






官方说明文档如下
大模型语音识别
双向流式模式: 支持将长音频实时识别成文字,达到“边说话边出文字”的效果,适用于实时语音识别的场景,如实时会议字幕、直播字幕、智能外呼等。具体为豆包打电话模式,实时语音通话;
流式输入模式: 支持将音频以流式方式送入,语音识别引擎处理完后返回句级的识别结果,适用于智能体对话、IM语音消息转写、语音输入法等场景。
两者都是每输入一个包返回一个包,双向流式模式会尽快返回识别到的字符,速度较快。
无论是哪种模式,单包音频建议在100~200ms大小左右,不能过大或者过小,否则均会影响性能。
大模型流式语音识别API
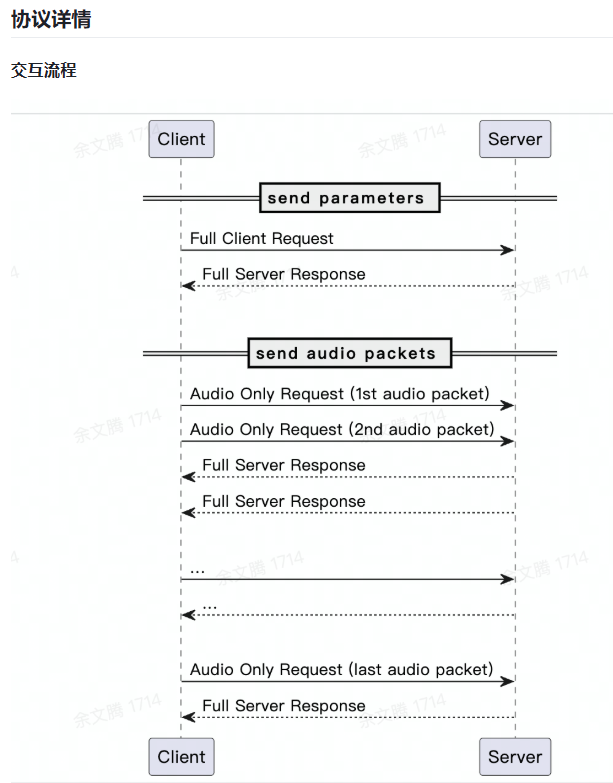
WebSocket协议

Header的主要参数内容
PROTOCOL_VERSION = 0b0001 #协议版本 此字段是为了使客户端和服务器在版本上达成共识
DEFAULT_HEADER_SIZE = 0b0001 #Header 大小,0b0001 - header size = 4 (1 x 4)# Message Type消息类型:
FULL_CLIENT_REQUEST = 0b0001 #端上发送包含请求参数的 full client request
AUDIO_ONLY_REQUEST = 0b0010 #端上发送包含音频数据的 audio only request
FULL_SERVER_RESPONSE = 0b1001 #服务端下发包含识别结果的 full server response
SERVER_ACK = 0b1011
SERVER_ERROR_RESPONSE = 0b1111 #服务端处理错误时下发的消息类型(如无效的消息格式,不支持的序列化方法等)# Message Type Specific Flags(消息类型特定标志) Message type 的补充信息
NO_SEQUENCE = 0b0000
# no check sequence 0b0000 - full client request 或包含非最后一包音频数据的audio only request 中设置
POS_SEQUENCE = 0b0001 # full client response 或包含非最后一包音频数据的audio only response 中设置
NEG_SEQUENCE = 0b0010 #包含最后一包音频数据的 audio only request 中设置
NEG_WITH_SEQUENCE = 0b0011 #包含最后一包音频数据的 audio only response 中设置
NEG_SEQUENCE_1 = 0b0011 #包含最后一包音频数据的 audio only response 中设置#Bit 位含义说明:
#bit0(0b0000最后一位):表示数据帧内是否编码 sequence 值信息
0:无序列号
1:有序列号
#bit1(0b0000倒数第二位): 表示当前数据帧是否是最后一包
0:非最后一包
1:最后一包
0b0000 无序列号
0b0001 有序列号
0b0010 无序列号 最后一包
0b0011 有序列号 最后一包# Message Serialization
NO_SERIALIZATION = 0b0000
JSON = 0b0001
# Message Compression
NO_COMPRESSION = 0b0000
GZIP = 0b0001Header函数定义
generate_header函数可传递的参数如下: message_type, message_type_specific_flags, serial_method, compression_type, reserved_data,
def generate_header(
message_type=FULL_CLIENT_REQUEST,
message_type_specific_flags=NO_SEQUENCE,
serial_method=JSON,
compression_type=GZIP,
reserved_data=0x00
):
"""
protocol_version(4 bits), header_size(4 bits),
message_type(4 bits), message_type_specific_flags(4 bits)
serialization_method(4 bits) message_compression(4 bits)
reserved (8bits) 保留字段
"""
header = bytearray()#创建一个可变的空字节数组对象,用于动态存储和修改二进制数据(如协议头、网络数据包等)
header_size = 1
header.append((PROTOCOL_VERSION << 4) | header_size)
header.append((message_type << 4) | message_type_specific_flags)
header.append((serial_method << 4) | compression_type)
header.append(reserved_data)
return header
if __name__ == '__main__':
print(generate_header())
#bytearray(b'\x11\x10\x11\x00')
# 协议版本1 + 头部大小1, 消息类型1 + 无序列, JSON + GZIP, 保留字段0x00
header.append((PROTOCOL_VERSION << 4) | header_size) 结合了位运算和列表操作
PROTOCOL_VERSION << 4将 PROTOCOL_VERSION 的值左移 4 位**(相当于乘以 )
PROTOCOL_VERSION | header_size 进行按位或运算,按位或的规则是:两个二进制位中至少有一个为 1 时,结果为 1
假如PROTOCOL_VERSION =1 ,二进制 为0b00000001
PROTOCOL_VERSION << 4后PROTOCOL_VERSION值为0b00010000
header_size = 5,二进制 0b00000101
0b00010000与 0b00000101进行或运算,等于0b00010101
建立连接
根据 WebSocket 协议本身的机制,client 会发送 HTTP GET 请求和 server 建立连接做协议升级。
需要在其中根据身份认证协议加入鉴权签名头。
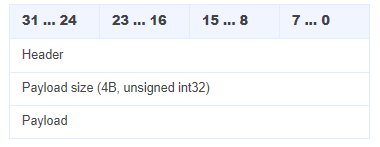
发送 full client request
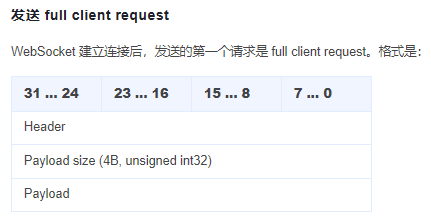
Header(4 字节)
header_size = 1
header.append((PROTOCOL_VERSION << 4) | header_size)
header.append((message_type << 4) | message_type_specific_flags)
header.append((serial_method << 4) | compression_type)
header.append(reserved_data)Payload Size
定义:表示按 Header 中指定的压缩方式压缩后的 Payload 长度,使用大端序(Big-Endian)表示
大端序(Big-Endian)是一种多字节数据在内存或网络传输中的存储顺序,其核心特征是高位字节存储在低地址,低位字节存储在高地址。
16进制数0x1234abcd存储在起始地址0x0000的内存中,大端序的排列将是:
0x0000 0x12
0x0001 0x34
0x0002 0xab
0x0003 0xcd
网络传输:TCP/IP协议强制使用大端序(网络字节序),确保跨平台数据一致性
编码规则:
-
若长度 ≤ 125 字节:直接使用 1 字节表示。
-
若长度 = 126:后续 2 字节(16 位)表示实际长度。
-
若长度 = 127:后续 8 字节(64 位)表示实际长度。
Payload
内容:包含音频元数据及服务器所需参数,通常为 JSON 格式(如 {"sampleRate": 44100, "codec": "opus"})
压缩:根据 Header 指定的压缩方式(如 GZIP)对 JSON 数据进行压缩
假设未压缩的 JSON 数据为 {"type": "audio", "size": 1024}(长度 22 字节),压缩后为 18 字节:
-
Header:
0x15(协议版本1,Header 大小5)。 -
Payload Size:
0x12(18 字节,直接使用 1 字节表示)。 -
Payload:压缩后的二进制数据。
第一层级的有
user ;用户相关配置
user层级下包含:
uid ;用户标识
did;设备名称
platform ;操作系统及API版本号
sdk_version;sdk版本
app_version;app 版本
audio;音频相关配置
audio层级下包含:
format;音频容器格式 pcm(pcm_s16le) / wav(pcm_s16le) / ogg
codec;音频编码格式 raw / opus,默认为 raw(pcm)
rate;音频采样率 默认为 16000,目前只支持16000
bits ;音频采样点位数 默认为 16
channel 音频声道数 1(mono) / 2(stereo),默认为1。
request;请求相关配置
request层级下包含:
model_name;模型名称
enable_itn;启用itn 默认为true。 文本规范化 (ITN) 是自动语音识别 (ASR) 后处理管道的一部分。 ITN 的任务是将 ASR 模型的原始语音输出转换为书面形式,以提高文本的可读性。 例如,“一九七零年”->“1970年”和“一百二十三美元”->“$123”。
enable_punc;启用标点 默认为true
enable_ddc;启用顺滑 默认为false。 语义顺滑是一种技术,旨在提高自动语音识别(ASR)结果的文本可读性和流畅性。这项技术通过删除或修改ASR结果中的不流畅部分,如停顿词、语气词、语义重复词等,使得文本更加易于阅读和理解。
show_utterances;输出语音停顿、分句、分词信息
result_type;结果返回方式 默认为"full",全量返回。设置为"single"则为增量结果返回,即不返回之前分句的结果。
vad_segment_duration;语义切句的最大静音阈值 单位ms,默认为3000。当静音时间超过该值时,会将文本分为两个句子。不决定判停,所以不会修改definite出现的位置。在end_window_size配置后,该参数失效。
end_window_size;强制判停时间 单位ms,默认为800,最小200。静音时长超过该值,会直接判停,输出definite。配置该值,不使用语义分句,根据静音时长来分句。用于实时性要求较高场景,可以提前获得definite句子
force_to_speech_time;强制语音时间 单位ms,默认为10000,最小1。音频时长超过该值之后,才会判停,根据静音时长输出definite,需配合end_window_size使用。用于解决短音频+实时性要求较高场景,不配置该参数,只使用end_window_size时,前10s不会判停。推荐设置1000,可能会影响识别准确率。
sensitive_words_filter ;敏感词过滤
corpus ;语料/干预词等
corpus层级下包含:
boosting_table_name;自学习平台上设置的热词词表名称
correct_table_name;自学习平台上设置的热词词表id
correct_table_name;自学习平台上设置的替换词词表名称
correct_table_id;自学习平台上设置的替换词词表id
context ;热词或者上下文
{
"user"用户相关配置: {
"uid"用户标识: "388808088185088"
},
"audio"音频相关配置: {
"format"音频容器格式: "wav",
"rate"音频采样率: 16000,
"bits"音频采样点位数: 16,
"channel"音频声道数: 1,
"language": "zh-CN"
},
"request"请求相关配置: {
"model_name"模型名称: "bigmodel",
"enable_itn"启用itn: false,
"enable_ddc"启用顺滑: false,
"enable_punc"启用标点: false,
"corpus"语料/干预词: {
"boosting_table_id"自学习平台上设置的替换词词表id: "通过自学习平台配置热词的词表id",
}
}
}发送audio only request
Client 发送 full client request 后,再发送包含音频数据的 audio-only client request。音频应采用 full client request 中指定的格式(音频格式、编解码器、采样率、声道)。
"audio"音频相关配置: {
"format"音频容器格式: "wav",
"rate"音频采样率: 16000,
"bits"音频采样点位数: 16,
"channel"音频声道数: 1,
"language": "zh-CN"
}
Payload 是使用指定压缩方法,压缩音频数据后的内容。可以多次发送 audio only request 请求,例如在流式语音识别中如果每次发送 100ms 的音频数据,那么 audio only request 中的 Payload 就是 100ms 的音频数据。
服务器发送full server response
Client 发送的 full client request 和 audio only request,服务端都会返回 full server response。格式如下:
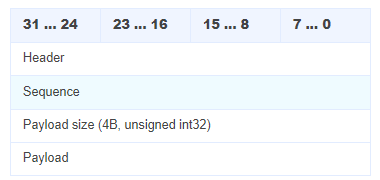
Payload 内容是包含识别结果的 JSON 格式,字段说明如下:
第一层级result:识别结果
第二层级
text;整个音频的识别结果文本
utterances;识别结果语音分句信息
utterances层级下
definite;是否是一个确定分句
end_time;结束时间
start_time;起始时间
text;utterance级的文本内容
示例:客户发送 3 个请求
下面的 message flow 会发送多次消息,每个消息都带有版本、header 大小、保留数据。由于每次消息中这些字段值相同,所以有些消息中这些字段省略了。 Message flow: client 发送 "Full client request"
version: b0001 (4 bits) header size: b0001 (4 bits) message type: b0001 (Full client request) (4bits) message type specific flags: b0000 (use_specific_pos_sequence) (4bits) message serialization method: b0001 (JSON) (4 bits) message compression: b0001 (Gzip) (4bits) reserved data: 0x00 (1 byte) payload size = Gzip 压缩后的长度 payload: json 格式的请求字段经过 Gzip 压缩后的数据
server 响应 "Full server response"
version: b0001 header size: b0001 message type: b1001 (Full server response) message type specific flags: b0001 (none) message serialization method: b0001 (JSON 和请求相同) message compression: b0001 (Gzip 和请求相同) reserved data: 0x00 sequence: 0x00 0x00 0x00 0x01 (4 byte) sequence=1 payload size = Gzip 压缩后数据的长度 payload: Gzip 压缩后的响应数据
client 发送包含第一包音频数据的 "Audio only client request"
version: b0001 header size: b0001 message type: b0010 (audio only client request) message type specific flags: b0000 (用户设置正数 sequence number) message serialization method: b0000 (none - raw bytes) message compression: b0001 (Gzip) reserved data: 0x00 payload size = Gzip 压缩后的音频长度 payload: 音频数据经过 Gzip 压缩后的数据
server 响应 "Full server response"
message type: 0b1001 - Full server response message specific flags: 0b0001 (none) message serialization: 0b0001 (JSON, 和请求相同) message compression 0b0001 (Gzip, 和请求相同) reserved data: 0x00 sequence data: 0x00 0x00 0x00 0x02 (4 byte) sequence=2 payload size = Gzip 压缩后数据的长度 payload: Gzip 压缩后的响应数据
client 发送包含最后一包音频数据(通过 message type specific flags) 的 "Audio-only client request",
message type: b0010 (audio only client request) message type specific flags: b0010 (最后一包音频请求) message serialization method: b0000 (none - raw bytes) message compression: b0001 (Gzip) reserved data: 0x00 payload size = Gzip 压缩后的音频长度 payload: Gzip 压缩后的音频数据
server 响应 "Full server response" - 最终回应及处理结果
message type: b1001 (Full server response) message type specific flags: b0011 (最后一包音频结果) message serialization method: b0001 (JSON) message compression: b0001 (Gzip) reserved data: 0x00 sequence data: 0x00 0x00 0x00 0x03 (4byte) sequence=3 payload size = Gzip 压缩后的 JSON 长度 payload: Gzip 压缩后的 JSON 数据
如处理过程中出现错误信息,可能有以下错误帧的返回
message type: b1111 (error response) message type specific flags: b0000 (none) message serialization method: b0001 (JSON) message compression: b0000 (none) reserved data: 0x00 Error code data: 0x2A 0x0D 0x0A2 0xff (4byte) 错误码 payload size = 错误信息对象的 JSON 长度 payload: 错误信息对象的 JSON 数据

















 1955
1955

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









