字段的值了。如下所示:
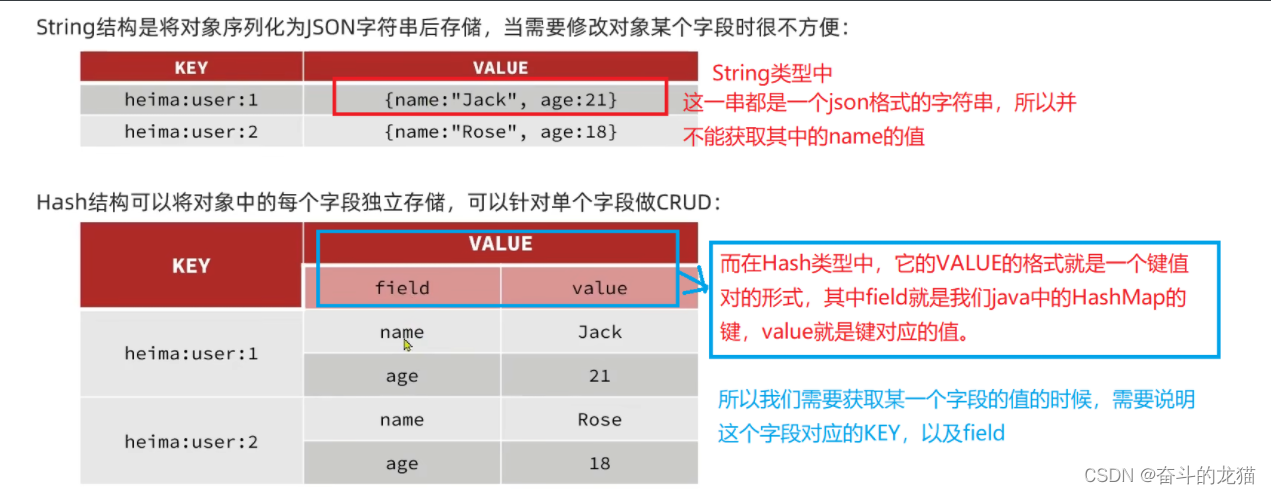
所以常用的命令有以下几种形式(在上面的String类型的命令中前面加一个h即可):
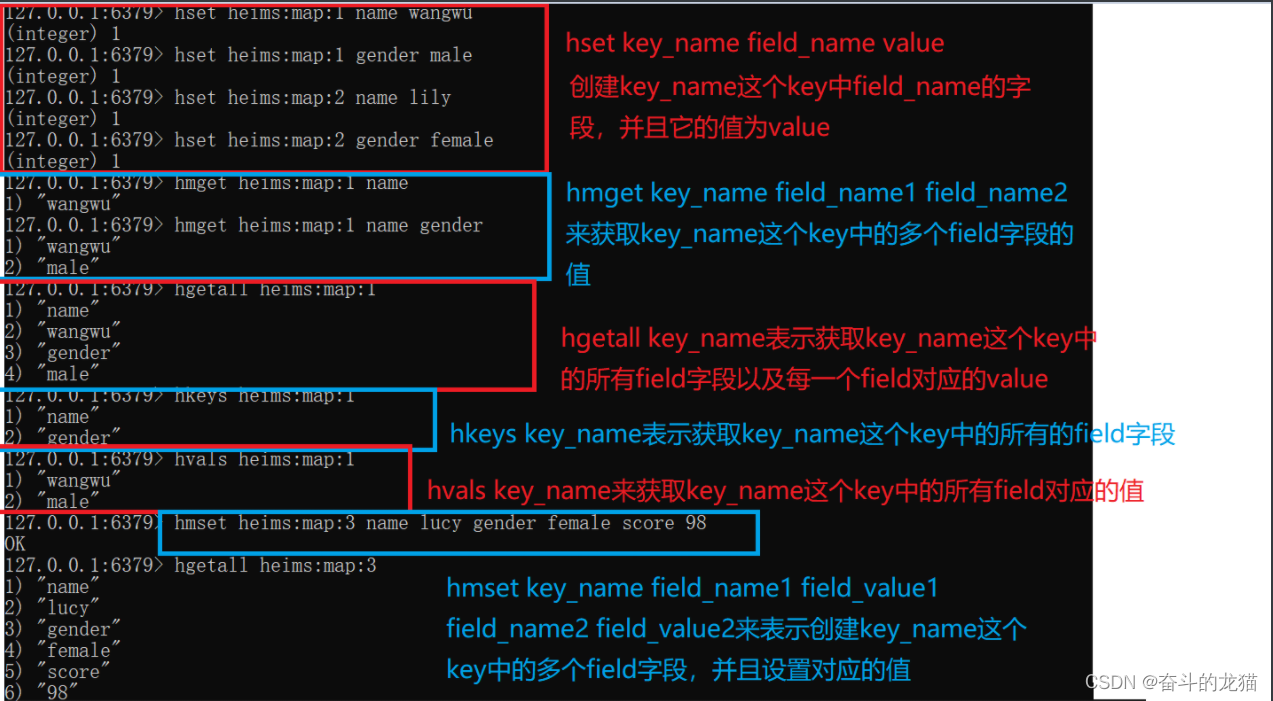
- hset key_name field_name field_value:创建key_name对应的key中,field_name的值为field_value.例如我们需要给heima:user:1中添加一个键为gender,值为female,那么就需要执行
hset heima:user:1 gender female即可 - hget key_name field_name: 获取key_name这个key对应的field的值,例如我们希望获取上面heima:user:1中的age的值,那么要执行的命令就是
hget heima:user:1 age - hmset key_name field_name1 field_value1 field_name2 field_value2 [field_name field_value]:给当前key_name这个key创建多个field,并设置对应的值
- hmget key_name field_name1 field_name2 [field_name3…]:获取key_name这个key中的多个field的值
- hgetall key_name :获取key_name这个key所有的field以及对应的值value
- hkeys key_name : 获取key_name这个key所有的field字段
- hvals key_name: 获取key_name这个key所有的value字段的值
- hincrby key_name field_name step: 将key_name这个key中的field_name字段根据step步幅增长,不过要求这个field_name对应的字段是一个int类型的
- hincrbyfloat key_name field_name step :将key_name这个key中的field_name字段根据step步幅增长
- hsetnx key_name field_name field_value : 当key_name这个key中不存在field_name这个字段的时候,就创建这个字段,否则不执行。
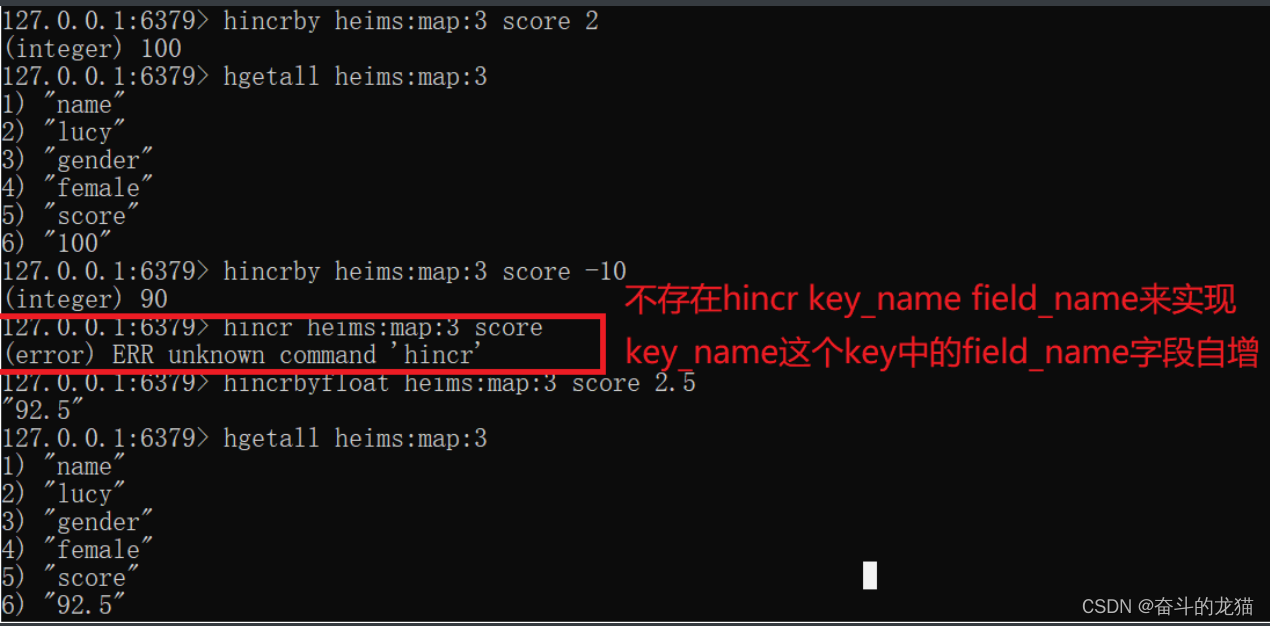
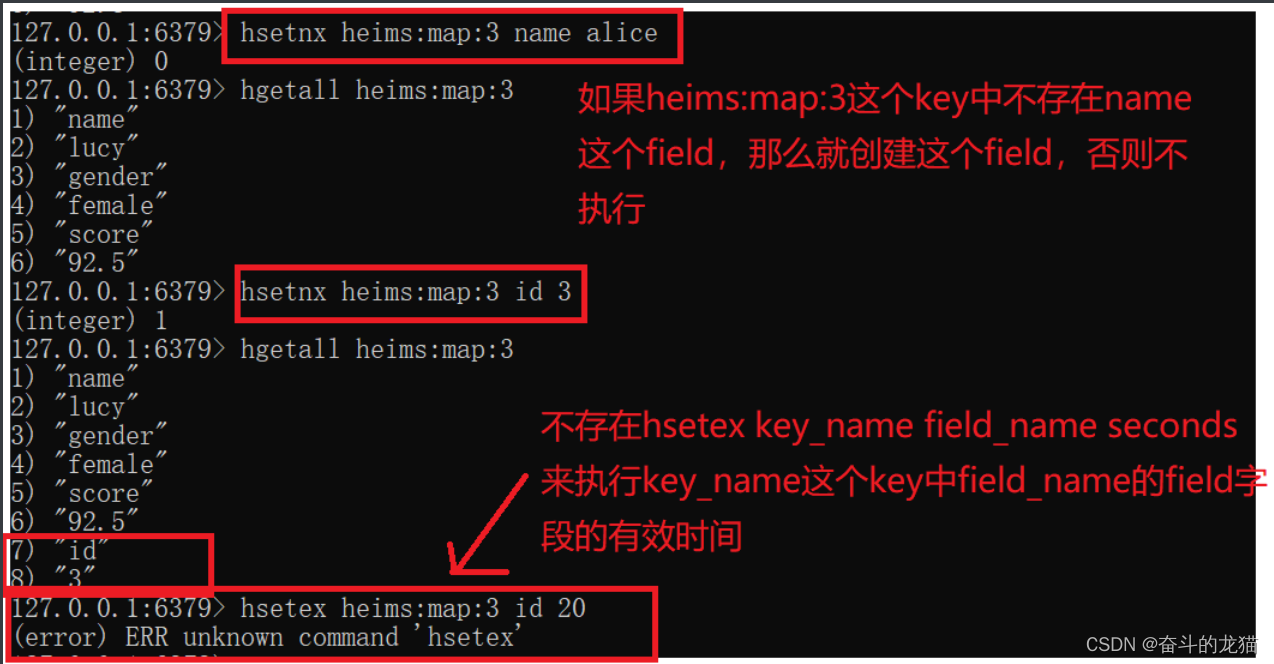
⭐⭐⭐值得注意的是,Hash类型中并不存在hincr key_name field_name来让key_name中的field_name自增。同时也不存在hsetex key_name field_name seconds 来设置key_name中的field_name的有效时间。
Redis中List类型的常用命令
-
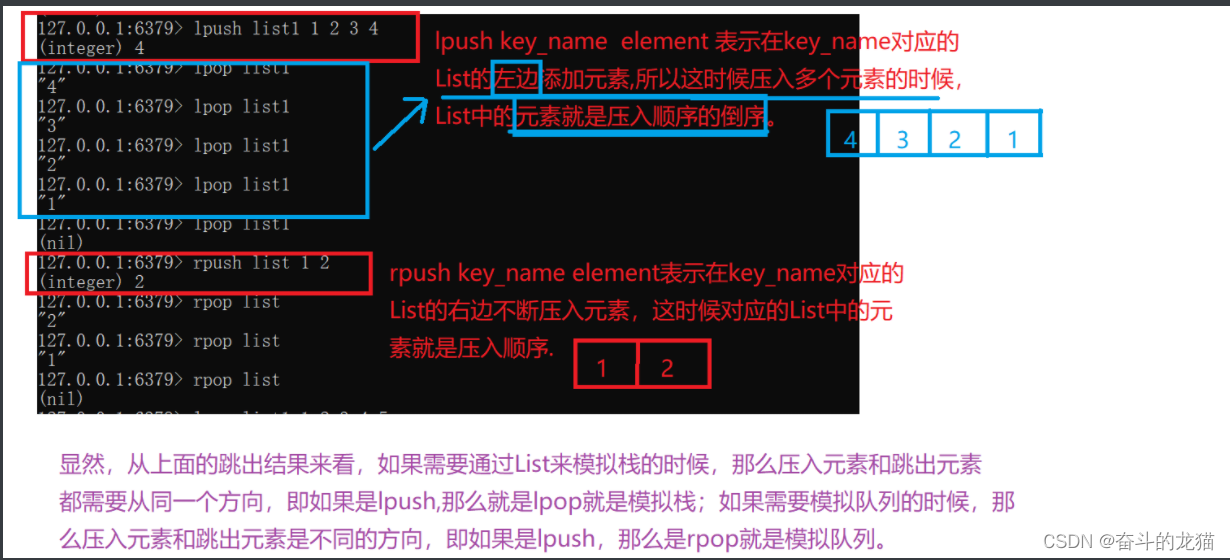
lpush key_name element1 element2 element…:在key_name这个KEY的左边不断压入element1,emelemnt2,element3…,它的VALUE是一个list类型的
-
rpush key_name element1 element2 element3…:在key_name这个KEY的右边不断压入element1,element2,element3…
-
lpop key_name: 从key_name这个KEY对应的List的左边不断获取第一个元素,并且将它移除。如果对应的List为空的时候,那么直接返回nil
-
rpop key_name:道理同上,不过是从右边不断获取元素,并且将其移除。如果List为空的时候,同样是直接返回nil
-
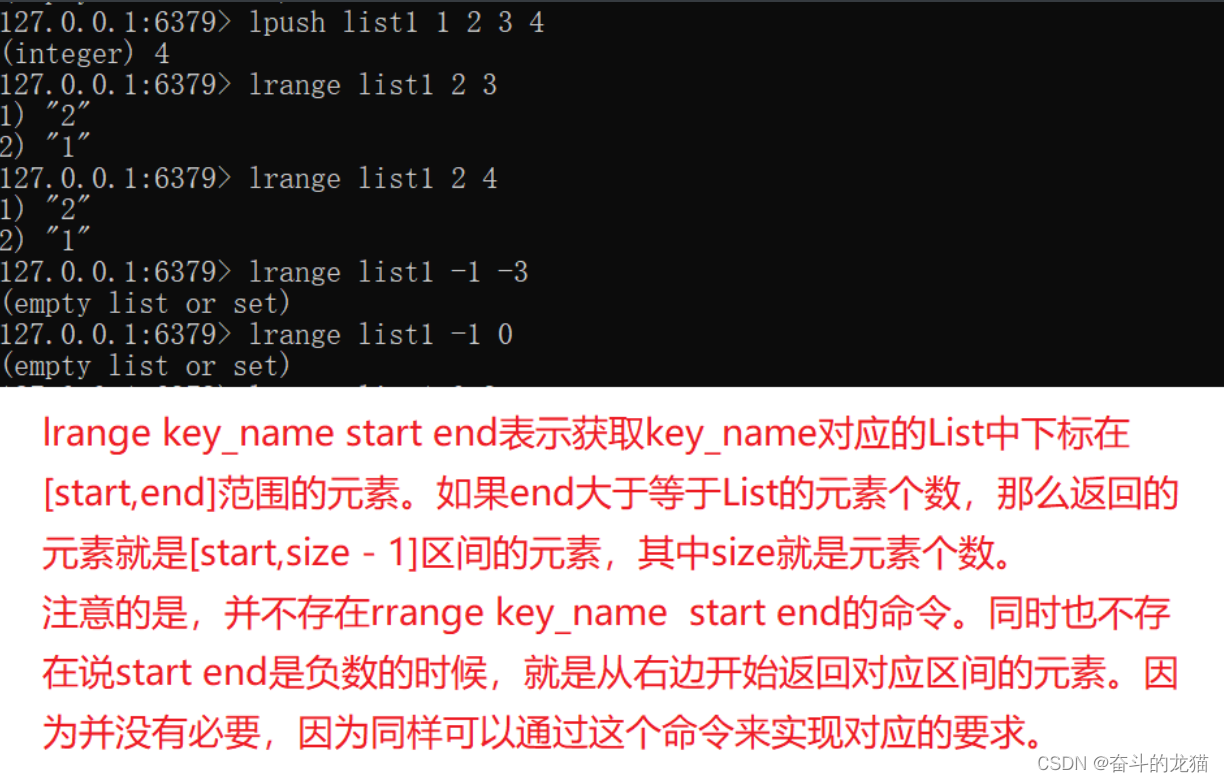
lrange key_name start end :表示获取key_name这个KEY对应的List中下标在[start,end]区间的元素.下标同样是从0开始的。如果end超过了List的元素个数,那么只能取到List的最后一个元素。注意并没有rrange key_name start end这个命令。
-
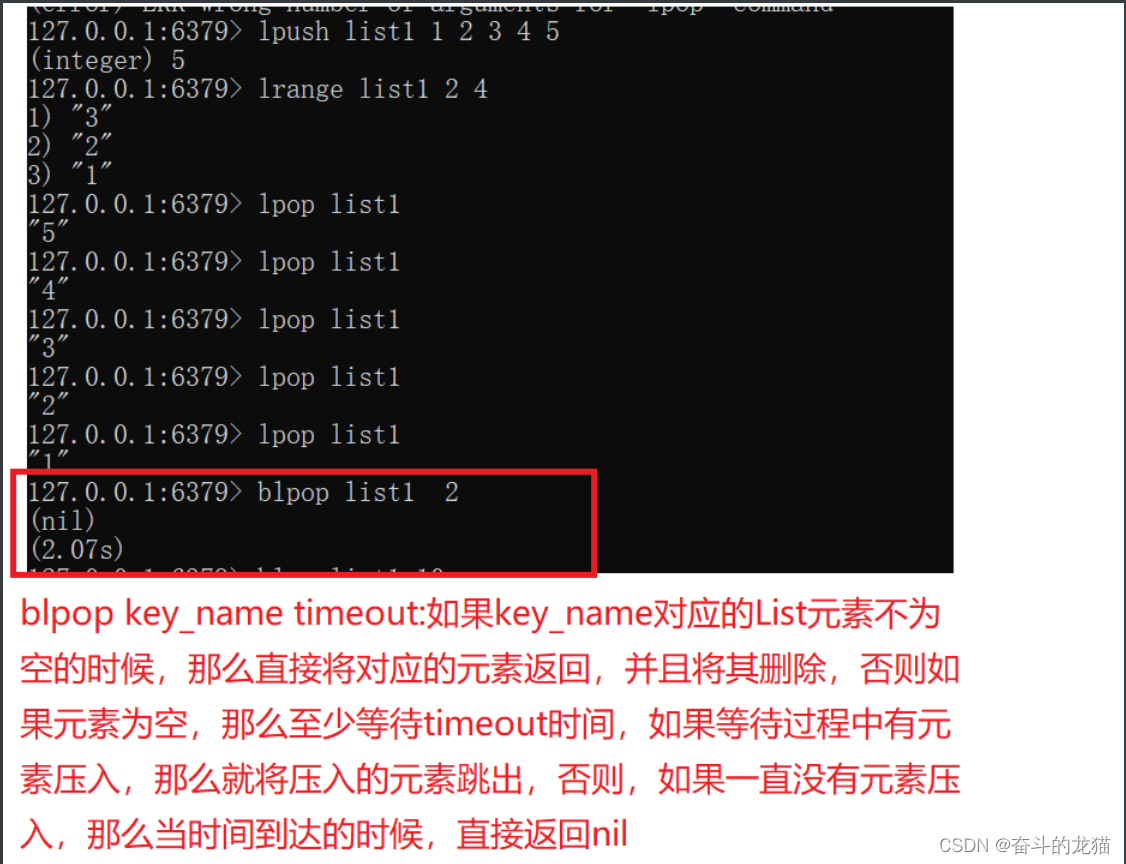
blpop key_name time_out:表示将从key_name这个KEY对应的List的左边移除第一个元素,并将这个元素返回。如果List元素为空的时候,会发生阻塞,当等待了time_out之后,如果还是没有元素,那么直接返回nil.否则如果在time_out时间内再次添加元素,那么执行对应的删除操作,并将删除的元素返回。
-
brpop key_name time_out:表示将从key_name这个KEY对应的List的右边移除第一个元素,并将这个元素返回。如果List元素为空的时候,会发生阻塞,当等待了time_out之后,如果还是没有元素,那么直接返回nil,否则如果在time_out时间内再次添加元素,那么执行对应的删除操作,并将删除的元素返回。
Redis中的Set类型的常用命令
-
sadd key_name element1 element2 element3…:给key_name这个KEY对应的Set添加元素element1,element2,element3…
-
srem key_name element1 element2 element3…: 给key_name这个KEY对应的Set删除元素element1,element2,element3…
-
scard key_name: 获取key_name这个KEY对应的Set对应的元素个数
-
smembers key_name: 获取key_name这个KEY对应的Set的所有元素
-
sismember key_name member: 判断member是否为key_name这个KEY对应的Set的元素
-
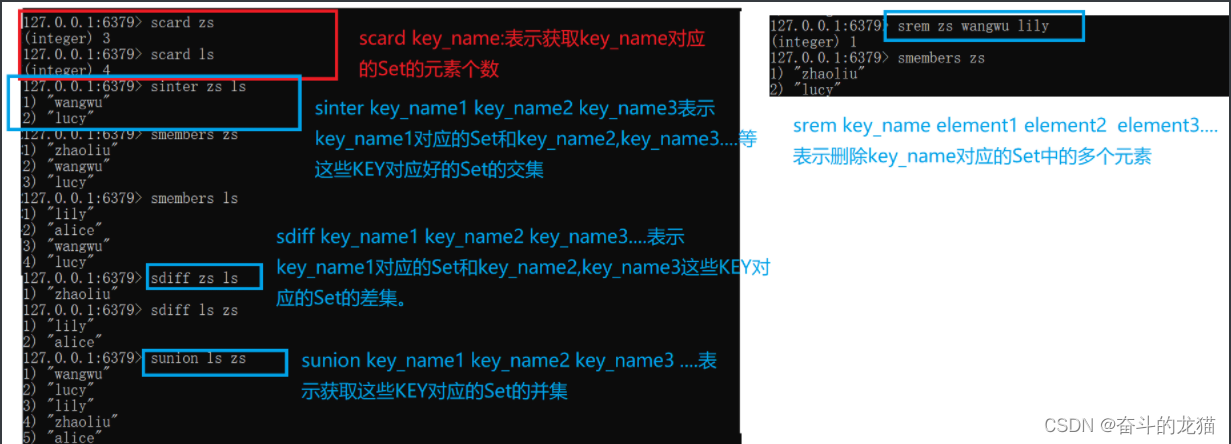
sinter key_name1 key_name2 key_name3…:获取key_name1对应Set和key_name2,key_name3…这些KEY对应的Set的并集
-
sdiff key_name1 key_name2 key_name3…:获取key_name1对应的Set和key_name2,key_name3…这些KEY对应的Set的差集
-
sunion key_name1 key_name2 key_name3…:获取key_name1对应的Set和key_name2,key_name3…这些KEY对应的Set的并集

Redis中的Sorted_set类型的常用命令
-
zadd key_name score element [score element…]:给key_name对应的Sorted_set添加多个元素,并且每一个元素都有一个属性score,它是根据score来进行排序的,默认是升序。
-
zrem key_name element1 element2…:删除key_name对应的Sorted_set中的多个元素
-
zcard key_name : 获取key_name对应的Sorted_set的元素个数
-
zcount key_name start end: 统计score在[start, end]范围中的元素个数
-
zrange key_name start end: 获取key_name对应的Sorted_set中下标在[start,end]的元素,这时候Sorted_set默认是根据score升序的。
-
zrangebyscore key_name start end: 获取key_name对应的Sorted_set中score在[start,end]的元素
-
zrank key_name element : 获取key_name中对应的Sorted_set中的元素element对应的下标
-
zscore key_name element: 获取key_name中对应的Sorted_set中的元素element的属性score的值
-
zincrby key_name step element : key_name对应的Sorte_set中的element元素对应的score以step步长进行增长。值得注意的是,如果Sorte_set中不存在这个element的时候,那么执行这一步之后,就会自动给Sorted_set添加这个element,并且对应的属性值score就是step.不仅仅使用于zincrby,也适用于incr等命令。
-
zinter key_name1 key_name2 key_name3…:获取key_name1,key_name2,key_name3这些KEY对应的Sorte_set的交集
-
zdiff key_name1 key_name2 key_name3…:获取key_name1对应的Sorted_set和key_name2,key_name3…这些KEY对应的Sorted_set的差集
-
zunion key_name1 key_name2 key_name3…:获取这些KEY对应的Sorted_set的并集

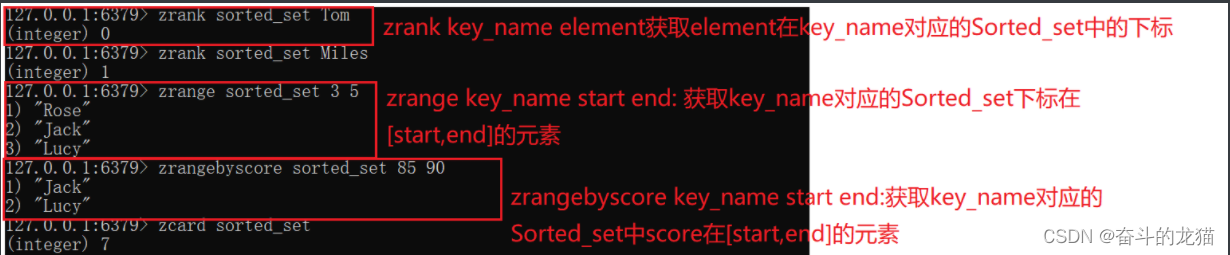
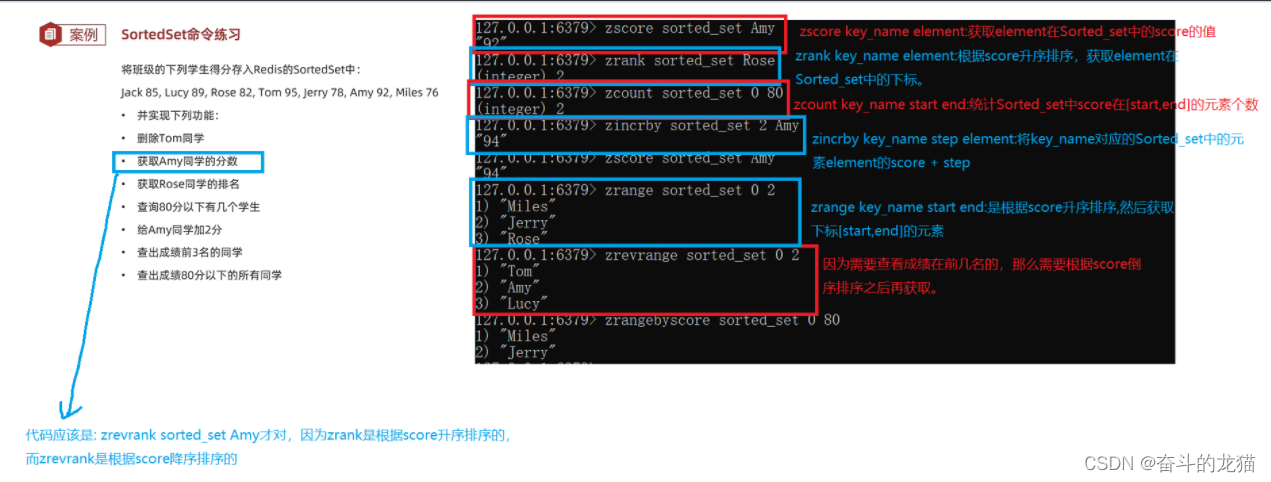
⭐⭐⭐值得注意的是,zrange,zrangebyscore,zrank进行的时候,这时候Sorted_set是根据score进行升序排序得出的结果,如果需要的是score降序对应的结果的话,那么需要执行的是zrevrange,zrevrangebyscore,zrevrank命令即可。

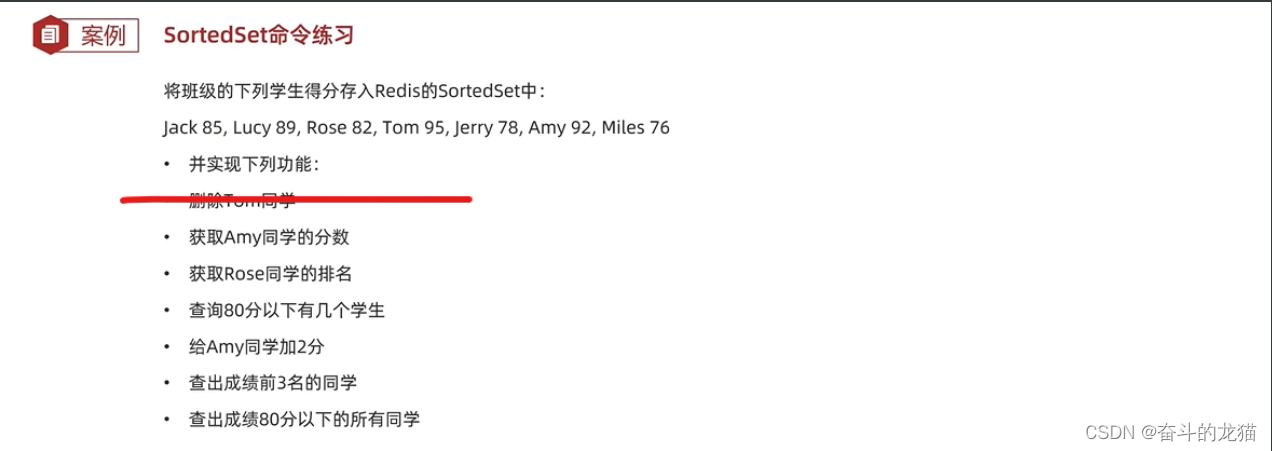
需求分析:
对应的代码为:
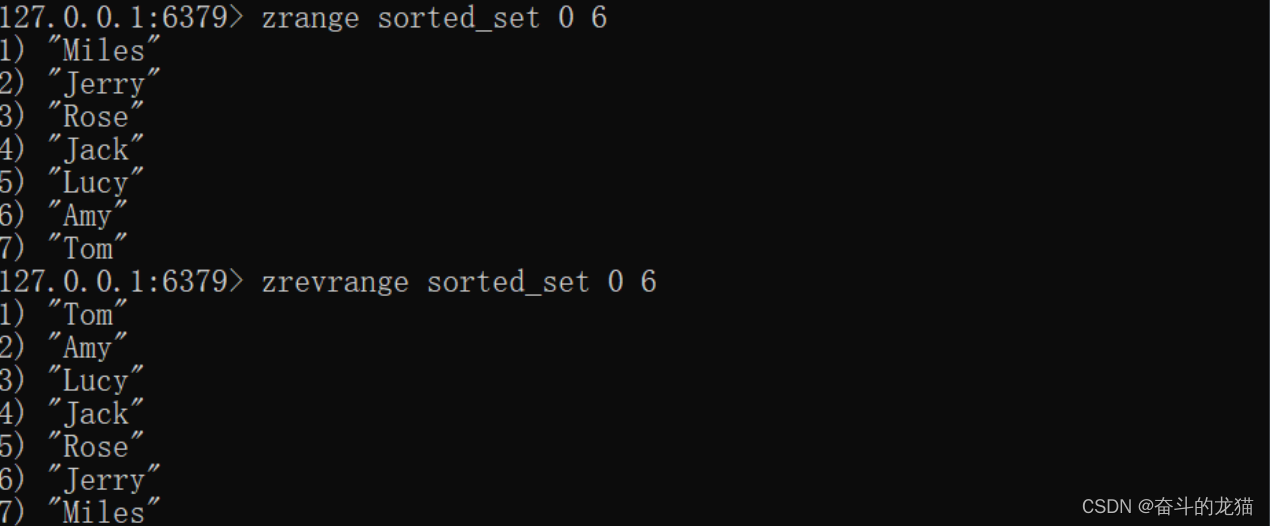
上面的代码演示判断我们是否已经所有的元素成功添加到了Sorted_set中。然后就开始演示了:
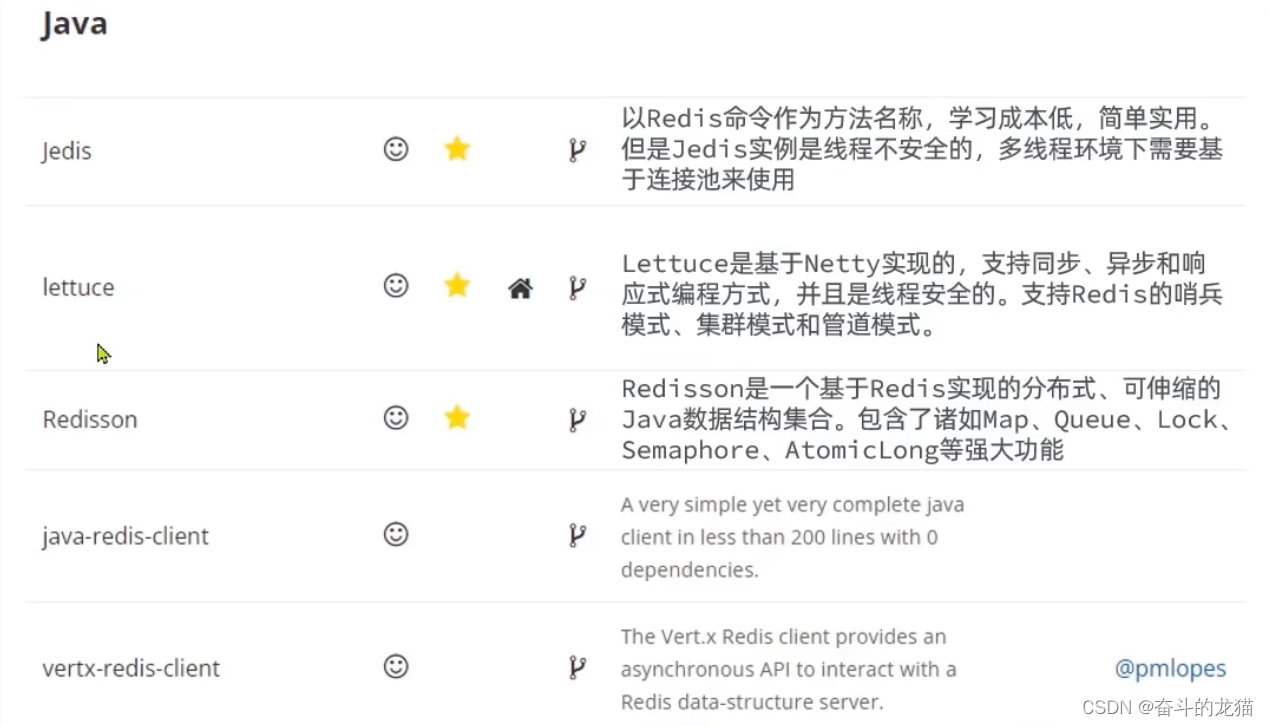
Redis中的Java客户端
Redis中的Java客户端主要有Jedis,Lettuce,Redision等,当然Spring Boot也会整合Jedis,Lettuce,所以就有了SpringBoot redis。
所以不同的客户端拥有不同的特点,如下所示:
Jedis的快速入门
实现的基本步骤:
-
导入依赖Jedis
<dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>3.3.0</version> </dependency> -
创建Jedis对象,建立和redis服务端建立连接,并且选择要使用的数据库
-
测试,因为Jedis的方法和命令相同,所以再熟悉上面的命令之后,就能够很好的通过Jedis调用相应的方法进行操作了
-
释放连接
测试代码如下所示:
public class JedisTest { private Jedis jedis; //建立连接 @Before //1、在所有的方法操作之前,执行这个代码,来初始化Jedis,建立连接 public void beforeEach(){ //利用无参构造方法建立Jedis的客户端,这时候redis的host就是localhost,端口默认为6379 jedis = new Jedis(); jedis.select(0);//选择下标为0的数据库 } @Test //测试String类型的命令 public void testString(){ String result = jedis.set("name", "zhangshan"); System.out.println(result);//如果返回的是OK,说明操作成功 String name = jedis.get("name"); System.out.println(name); String result2 = jedis.set("age", "20"); System.out.println(result2); String age = jedis.get("age"); System.out.println(age); //测试获取多个key的值 List<String> strList = jedis.mget("name", "age"); System.out.println(strList); //测试自增 jedis.incrBy("age",2); System.out.println(jedis.get("age")); //测试删除操作,返回值就是删除的key的个数,如果不存在,直接返回0 Long del = jedis.del("name"); if(del != 0){ System.out.println("删除name这个key成功"); }else{ System.out.println("没能成功删除name这个key"); } } //测试哈希表 @Test public void testHash(){ //调用hset,来给KEY添加hash类型的值 jedis.hset("test:1","name","zhangshan"); jedis.hset("test:1","age","20"); jedis.hset("test:2","name","wangwu"); jedis.hset("test:3","name","lisi"); jedis.hset("test:3","age","19"); jedis.hset("test:3","gender","male"); //调用hmget,来获取KEY的多个值 List<String> list = jedis.hmget("test:3","name","gender"); System.out.println(list); //调用hgetall,来获取KEY的所有的field以及对应的值 Map<String, String> mapList = jedis.hgetAll("test:3"); System.out.println("test:3 = " + mapList); //调用hkeys,来获取KEY所有的field Set<String> keys = jedis.hkeys("test:3"); System.out.println("test:3:keys = " + keys); //调用hvals,获取KEY所有的field对应的值 List<String> vals = jedis.hvals("test:3"); System.out.println("test:3:vals = " + vals); //调用hrem,删除KEY的多个field Long del = jedis.hdel("test:3", "name", "age"); System.out.println("test:3这个KEY删除的field个数为: " + del); } //测试List类型 @Test public void testList(){ //在List的左边不断压入元素 Long count = jedis.lpush("list1", "1", "2", "3", "4"); System.out.println("成功压入了" + count + "个元素"); //获取某一个下标范围的元素,如果stop超过了元素的个数,那么list的最后一个元素为止 List<String> rangeList = jedis.lrange("list1", 2, 4); System.out.println("[2,4]的元素为: " + rangeList); //模拟队列,那么需要从右边不断跳出元素 System.out.print("List : "); for(int i = 0; i < 4; ++i){ String rpop = jedis.rpop("list1"); System.out.print(rpop + " "); } System.out.println(); } //测试Set @Test public void testSet(){ jedis.sadd("zs","zhaoliu","lisi"); jedis.sadd("ls","wangwu","lucy","zhaoliu","alice"); //调用scard方法,获取元素个数 Long zs = jedis.scard("zs"); Long ls = jedis.scard("ls"); System.out.println("zs = " + zs + ", ls = " + ls); //调用smembers,来获取对应的Set的所有元素 Set<String> zsList = jedis.smembers("zs"); Set<String> lsList = jedis.smembers("ls"); System.out.println("zsList = " + zsList + ", lsList = " + lsList); //调用srem方法,来删除key对应的Set的多个元素 Long rem = jedis.srem("ls", "wangwu", "alice"); System.out.println("删除ls中的元素个数: " + rem + ", 删除之后的元素: " + jedis.smembers("ls")); //调用sismemember,来判断member是否为Set的元素 Boolean isMember = jedis.sismember("zs", "zhaoliu"); System.out.println("zhaoliu is member of zs : " + isMember); isMember = jedis.sismember("zs", "alice"); System.out.println("alice is member of zs : " + isMember); //调用sinter,来获取多个Set的交集 Set<String> commons = jedis.sinter("zs", "ls"); System.out.println("zs and ls 交集: " + commons); //调用sdiff,来获取第一个Set和其他的Set的差集 Set<String> zs_diff = jedis.sdiff("zs", "ls"); Set<String> ls_diff = jedis.sdiff("ls", "zs"); System.out.println("zs_diff = " + zs_diff + ", ls_diff = " + ls_diff); //调用sunion,来获取多个Set的并集 Set<String> union = jedis.sunion("zs", "ls"); System.out.println("union = " + union); } @Test //测试Sorted_set,每一个元素都有一个属性score,它是根据score来排序的 public void testSorted_Set(){ //调用zadd,来添加元素 jedis.zadd("sorted",83,"Tom"); jedis.zadd("sorted",78,"Jim"); jedis.zadd("sorted",60,"Cindy"); jedis.zadd("sorted",55,"Tim"); jedis.zadd("sorted",86,"Alice"); jedis.zadd("sorted",85,"Lucy"); //调用zrange,来获取下标在[start,end]的元素,此时是根据score升序排序的 Set<String> incr_sorted = jedis.zrange("sorted", 0, 5); System.out.println("根据score升序排序时 : " + incr_sorted); //调用zrevrange,来获取下标在[start,end]的元素,此时根据score降序排序的 Set<String> dec_sorted = jedis.zrevrange("sorted", 0, 5); System.out.println("根据score降序排序时: " + dec_sorted); //调用zrank,来获取某一个元素在Sorted_set中的下标,默认时根据score升序排序的 Long incr_rank = jedis.zrank("sorted", "Tom"); System.out.println("根据score升序排序时,Tom的下标为 : " + incr_rank); //调用zrevrank,获取哦某一个元素在sorted_set中的下标,根据score降序排序的 Long dec_rank = jedis.zrevrank("sorted", "Tom"); System.out.println("根据score降序排序时,Tom下标为: " + dec_rank); //调用zrangeByScore,获取score在某一个区间的元素,默认时根据score升序排序的 Set<String> incr_rangeList = jedis.zrangeByScore("sorted", 75, 85); System.out.println("根据score升序排序的时候,score在[50,80]范围元素为: " + incr_rangeList); //调用zrevrangeByScore,获取score在某一个区间的元素,此时根据score降序排序的 Set<String> dec_rangeList = jedis.zrevrangeByScore("sorted", 85, 65); System.out.println("根据score降序排序时,score在[85,65]区间的元素为: " + dec_rangeList); //调用zscore,来获取某一个元素的score属性的值 Double score = jedis.zscore("sorted", "Tom"); System.out.println("Tom's score = " + score); } @After public void after(){ //释放资源 jedis.close(); } }但是因为Jedis是线程不安全的,所以在多线程的环境下,需要基于连接池来实现,所以如果我们需要通过连接池来操作的时候,需要先配置连接池,然后再从连接池中获取Jedis对象.
对应的代码为:
public class JedisConnectionFactory { private static final JedisPool jedisPool; static { //配置连接池的数据 JedisPoolConfig jedisPoolConfig = new JedisPoolConfig(); jedisPoolConfig.setMaxTotal(8);//最多连接个数 jedisPoolConfig.setMaxIdle(8);//设置最大空闲时间 jedisPoolConfig.setMinIdle(0);//设置最小空闲时间 //建立连接池 jedisPool = new JedisPool(jedisPoolConfig,"localhost",6379,1000); } //获取Jedis对象 public static Jedis getJedis(){ return jedisPool.getResource(); } }上面的代码是用来配置连接池的,然后通过调用它的静态方法getJedis,就可以获取Jedis对象了.测试代码只要利用上面的测试代码即可,只需要修改Jedis是通过上面配置连接池的代码中调用静态方法来获取即可。
Spring Data Redis快速入门以及序列化的2种方式以及注意的问题
我们知道,Spring善于整合各种框架,同样,它也可以整合Redis,进行操作。

所以Spring Data Redis开发的基本步骤为:
-
导入依赖spring-boot-starter-data-redis以及commons-pool2,之所以需要导入commons-pool2,是因为不管是Jedis,还是Lettuce,都需要通过连接池来获取
-
在配置文件中配置连接池,redis
# 配置redis spring: redis: lettuce: # 配置redis的客户端,spring中的redis默认的是lettuce pool: # 配置连接池 max-active: 8 # 最大连接数 max-idle: 8 # 最大空闲时间 min-idle: 0 # 最小空闲时间 # host: 默认时localhot # port: 6379端口默认为6379 -
使用Spring容器中的RedisTemplate对象,这个对象已经封装了对应的API,实现各种类型的操作。例如通过调用opsForValue方法,那么就会返回一个ValueOperations对象,它封装了操作String类型的各种方法。所以如果需要操作什么类型的,就通过RedisTemplate对象调用opsForXXX,就会返回XXXOperations对象,然后通过这个XXXOperations对象调用对应的方法进行对应的操作即可。
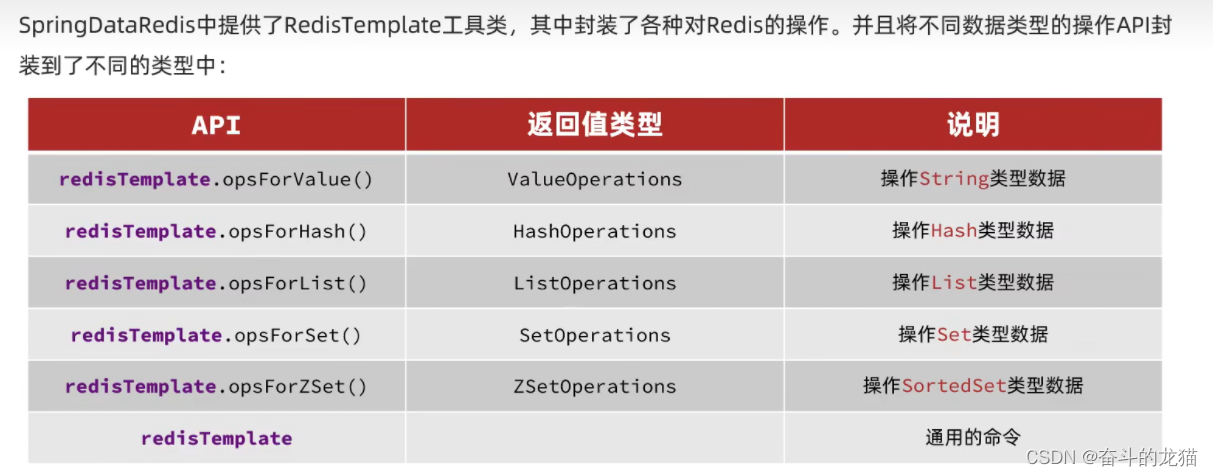
测试代码:
@SpringBootTest
class RedisTemplateApplicationTests {
//由于已经注入了data-redis依赖,所以可以直接通过@Autowired来获取RedisTemplate
@Autowired
private RedisTemplate<Object,Object> redisTemplate;
@Test
void contextLoads() {
}
@Test
public void testString(){
ValueOperations valueOperations = redisTemplate.opsForValue();
valueOperations.set("name","小小怪");
Object name = valueOperations.get("name");
System.out.println(name);//输出小小怪
}
@Test
public void testHash(){
HashOperations hashOperations = redisTemplate.opsForHash();
hashOperations.put("heims:map:4","name","wangwu");
hashOperations.put("heims:map:4","age","20");
Map<String,Object> entries = hashOperations.entries("heims:map:4");
System.out.println(entries);//输出{name=wangwu, age=20}
List<Object> values = hashOperations.values("heims:map:4");
System.out.println(values);//输出[wangwu, 20]
}
}
但是在测试testString的时候,如果在cmd中使用命令行来获取name的值的时候,如果之前数据库中并没有存在name这个key的时候,发现返回的是nil,表示没有找到name这个key,但是事实上,我们运行testString的时候已经添加了name这个key,这时候我们打开redis客户端发现,的确不存在name这个key,而是存在这一大串的key:\xac\xed\x00\x05t\x00\x04name,如下所示:
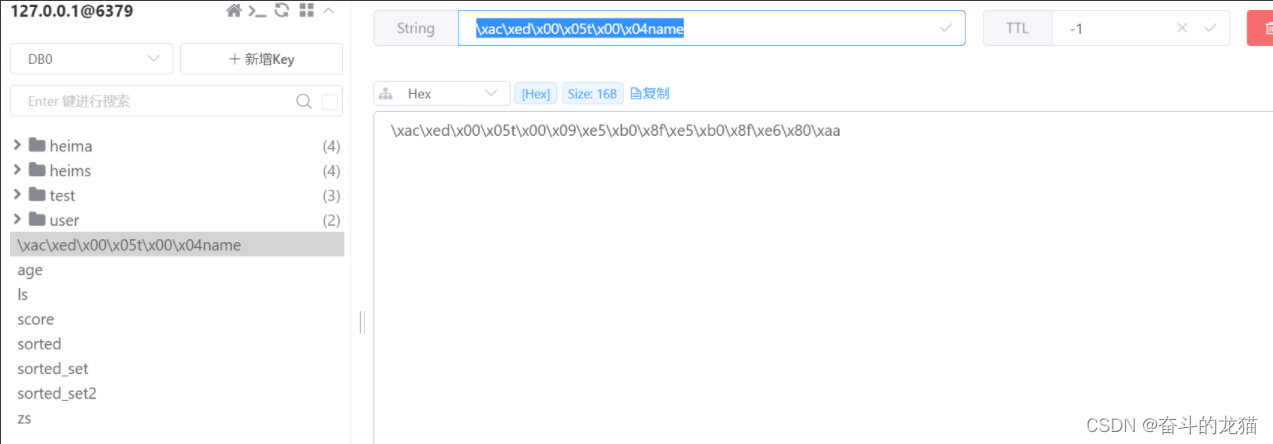
而对应的值也是一大串无法看懂的字符。这是为什么呢?通过查看源码得:
void set(K var1, V var2);
public void set(K key, V value) {
final byte[] rawValue = this.rawValue(value);
this.execute(new AbstractOperations<K, V>.ValueDeserializingRedisCallback(key) {
protected byte[] inRedis(byte[] rawKey, RedisConnection connection) {
connection.set(rawKey, rawValue);
return null;
}
}, true);
}
byte[] rawValue(Object value) {
return this.valueSerializer() == null && value instanceof byte[] ? (byte[])((byte[])value) : this.valueSerializer().serialize(value);
}
重点在rawValue方法中的valueSerializer(),获取valueSerializer对象,此时就来到了RedisTemplate类中,关键代码如下所示:
public class RedisTemplate<K, V> extends RedisAccessor implements RedisOperations<K, V>, BeanClassLoaderAware {
private boolean enableTransactionSupport = false;
private boolean exposeConnection = false;
private boolean initialized = false;
private boolean enableDefaultSerializer = true;
private RedisSerializer<?> defaultSerializer;
private RedisSerializer keySerializer = null;
private RedisSerializer valueSerializer = null;
private RedisSerializer hashKeySerializer = null;
private RedisSerializer hashValueSerializer = null;
/*
顾名思义,这个方法是在将设置属性之后,才会执行这个方法的,那么当我们从Spring中直接获取RedisTemplate对象
的时候,并没有设置属性,那么这时候就可以直接执行这个方法,这时候,就会设置默认的序列化对象为
JdkSerializationRedisSerializer,同样的,因为没有设置属性,所以所有的key的序列化对象,以及value的序列化
器都是采用的是JdkSerializationRedisSerializer,所以这时候就会使得我们设置的key的值如果是中文的时候,那么
就会采用JdkSerializationRedisSerializer,而返回一个byte数组,形式就是我们在客户端看到的样子.
*/
public void afterPropertiesSet() {
super.afterPropertiesSet();
boolean defaultUsed = false;
if (this.defaultSerializer == null) {
this.defaultSerializer = new JdkSerializationRedisSerializer(this.classLoader != null ? this.classLoader : this.getClass().getClassLoader());
}
if (this.enableDefaultSerializer) {
if (this.keySerializer == null) {
this.keySerializer = this.defaultSerializer;
defaultUsed = true;
}
if (this.valueSerializer == null) {
this.valueSerializer = this.defaultSerializer;
defaultUsed = true;
}
if (this.hashKeySerializer == null) {
this.hashKeySerializer = this.defaultSerializer;
defaultUsed = true;
}
if (this.hashValueSerializer == null) {
this.hashValueSerializer = this.defaultSerializer;
defaultUsed = true;
}
}
if (this.enableDefaultSerializer && defaultUsed) {
Assert.notNull(this.defaultSerializer, "default serializer null and not all serializers initialized");
}
if (this.scriptExecutor == null) {
this.scriptExecutor = new DefaultScriptExecutor(this);
}
this.initialized = true;
}
super.afterProperties方法代码为:
public void afterPropertiesSet() {
Assert.state(this.getConnectionFactory() != null, "RedisConnectionFactory is required");
}
所以通过上面的代码,就可以很容易发现,原来是因为没有设置key以及value的序列化器,从而默认采用的是JDK序列化器,然后就会将value返回的是一个byte数组,这样就会使得在redis的客户端中看到的是一大串的数据了。
所以只要我们通过配置RedisTemplate对象,创建的时候同时初始化key以及value的序列化器,就可以避免返回的是byte数组了。(注意并不是自定义,而是配置RedisTemplate对象,增加了设置属性的过程,而如果直接获取RedisTemplate对象的话,就没有配置属性的过程,也就出现了上面返回byte数组的情况)
@Configuration //使用注解@Configuration,表示这个是一个配置类,然后将方法中的返回值添加到Spring容器中
public class RedisTemplateConfig {
@Bean
public RedisTemplate<String,Object> redisTemplate(RedisConnectionFactory redisConnectionFactory){
//创建RedisTemplate对象
RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();
//设置连接工厂,因为我们重写了afterPropertiesSet,而在原来的方法中,同样注入了设置了连接的工厂。如上面的代码所示,如果没有设置,就会发生报错,提示RedisConnectionFactory is required
redisTemplate.setConnectionFactory(redisConnectionFactory);
//设置value的序列化器为GenericJackson2JsonRedisSerializer,能够转成json格式的字符串,同时也会自动的将json格式的字符串反序列化成为对象
GenericJackson2JsonRedisSerializer jsonRedisSerializer = new GenericJackson2JsonRedisSerializer();
//序列化key,一般建议KEY时String类型
redisTemplate.setKeySerializer(RedisSerializer.string());
redisTemplate.setHashKeySerializer(RedisSerializer.string());
//序列化value
redisTemplate.setValueSerializer(jsonRedisSerializer);
redisTemplate.setHashValueSerializer(jsonRedisSerializer);
return redisTemplate;
}
}
值得注意的是,上面需要设置4个序列化器,即KeySerializer,HashKeySerializer,ValueSerializer,HashValueSerializer,否则,就会导致发生报错,因为defaultedUsed为true,就有提示default serializer null and not all serializers initialized.所以在明白上面的源代码之后,就很容易知道这一部分配置的代码为什么这样写了。
配置之后,再次测试的时候,来到redis客户端,发现是成功运行的,name的值就变成了中文了,如下所示:
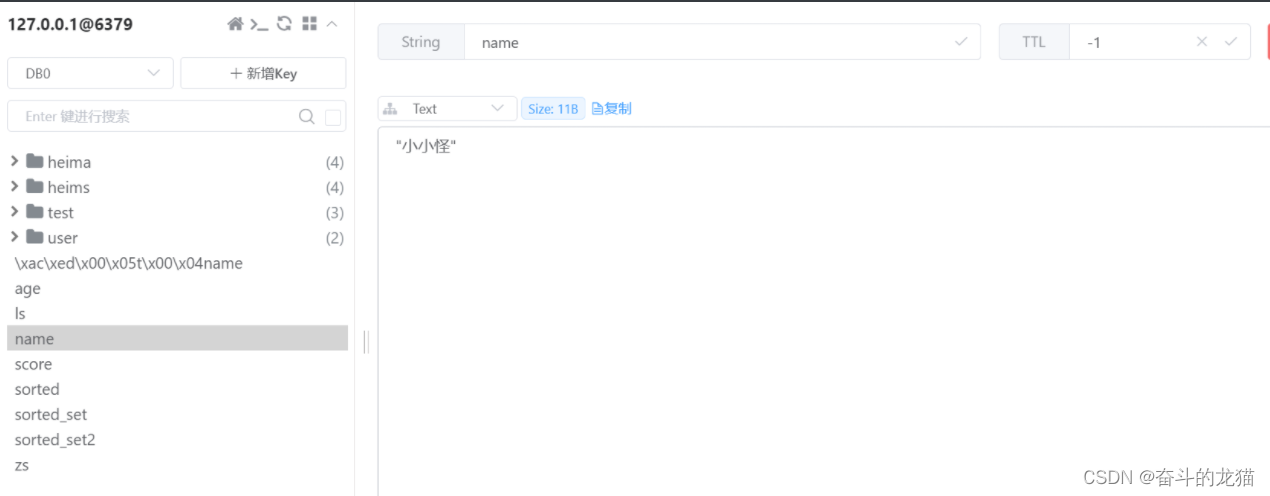
而之前的xxxxname依旧存在,是因为key不同,所以此时操作并没有影响到上次的xxxname这个key.
这时候我们也同样可以设置key的值是一个对象,因为我们的Value的序列化器是一个GenericJackson2JsonRedisSerializer,能够将对象自动序列化成为json格式的字符串,也可以将字符串反序列化成为一个对象。测试代码如下所示:
public void test(){
ValueOperations valueOperations = redisTemplate.opsForValue();
valueOperations.set("user:1",new User("wangwu",20));
User user = (User)valueOperations.get("user:1");
System.out.println(user);
}
User代码:
public class User {
private String name;
private int age;
public User() {
}
public User(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "User{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
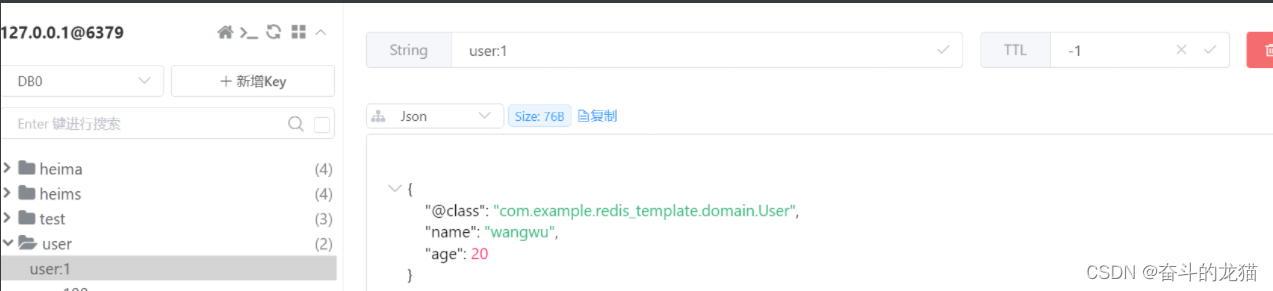
这时候我们看到了这个key对应的值中存在一个属性@class,它是根据这个属性来自动反序列化成为对应的User对象的。但是我们采用这一种方式进行序列化时,会导致占用很大的内存空间,因为存在这个属性值。所以为了解决这个问题,我们可以采用手动的方式进行序列化,就是采用StringRedisTemplate,将KeySerializer,HashKeySerializer,ValueSerializer,HashValueSerializer这四个属性都设置为StringRedisSerializer,并且编码为UTF-8,因为需要用到ObjectMapper,所以需要导入jackson-databind依赖,对应的代码如下所示:
<!-- https://mvnrepository.com/artifact/com.fasterxml.jackson.core/jackson-databind -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.13.3</version>
</dependency>
如下代码所示:
public StringRedisTemplate() {
this.setKeySerializer(RedisSerializer.string());
this.setValueSerializer(RedisSerializer.string());
this.setHashKeySerializer(RedisSerializer.string());
this.setHashValueSerializer(RedisSerializer.string());
}
static RedisSerializer<String> string() {
return StringRedisSerializer.UTF_8;
}
然后如果是一个对象的话,就需要手动地将其转成json格式的字符串,当从redis获取到这个字符串的时候,再手动将其转成对应的对象即可。所以上面代码可以改成如下代码:
@Test
public void test2() throws JsonProcessingException {
ValueOperations valueOperations = stringRedisTemplate.opsForValue();
User user = new User("lucy", 30);
//通过mapper对象,调用writeValueAsString,从而将对象转成json格式的字符串
String json = mapper.writeValueAsString(user);
valueOperations.set("user:100",json);
//获取值
String jsonUser = (String)valueOperations.get("user:100");
//手动转成User对象
user = mapper.readValue(jsonUser, User.class);
System.out.println(user);
}
再次运行的时候,客户端就变成了:
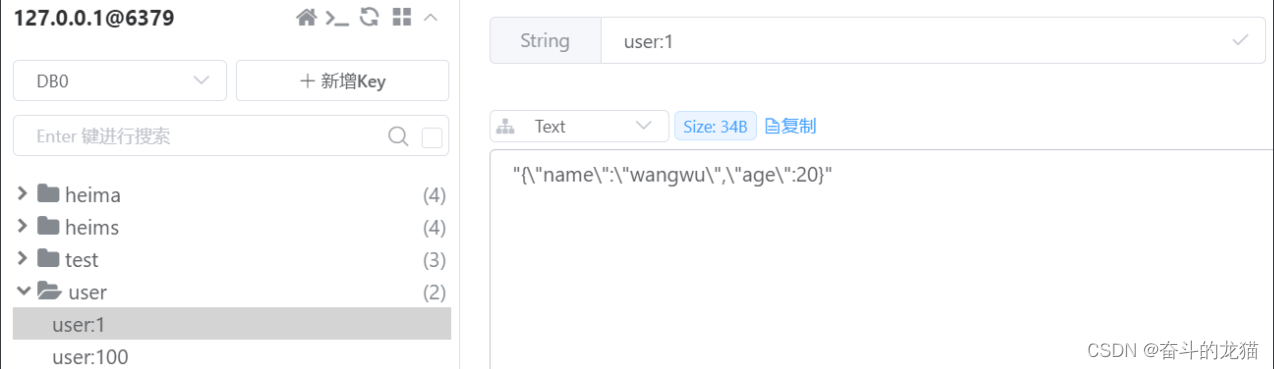
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









